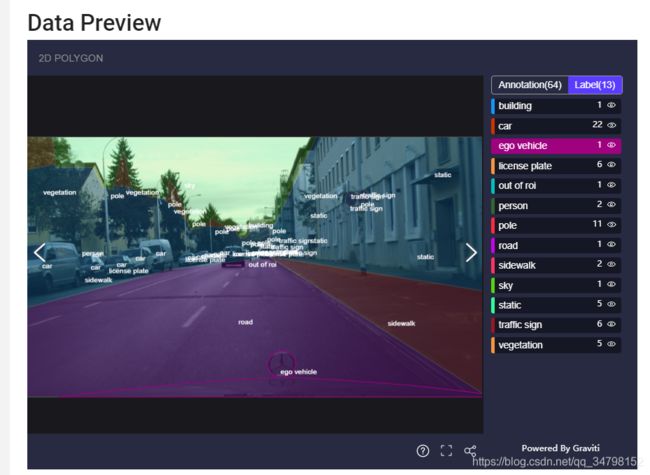
cityscapes数据集
一:下载:
官方网站:Semantic Understanding of Urban Street Scenes
以下下载内容来自(https://zhuanlan.zhihu.com/p/147195575)
下载前3个文件即可。
其中3文件代表训练使用的原图,1文件代表精细标注label,2文件代表非精细标注label。
有的同学要问了,那我下载1、3不就行了吗?我要这2有何用?
其实Cityscapes数据集提供了34种分类,但有时我们不需要那么多,比如仅需要19分类(默认的)或任意多个分类,进行图像语意分割的神经网络训练,我们就需要用到他Cityscapes提供的自带工具进行label的转换,若缺少2文件,转换代码会报错无法进行。

没有账号的淘宝买edu账号
二:数据集处理:
官方处理脚本:https://github.com/mcordts/cityscapesScripts
上不了github的,翻不了的改host
一下两步操作来自:https://blog.csdn.net/weixin_41950276/article/details/89930940
2. 修改路径到gtFine文件夹的上一层
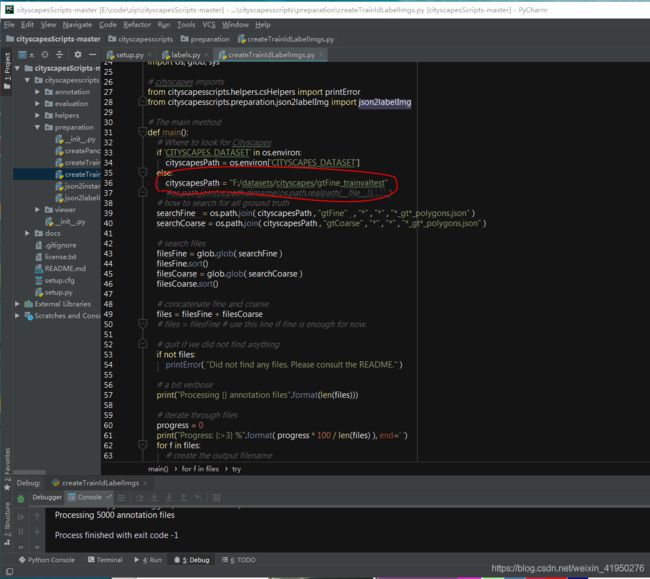
3. 接着直接运行createTrainIdLabelImgs.py文件
labels解析:
labels = [
# name id trainId category catId hasInstances ignoreInEval color
Label( 'unlabeled' , 0 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'ego vehicle' , 1 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'rectification border' , 2 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'out of roi' , 3 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'static' , 4 , 255 , 'void' , 0 , False , True , ( 0, 0, 0) ),
Label( 'dynamic' , 5 , 255 , 'void' , 0 , False , True , (111, 74, 0) ),
Label( 'ground' , 6 , 255 , 'void' , 0 , False , True , ( 81, 0, 81) ),
Label( 'road' , 7 , 0 , 'flat' , 1 , False , False , (128, 64,128) ),
Label( 'sidewalk' , 8 , 1 , 'flat' , 1 , False , False , (244, 35,232) ),
Label( 'parking' , 9 , 255 , 'flat' , 1 , False , True , (250,170,160) ),
Label( 'rail track' , 10 , 255 , 'flat' , 1 , False , True , (230,150,140) ),
Label( 'building' , 11 , 2 , 'construction' , 2 , False , False , ( 70, 70, 70) ),
Label( 'wall' , 12 , 3 , 'construction' , 2 , False , False , (102,102,156) ),
Label( 'fence' , 13 , 4 , 'construction' , 2 , False , False , (190,153,153) ),
Label( 'guard rail' , 14 , 255 , 'construction' , 2 , False , True , (180,165,180) ),
Label( 'bridge' , 15 , 255 , 'construction' , 2 , False , True , (150,100,100) ),
Label( 'tunnel' , 16 , 255 , 'construction' , 2 , False , True , (150,120, 90) ),
Label( 'pole' , 17 , 5 , 'object' , 3 , False , False , (153,153,153) ),
Label( 'polegroup' , 18 , 255 , 'object' , 3 , False , True , (153,153,153) ),
Label( 'traffic light' , 19 , 6 , 'object' , 3 , False , False , (250,170, 30) ),
Label( 'traffic sign' , 20 , 7 , 'object' , 3 , False , False , (220,220, 0) ),
Label( 'vegetation' , 21 , 8 , 'nature' , 4 , False , False , (107,142, 35) ),
Label( 'terrain' , 22 , 9 , 'nature' , 4 , False , False , (152,251,152) ),
Label( 'sky' , 23 , 10 , 'sky' , 5 , False , False , ( 70,130,180) ),
Label( 'person' , 24 , 11 , 'human' , 6 , True , False , (220, 20, 60) ),
Label( 'rider' , 25 , 12 , 'human' , 6 , True , False , (255, 0, 0) ),
Label( 'car' , 26 , 13 , 'vehicle' , 7 , True , False , ( 0, 0,142) ),
Label( 'truck' , 27 , 14 , 'vehicle' , 7 , True , False , ( 0, 0, 70) ),
Label( 'bus' , 28 , 15 , 'vehicle' , 7 , True , False , ( 0, 60,100) ),
Label( 'caravan' , 29 , 255 , 'vehicle' , 7 , True , True , ( 0, 0, 90) ),
Label( 'trailer' , 30 , 255 , 'vehicle' , 7 , True , True , ( 0, 0,110) ),
Label( 'train' , 31 , 16 , 'vehicle' , 7 , True , False , ( 0, 80,100) ),
Label( 'motorcycle' , 32 , 17 , 'vehicle' , 7 , True , False , ( 0, 0,230) ),
Label( 'bicycle' , 33 , 18 , 'vehicle' , 7 , True , False , (119, 11, 32) ),
Label( 'license plate' , -1 , -1 , 'vehicle' , 7 , False , True , ( 0, 0,142) ),
]trainId就是标签的像素值,
不感兴趣的类,就将trainId设为255,ignoreInEval设为True(https://blog.csdn.net/chenzhoujian_/article/details/106874950)
三:评估和文件夹详解:
https://blog.csdn.net/nefetaria/article/details/105728008
python数据读取:(前提是创建了createTrainIdLabelImgs产生了 *labelTrainIds.png的图片,如无产生,自行更改即可)
一:创建list
# -*- coding: utf-8 -*-
import os
import glob
root_path=os.path.expanduser('./cityscapes')
image_path='leftImg8bit'
annotation_path='gtFine'
splits=['train','val','test']
#train glob images 2975
#train glob annotations 2975
#val glob images 500
#val glob annotations 500
#test glob images 1525
#test glob annotations 1525
for split in splits:
glob_images=glob.glob(os.path.join(root_path,image_path,split,'*','*leftImg8bit.png'))
glob_annotations=glob.glob(os.path.join(root_path,annotation_path,split,'*','*labelTrainIds.png'))
print('%s glob images'%split,len(glob_images))
print('%s glob annotations'%split,len(glob_annotations))
write_file=open('./cityscapes/cityscapes_'+split+'_list.txt','w')
for g_img in glob_images:
#img_p: eg leftImg8bit/val/frankfurt/frankfurt_000001_083852_leftImg8bit.png
#ann_p: eg gtFine/val/frankfurt/frankfurt_000001_083852_gtFine_labelTrainIds.png
img_p=g_img.replace(root_path+'/','')
#replace will not change img_p
ann_p=img_p.replace('leftImg8bit/','gtFine/').replace('leftImg8bit.png','gtFine_labelTrainIds.png')
assert os.path.join(root_path,img_p) in glob_images,'%s not exist'%img_p
assert os.path.join(root_path,ann_p) in glob_annotations,'%s not exist'%ann_p
write_file.write(img_p+' '+ann_p+'\n')
write_file.close()
二:读取
import os.path as osp
import numpy as np
import random
import cv2
from torch.utils import data
import pickle
class CityscapesDataSet(data.Dataset):
"""
CityscapesDataSet is employed to load train set
Args:
root: the Cityscapes dataset path,
cityscapes
├── gtFine
├── leftImg8bit
list_path: cityscapes_train_list.txt, include partial path
mean: bgr_mean (73.15835921, 82.90891754, 72.39239876)
"""
def __init__(self, root='', list_path='', max_iters=None,
crop_size=(512, 1024), mean=(128, 128, 128), scale=True, mirror=True, ignore_label=255):
self.root = root
self.list_path = list_path
self.crop_h, self.crop_w = crop_size
self.scale = scale
self.ignore_label = ignore_label
self.mean = mean
self.is_mirror = mirror
self.img_ids = [i_id.strip() for i_id in open(list_path)]
if not max_iters == None:
self.img_ids = self.img_ids * int(np.ceil(float(max_iters) / len(self.img_ids)))
self.files = []
# for split in ["train", "trainval", "val"]:
for name in self.img_ids:
img_file = osp.join(self.root, name.split()[0])
# print(img_file)
label_file = osp.join(self.root, name.split()[1])
# print(label_file)
self.files.append({
"img": img_file,
"label": label_file,
"name": name
})
print("length of dataset: ", len(self.files))
def __len__(self):
return len(self.files)
def __getitem__(self, index):
datafiles = self.files[index]
image = cv2.imread(datafiles["img"], cv2.IMREAD_COLOR)
label = cv2.imread(datafiles["label"], cv2.IMREAD_GRAYSCALE)
size = image.shape
name = datafiles["name"]
if self.scale:
scale = [0.75, 1.0, 1.25, 1.5, 1.75, 2.0]
f_scale = scale[random.randint(0, 5)]
# f_scale = 0.5 + random.randint(0, 15) / 10.0 # random resize between 0.5 and 2
image = cv2.resize(image, None, fx=f_scale, fy=f_scale, interpolation=cv2.INTER_LINEAR)
label = cv2.resize(label, None, fx=f_scale, fy=f_scale, interpolation=cv2.INTER_NEAREST)
image = np.asarray(image, np.float32)
image -= self.mean
# image = image.astype(np.float32) / 255.0
image = image[:, :, ::-1] # change to RGB
img_h, img_w = label.shape
pad_h = max(self.crop_h - img_h, 0)
pad_w = max(self.crop_w - img_w, 0)
if pad_h > 0 or pad_w > 0:
img_pad = cv2.copyMakeBorder(image, 0, pad_h, 0,
pad_w, cv2.BORDER_CONSTANT,
value=(0.0, 0.0, 0.0))
label_pad = cv2.copyMakeBorder(label, 0, pad_h, 0,
pad_w, cv2.BORDER_CONSTANT,
value=(self.ignore_label,))
else:
img_pad, label_pad = image, label
img_h, img_w = label_pad.shape
h_off = random.randint(0, img_h - self.crop_h)
w_off = random.randint(0, img_w - self.crop_w)
# roi = cv2.Rect(w_off, h_off, self.crop_w, self.crop_h);
image = np.asarray(img_pad[h_off: h_off + self.crop_h, w_off: w_off + self.crop_w], np.float32)
label = np.asarray(label_pad[h_off: h_off + self.crop_h, w_off: w_off + self.crop_w], np.float32)
image = image.transpose((2, 0, 1)) # NHWC -> NCHW cv2.imread读取彩色图像后得到的格式是BGR格式,像素值范围在0~255之间,通道格式为(H,W,C)
if self.is_mirror:#随机翻转
flip = np.random.choice(2) * 2 - 1
image = image[:, :, ::flip]
label = label[:, ::flip]
return image.copy(), label.copy(), np.array(size), name
class CityscapesValDataSet(data.Dataset):
"""
CityscapesDataSet is employed to load val set
Args:
root: the Cityscapes dataset path,
cityscapes
├── gtFine
├── leftImg8bit
list_path: cityscapes_val_list.txt, include partial path
"""
def __init__(self, root='',
list_path='',
f_scale=1, mean=(128, 128, 128), ignore_label=255):
self.root = root
self.list_path = list_path
self.ignore_label = ignore_label
self.mean = mean
self.f_scale = f_scale
self.img_ids = [i_id.strip() for i_id in open(list_path)]
self.files = []
for name in self.img_ids:
img_file = osp.join(self.root, name.split()[0])
# print(img_file)
label_file = osp.join(self.root, name.split()[1])
# print(label_file)
image_name = name.strip().split()[0].strip().split('/', 3)[3].split('.')[0]
# print("image_name: ",image_name)
self.files.append({
"img": img_file,
"label": label_file,
"name": image_name
})
print("length of dataset: ", len(self.files))
def __len__(self):
return len(self.files)
def __getitem__(self, index):
datafiles = self.files[index]
image = cv2.imread(datafiles["img"], cv2.IMREAD_COLOR)
label = cv2.imread(datafiles["label"], cv2.IMREAD_GRAYSCALE)
size = image.shape
name = datafiles["name"]
if self.f_scale != 1:
image = cv2.resize(image, None, fx=self.f_scale, fy=self.f_scale, interpolation=cv2.INTER_LINEAR)
label = cv2.resize(label, None, fx=self.f_scale, fy=self.f_scale, interpolation=cv2.INTER_NEAREST)
image = np.asarray(image, np.float32)
image -= self.mean
# image = image.astype(np.float32) / 255.0
image = image[:, :, ::-1] # change to RGB
image = image.transpose((2, 0, 1)) # HWC -> CHW
# print('image.shape:',image.shape)
return image.copy(), label.copy(), np.array(size), name
class CityscapesTestDataSet(data.Dataset):
"""
CityscapesDataSet is employed to load test set
Args:
root: the Cityscapes dataset path,
list_path: cityscapes_test_list.txt, include partial path
"""
def __init__(self, root='',
list_path='', mean=(128, 128, 128),
ignore_label=255):
self.root = root
self.list_path = list_path
self.ignore_label = ignore_label
self.mean = mean
self.img_ids = [i_id.strip() for i_id in open(list_path)]
self.files = []
for name in self.img_ids:
img_file = osp.join(self.root, name.split()[0])
# print(img_file)
image_name = name.strip().split()[0].strip().split('/', 3)[3].split('.')[0]
# print(image_name)
self.files.append({
"img": img_file,
"name": image_name
})
print("lenth of dataset: ", len(self.files))
def __len__(self):
return len(self.files)
def __getitem__(self, index):
datafiles = self.files[index]
image = cv2.imread(datafiles["img"], cv2.IMREAD_COLOR)
name = datafiles["name"]
image = np.asarray(image, np.float32)
size = image.shape
image -= self.mean
# image = image.astype(np.float32) / 255.0
image = image[:, :, ::-1] # change to RGB
image = image.transpose((2, 0, 1)) # HWC -> CHW
return image.copy(), np.array(size), name
class CityscapesTrainInform:
""" To get statistical information about the train set, such as mean, std, class distribution.
The class is employed for tackle class imbalance.
"""
def __init__(self, data_dir='', classes=19,
train_set_file="", inform_data_file="", normVal=1.10):
"""
Args:
data_dir: directory where the dataset is kept
classes: number of classes in the dataset
inform_data_file: location where cached file has to be stored
normVal: normalization value, as defined in ERFNet paper
"""
self.data_dir = data_dir
self.classes = classes
self.classWeights = np.ones(self.classes, dtype=np.float32)
self.normVal = normVal
self.mean = np.zeros(3, dtype=np.float32)
self.std = np.zeros(3, dtype=np.float32)
self.train_set_file = train_set_file
self.inform_data_file = inform_data_file
def compute_class_weights(self, histogram):
"""to compute the class weights
Args:
histogram: distribution of class samples
"""
normHist = histogram / np.sum(histogram)
for i in range(self.classes):
self.classWeights[i] = 1 / (np.log(self.normVal + normHist[i]))
def readWholeTrainSet(self, fileName, train_flag=True):
"""to read the whole train set of current dataset.
Args:
fileName: train set file that stores the image locations
trainStg: if processing training or validation data
return: 0 if successful
"""
global_hist = np.zeros(self.classes, dtype=np.float32)
no_files = 0
min_val_al = 0
max_val_al = 0
with open(self.data_dir + '/' + fileName, 'r') as textFile:
# with open(fileName, 'r') as textFile:
for line in textFile:
# we expect the text file to contain the data in following format
# 一张绝妙的图帮你分析: