opencv实战---人脸检测与出勤项目
face_recognition应该是最简单的开源人脸识别库,关于face_recognition的详细介绍,请参考这位博主写的。
face_recognition后面使用的分类器是支持向量机(SVM),属于经典解决分类问题的机器学习算法之一,但准确率不那么高。
目录
face_recognition依赖的相关下载:
(一)Visual Studio的安装(安装包链接放最后)
(二)相关库的安装
针对原理进行简单的程序编写:
基于人脸检测的出勤项目:
导入图像:
编写方法对图片进行编码:
导入未知的图片,比较差值
框出人脸,放置识别结果(识别的名字)
出勤表的制作:
所有的资源链接(包含软件、库、程序、程序用到的图片和视频):
总结:
由于在pycharm里面并不包含face_recognition,所以需要外部的一些东西导入。
face_recognition依赖的相关下载:
(一)Visual Studio的安装(安装包链接放最后)
dlib在Windows系统下的编译依赖于Visual C++,所以需要安装Visual Studio,为dlib的安装提供Visual C++编译器支持。记得勾选这个“使用C++的桌面开发”。
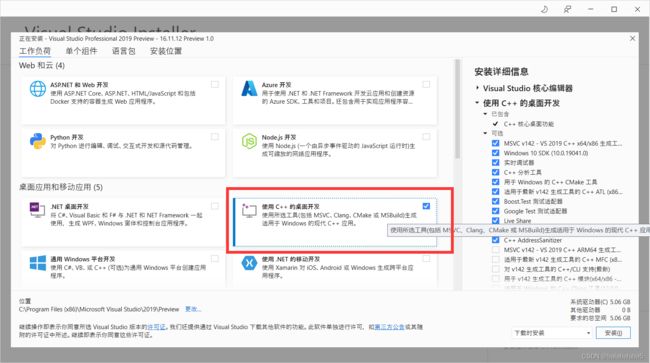
安装Visual Studio可能遇到的问题和解决方案:
停留在这个界面,进度条始终不动,最后会提示网络有问题,但事实上是联网了。
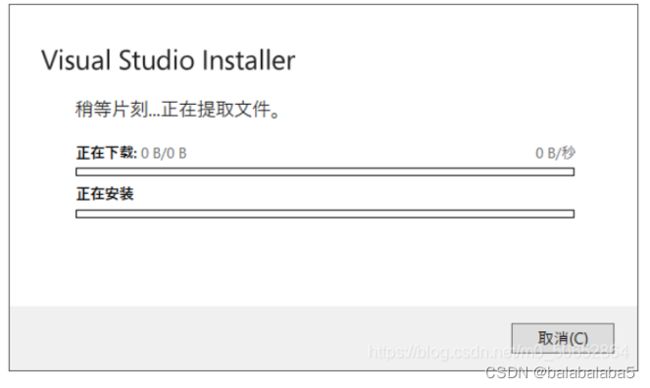
解决方法步骤:
鼠标右键单击桌面右下角WiFi图案,打开“网络和lnternet设置”。
打开“网络和共享中心”。
点进你连接的WiFi。 点进你连接的无线网络。
点击“属性”。
点击“Internet协议版本4 (TCP/IPv4) ”。点击“属性”。
点击“使用下面的DNS服务器地址”。
将“首选DNS服务器”改为114.114.114.114。将“备用DNS服务器”改为8.8.8.8。
点击“确定”。
完成。
(二)相关库的安装
- 安装cmake库:这个库的安装毫无障碍,跟往常一样使用pip install cmake的命令即可。
- 下载dlib和face_recognition。
然而,在下载dlib的时候总会出现触目惊心的红色ERROR。

如果dlib安装不了,就会导致人脸检测项目里最重要的face_recognition库也无法下载。
我参考了无数的博主方法,终于安装好了。但过程比较繁琐,我还是将这两个库打包在一起,做该项目的时候放进虚拟环境里的site-packages文件夹下即可。链接放在最后。
另外:
这种投机取巧安装dlib和 face_recognition的方式,在导入库的时候会出现新的ERROR:

![]()
那么就在终端或者cmd,根据提示下载numpy、click、pillow。无论在运行下面三条命令时,控制台报什么错,都无需搭理。
pip install pillow -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install click -i https://pypi.tuna.tsinghua.edu.cn/simple
因为face_recognition的使用需要依赖这些,在常规下载dlib和 face_recognition的时候,系统会自动下载这些库。但在咱们这种方式下,就得自己手动的去安装了。
以上都是为了安装 face_recognition所做的努力。
针对原理进行简单的程序编写:
接下来,就开始描述程序的编写了。
原理:使用face_recognition做到人脸检测,只需4步。
- 找出所有的面孔
- 使用特征点矫正姿态,将侧脸转为正脸
- 根据面部特征点计算这个面孔的特征值(特征向量)
- 与已知面孔进行特征值比对,看是否可以寻找到匹配的面孔
import face_recognition
import cv2
# 导入两张已知面孔的图像(苏醒和王栎鑫的图片),并将其转换成RGB格式
imgSu = face_recognition.load_image_file('pic/Su_xing.jpeg') # 导入图片
imgSu = cv2.cvtColor(imgSu, cv2.COLOR_BGR2RGB) #将BGR图片转换成RGB图片
imgWang = face_recognition.load_image_file('pic/Wang_yue_xing.jpeg') # 导入测试的图片
imgWang = cv2.cvtColor(imgWang, cv2.COLOR_BGR2RGB) #将BGR图片转换成RGB图片
# 找到已知图像人脸的位置,并框出来
faceLocSu = face_recognition.face_locations(imgSu)[0]
cv2.rectangle(imgSu, (faceLocSu[3],faceLocSu[0]),(faceLocSu[1],faceLocSu[2]),(255, 0, 0), 2)
faceLocWang = face_recognition.face_locations(imgWang)[0]
cv2.rectangle(imgWang, (faceLocWang[3],faceLocWang[0]),(faceLocWang[1],faceLocWang[2]),(255, 0, 0), 2)
# 对已知图像进行编码,并存进数组里
encodeSu = face_recognition.face_encodings(imgSu)[0]
encodeWang = face_recognition.face_encodings(imgWang)[0]
know_encode = [encodeSu,encodeWang]
# 加载一张未知人脸的图像,用作检测。重复以上的步骤
imgTest = face_recognition.load_image_file('pic/huGe.png') # 导入图片
imgTest = cv2.cvtColor(imgTest, cv2.COLOR_BGR2RGB) #将BGR图片转换成RGB图片
faceLocTest = face_recognition.face_locations(imgTest)[0] # 找到位置
cv2.rectangle(imgTest, (faceLocTest[3],faceLocTest[0]),(faceLocTest[1],faceLocTest[2]),(255, 0, 0), 2)
encodeTest = face_recognition.face_encodings(imgTest)[0] # 编码
# 比较未知图片和已知图片的面孔距离
results = face_recognition.compare_faces(know_encode, encodeTest)
faceDis = face_recognition.face_distance(know_encode, encodeTest)
print(results,faceDis)
cv2.imshow('SU',imgSu)
cv2.imshow('wang',imgWang)
cv2.imshow('test',imgTest)
cv2.waitKey(0)
我这已知的面孔是苏醒和王栎鑫的,未知的面孔是胡歌的。
运行结果:
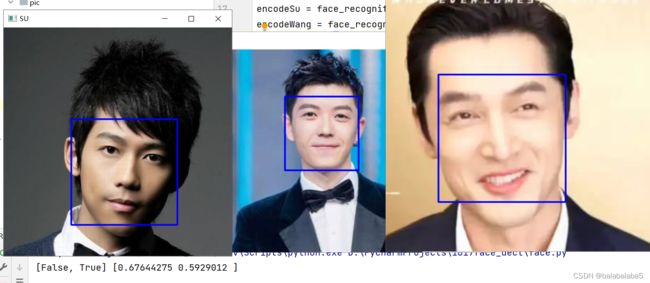
运行结果的含义就是能否在已知的面孔库里面匹配到相似的面孔。
胡歌的脸部差异和苏醒的达到了0.676,所以不能认为是一个人;和王栎鑫的达到了0.592,可以认为是一个人。(机器学习就是这样,算法没有使用大量的原始图片进行训练学习,测试结果差强人意也是很常见的事)。
基于人脸检测的出勤项目:
导入图像:

如果每次都需要像上面这样去导入图片,就过于繁琐了。所以自己创建一个可以从指定文件夹中读取图片的列表。
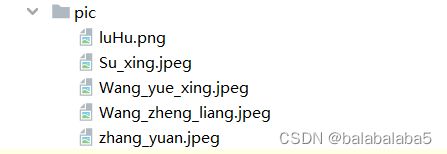
在网上找了“再就业男团”的图片,并且为每张图片写上了对应的名字,存在pic文件夹内。
path = 'pic'
images = []
classNames = []
myList = os.listdir(path)
print(myList)
for cl in myList:
curImg = cv2.imread(f'{path}/{cl}')
images.append(curImg)
classNames.append(os.path.splitext(cl)[0])
print(classNames)
- images存放图片;
- classNames存放名字;
- myList里面包含了所有图片的名称:['luHu.png', 'Su_xing.jpeg', 'Wang_yue_xing.jpeg', 'Wang_zheng_liang.jpeg', 'zhang_yuan.jpeg']
- cl是每一张图片的名称(比如luHu.png),和path一起组成了路径。使用cv2.imread()函数进行读取。
- os.path.splitext(cl)[0]:对图片名称进行分割,获取到第一部分的名字(比如luHu)
- 所以最后的classNames包含:['luHu', 'Su_xing', 'Wang_yue_xing', 'Wang_zheng_liang', 'zhang_yuan']
编写方法对图片进行编码:
书写方法的原因就是为了后续可以直接调用:
def findEncodings(images):
encodeList = []
for img in images:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
encode = face_recognition.face_encodings(img)[0]
encodeList.append(encode)
return encodeListimages里面存放了文件夹里面所有的图片,使用for循环,以便一张一张地处理。
opencv读入的图片格式都是BGR格式的,咱们还得将其转换为RGB格式。
将图片的编码数据存进encodeList这个数据库(数组)里,以供匹配。
最后返回编码数据库。
调用这个方法:
encodeListKnown = findEncodings(images)
print(len(encodeListKnown))结果如下:说明数据库里面有5个已知面孔
![]()
导入未知的图片,比较差值
记录出勤的话需要用到摄像头,属于动态的图像,所以会用到cv2.VideoCapture(0)进行捕捉。但我这里就不用实时的了,使用预先导入的视频作为测试。
cap = cv2.VideoCapture('happy.mp4')
while True:
success, img = cap.read()
imgS = cv2.resize(img, (0, 0), None, 0.25, 0.25) # 重塑每一帧图片的大小
imgS = cv2.cvtColor(imgS, cv2.COLOR_BGR2RGB) # 转换成RGB格式
facesCurFrame = face_recognition.face_locations(imgS) # 找人脸
encodeCurFrame = face_recognition.face_encodings(imgS, facesCurFrame) # 对人脸的地方进行编码
# 找匹配项。捕捉到的人脸与已知数据库里的每一张图像都进行比对,计算差值
for encodeFace, faceLoc in zip(encodeCurFrame, facesCurFrame):
matches = face_recognition.compare_faces(encodeListKnown, encodeFace)
faceDis = face_recognition.face_distance(encodeListKnown,encodeFace)
print(faceDis)这里的faceDis代表捕捉到视频里的人脸和数据库里已知的面孔,相差多少。
结果如下:
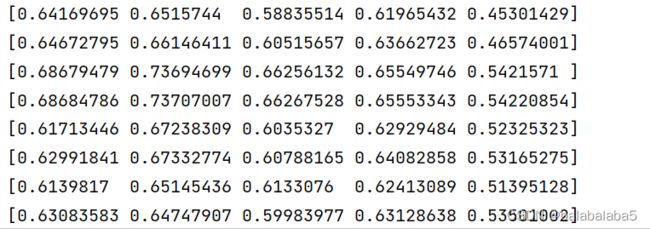
差值最小的就默认为最佳匹配项。用np.argmin()函数得到最小值的位置,即索引号。
# 找到最佳匹配项的索引,也就是差值最小的
matchIndex = np.argmin(faceDis)框出人脸,放置识别结果(识别的名字)
计算的差值和前面导入已知图像时截取的图片名称,索引号是一致的。只要进行索引,所以就可以知道视频里捕捉到的人脸是谁了。
if matches[matchIndex]:
name = classNames[matchIndex].upper() #首字母大写
print(name)
y1, x2, y2, x1 = faceLoc
# 前面重塑了一次图像的大小(缩小了1/4),
# 所以faceLoc的值也是缩小了1/4的值,这里需要扩大四倍
y1, x2, y2, x1 = y1*4, x2*4, y2*4, x1*4
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.rectangle(img, (x1, y2-35), (x2, y2), (0, 255, 0), cv2.FILLED)
cv2.putText(img, name, (x1+6, y2-6), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 2)如果最小值所在索引的位置,对应的比较结果为True,那么就在classNames名字库里匹配名字,在视频的那一帧里框出人脸,放上匹配到的人名。
部分结果:

出勤表的制作:
就是将名字和出现的时间放到一个表格里面。
出勤方法的代码:
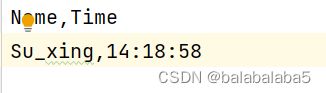
- 首先需要在当前目录下创建一个名叫“Attendance.csv”的表格
- 其次,在pycharm里面打开,写入:Name,Time
- 接着,开始写下面的代码
from datetime import datetime
def markAttendance(name):
with open('Attendance.csv', 'r+') as f: # 以读写模式打开“Attendance.csv”表格
myDataList = f.readlines() # 读取每一行
nameList = []
for line in myDataList:
entry = line.split(',') # 每一行里的每个数据都是用','分割开
nameList.append(entry[0]) # nameList数组里面存放的都是名字
if name not in nameList: # 如果name不存在在nameList里,也就是出现了新人
now = datetime.now() # 那么获取当前的时间
dtString = now.strftime('%H:%M:%S') # 设置时间的书写格式
f.writelines(f'\n{name},{dtString}') # 在新的一行里写下新人的名字,时间调用这个方法:
markAttendance('Su_xing') csv文件里的结果:
所以,放到咱们的主程序后的结果:

完整程序:
import os
from datetime import datetime
import face_recognition
import numpy as np
import cv2
path = 'pic'
images = []
classNames = []
# 获取图片名称的名字
myList = os.listdir(path)
print(myList)
for cl in myList:
curImg = cv2.imread(f'{path}/{cl}')
images.append(curImg)
classNames.append(os.path.splitext(cl)[0])
print(classNames)
def findEncodings(images):
encodeList = []
for img in images:
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
encode = face_recognition.face_encodings(img)[0]
encodeList.append(encode)
return encodeList
def markAttendance(name):
with open('Attendance.csv', 'r+') as f:
myDataList = f.readlines()
nameList = []
for line in myDataList:
entry = line.split(',')
nameList.append(entry[0])
if name not in nameList:
now = datetime.now()
dtString = now.strftime('%H:%M:%S')
f.writelines(f'\n{name},{dtString}')
encodeListKnown = findEncodings(images)
print('Encoding Complete')
cap = cv2.VideoCapture('happy.mp4')
while True:
success, img = cap.read()
imgS = cv2.resize(img, (0, 0), None, 0.25, 0.25) # 重塑每一帧图片的大小
imgS = cv2.cvtColor(imgS, cv2.COLOR_BGR2RGB) # 转换成RGB格式
facesCurFrame = face_recognition.face_locations(imgS) # 找人脸
encodeCurFrame = face_recognition.face_encodings(imgS, facesCurFrame) # 对人脸的地方进行编码
# 找匹配项。捕捉到的人脸与已知数据库里的每一张图像都进行比对,计算差值
for encodeFace, faceLoc in zip(encodeCurFrame, facesCurFrame):
matches = face_recognition.compare_faces(encodeListKnown, encodeFace)
faceDis = face_recognition.face_distance(encodeListKnown,encodeFace)
print(faceDis)
# 找到最佳匹配项,也就是差值最小的
matchIndex = np.argmin(faceDis)
if matches[matchIndex]:
name = classNames[matchIndex].upper() #首字母大写
print(name)
y1, x2, y2, x1 = faceLoc
# 前面重塑了图像的大小(缩小了1/4),所以faceLoc的值也是缩小了1/4的值,这里需要扩大四倍
y1, x2, y2, x1 = y1*4, x2*4, y2*4, x1*4
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.rectangle(img, (x1, y2-35), (x2, y2), (0, 255, 0), cv2.FILLED)
cv2.putText(img, name, (x1+6, y2-6), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 2)
markAttendance(name)
cv2.imshow('results',img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break所有的资源链接(包含软件、库、程序、程序用到的图片和视频):
链接:https://pan.baidu.com/s/1GXQGS5nYijhVjJzPS0YIWA
提取码:opo8
总结:
应该是电脑配置的原因导致的视频结果卡顿,但就当一个练手的人脸检测项目来做是可行的。
后面如果有服务器或者gpu,或许可以解决卡顿问题。