在pytorch中自定义dataset读取数据
class Pokemon(Dataset):
def __init__(self, root, resize, mode):# 根目录,
super(Pokemon, self).__init__()
self.root=root
self.resize=resize
self.name2label={}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root,name)):
continue
self.name2label[name]=len(self.name2label.keys())
print(self.name2label)
self.labels,self.images = self.load_csv('images.csv')
if mode=='train':
self.images=self.images[:int(0.6*len(self.images))]
self.labels=self.labels[:int(0.6*len(self.labels))]
elif mode=='val':
self.images = self.images[int(0.6 * len(self.images)):int(0.8 * len(self.images))]
self.labels = self.labels[int(0.6 * len(self.images)):int(0.8 * len(self.labels))]
else:
self.images = self.images[int(0.8 * len(self.images)):]
self.labels = self.labels[int(0.8 * len(self.images)):]
def load_csv(self,filename):
if os.path.exists(os.path.join(self.root,filename)):
images=[]
for name in self.name2label.keys():
images += glob.glob(os.path.join(self.root,name,'*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
print(len(images),images)
random.shuffle(images)
with open(os.path.join(self.root,filename),mode='w',newline='') as f:
writer=csv.writer(f)
for img in images:
name=img.split(os.sep)[-2]
label=self.name2label[name]
writer.writerow([label,img])
print('csv file:',filename)
images=[]
labels=[]
with open(os.path.join(self.root,filename)) as f:
reader=csv.reader(f)
for row in reader:
label,img=row
label=int(label)
images.append(img)
labels.append(label)
assert len(images)==len(labels)#保证长度一样
return labels,images
def __len__(self):
return len(self.images)
def denormalize(self,y_hat):
mean = [0.485, 1.456, 0.406]
std = [0.229, 0.224, 0.225]
mean=torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
y=y_hat*std+mean
return y
def __getitem__(self, idx):
label,img=self.labels[idx],self.images[idx]
tf = transforms.Compose([
lambda x:Image.open(x).convert('RGB'),
transforms.Resize((int(self.resize*1.25),int(self.resize*1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,1.456,0.406],
std=[0.229,0.224,0.225])
])
img=tf(img)
label=torch.tensor(label)
return label,imgPYtorch官方提供了许多数据集,下载训练集Training a Classifier — PyTorch Tutorials 1.12.0+cu102 documentation
import torchvision
import torchvision.transforms as transforms
# 预处理方法:转换为tensor类型HWC(0,255)-CHW-(0.0,1.0)
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 导入CIFAR10训练集5万张,到当前目录下的data
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)# 将训练集分批次,每次32张,并且打乱
import torch
trainloader=torch.utils.data.DataLoader(trainset, batch_size=32,
shuffle=True, num_workers=0)简单的看一下测试集的图片:
# 测试集
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
# 可迭代的迭代器
test_data_iter = iter(testloader)
test_image, test_label = test_data_iter.next()
# 标签元组,不能改变
classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
import numpy as np
import matplotlib.pyplot as plt
def imshow(img):
img = img / 2 + 0.5# 反标准化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))# 转化为(H,W,C)
plt.show()
print(' '.join(f'{classes[test_label[j]]:5s}' for j in range(4)))
imshow(torchvision.utils.make_grid(test_image))
DATAset获取数据:img和对应labal
DATAloader喂数据的打包方式
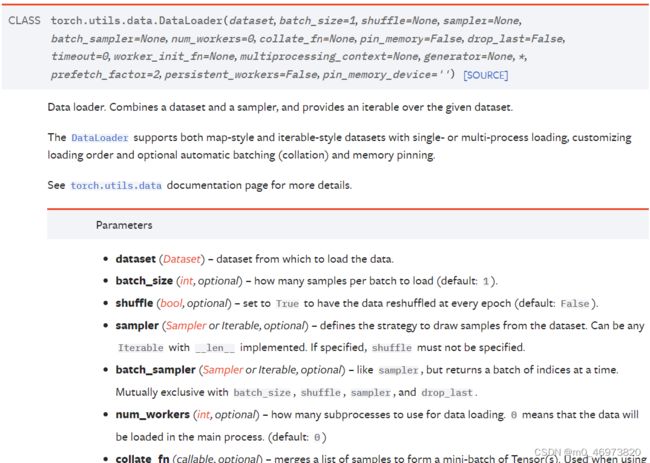
参数意义: 数据集;一次拿几张;顺序打乱吗?drop_last是否舍弃余数