(Python)PyTorch 快速入门(B站图卷积)
课程地址:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili
目录
一、Dataset类代码实战
二、Dataset类(ants,bees)文件名的修改操作
三、Tensorboard的使用
四、Transform的使用
五、常见的transforms
一、Dataset类代码实战
#Dataset类代码实战
from PIL import Image
import matplotlib.pyplot as plt
from torch.utils.data import Dataset
import os #寻找文件地址时的包
class MyData(Dataset):
def __init__(self,root_dir,label_dir): #初始化类
self.root_dir = root_dir #使之成为全局变量
self.label_dir = label_dir
self.path = os.path.join(self.root_dir,self.label_dir) #地址的合并
self.img_path = os.listdir(self.path)#获取地址下的列表
def __getitem__(self,idx): #idx表示相应的索引,获取每一个图片
img_name = self.img_path[idx] #获取名称,self. 就表示全局变量
img_item_path = os.path.join(self.root_dir,self.label_dir,img_name) #获取每一个图片的地址
img = Image.open(img_item_path)#读取图片
label = self.label_dir
return img,label
def __len__(self):
return len(self.img_path)
root_dir = "D:/上课文件/python/B站图卷积数据集/hymenoptera_data/hymenoptera_data/train"
ants_label_dir = "ants_image"
bees_label_dir = "bees_image"
ants_dataset = MyData(root_dir,ants_label_dir)
bees_dataset = MyData(root_dir,bees_label_dir)
#把两个训练数据集集合混合到一起,按照前后的顺序排列,可以通过下面的代码实现
train_dataset = ants_dataset + bees_dataset
img,label = train_dataset[123]
plt.imshow(img)
plt.show()
print(label)二、Dataset类(ants,bees)文件名的修改操作
把只有图片的文件(2个图片文件,ants_image和bees_image文件),转化成四个文件(ants_image、ants_label、bees_image、bees_label),需要提前命名好ants_label、b、bees_label 这两个文件夹,以及每一个文件夹里预先有一个命名好的txt文件,这个文本文件的内容为ants。
#文件名的修改操作
import os
root_dir = "D:/上课文件/python/B站图卷积数据集/hymenoptera_data/hymenoptera_data/train"
target_dir = "bees_image"
img_path = os.listdir(os.path.join(root_dir,target_dir))
label = target_dir.split('_')[0]
out_dir = "bees_label"
for i in img_path:
file_name = i.split('.jpg')[0]
with open(os.path.join(root_dir,out_dir,"{}.txt".format(file_name)),'w')as f:
f.write(label)三、Tensorboard的使用
from torch.utils.tensorboard import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs") #创建一个实例
image_path = r"D:\上课文件\python\B站图卷积数据集\hymenoptera_data\hymenoptera_data\train\ants_image\0013035.jpg"
img_PIL = Image.open(image_path) #用PIL打开图片,但是此时不符合要求
img_array = np.array(img_PIL) #转成数组类型
writer.add_image("test",img_array,1,dataformats='HWC')#需要用dataformats='HWC'指定一下数据的位置
#这里的 1 表示步骤
#y=x
#for i in range(100):
# writer.add_scalar("y=x",i,i)
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()
'''
在Anaconda Promote内
1.先进入pytorch环境
2.输入tensorboard --logdir=logs
3.点开弹出的网址
'''四、Transform的使用
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
import cv2
'''
python 就是将自己的数据转换为 tonser数据类型
通过transform.ToTensor去解决两个问题
1.为什么需要tensor数据类型?
绝对路径:D:/上课文件/python/B站图卷积数据集/hymenoptera_data/hymenoptera_data/train/ants_image/0013035.jpg
相对路径:0013035.jpg
'''
img_path = "D:/上课文件/python/B站图卷积数据集/hymenoptera_data/hymenoptera_data/train/ants_image/0013035.jpg"
img = Image.open(img_path) #这个里面读出来的是PIL的图片数据类型
''' transform该如何使用?'''
tensor_trans = transforms.ToTensor() #定义一个工具,这里的ToTenser可以将PIL
#和numpy.ndarray 两种数据类型转换为tensor数据类型
tensor_img = tensor_trans(img)
cv_img = cv2.imread("0013035.jpg")#在这个里面打不开绝对路径的图片,相对路径的可以
tensor_cv_img = tensor_trans(cv_img)
''' tensor数据类型包含一些神经网络所用的各种参数
神经网络中肯定要转化成tensor型进行训练
'''
writer = SummaryWriter("logs")
writer.add_image("tensor_img",tensor_img)
writer.close()
'''
终端pytorch里输入:tensorboard --logdir=logs
这里的地址要与终端的地址相对应,否则不会显示
'''五、常见的transforms
'''
常见的transforms
PIL Image.open()
tensor ToTensor()
narrays cv.imread()
'''
'''
类的定义:
class Person:
def __call__(self,name):
print("__call__"+"hello"+name)
def hello(self,name):
print("hello"+name)
person = Person() #类的实例化
person("zhangsan") #__call__ 的用法
person.hello("lisi") #hello的用法
'''
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("D:\上课文件\python\python操作文件\ciyun.png").convert('RGB')
#PIL方式打开图片,并且图片以RGB形式数据排列
#print(img)
#ToTensor 转化为tensor类型
trans_totensor = transforms.ToTensor()#类的实例化
img_tensor = trans_totensor(img) #图片转化成tensor类型
writer.add_image("totensor", img_tensor)
#Normalize 标准化
#print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
#第一个括号是mean,第二个括号是std
#tensor数据类型对应的是三个值,很多都需要实例化
img_norm = trans_norm(img_tensor)
#print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
#Resize 输入的是PIL的图片数据
#print(img.size)
#print(type(img))
trans_resize = transforms.Resize((512,512)) #实例化
#img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
#print(img_resize.size)
#通过以下方法可以查看图片的类型
#print(img_resize)
#print(type(img_resize))
#img_resize PIL -> totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize,0)
#print(img_resize)
#Compose - resize -2 #compose:组合
trans_resize_2 = transforms.Resize(512) #变化的是第二个参数,
#并且保持长宽比例
#PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_resize_2(img)
#print(img_resize_2)
img_resize_2 = trans_totensor(img_resize_2)
writer.add_image("Resize2", img_resize_2,0)
#注意:以上两步可以合并为一步实现,利用compose
img_resize_3 = trans_compose(img)
writer.add_image("Resize3", img_resize_3,0)
#RandomCrop 随机裁剪
trans_random = transforms.RandomCrop(32) #随机裁剪出来是32*32的
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop,i)
writer.close()

使用transforms时的注意事项:
1.关注输入和输出类型
2.多看官方文档
3.关注方法需要什么参数
不知道返回值的时候:
*print(type())
*debug
transforms 里面也有tensor数据类型转化为 PIL数据类型的命令。
六、torchvision中的数据集的使用
#%%torchvision中的数据集的使用
#pytorch使用时需要转化为tensor数据类型
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) #将数据转换为tensor数据类型
#在这里也可以用resize进行裁剪
train_set = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = True,
transform = dataset_transform,#转化为tensor数据类型
download = False)
test_set = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = False,
transform = dataset_transform,#转化为tensor数据类型
download = False)
'''
#查看数据集-可以将咱们要处理的数据格式转换为模型的数据格式
print(test_set[0])
print(test_set.classes)
img,target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
'''
#print(test_set[0])
#使用tensorboard显示图片
writer = SummaryWriter("p10")
for i in range(10):
img,target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()
'''
在Anaconda Promote内
1.先进入pytorch环境
2.输入tensorboard --logdir=logs
3.点开弹出的网址
'''
七、dataloader的使用

#%%dataloader的使用
import torchvision
from torch.utils.data import DataLoader #注意L是大写的
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) #将数据转换为tensor数据类型
#在这里也可以用resize进行裁剪
#准备测试数据集
test_data = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = False,
transform = dataset_transform,#转化为tensor数据类型
download = False)
test_loader = DataLoader(dataset=test_set,
batch_size=64, #每次取四个数据集进行打包
shuffle=True, #第一轮和第二轮是否会打乱
num_workers=0,
drop_last=True)
#测试数据集中第一张图片及target
img,target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs,targets = data
#print(imgs.shape)
#print(targets)
writer.add_images("Epoch: {}".format(epoch),imgs,step)
step = step + 1
writer.close()
'''
torch.Size([4, 3, 32, 32]) 四张图片,三个通道,32*32的图片
tensor([6, 4, 9, 3])
'''八、神经网络的基本骨架-nn.Module的使用

#%% 神经网络的基本骨架-nn.Module的使用
from torch import nn
import torch
class Tudui(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):
output = input + 1
return output
tudui = Tudui() #实例化
x = torch.tensor(1.0)
output = tudui(x)
print(output)九、神经网路卷积层
out_channel = 1时,会有一个卷积核。

out_channel = 2 时,会有两个卷积核(两个卷积核不一定相同),有两个输出。

#%%神经网络-卷积层
from torch import nn
import torch
import torchvision
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) #将数据转换为tensor数据类型
#在这里也可以用resize进行裁剪
#准备测试数据集
dataset = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = False,
transform = dataset_transform,#转化为tensor数据类型
download = False)
#使用加载器加载一下
dataloader = DataLoader(dataset,batch_size = 64,drop_last=True)
class Tudui(nn.Module):
def __init__(self): #定义一下副类
super(Tudui,self).__init__()
self.conv1 = Conv2d(in_channels=3,
out_channels=6,
kernel_size=3,
stride=1,
padding=0)
def forward(self,x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("loges")
step = 0
for data in dataloader:
imgs,targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
#torch.size([64,3,32,32])
writer.add_images("input",imgs,step)
#torch.size([64,3,32,32]) --> torch.size([xxx,3,32,32])
output = torch.reshape(output,(-1,3,30,30))
''' 当不知道输出的具体是几时,可以用-1代替'''
writer.add_images("output",output,step)
step = step + 1
writer.close()十、神经网络-最大池化的使用
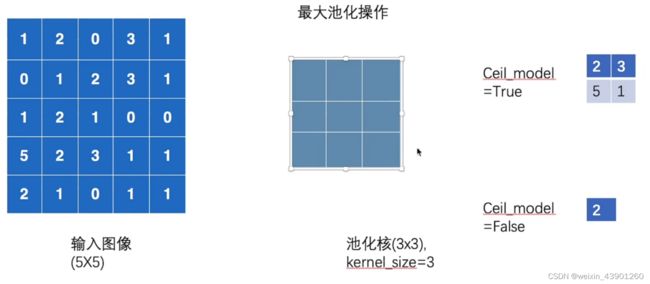
#%%神经网络-最大池化的使用
'''
最大池化也被称为下采样
'''
import torch
from torch import nn
from torch.nn import MaxPool2d
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) #将数据转换为tensor数据类型
#在这里也可以用resize进行裁剪
dataset = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = False,
transform = dataset_transform,#转化为tensor数据类型
download = False)
dataloader = DataLoader(dataset,batch_size = 64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=False)
def forward (self,input):
output = self.maxpool1(input)
return output
tudui = Tudui()
writer = SummaryWriter("logess")
step = 0
for data in dataloader:
imgs,targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
#torch.size([64,3,32,32])
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step = step + 1
writer.close()十一、非线性激活

建议 inplace = False 可以防止数据的丢失
#%% 非线性激活
import torch
from torch.nn import Sigmoid
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) #将数据转换为tensor数据类型
#在这里也可以用resize进行裁剪
dataset = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = False,
transform = dataset_transform,#转化为tensor数据类型
download = False)
dataloader = DataLoader(dataset,batch_size = 64,drop_last=True)
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.relu1 = Sigmoid()
def forward(self,input):
output = self.relu1(input)
return output
tudui = Tudui()
writer = SummaryWriter("logesss")
step = 0
for data in dataloader:
imgs,targets = data
output = tudui(imgs)
print(imgs.shape)
print(output.shape)
#torch.size([64,3,32,32])
writer.add_images("input",imgs,step)
writer.add_images("output",output,step)
step = step + 1
writer.close()非线性激活可以给网络中引入一些非线性特征,非线性越多,才能训练出符合各种曲线、符合各种特征的模型,进而提高模型的泛化能力。
十二、线性层及其他层的介绍
线性层
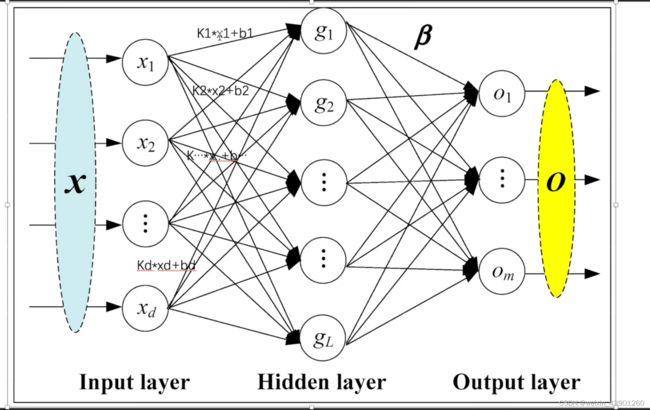

#%%搭建小实战和Sequential的使用
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
import torch
from torch.utils.tensorboard import SummaryWriter
'''
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.conv1 = Conv2d(in_channels=3,
kernel_size=5,
out_channels=32,
padding=2,
)
self.maxpool1 = MaxPool2d(kernel_size=2)
self.conv2 = Conv2d(in_channels=32,
out_channels=32,
kernel_size=5,
padding = 2)
self.maxpool2 = MaxPool2d(kernel_size=2)
self.conv3 = Conv2d(in_channels=32,
out_channels=64,
kernel_size=5,
padding=2)
self.maxpool3 = MaxPool2d(kernel_size=2)
self.flatten = Flatten()
self.linear1 = Linear(in_features=1024,
out_features=64)
self.linear2 = Linear(in_features=64,
out_features=10) #因为分成了10类别,所以是10个输出
def forward(self,x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
tudui = Tudui()
#print(tudui)
下面这个步骤可以用来检验这个网络
input = torch.ones(64,3,32,32)
output = tudui(input)
print(output.shape)
'''
#Sequential的作用-与上面是一样的
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3,
kernel_size=5,
out_channels=32,
padding=2
),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32,
out_channels=32,
kernel_size=5,
padding = 2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32,
out_channels=64,
kernel_size=5,
padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024,
out_features=64),
Linear(in_features=64,
out_features=10) #因为分成了10类别,所以是10个输出
)
def forward(self,x):
x = self.model1(x)
return x
tudui = Tudui()
#print(tudui)
'''下面这个步骤可以用来检验这个网络'''
input = torch.ones(64,3,32,32)
output = tudui(input)
print(output.shape)
#这个可以用来看具体的网络结构
writer = SummaryWriter("seq")
writer.add_graph(tudui,input)
writer.close()
以下这个代码这个可以用来看具体的网络结构:
#这个可以用来看具体的网络
writer = SummaryWriter("seq")
writer.add_graph(tudui,input)
writer.close()
十三、损失函数和反向传播

根据梯度,反向传播,进而优化,使得loss降低。
交叉熵常常用于分类问题
#%% 损失函数
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
from torch.utils.tensorboard import SummaryWriter
import torch
from torch.nn import L1Loss
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
'''
inputs = torch.tensor([1,2,3],dtype=torch.float32)
targets = torch.tensor([1,2,5],dtype=torch.float32)
inputs = torch.reshape(inputs,(1,1,1,3))
targets = torch.reshape(targets,(1,1,1,3))
loss = L1Loss() #必须要实例化
result = loss(inputs,targets)
loss_mes = nn.MSELoss() #也可以这样导入
result_mse = loss_mes(inputs,targets)
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1, #这个1表示类别
3)) #这个3表示有几个类别
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
# print(result_cross)
'''
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) #将数据转换为tensor数据类型
#在这里也可以用resize进行裁剪
dataset = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = False,
transform = dataset_transform,#转化为tensor数据类型
download = False)
dataloader = DataLoader(dataset,batch_size = 1,drop_last=True)
#Sequential的作用-与上面是一样的
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3,
kernel_size=5,
out_channels=32,
padding=2
),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32,
out_channels=32,
kernel_size=5,
padding = 2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32,
out_channels=64,
kernel_size=5,
padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024,
out_features=64),
Linear(in_features=64,
out_features=10) #因为分成了10类别,所以是10个输出
)
def forward(self,x): #这个叫做前向传播
x = self.model1(x)
return x
tudui = Tudui()
loss_cross = nn.CrossEntropyLoss()
for data in dataloader:
imgs,targets = data
outputs = tudui(imgs)
result_cross = loss_cross(outputs,targets)
# print(result_cross)
# result_cross.backward() #反向传播,是对result_cross进行反向传播十四、优化器
#%%优化器
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
from torch.utils.tensorboard import SummaryWriter
import torch
from torch.nn import L1Loss
from torch import nn
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) #将数据转换为tensor数据类型
#在这里也可以用resize进行裁剪
dataset = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = False,
transform = dataset_transform,#转化为tensor数据类型
download = False)
dataloader = DataLoader(dataset,batch_size = 1,drop_last=True)
#Sequential的作用-与上面是一样的
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.model1 = Sequential(
Conv2d(in_channels=3,
kernel_size=5,
out_channels=32,
padding=2
),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32,
out_channels=32,
kernel_size=5,
padding = 2),
MaxPool2d(kernel_size=2),
Conv2d(in_channels=32,
out_channels=64,
kernel_size=5,
padding=2),
MaxPool2d(kernel_size=2),
Flatten(),
Linear(in_features=1024,
out_features=64),
Linear(in_features=64,
out_features=10) #因为分成了10类别,所以是10个输出
)
def forward(self,x): #这个叫做前向传播
x = self.model1(x)
return x
tudui = Tudui()
loss_cross = nn.CrossEntropyLoss()
optim = torch.optim.SGD(tudui.parameters(),
lr=0.01,
)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs,targets = data
outputs = tudui(imgs)
result_loss = loss_cross(outputs,targets)
optim.zero_grad() #对优化器网络里的每个参数进行清零
result_loss.backward() #调用损失函数的反向传播
optim.step() #对模型里面的每个参数进行调优
running_loss = running_loss + result_loss
print(running_loss)十五、网络模型的使用和修改
#%% 网络模型的使用和修改
import torchvision
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False)
'''
pretrained=True
预训练设置为True的时候,参数已经是在数据集上训练好的
在数据集上能够达到一个好的效果
'''
vgg16_true = torchvision.models.vgg16(pretrained=True)
'''通过打印可以看到具体的数据结构'''
#print(vgg16_true)
'''
可以在该模型上进行操作和改动
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
'''
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]) #将数据转换为tensor数据类型
#在这里也可以用resize进行裁剪
train_data = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = False,
transform = dataset_transform,#转化为tensor数据类型
download = False)
#在vgg16模型的基础上进行操作和改动
#这个是加到模型的最后面
#vgg16_true.add_module('add_linear', module=nn.Linear(1000,10))
#print(vgg16_true)
'''
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
'''
#看与上面的区别,这个是加到classifier里面
vgg16_true.classifier.add_module('add_linear', module=nn.Linear(1000,10))
print(vgg16_true)
'''
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
)
'''
#在原来的网络结构上修改
vgg16_false.classifier[6] = nn.Linear(4096,10)
print(vgg16_false)
'''
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
'''
十六、网络模型的保存与读取
以下代码中包括了三种方法,要仔细甄别。
#%%模型的保存与读取
import torchvision
import torch
from torch import nn
vgg16 = torchvision.models.vgg16(pretrained=False)
#此时有模型,但是参数没有训练,是初始化的参数
#保存方式1-保存了网络模型的结构和参数
torch.save(vgg16,"vgg16_method1.pth")
#同时保存了网络模型的结构和参数
#加载模型的方法
model = torch.load('vgg16_method1.pth')
print(model)
#保存方式2-以字典形式保存,保存的模型的参数(官方推荐)
torch.save(vgg16.state_dict(),"vgg16_method2.pth")
#加载模型的方法
model = torch.load("vgg16_method2.pth")
print(model)
#这样是可以看到具体的结构的
vgg16 = torchvision.models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)
#保存一个模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.conv1 = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x):
x = self.conv1(x)
return x
#tudui = Tudui() ---这一步是不需要的
torch.save(tudui,"tudui_method1.pth")
#加载
model = torch.load('tudui_method1.pth')
print(model)十七、完整的模型训练套路

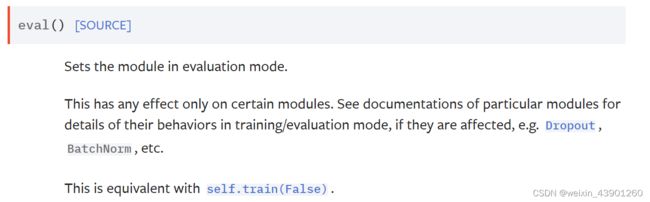
train()和eval() 只对特定的层有用
可以调用GPU的地方:
网络结构、损失函数 、数据
谷歌训练:
国内的 阿里云和天池
PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】_哔哩哔哩_bilibili
#%%完整的模型训练套路
import torchvision
from torch import nn
from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
import torch
from torch.utils.tensorboard import SummaryWriter
#from model import *
from torch.utils.data import DataLoader #注意L是大写的
import time
#准备数据集
train_data = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = True,
transform=torchvision.transforms.ToTensor(),#转化为Tensor数据类型
download=False)
test_data = torchvision.datasets.CIFAR10(root="D:\\上课文件\\data\\",
train = False,
transform=torchvision.transforms.ToTensor(),
download=False)
#length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
#利用DataLoader加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#创建网络模型
class Tudui(nn.Module):
def __init__(self):
super(Tudui,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,32,5,1,2),
nn.MaxPool2d(2),
nn.Conv2d(32,64,5,1,2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64,10)
)
def forward(self,x):
x = self.model(x)
return x
tudui = Tudui()
if torch.cuda.is_available():
tudui = tudui.cuda() #调用GPU
#损失函数-因为是分类问题,所以使用交叉熵
loss__fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss__fn = loss__fn.cuda()
#优化器
#learning_rate = 0.01 #把学习速率提出来,有助于修改参数
learning_rate = 1e-2 #1e-2 = 1*(10)^(-2) = 0.01
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练轮数
epoch = 10
#添加Tensorboard
writer = SummaryWriter("log_train_")
start_time = time.time() #记录此时的时间
for i in range(epoch):
print("----------第 {} 轮训练开始---------".format(i+1)) #因为是从0开始的,所以要+1
#训练步骤开始
tudui.train()#Sets the module in training mode.
#This has any effect only on certain modules.
#See documentations of particular modules for
#details of their behaviors in training/evaluation mode,
#if they are affected, e.g. Dropout, BatchNorm, etc.
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss__fn(outputs,targets)
#优化器调优 优化模型
optimizer.zero_grad() #优化的过程中首先一定要进行梯度清零
loss.backward() #当我们利用优化器梯度清零的时候,我们可以调用求出来的损失
#然后我们用损失的反向传播,得到每一个参数节点的梯度
optimizer.step() #这一步可以对其中的参数进行优化
total_train_step = total_train_step + 1#此时已经完成了一次训练
if total_train_step % 100 ==0: #逢100的时候才打印
end_time = time.time() #记录结束的时间
print(end_time - start_time)
print("训练次数:{}, Loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss", #标签
scalar_value=loss.item(), #每次的值是多少
global_step=total_train_step
)
#假如是Tensor 数据类型,写loss 打印:tensor(5)
# 写loss.item() 就会打印:5
#每次训练完,要在测试数据集上跑一遍,看看模型的效果怎么样
#在测试的过程中不需要对模型进行调优,使用现有的模型来进行测试
#所以要加一个这个
#测试步骤开始
tudui.eval() #Sets the module in evaluation mode.
#This has any effect only on certain modules.
#See documentations of particular modules for
#details of their behaviors in training/evaluation mode,
#if they are affected, e.g. Dropout, BatchNorm, etc.
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): #在这个里面没有了梯度,相当于不会对参数进行调优,就可以写测试代码了
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = tudui(imgs)
loss = loss__fn(outputs,targets)
total_test_loss = total_test_loss + loss #把每次的loss都加到了整体的loss上
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", #标签
scalar_value=total_test_loss, #每次的值是多少
global_step=total_test_step
)
writer.add_scalar("test_accuracy", #标签
scalar_value=total_accuracy, #每次的值是多少
global_step=total_test_step
)
total_test_step = total_test_step + 1
torch.save(tudui,"D://上课文件//python//python代码//B站卷积模型//tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
'''
测试代码:
import torch
outputs = torch.tensor([[0.1,0.2],
[0.3,0.4]])
print(outputs.argmax(1)) 填1表示横向看,填0表示纵向看
结果:
tensor([1,1])
''' 十八、完整的模型验证套路
#%% 完整的模型验证套路
from PIL import Image
import torchvision
image_path = "C:/Users/HuXiang/Desktop/dog.png"
image = Image.open(image_path)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
image = transform(image)
#print(image.shape)
model = torch.load(r"D:\上课文件\python\python代码\B站卷积模型\tudui_0.pth",
map_location=torch.device('cpu')#这个把Gpu上的东西映射到cpu上
)
#print(model)
image = torch.reshape(image,(1,3,32,32)) #这一步容易遗忘
model.eval() #这一步写上,养成良好的代码习惯
with torch.no_grad(): #这一步可以节省很多内存
output = model(image)
print(output)
print(output.argmax(1))