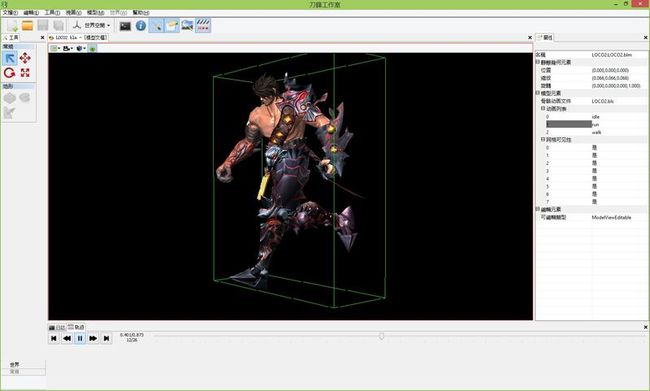
引擎设计跟踪(九.14.2b) 骨骼动画基本完成
首先贴一个介绍max的sdk和骨骼动画的文章, 虽然很早的文章, 但是很有用, 感谢前辈们的贡献:
1.Dual Quaternion
关于Dual Quaternion, 这里不做太详细的介绍了,贴出来几个链接吧:
http://en.wikipedia.org/wiki/Dual_quaternion
http://www.seas.upenn.edu/~ladislav/kavan08geometric/kavan08geometric.pdf
http://www.xbdev.net/misc_demos/demos/dual_quaternions_beyond/paper.pdf
Qual Quaternion可以用两个quaternion以类似二元数的形式表示( dq = p + ε q, ε^2 = 0), 其中,实部用来表示旋转, 虚部可以解出来偏移量. 一个dq可以表示一个不带缩放的刚体变换:
1 DualQuaternion(const Quaternion& rotation, const Vector3& translation) 2 { 3 p = rotation;
4 q = reinterpret_cast<Quaternion&>(Vector4(translation,0))*rotation*0.5;
5 }
需要注意的要点是, Dual Quaternion的插值和混合, 也跟quaternion的插值比较类似.
quaternion的一般线性差值不是匀速平滑的, 如果要精确差值的话, 需要用球面线性插值, 但是在变化量比较小的时候, 可以用线性插值作为近似值,不过需要normalize, 即quaternion的nlerp.
与quaternion类似, Dual Quaternion的线性混合(DLB, Dual-quaternion Linear Blending)也可以用在差量比较小的混合, 作为一个近似值. DLB跟nlerp很类似:
(w0*dq0 + w1*dq1 + ... + wn*dqn..) / | w0*dq0 + w1*dq1 + ... + wn*dqn| (w0+w1+...+wn=1表示权重), 即加权混合后单位化.
而与球面线性插值类似, Dual Quaternion也有平滑精确的插值混合方式, 叫做ScLerp, 两个DQ的ScLerp插值可以推广为n个DQ的一般形式, 具体公式我也记不清了, 记得是用次方? 不说了, 内容全在上面那两个paper里.
在shader里为了效率的考量, 使用DLB来混合骨骼的变换.
2.骨骼空间的选择
这个在开始贴的那篇文章里面已经提到了. 这里也谈谈自己的理解.
导出骨骼动画时, 可以导出两种空间:
- 世界空间(即max里单独模型的世界空间, 在游戏里面将会变成整个角色的局部空间)
- 局部空间(相对于父骨骼的变换)
对于世界空间的变换, 相当于预计算了每一帧中的骨骼层级关系, 运行时的计算时相对简单, 每个骨头相当于孤立的控制点, 不需要记录骨头的父子关系, 直接把骨头的变换应用到顶点即可.
而导出局部空间变换时, 首先要像更新场景图那样, 从根节点更新到叶子节点, 计算骨头的变换. 更新完以后, 再把最后的骨骼变换应用到顶点.
局部空间骨骼变换的好处是可以方便的进行动画混合. 因为混合的时候父节点位置会改变, 从而影响到子节点. 但是用世界空间变换, 混合动画时, 父节点混合后的变换无法影响到子节点, 所以会有问题.
而对于之前预研过的骨骼变换公式:
![]()
这个公式中的matrix[i]是骨头的世界空间变换.
可以看出, 世界空间的变换, 效率很高, 甚至可以不要单独保存TPose? 因为从公式上看 matrix[i]*matrix[i]bindpose-1是可以合并到每一帧里,预计算的.
说道T Pose, 因为顶点相对于骨头的位置, 是有一个固定值的, 比如皮肤到骨骼有段距离, 这段距离通常不会跟随骨骼的旋转/移动而改变. 如果把这个初始相对位置"直接"保存的话, 那么对于每个影响到该顶点的骨头都需要保存一个相对的初始位置, 而且, 一个骨头也可能影响到多个顶点, 总的来说数据量会多一点.
所以取一个骨骼动画的初始"顶点"位置(Vbindpose), 作为一个mesh保存, 加上对应的骨骼的初始变换状态:matrix[i]bindpose,一并保存. 这个初始状态就是Binding Pose, 也叫T Pose("T"字形).T pose还会尽量把无关的骨头分的更远, 避免骨头间的相互影响, 方便美术建模.
Vbindpose是初始顶点位置, 是模型的世界空间,
matrix[i]bindpose是世界空间的初始骨骼变换,
这两个值"间接"保存了顶点相对于骨头的初始位置, 即 matrix[i]bindpose-1*Vbindpose, 有了这个相对位置, 再应用上每一帧动画里的骨骼变换, 顶点就会跟着骨头做变换了.
3.导出时遇到的一些问题
去掉骨骼缩放:
因为我这里的骨骼动画不处理缩放的情况, 而有的骨头带缩放, debug时矩阵的数据非常小, 为了避免产生不必要的误差, 去掉骨骼变换的缩放.
1 GMatrix tm = node->GetWorldTM(0); 2 3 //drop scale 4 Matrix3 m3 = tm.ExtractMatrix3(); 5 m3.NoScale(); 6 tm = m3;
max sdk的问题:
一开始使用INode取出骨骼变换, 结果不对, 因为INode使用的是Max的坐标系, 而我用的是自己的坐标系, 而且已经通过IGame设置好了, 所以正确的做法是用IGameNode来获取GMatrix变换, 而不适用INode的Matrix3.
另外, Gmaxtrix转换到Matrix3之后的坐标系也不一样:
1 //!Extract a Matrix3 from the GMatrix 2 /*!This is for backward compatibility. This is only of use if you use 3ds Max as a coordinate system, other wise 3 standard 3ds Max algebra might not be correct for your format. 4 \returns A 3ds Max Matrix3 form of the GMatrix 5 */ 6 IGAMEEXPORT Matrix3 ExtractMatrix3()const ;
最大的坑是, GMatrix解出的quaternion的坐标系也是max的坐标系... 但是不像上面那样有清楚的文档注释, 害得被坑了好久.
1 //! Return a essential rotation transformation 2 IGAMEEXPORT Quat Rotation () const;
最大的问题是调试:
因为导出插件需要调试, 而且要用runtime验证结果, 但是runtime也没写好, 也在调试中(-_-!), 所以最终结果渲染不对的时候, 不知道是runtime代码有问题, 还是导出的时候出了问题.
这个没有很好的办法, 只能慢慢看代码, 单步调了.不过有一些方法还是能够帮助定位问题的:
- 从渲染结果里面能看出很多东西, 比如动画的根节点是横着放的(其他骨骼也不对,而且整体是乱的), 说明旋转有问题, 而且极有可能是导出坐标系的问题.
- 还有就是, 先改用用最简单的, 只导出骨骼的世界坐标, 并且可以去掉插值, 这样runtime也更简单: 简化调试, 等到结果正确了, 再提高复杂度, 继续调试, 将问题逐个击破(调试中的分治法?).
- 另外就是一开始先导出简单的模型测试, 这样可以暂时忽略掉其他复杂情况, 针对简单模型测试, 然后在测试复杂的模型.
最后快完成的时候, 遇到一个法线闪烁的问题, 也折腾了好久. 当去掉法线贴图之后就对了, 于是问题也能找到了: TBN quaternion的w保存的是镜像. 当这个quaterion被骨骼动画旋转的时候, w的符号可能会被改变.
所以要预先保存下这个镜像符号. 问题看起来确实很简单, 但是实际中有时候要定位到还是需要格外仔细小心. 下面是shader代码(line 28):
1 void MeshVSMain( 2 float4 pos : POSITION, 3 float4 tbn_quat : NORMAL0, //ubyte4-n compressed quaternion 4 float4 uv : TEXCOORD0, 5 #if defined(ENABLE_SKIN) 6 uint4 bones : BLENDINDICES0, 7 float4 weights : BLENDWEIGHT0, 8 #endif 9 10 uniform float4x4 wvp_matrix, 11 uniform float4x4 world_matrix, 12 13 out float4 outPos : POSITION, 14 out float4 outUV : TEXCOORD0, 15 out float4 outWorldPos : TEXCOORD1, 16 17 #if defined(ENABLE_NORMAL_MAP) 18 out float3 Tangent : TEXCOORD2, 19 out float3 BiTangent : TEXCOORD3, 20 out float3 Normal : TEXCOORD4 21 #else 22 out float3 outWorldNormal : TEXCOORD2 23 #endif 24 ) 25 { 26 tbn_quat = expand_vector(tbn_quat); 27 //tbn_quat = normalize(tbn_quat); 28 float w = sign(tbn_quat.w); //store sign before transform TBN, or w MAY CHANGE after skinning! 29 #if defined(ENABLE_SKIN) 30 skin_vertex_tbn_weight4(pos.xyz, tbn_quat, bones, weights); 31 //pos.xyz = skin_vertex_weight4(pos.xyz, bones, weights); 32 #endif 33 outPos = mul(pos, wvp_matrix); 34 outUV = uv; 35 outWorldPos = mul(pos,world_matrix); 36 37 #if defined(ENABLE_NORMAL_MAP) 38 //because the quaternion's interpolation is not linear (it is spherical linear interpolation) 39 //we need to extract the normal, tangent vector before pass to pixel shader. 40 41 //normal map: extract tbn 42 Tangent = qmul( tbn_quat, float3(1,0,0) ); 43 Normal = qmul( tbn_quat, float3(0,0,1) ); 44 45 //tangent space to world space 46 //note: world_matrix MUST only have uniform scale, or we have to use senmatic T(M-1) 47 Tangent = normalize( mul(Tangent, (float3x3)world_matrix) ); 48 Normal = normalize( mul(Normal, (float3x3)world_matrix) ); 49 BiTangent = normalize( cross(Normal, Tangent) ) * w; 50 #else 51 //vertex normal 52 //tangent space normal (0,0,1) to object space normal 53 outWorldNormal = qmul( tbn_quat, float3(0,0,1) ); 54 //then to world space 55 outWorldNormal = mul(outWorldNormal, (float3x3)world_matrix); 56 #endif 57 }
另外还遇到了C++里, 继承多个"空父类"时, MSVC的Empty Base Class Optimization失效的问题, 这个在我的C++博客:
http://hi.baidu.com/crazii_chn/item/5557deb54846b6f162388e30
原因是Empty Base Class Optimization在C++11之前都不是标准要求必须的, 所以编译器可以随便搞, 这里只能绕过去了.
4.动画的混合
使用动画树(animation blending tree), 暂时只写了接口和简单实现, 还没有使用和测试.
5.数据的优化
- 数据格式的选择: 目前位置使用的是Float16, 只保存xyz, 旋转使用的是Int16N, 精度应该满足需求, 如果不满足可以改为Float32, 而单位化的quaternion的w分量可以由xyz求得, 所以也只保存xyz:
typedef struct BoneTransformFormat : public TempAllocatable { int16 rotation_i16x3n[3]; fp16 position_f16x3[3]; fp32 time_pos; //uint32 frame_id; }BT_FMT; BSTATIC_ASSERT(sizeof(BT_FMT) == 16, "size/alignment error!");
可以看出, 目前单个骨骼的一个关键帧大小16字节. 这个数据只是加载/保存的中间/临时数据, 它会在加载时直接转为Dual Quaternion.
- 关键帧定义里面, 去掉无用的数据.
比如frame id, 一开始设计的时候加的, 后来发现没什么用处, 除了调试的时候拿来校验, 所以后来去掉了. 在动画非常多, 帧数非常多的时候, 因为基数很大, 所以减掉一个int也能省非常大的空间. - 去掉冗余的关键帧, 思路和参考在千里马干大大的博客, 很早在Azure的博客里也看到过, 后来地址失效了:
http://www.cnblogs.com/oiramario/archive/2010/12/22/1914120.html
原理文中有说明, 前面文章里我也记录过. 比如有A,B,C,三个关键帧, 根据A和C的插值结果, 与B比对, 如果非常近似, 那么可以去掉B.
在比对的时候, 要比对位置和旋转, 所以我用了两个precision threshold - 角度误差和位置误差, 来相对直观的控制精度. 对于根据骨骼节点深度加大精度误差的做法, 我也尝试了, 感觉差别不是很大.
代码见下:
#if OPTIMIZE_FRAME //accumulated error float accumAngle = Blade::Math::Degree2Radian(mConfig.mAngleError); float accumPos = mConfig.mPositionError; float angleThreshold = accumAngle / maxBoneDepth; float posThreshold = accumPos / maxBoneDepth; BoneKeyframeList::iterator start = keyFrames.begin(); for(int i = 0; i < mBoneList.size(); ++i) { size_t keyCount = keyCountList[i]; BoneKeyframeList::iterator iter = start + 1; for(size_t index = 1; index+1 < keyCount; ) { //assert( std::distance(start, iter) == index ); //debug too slow, uncomment if needed const KeyFrame& kf = *iter; const KeyFrame& prev = *(iter - 1); const KeyFrame& next = *(iter + 1); scalar t = (kf.getTimePos() - prev.getTimePos()) / (next.getTimePos() - prev.getTimePos()); assert( t > 0 && t < 1); //possibly iter position error across two bone key frame sequences BoneDQ interpolated = prev.getTransform(); interpolated.sclerpWith(next.getTransform(), t, true); interpolated.normalize(); const BoneDQ& dq = kf.getTransform(); if( interpolated.getRotation().equal(dq.getRotation(), angleThreshold) && interpolated.getTranslation().equal( dq.getTranslation(), posThreshold) ) { iter = keyFrames.erase(iter); --keyCount; } else { ++iter; ++index; } } keyCountList[i] = keyCount; start = iter; } #endif
目前最大累积角度误差默认取的是0.4角度, 最大累积位置误差取的是0.004个单位. 如果太大的话动画感觉很松动不流畅, 动作幅度也变小, 产生严重的失真. 这两个参数可以通过导出界面配置, 不过一般来说, 美术不需要修改.
- 采样率的选择. max默认的FPS是25, 记得以前看过一篇文章说, 人眼可以观察到的动画,极限FPS是30, 超过30以后, 人眼也看不出差别, 所以高于30没有意义. 我在网上搜到的动画采样配置, 有FPS=12的. 为了减少数据量, 个人觉得15FPS左右就可以, 剩下的数据在runtime插值出来. 除非对动画质量有很高的要求, 才需要使用30FPS. 事实上如果FPS>=30, 那么甚至可以不用runtime插值, 比如之前看到过的某些动画代码, 根本没有插值, 而是将时间直接转为frame id去索引关键帧.
通过以上方法, 之前那个70M可以减到20M的骨骼文件, litch king 阿尔萨斯, 在3ds max中有18195个关键帧. 现在在采样率为25的情况下, 骨骼文件大小为3.9M, 在采样率为15的情况下, 骨骼文件大小为2.9M, 而最终动画效果可以接受.
除此之外, 我们公司的动画, 在某些平台上, 还使用了一种变率(VBR)的浮点压缩方式, 不过没有仔细研究也没去搜paper, 大致原理是根据不同的浮点精度, 使用不同的位数来存放.这个确实蛮屌的,但是有精度损失, 可能会有轻微抖动.Blade暂时不使用这种方式.
6.运行时优化 Runtime Optimization
骨骼动画的计算是渲染中比较耗CPU的部分, 所以优化是必须的, 这是我目前想到的和已经做的优化:
- 使用SIMD, 这个我是把DirectXMath拿过来, 做了相对的调整, 跟DXTK的SimpleMath一样, 嵌入到已有的数学类里面, 做到无缝接合, 并且可以随时关闭(当然需要重编译). 经过测试, 效率确实要比编译器自动SSE优化的快.
- 数据紧凑 - Compact Data: 不使用节点, 使用有序数组提高cache效率, 这样更能够发挥SIMD的优势.
因为骨骼节点嘛, 通常都会先想到Node, 事实上需要传入shader的, 只是一个数组. 通常树的节点遍历, 有大量的间接寻址和函数调用. 使用有序数组的cache效率会更高, 甚至可以把这个计算结果直接传给shader.
比如Ogre的Bone, 是继承自基类Node, 本身Node类就很庞大复杂, 导致Bone的虽然代码简单, 但是实际上数据很复杂, 有很多冗余成员数据. 关于复用, 我个人觉得, 除了基础代码尽量复用以外, 任何时候, 复用的都最好是接口(设计), 这样才能减少代码的侵入性, 减少掣肘, 使得子模块高度定制, 保证其有简单高效的实现.
整个骨骼的遍历是要求有顺序的, 如果用树表示的话, 是先根遍历(兄弟之间无所谓), 如果用数组就需要排序.
还记得数据结构里面的"二叉树的数组表示"法么?
然而, 即便是数组表示的树, 普通的Node有额外的信息, 比如兄弟指针(索引),父指针(索引)等等, 而传入shdader的BonePalette也只是一个DQ数组(以前喜欢叫bone matrices, 现在用了DQ,虽然代码里面叫BoneDQ, 但Bone Palette是更一般的叫法).
如果想只使用DQ数组, 就得把父节点这些数据单独分开存放(毕竟这些是写在资源里的固定数据,所以不难), 而且要预先排序, 而不需要显式的父子顺序, 然后按顺序计算更新就可以了.
因为boneIndices是预生成以后保存在模型/骨骼数据里面的,shader里面要用它索引BonePalette, 所以运行时不能再排序, 否则索引就会出错. 所以这个在导出时排序最好: 把父节点放在子节点之前(兄弟之间无所谓), 这样的顺序不是严格有序, 但是足够满足需求了.
1 struct BoneCollector : public ITreeEnumProc 2 { 3 BoneList& listRef; 4 BoneCollector(BoneList& list) :listRef(list){} 5 6 virtual int callback(INode* node) 7 { 8 if( IsBoneNode(node) ) 9 { 10 IGameScene* game = ::GetIGameInterface(); 11 listRef.push_back( game->GetIGameNode(node) ); 12 } 13 return TREE_CONTINUE; 14 } 15 }collector(mBoneList); 16 ei->theScene->EnumTree(&collector); 17 18 //important: sort bones so that parent comes first, this is an optimization for animation runtime 19 struct FnIGameBoneCompare 20 { 21 //check if rhs is descendant of lhs 22 inline bool isDescendant(IGameNode* left, IGameNode* right) const 23 { 24 while(right->GetNodeParent() != NULL) 25 { 26 right = right->GetNodeParent(); 27 if( left == right ) 28 return true; 29 } 30 return false; 31 } 32 33 bool operator()(IGameNode* lhs, IGameNode* rhs) const 34 { 35 if( this->isDescendant(lhs, rhs) ) 36 return true; 37 else 38 return false; 39 } 40 }; 41 42 std::sort( mBoneList.begin(), mBoneList.end(), FnIGameBoneCompare() );
运行时, 更新完动画混合/插值以后, 只需要按顺序更新数组就可以了, 有先天的cache优势:
1 //update bone hierarchy & calculate bone transforms 2 for(size_t i = 0; i < boneCount; ++i) 3 { 4 mBoneDQ[i].normalize(); 5 6 //apply hierarchy 7 uint32 parent = boneData[i].mParent; 8 if( parent != uint32(-1) ) 9 { 10 //bones already sorted in linear order (by animation exporter), parent always calculated before children 11 assert( parent < (uint32)i ); 12 //apply hierarchy: 13 14 //note: parent is already applied inversed binding pose, need to get it back 15 const BoneDQ& parentBindingPose = boneData[parent].mInitialPose; 16 mBoneDQ[i] = mBoneDQ[parent]*mBoneDQ[i]; 17 } 18 else 19 ;//mBoneDQ[i] = mBoneDQ[i]; 20 } 21 22 //apply animations 23 for(size_t i = 0; i < boneCount; ++i) 24 { 25 //reset bone matrices to init pose (T pose) to prepare animation 26 const BoneDQ& tposeDQ = boneData[i].mInitialPose; 27 28 //note: tposeDQ is normalized after loading and never modified 29 //and Inverse(dq) == Conjugate(dq), if dq is normalized 30 BoneDQ inversedBindingPose = tposeDQ.getConjugate(); 31 32 mBoneDQ[i] = mBoneDQ[i]*inversedBindingPose; 33 } 34 }
-
单遍遍历: 避免多次内存访问, 因为多以次遍历的话, CPU流水线可能需要reload cache, 这个过程可能要比数学指令慢很多. 这处修改还没有profile, 有空的话去看看这个做法到底对不对.
现在是One Pass就完成了所有的Bone Palette Update了, 不过有冗余的计算(基于上面代码做了简单修改):1 //update bone hierarchy & calculate bone transforms 2 for(size_t i = 0; i < boneCount; ++i) 3 { 4 mBoneDQ[i].normalize(); 5 6 //reset bone matrices to init pose (T pose) to prepare animation 7 const BoneDQ& tposeDQ = boneData[i].mInitialPose; 8 9 //note: tposeDQ is normalized after loading and never modified 10 //and Inverse(dq) == Conjugate(dq), if dq is normalized 11 BoneDQ inversedBindingPose = tposeDQ.getConjugate(); 12 13 //apply hierarchy & animations 14 uint32 parent = boneData[i].mParent; 15 if( parent != uint32(-1) ) 16 { 17 //bones already sorted in linear order (by animation exporter), parent always calculated before children 18 assert( parent < (uint32)i ); 19 //apply hierarchy: 20 21 //note: parent is already applied inversed binding pose, need to get it back 22 const BoneDQ& parentBindingPose = boneData[parent].mInitialPose; 23 mBoneDQ[i] = (mBoneDQ[parent]*parentBindingPose)*mBoneDQ[i]*inversedBindingPose; 24 } 25 else 26 mBoneDQ[i] = mBoneDQ[i]*inversedBindingPose; 27 } 28 }
这样, 计算出的结果可以直接丢给shader, 一个动画的所有mesh只需要传一次shader就可以了.
不过这样做的话, 整个动画的骨骼数量就太受限了. 为了突破骨骼数量限制, 可以像Ogre那样, 对于每个mesh保存一个shader cache, 每个mesh从骨骼的计算结果里复制需要的数据, 传一次shader constant, 这样每个mesh的骨骼数量有限制, 但是整个动画没有了. -
在需要的地方加上必要的memory prefetch.
- 另外还可以考虑多线程, 这个目前没有计划.
7. UI
UI遇到了一些恶心的问题, 主要是之前的UI不满足需求...
proerpty grid + 数据绑定遇到的问题:
动画列表想用下拉框, 但是无法实现. 目前数据绑定的下拉列表选项是固定的, 选中的选项被绑定到类成员数据或者函数上. 但是动画的列表不是静态的, 需要跟绑定对象关联, 才能做到.
这个功能在现有机制上可以添加, 但是不想改UI了, 所以改用其他方式:
用collection的数据绑定, 可以展开多个item, 选中item的事件在编辑端处理, 并发送动画变更给动画组件, 完成动画的切换.
导出动画的配置界面, 也需要复杂的UI. 比如单个动画序列, 需要有名字,起始帧,结束帧, 是否循环等等, 如果要导出多个动画, 现有的UI很难满足需求.目前的workaround是导出多个动画序列时, 使用配置文件...不过由于动画可能是由不同的artist制作的, 而且在游戏开发过程中, 会不停加入新内容, 所以一般最好的方式是一个一个导出, 然后用工具合并, 想到这里, 就暂时没有改动UI了, 勉强先这样用.
trackview - 简单的接口定义. 为了实现UI与具体的逻辑解耦, 即UI可以handle不同类型的数据, 比如以后的过场动画(CutScene即in-game cinematic)的视轨编辑, 做了以下抽象:
1 /************************************************************************/ 2 /* */ 3 /************************************************************************/ 4 class ITrack 5 { 6 public: 7 typedef enum ETrackFeature 8 { 9 TF_SEEK = 0x00000001, 10 TF_SETLENGTH= 0x00000002, 11 TF_KEYFRAME = 0x00000004|TF_SEEK, 12 TF_ADDKEY = 0x00000008|TF_KEYFRAME, 13 TF_REMOVEKEY= 0x000000010|TF_KEYFRAME, 14 }FEATURE_MASK; 15 public: 16 /* @brief */ 17 virtual scalar getDuration() const = 0; 18 /* @brief get current play pos */ 19 virtual scalar getPosition() const = 0; 20 /* @brief FEATURE_MASK */ 21 virtual int getFeatures() const = 0; 22 23 /* @brief */ 24 virtual bool play() = 0; 25 /* @brief */ 26 virtual bool pause() = 0; 27 /* @brief */ 28 virtual bool isPlaying() const = 0; 29 30 /* @brief get current animation name, if have any */ 31 virtual const tchar* getCurrentAnimation() const {return NULL;} 32 33 /* @brief TF_SEEK */ 34 virtual bool setPosition(scalar pos) {BLADE_UNREFERENCED(pos); return false;} 35 36 /* @brief TF_SETLENGTH */ 37 virtual bool setDuration(scalar length) {BLADE_UNREFERENCED(length); return false;} 38 39 /* @brief TF_KEYFRAME */ 40 virtual size_t getKeyFrameCount() const {return 0;} 41 virtual scalar getKeyFrame() const {return 0;} 42 43 /* @brief TF_ADDKEY */ 44 virtual index_t addKeyFrame(scalar pos) {BLADE_UNREFERENCED(pos); return INVALID_INDEX;} 45 46 /* @brief TF_REMOVEKEY */ 47 virtual bool removeKeyFrame(index_t index){BLADE_UNREFERENCED(index); return false;} 48 49 };//class ITrack 50 51 52 /************************************************************************/ 53 /* */ 54 /************************************************************************/ 55 class BLADE_EDITOR_API ITrackManager : public InterfaceSingleton<ITrackManager> 56 { 57 public: 58 virtual ~ITrackManager() {} 59 60 /* @brief */ 61 virtual size_t getTrackCount() const = 0; 62 63 /* @brief get bound track */ 64 virtual ITrack* getTrack(index_t index) const = 0; 65 66 /* @brief */ 67 virtual index_t getTrackIndex(ITrack* track) const = 0; 68 69 /* @brief bind track to view */ 70 virtual bool addTrack(ITrack* track) = 0; 71 72 /* @brief */ 73 virtual bool removeTrack(index_t index) = 0; 74 inline bool removeTrack(ITrack* track) 75 { 76 return this->removeTrack(this->getTrackIndex(track)); 77 } 78 };
有了以上接口, 就可以绑定到给UI, 用来显示和多动播放进度等等. 当然目前的设计还很简单, 需要继续完善, 比如多个track的编辑和插入关键帧,编辑关键帧等等. 其实要做好这一块还是很难的, 如果要兼顾复杂度和用户体验的话, 需要花精力慢慢做.
trackview的实现, 这个没什么说的了. 但是遇到了一个有点诡异的东西: MFC的 CSlider事件, 用NM_CUSTOMDRAW不行. 比如CEdit的EN_SELCHANGE, 只有用户改变的时候才会发消息, 而CSlider的NM_CUSTOMDRAW, 代码里更改了slider的位置, 也会发这个消息, 这不符合需求. 最后用的是Scroll事件 - 是的, CSlider会给父窗口发滚动事件. 最诡异的就是这里的强制类型转换, 把输入参数CScrollBar转换为CSlider.
1 void CTrackViewUI::OnHScroll(UINT /*nSBCode*/, UINT /*nPos*/, CScrollBar* pScrollBar) 2 { 3 if( mTrack != NULL && (mTrack->getFeatures()&ITrack::TF_SEEK) ) 4 { 5 CSliderCtrl* slider = reinterpret_cast<CSliderCtrl*>( pScrollBar ); 6 assert( slider == this->GetDlgItem(IDC_TRACKVIEW_TRACK) ); //this is the only slider/scrollbar we have. 7 if( slider != NULL ) 8 { 9 int pos = slider->GetPos(); 10 mTrack->pause(); 11 mTrack->setPosition( (scalar)pos / (scalar)mFPS ); 12 this->updateUI(true); 13 } 14 } 15 }
这里的reinterpret_cast (line 5) 有点诡异和丑陋, 明显有点生硬的感觉, 但是还好有详细的文档 http://msdn.microsoft.com/en-us/library/ekx9yz55.aspx.
所以MS的开发者友好度大赞, 比android什么的强了不止几倍, 不过MSDN也是积累了n年才有如此好的开发生态圈, android目前确实比不了.
8.遗留问题
- 目前骨骼数量定的是120, 对于256个vs constant, 除了骨骼变换数组占用的120x2=240个, 还剩下16个, 虽然有点少, 目前够用了, 没有什么问题. 如果单个mesh的骨骼数量太多(> 120), 需要分割mesh, 拆分到多个draw call里, 这个暂时先不做.
- 动画混合树: 这个以后慢慢完善.
- 动画合并工具: 这个准备作为模型浏览器(modelviewer)插件的一个功能, 集成在编辑器里, 以后慢慢完善.
- IK, 下一步着手去做.
最后还是惯例, 发截图: