多行人追踪至落地部署项目,Deepsort、JDE、Fair-MOT三种算法简介及其核心卡尔曼滤波器与匈牙利算法简介
大致效果:主要以部署为主,后续更新部署成品
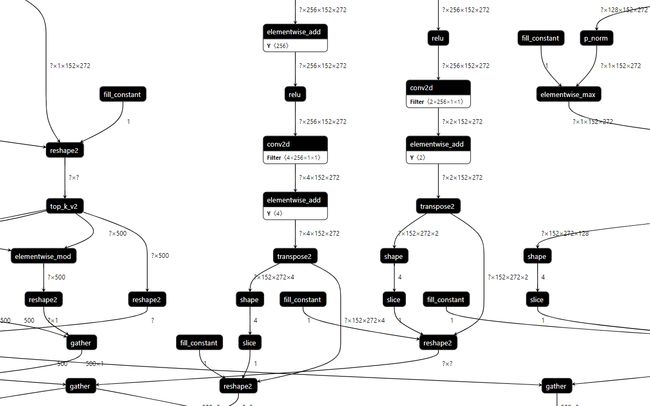
部分网络模型结构:
1 、项目简介
点我直接进入项目更加全面的信息,数据集,代码,一键训练模型
本项目基于单镜头多行人追踪模型实现对行人的追踪。该项目使用PaddleDetection快速训练分类模型,然后通过PaddleLite部署到安卓手机上,实现飞桨框架深度学习模型的落地。
- 模型训练:
Fair-MOT、JDE、Deep sort三种由PaddleDetection2.1提供的模型 - 模型转换:Paddle-Lite
- Android开发环境:Android Studio on Ubuntu 18.04 64-bit
- 移动端设备:安卓9.0以上的手机设备 (部署还在加工中,已经导出MOT导出的权重文件,后续会更新部署到树莓派或者安卓上的代码,先生成V3版本)
1.2 关于本项目
本项目基于单镜头多行人追踪模型。对项目还存在的改进空间,以及其它模型在不同移动设备的部署,希望大家多交流观点、介绍经验,共同学习进步,可以互相关注♥。个人主页
1.3 PaddleDetection简介
PaddleDetection飞桨目标检测开发套件,旨在帮助开发者更快更好地完成检测模型的组建、训练、优化及部署等全开发流程。PaddleDetection模块化地实现了多种主流目标检测算法,提供了丰富的数据增强策略、网络模块组件(如骨干网络)、损失函数等,并集成了模型压缩和跨平台高性能部署能力。
1.4 MOT文档
- Fair-MOT中文文档
- JDE中文文档
- Deep sort中文文档
附上:
----------------->项目地址链接
----------------->笔记以及PPT下载链接,提取码:6666
----------------->b站MOT简单介绍链接
2、在了解SORT类的追踪算法之前,用大白话介绍在MOT任务中最核心的两个算法“卡尔曼滤波器”与“匈牙利算法”
2.1卡尔曼滤波
2.1.1背景介绍
卡尔曼滤波(Kalman)无论是在单目标还是多目标领域都是很常用的一种算法,我们将卡尔曼滤波看做一种运动模型,用来对目标的位置进行预测,并且利用预测结果对跟踪的目标进行修正,属于自动控制理论中的—种方法。
在对视频中的目标进行跟踪时,当目标运动速度较慢时,很容易将前后两帧的目标进行关联,举个栗子如下图所示:

物体运动速度比较慢时
如果目标运动速度比较快,或者进行隔帧检测时,在后续帧中,目标A已运动到前一帧B所在的位置,这时再进行关联就会得到错误的结果,将A’与B关联在一起。

解决这个问题,就可以用到卡尔曼滤波,用卡尔曼滤波来预测下一帧A和B可能出现的位置,然后进行距离计算。

上图所示,预测A与B可能出现的位置,产生了一个下一时刻预测的实线框,计算预测的实线框与实际出现的虚线框的距离,即可解决上诉问题。(可以利用之前几帧的位置来预测下一帧的位置,即可关联同一目标)
2.1.2 原理介绍
举一个简单的场景栗子,有一辆小车在行驶,它的速度是v,可以通过观测得到它的位置p,也就是说我们可以实时的观测小车的状态。
小车在某一时刻的状态表示为一个向量:
x ⃗ = [ p v ] \vec{x}=\left[\begin{array}{l} p \\ v \end{array}\right] x=[pv]
虽然我们比较确定小车此时的状态,无论是计算还是检测都会存在一定的误差,所以我们只能认为当前状态是其真实状态的一个最优估计。那么我们不妨认为当前状态服从一个高斯分布,如下图所示:
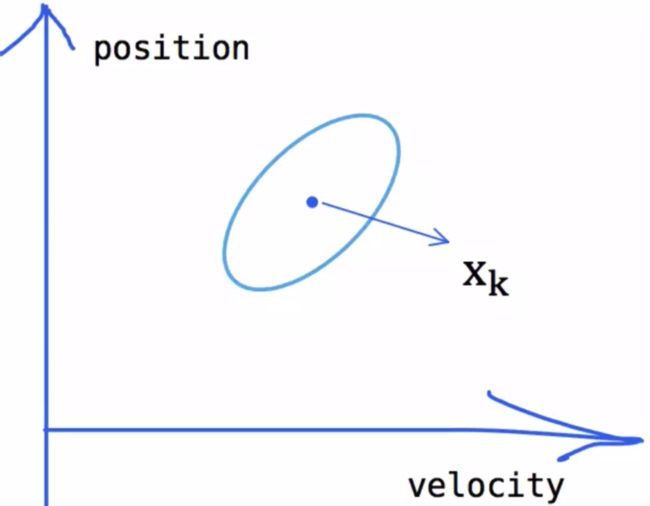
高斯分布的中心 u就是图中的 x ^ k \hat{\mathbf{x}}_{k} x^k
x ^ k = [ position velocity ] \hat{\mathbf{x}}_{k}=\left[\begin{array}{l} \text { position } \\ \text { velocity } \end{array}\right] x^k=[ position velocity ]
因为我们有两个变量,所以可以用一个协方差矩阵 Pk来表示数据之间的相关性和离散程度:
P k = [ Σ p p Σ p v ∑ v p Σ v v ] \mathbf{P}_{k}=\left[\begin{array}{ll} \Sigma_{p p} & \Sigma_{p v} \\ \sum_{v p} & \Sigma_{v v} \end{array}\right] Pk=[Σpp∑vpΣpvΣvv]
-
预测下一时刻的状态
下面我们需要通过小车的当前状态,运用一些物理学的知识来预测它的下一个状态,即通过k-1时刻的位置利速度,可以推测下一个时刻的状态为:
p k = p k − 1 + Δ t v k − 1 v k = v k − 1 \begin{array}{ll} p_{k}=p_{k-1}+\Delta t & v_{k-1} \\ v_{k}= & v_{k-1} \end{array} pk=pk−1+Δtvk=vk−1vk−1
写成矩阵形式就是:
x ^ k = [ 1 Δ t O 1 ] x ^ k − 1 = F k x ^ k − 1 \hat{\mathbf{x}}_{k}=\left[\begin{array}{cc} \mathbf{1} & \Delta t \\ \mathbf{O} & \mathbf{1} \end{array}\right] \hat{\mathbf{x}}_{k-\mathbf{1}}=\mathbf{F}_{k} \hat{\mathbf{x}}_{k-1} x^k=[1OΔt1]x^k−1=Fkx^k−1
此处的Fk就是状态转移矩阵。
但是现实生活大部分都不是匀速运动假如有加速度!所以我们需要对小车进行控制,比如加速和减速,假设某个时刻我们施加的加速度是a,那么下一时刻的位置和速度则应该为:
p k = p k − 1 + Δ t v k − 1 + 1 2 a Δ t 2 v k = v k − 1 + a Δ t \begin{array}{ll} p_{k}=p_{k-1}+\Delta t & v_{k-1}+\frac{1}{2} a \Delta t^{2} \\ v_{k}= & v_{k-1}+a \Delta t \end{array} pk=pk−1+Δtvk=vk−1+21aΔt2vk−1+aΔt
写成矩阵的形式:
x ^ k = F k x ^ k − 1 + [ Δ t 2 2 Δ t ] a = F k x ^ k − 1 + B k u k − 1 \begin{aligned} \hat{\mathbf{x}}_{k} &=\mathbf{F}_{k} \hat{\mathbf{x}}_{k-1}+\left[\begin{array}{c} \frac{\Delta t^{2}}{2} \\ \Delta t \end{array}\right] a \\ &=\mathbf{F}_{k} \hat{\mathbf{x}}_{k-1}+\mathbf{B}_{k} \mathbf{u}_{k-1} \end{aligned} x^k=Fkx^k−1+[2Δt2Δt]a=Fkx^k−1+Bkuk−1
其中,Bk我们称为状态控制矩阵,uk-1而称为状态控制向量,很明显,前者表明的是加速减速如何改变小车的状态,而后者则表明控制的力度大小和方向。
考虑系统的外部影响:
外界有很多影响因素能够对小车的状态产生影响,比如说风速,地面好不好走(湿度,摩擦力)等,在这里我们假设外部的不确定因素对小车造成的系统状态误差wk服从高斯分布wk-1~N(0,Qk-1),至此我们就能得到Kalman滤波中完整的状态预测方程:(wk-1是过程噪声不可测)
提一句。x上的小尖尖,是简单物理公式得出来的值,不是真实值,同样k-1上一时刻也无法得出真实值。这样就会误差越来越大。用两个带有误差不太准确结果,得出来一个比较真实的结果。这个时候就需要用到卡尔曼滤波了。
x ^ k = F k x ^ k − 1 + B k u k + w k − 1 \begin{aligned} \hat{\mathbf{x}}_{k} &=\mathbf{F}_{k} \hat{\mathbf{x}}_{k-1}+\mathbf{B}_{k} \mathbf{u}_{k}+\mathrm{w}_{k-1} \\ \end{aligned} x^k=Fkx^k−1+Bkuk+wk−1
传感器测量出来的结果,小车的当前状态和观测到的数据应该具备某种特定的关系,假设这个关系通过矩阵表示为H,如下图在k时刻所示:
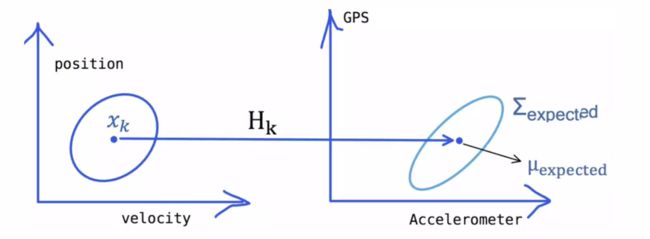
这是传感器测量出来的结果,H是一个关系矩阵,vk是传感器传来的测量噪声(不可测)
z k = H x k + v k z_{k}=H x_{k}+v_{k} zk=Hxk+vk
(x右上角一个杠是指先验估计,去除误差计算的值)
那么我们就可以得出两个Xk来,如下:
按照简单物理学公式计算出的
x ^ k − = F k x ^ k − 1 + B k u k \begin{aligned} \hat{\mathbf{x}}_{k}^{-} &=\mathbf{F}_{k} \hat{\mathbf{x}}_{k-1}+\mathbf{B}_{k} \mathbf{u}_{k} \\ \end{aligned} x^k−=Fkx^k−1+Bkuk
传感器测量出的
z k = H x k → x ^ k = H − z k z_{k}=H x_{k} \rightarrow \hat{\mathbf{x}}_{k}=H^{-} z_{k} zk=Hxk→x^k=H−zk
得出一个公式,卡尔曼滤波器:
x ^ k = x ^ k − + G ( H − z k − x ^ k − ) \hat{x}_{k}=\hat{x}_{k}^{-}+G\left(H^{-} z_{k}-\hat{x}_{k}^{-}\right) x^k=x^k−+G(H−zk−x^k−)
G则是卡尔曼增益,G=1就是完全相信测量的结果。G=0就趋近0就是完全相信计算出的预测结果。也就是说我们要取一个k值,让两者加权平均出来一个相对方差小的结果,作为计算出来最接近真实值的结果。
所以要计算卡尔曼增益系数k大概就是:
卡尔曼增益 = (当前估计协方差的平方 / (当前估计协方差的平方 + 当前测量测方差的平方))
真实结果= 估计值 + 卡尔曼增益 * (测量值 - 估计值)

对观测数据的预测。
总的来说卡尔曼滤波需要做的最重要的最核心的事就是融合预测和观测的结果,充分利用两者的不确定性来得到更加准确的估计。通俗来说就是怎么从上面的两个椭圆中来得到中间淡黄色部分的高斯分布,看起来这是预测和观测高斯分布的重合部分,也就是概率比较高的部分。
2.1.3 总结:
卡尔曼滤波器中在目标跟踪中的应用:
卡尔曼滤波器通过预测目标在后续帧中的位置,避免在进行目标关联时出现误差
卡尔曼滤波器的原理:
滤波器根据上一时刻(k-1时刻)的值来估计当前时刻(k时刻)的状态,得到k时刻的先验估计值;然后使用当前时刻的测量值来更正这个估计值,得到当前时刻的估计值。
- 目标不确定姓和相关性的度量
- 预测目标的下一时刻的状态
- 系统内部的控制和外部的影响
- 利用观测值进行修正
- 实际应用中:预测和更新两个阶段
2.2 匈牙利算法
2.2.1 二分图匹配
匈牙利算法是由匈牙利数学家Edmonds于1965年提出。匈牙利算法是基于Hall定理中充分性证明的思想,它是二分图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。这篇文章讲无权二分图(unweightedbipartite graph)的最大匹配(maximum matching)和完美匹配( perfect matching) ,以及用于求解匹配的匈牙利算法(Hungarian Algorithm)
举个栗子,如下图,(假如训练出一个检测器模型,把他计算所得的超过阈值的可能用红色的线连接起来)
红线: 可能有关联的线
蓝线: 匈牙利算法连接确认的线(可以暂时拆除)
黄线: 暂时拆除的线


-
第一步
首先给左1进行匹配,发现第一个与其相连的右1还未匹配,将其配对,连上一条蓝线。 -
第二步
接着匹配左2,发现与其相连的第一个目标右2还未匹配,将其配对 -
第三步
接下来是左3,发现最优先的目标右1已经匹配完成了,怎么办呢?我们给之前右1的匹配对象左1分配另一个对象。(黄色线表示这条边被临时拆掉)
可是与左1匹配的第二个目标是右2,但右2也已经有了匹配对象,怎么办呢?
我们再给之前右2的匹配对象左2分配另一个对象(注意这个步骤和上面是一样的,这是一个递归的过程)。
暂时断掉先前连接的两条线,那么左1,左2只能如下图蓝线匹配,左三就能匹配到右1,
- 按照第三步的节奏我们没法给左4腾出来一个匹配对象,只能放弃对左4的匹配,匈牙利算法流程至此结束。蓝线就是我们最后的匹配结果。至此我们找到了这个二分图的一个最大匹配。最终的结果是我们匹配出了三对目标,由于候选的匹配目标中包含了许多错误的匹配红线(边),所以匹配准确率并不高。可见匈牙利算法对红线连接的准确率要求很高,也就是要求我们运动模型(Detection)、外观模型等部件必须进行较为精准的预测,或者预设较高的阈值,只将置信度较高的边才送入匈牙利算法进行匹配,这样才能得到较好的结果。
2.2.2 总结:
匈牙利算法得到的最大匹配并不是唯一的,预设匹配边、或者匹配顺序不同等,都可能会导致有多种最大匹配情况。假如Detection训练很好,经过匈牙利算法能够把人物与ID完美对应,则称为完美匹配,完美匹配一定是最大匹配,而最大匹配不一定是完美匹配。匈牙利算法核心目标就是找到最大匹配了。

3、准备制作模型的开始,先准备好数据集,解压MOT照片资源
在MOT官网 上有很多现成的MOT数据集,物尽其用,我就挑选了MOT17Det的 02、04、05、09、10、11与MOT20Det的 01、02、03、05这10个数据集
请在Jupyter下执行该代码,建议到该链接一步全部运行即可
#拉取最新版PaddleDetection
!git clone https://github.com.cnpmjs.org/PaddlePaddle/PaddleDetection
#移动到持久层上
!mv PaddleDetection work
#一些修改过的配置文件
!rm work/PaddleDetection/ppdet/engine/tracker.py
!rm work/PaddleDetection/dataset/mot/gen_labels_MOT.py
!rm work/PaddleDetection/configs/datasets/mot.yml
!cp Ready_file/mot.yml work/PaddleDetection/configs/datasets/ #数据集配置文件
!cp Ready_file/gen_labels_MOT.py work/PaddleDetection/dataset/mot/ #生成训练所需要的帧率、id、位置坐标的信息work/PaddleDetection/dataset/mot/MOT20/labels_with_ids
!cp Ready_file/tracker.py work/PaddleDetection/ppdet/engine/ #增加在视频推理输出提交百度行人追踪的结果文件.txt
#配置PaddleDetection环境
!pip install -r /home/aistudio/work/PaddleDetection/requirements.txt
#划分数据集与验证集所需要的文件格式 (文档)
!wget https://dataset.bj.bcebos.com/mot/image_lists.zip
!unzip -oq image_lists.zip
!rm image_lists.zip
3.1 数据集图像增广(拓展代码)
在某些特殊情况,数据集不够多的时候,可以采取这样的方式,增广一整个文件夹的数据集 ,这里拿MOT20/images/train/MOT20-01/img1路径的图片做示例
from paddle.vision.transforms import Compose, ColorJitter, Resize,Transpose, Normalize
from PIL import Image, ImageFilter, ImageEnhance
import cv2
import paddle.vision as F
import paddle.fluid as fluid
import os
def sharp_data(photo_path,output_path): #05 no
filelist = os.listdir(photo_path)
num_jpg = len(filelist)
print("--------原始图像个数-------:",num_jpg)
load="../"+photo_path
file_output_path="../"+output_path
!mkdir -p $output_path
allTestDataName = []
for filename in filelist:
if filename.endswith('.jpg'):
allTestDataName.append(filename)
allTestDataName.sort(key= lambda x:int(x[:-4])) #做一个排序 前提是有循序的图片如:001.jpg,002.jpg,003.jpg等等
for item in allTestDataName:
all_item=photo_path+item
img = Image.open(all_item)
# print(img.size)
# 两次锐化
img = img.filter(ImageFilter.SHARPEN)
img = img.filter(ImageFilter.SHARPEN)
bright_enhancer = ImageEnhance.Brightness(img) # 传入调整系数亮度
img = bright_enhancer.enhance(1.1)
contrast_enhancer = ImageEnhance.Contrast(img) # 传入调整系数对比度
img = contrast_enhancer.enhance(1.1)
img.save(output_path+item)
filelist = os.listdir(output_path)
num_jpg = len(filelist)
print("--------输出图像个数-------:",num_jpg)
sharp_data("MOT20/images/train/MOT20-01/img1","/home/aistudio/deal_img/img1/")
3.2 数据集图像转为视频.avi格式 (拓展代码)
import cv2
import os
%cd /home/aistudio/
def getvideo(photo_path, video_name, fps):
filelist = os.listdir(photo_path)
size = (1920, 1080)
video = cv2.VideoWriter(video_name, cv2.VideoWriter_fourcc('I', '4', '2', '0'), fps, size)
# video = cv2.VideoWriter(video_name, cv2.VideoWriter_fourcc('M','J','P','G'), fps, size)
num_jpg = len(filelist)
allTestDataName = []
for filename in filelist:
if filename.endswith('.jpg'):
allTestDataName.append(filename)
allTestDataName.sort(key= lambda x:int(x[:-4]))
for item in allTestDataName:
item=photo_path+item
print(item)
img = cv2.imread(item)
video.write(img)
video.release()
cv2.destroyAllWindows()
def main():
photo_path = 'MOT20/images/train/MOT20-01/img1' #照片路径
video_name = '"/home/aistudio/video/MOT1.avi' #照片输出生成的视频路径
fps = 25 #帧率
getvideo(photo_path, video_name, fps)
if __name__ == '__main__':
main()
4、整理成训练所需要MOT20格式
提取MOT格式中的标注信息,生成最终训练所需要的标注文件
import pandas as pd
import cv2
import os
#划分训练集,生成work/PaddleDetection/dataset/mot/MOT20/labels_with_ids 内部存储
%cd /home/aistudio/work/PaddleDetection/dataset/mot/
!python gen_labels_MOT.py
#生成自己新组成MOT的数据集路径信息,只能执行一遍。否则数据量成倍数增长,假如执行多了,删除生成的MOT20.txt即可
def getfile(photo_path):
filelist = os.listdir(photo_path)
num_jpg = len(filelist)
allTestDataName = []
for filename in filelist:
if filename.endswith('.jpg'):
allTestDataName.append(filename)
allTestDataName.sort(key= lambda x:int(x[:-4])) #做一个排序 前提是有循序的图片如:001.jpg,002.jpg,003.jpg等等
with open("MOT20.txt","a") as f:
for item in allTestDataName:
item=photo_path+item
f.write(item)
f.write('\n')
def main():
list_name=["MOT20/images/train/MOT20-07/img1/","MOT20/images/train/MOT20-08/img1/","MOT20/images/train/MOT20-09/img1/","MOT20/images/train/MOT20-10/img1/",
"MOT20/images/train/MOT20-11/img1/","MOT20/images/train/MOT20-01/img1/","MOT20/images/train/MOT20-02/img1/","MOT20/images/train/MOT20-03/img1/",
"MOT20/images/train/MOT20-05/img1/","MOT20/images/train/MOT20-06/img1/"]
for i in list_name:
getfile(i)
if __name__ == '__main__':
main()
#将20的训练集改为自己定义的
!mv image_lists/mot20.train image_lists/mot20.val
!mv MOT20.txt image_lists/mot20.train
5、开始训练,及Fair-MOT、JDE、Deepsort算法介绍
5.1 简单介绍 PaddleDetection各个文件路径配置简介
├── configs # YML配置
├── dataset # 数据集
├── deploy # 部署:cpp, pyton, serving
├── docs # 中、英文档
├── ppdet # 核心源码,可安装
│ ├── core
│ ├── data # 数据加载
│ │ ├── source
│ │ └── transform
│ ├── engine # 执行引擎
│ ├── metrics # 评估器
│ ├── optimizer # 优化器
│ ├── modeling # 核心建模
│ │ ├── architectures #骨架网络
│ │ ├── backbones # 骨干网络
│ │ ├── heads # 检测头
│ │ ├── losses # 损失函数
│ │ ├── necks # 特征融合
│ ├── slim # 模型压缩
└── tools # 执行入口
├── eval.py
├── export_model.py
├── infer.py
└── train.py

5.2 Deepsort
DeepSort用来跟踪的思路较为明朗,也是目前主要流行的跟踪思路:detection + track 。 所以代码也以检测结果为输入:bounding box、confidence、feature 。conf主要用于进行一部分的检测框的筛选;bounding box与feature(ReID)用于后面与跟踪器的match计算;首先是预测模块,会对跟踪器使用卡尔曼滤波器进行预测。作者在这里使用的是卡尔曼滤波器的匀速运动和线性观测模型(意味着只有四个量且在初始化时会使用检测器进行恒值初始化)。其次是更新模块,其中包括匹配,追踪器更新与特征集更新。在更新模块的部分,根本的方法还是使用IOU来进行匈牙利算法的匹配,以下是整个算法流程,在b站链接也有讲解:

使用级联匹配算法:针对每一个检测器都会分配一个跟踪器,每个跟踪器会设定一个time_since_update参数。如果跟踪器完成匹配并进行更新,那么参数会重置为0,否则就会+1。实际上,级联匹配换句话说就是不同优先级的匹配。在级联匹配中,会根据这个参数来对跟踪器分先后顺序,参数小的先来匹配,参数大的后匹配。也就是给上一帧最先匹配的跟踪器高的优先权,给好几帧都没匹配上的跟踪器降低优先权(慢慢放弃),而且当一个目标长时间被遮挡之后,kalman滤波预测的不确定性就会大大增加,状态空间内的可观察性就会大大降低。假如此时两个追踪器竞争同一个检测结果的匹配权,往往遮挡时间较长的那条轨迹的马氏距离更小,使得检测结果更可能和遮挡时间较长的那条轨迹相关联,这种不理想的效果往往会破坏追踪的持续性。这么理解吧,假设本来协方差矩阵是一个正态分布,那么连续的预测不更新就会导致这个正态分布的方差越来越大,那么离均值欧氏距离远的点可能和之前分布中离得较近的点获得同样的马氏距离值。所以,作者使用了级联匹配来对更加频繁出现的目标赋予优先权。当然同样也有弊端: 可能导致一些新产生的轨迹被连接到了一些旧的轨迹上。
5.3 JDE
范式首先通过检测器(detector)检测出画面中物体所在的检测框,然后根据物体检测框移动的规律(运动特征)和检测框中物体的外观特征(通常通过一个ReID网络抽取一个低维的向量,叫做embedding向量)来进行前后帧同一物体的匹配,从而实现多目标追踪。该类范式将MOT分为了两步,即:
- 物体检测
- 特征提取与物体关联
该类方法检测与特征提取是分开的,所以又被称为SDE。SDE存在的最大缺点就是速度慢,因为将物体检测和(外观)特征提取分开,检测速度自然就下去了。
所以提出JDE范式,方法是基于One-stage检测器学习到物体的embedding的(代码中采用的是经典的YOLO V3模型)。那么JDE范式就应该在检测器的输出(head),多输出一个分支用来学习物体的embedding的。
首先embedding要怎么学出来?我们知道,理想情况下同一物体在不同的帧中,被同一跟踪标签锁定(即拥有同一track ID)。我们知道的信息就只有他们的标签索引(同一物体的track ID一致,不同物体的track ID不一样)。
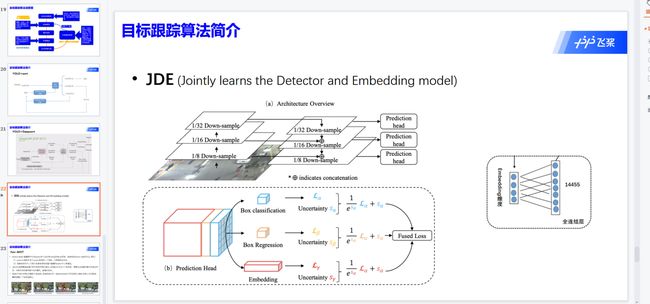
那么网络在训练的过程中,应该需要对embedding进行转化,转化为足够强的语义信息,也就是这个embedding到底属于哪个track ID的物体,那么这种就需要借鉴物体分类的思路了(将每个track ID当作一个类别),所以作者引入了全连接层将embedding信息转化为track ID分类信息。
因为刚才我们提到,要将每个track ID当作一个类别,但是这个track ID的数量十分庞大,甚至不可计数。这个输出节点应该如何设置呢?原论文中中设置了14455个输出节点,具体设置的依据是什么,可能和训练数据集的物体数量有关吧。
注释:笔记以及PPT下载链接,提取码:6666
5.3 微软AI对象检测器 Fair-MOT
-
Anchor-Based 检测器产生的anchor并不适合学习合适的Re-ID信息,应该使用anchor free的方法。原因:
(1)锚不适合Re-ID。anchor会导致有多个anchor对应同一个物体,从而导致歧义性。当前的单步法跟踪器都是基于锚的,因为它们是从对象检测器修改而来的。但是,有两个原因造成了锚点不适合学习Re-ID功能。首先,对应于不同图像补丁的多个锚点可能负责估计同一对象的身份。这导致网络的严重歧义。此外,通常会将特征图降级采样8次以平衡精度和速度。这对于检测是可以接受的,但对于ReID来说太粗糙了,因为对象中心可能与在粗略锚点位置提取的用于预测对象身份的特征不对齐。我们解决该问题,是通过将MOT问题,处理为位于高分辨率特征图顶部的像素级关键点(对象中心)估计和身份分类问题。
(2)实际物体的中心可能与负责对该物体进行检测的anchor中心有偏差。
(3)多层特征聚合。这对于MOT尤为重要,因为Re-ID功能需要利用低级和高级功能来容纳大小两种对象。我们在实验中观察到,由于提高了处理标度变化的能力,这有助于减少单步法的身份切换。请注意,对于两步方法而言,改进并不那么重要,因为在裁剪和调整大小操作之后,对象将具有相似的比例。
-
Re-ID任务需要高低层不同分辨率的特征融合。因为Re-ID关注于个体信息,需要包含高层网络中的语义信息,也要包含低层网络中的的颜色,纹理的信息。
-
在MOT中Re-ID特征的维数不宜过高。因为在MOT的一些benchmarks中并没有那么像Re-ID那么多的数据,维度设置大了容易过拟合。
图示举例:

#训练开始
# !python -u tools/train.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml --use_vdl True
#断点续训
!python -u tools/train.py -c configs/mot/fairmot/fairmot_dla34_30e_1088x608.yml -r output/fairmot_dla34_30e_1088x608/model_final.pdparams --use_vdl True
代码打印部分日志如下:
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
[07/10 14:43:21] ppdet.data.source.mot INFO: ================================================================================
[07/10 14:43:21] ppdet.data.source.mot INFO: MOT dataset summary:
[07/10 14:43:21] ppdet.data.source.mot INFO: OrderedDict([('mot20.train', 2652)])
[07/10 14:43:21] ppdet.data.source.mot INFO: total images: 23079
[07/10 14:43:21] ppdet.data.source.mot INFO: image start index: OrderedDict([('mot20.train', 0)])
[07/10 14:43:21] ppdet.data.source.mot INFO: total identities: 2653
[07/10 14:43:21] ppdet.data.source.mot INFO: identity start index: OrderedDict([('mot20.train', 0)])
[07/10 14:43:21] ppdet.data.source.mot INFO: ================================================================================
W0710 14:43:45.804842 17087 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W0710 14:43:45.811911 17087 device_context.cc:422] device: 0, cuDNN Version: 7.6.
[07/10 14:43:55] ppdet.utils.checkpoint INFO: Finish resuming model weights: output/fairmot_dla34_30e_1088x608/model_final.pdparams
[07/10 14:44:02] ppdet.engine INFO: Epoch: [24] [ 0/1049] learning_rate: 0.000090 loss: 1.947675 heatmap_loss: 0.599841 size_loss: 0.596399 offset_loss: 0.203034 reid_loss: 7.708297 eta: 3:01:52 batch_cost: 3.4675 data_cost: 0.0006 ips: 6.3445 images/s
[07/10 14:44:53] ppdet.engine INFO: Epoch: [24] [ 20/1049] learning_rate: 0.000045 loss: 1.969169 heatmap_loss: 0.616040 size_loss: 0.616855 offset_loss: 0.209220 reid_loss: 7.717417 eta: 2:15:07 batch_cost: 2.5490 data_cost: 0.0010 ips: 8.6307 images/s
[07/10 14:45:45] ppdet.engine INFO: Epoch: [24] [ 40/1049] learning_rate: 0.000045 loss: 1.967628 heatmap_loss: 0.619022 size_loss: 0.668332 offset_loss: 0.209818 reid_loss: 7.742723 eta: 2:13:34 batch_cost: 2.5657 data_cost: 0.0004 ips: 8.5747 images/s
[07/10 14:46:36] ppdet.engine INFO: Epoch: [24] [ 60/1049] learning_rate: 0.000045 loss: 1.980954 heatmap_loss: 0.642127 size_loss: 0.714834 offset_loss: 0.211269 reid_loss: 7.719330 eta: 2:12:25 batch_cost: 2.5618 data_cost: 0.0004 ips: 8.5876 images/s
详情请到项目地址链接fork一键运行即可得到属于自己的模型