深度学习:语义分割 FCN与Unet
参考:https://blog.csdn.net/wyzjack47/article/details/81107980
图像分割:

什么是图像分割问题呢? 简单的来讲就是给一张图像,检测是用框出框出物体,而图像分割分出一个物体的准确轮廓。也这样考虑,给出一张图像 I,这个问题就是求一个函数,从I映射到Mask。至于怎么求这个函数有多种方法。我们可以看到这个图,左边是给出图像,可以看到人和摩托车,右边是分割结果. 像素级分类。mask=function(I)
图像分割:两个框架 一个基于 cnn 一个基础 FCN
一、FCN(fully convolutional network)
论文:Fully Convolutional Networks for Semantic Segmentation. Jonathan Long ,Evan Shelhamer ,Trevor Darrell
第一次将深度学习结合起来的是这篇文章全卷积网络(FCN),利用深度学习求这个函数。在此之前深度学习一般用在分类和检测问题上。由于用到CNN,所以最后提取的特征的尺度是变小的。和我们要求的函数不一样,我们要求的函数是输入多大,输出有多大。为了让CNN提取出来的尺度能到原图大小,FCN网络利用上采样和反卷积到原图像大小。然后做像素级的分类。输入原图,经过VGG16网络,得到特征map,然后将特征map上采样回去。再将预测结果和ground truth每个像素一一对应分类,做像素级别分类。也就是说将分割问题变成分类问题,而分类问题正好是深度学习的强项。如果只将特征map直接上采样或者反卷积,明显会丢失很多信息。
FCN毫无疑问是语义分割领域的经典之作,在FCN出现之前,传统的CNN分割是将像素周围一个小区域作为CNN输入,做训练和预测,这样低效且不准确(忽略整体信息)。CNN主要有三点创新:
• 卷积化:即将传统CNN结构(文中提到的Alexnet、VGG)最后的全连接层改成卷积层,以便进行直接分割,这是十分有创造性的。
• 上采样:由于网络过程中进行了一系列下采样,使得特征层大小减小,了最后得到的预测层和原图一致,需要采用上采样,作用类似于反卷积。
• 并联跳跃结构:想法类似于resnet和inception,在进行分类预测时利用多层信息,具体如下图:
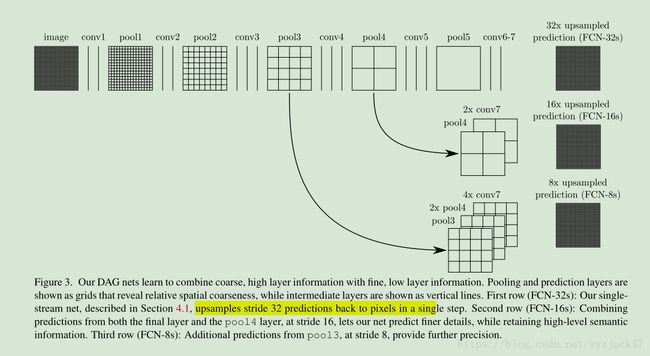
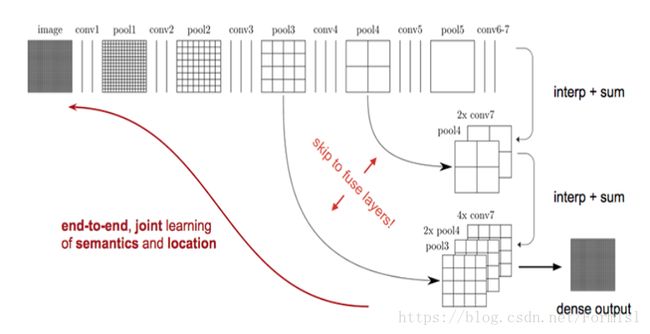
FCN采取解决方法是将pool4、pool3、和特征map融合起来,由于pool3、pool4、特征map大小尺寸是不一样的,所以融合应该前上采样到同一尺寸。这里的融合是拼接在一起(concact),不是对应元素相加。
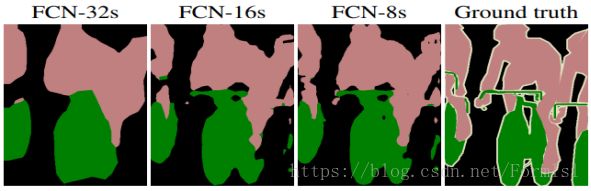
FCN是深度学习在图像分割的开山之作,FCN优点是实现端到端分割等,缺点是分割结果细节不够好,可以看到图四,FCN8s是上面讲的pool4、pool3和特征map融合,FCN16s是pool4和特征map融合,FCN32s是只有特征map,得出结果都是细节不够好,具体可以看自行车。由于网络中只有卷积没有全连接,所以这个网络又叫全卷积网络
二、Unet:医学影像分割的基石
论文:U-Net: Convolutional Networks for Biomedical Image Segmentation. Olaf Ronneberger, Philipp Fischer, and Thomas Brox
医学影像分割的论文,大部分都以Unet为基础进行改良,可见其重要性。而Unet是在FCN的基础上进行改良的,其网络结构如下:
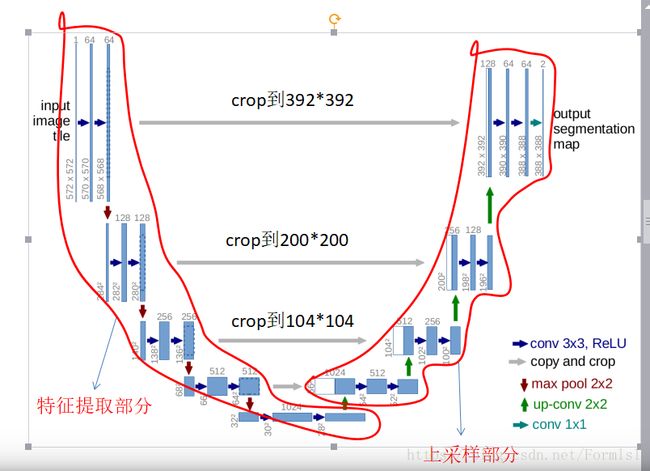
可见,Unet 包括左边的收缩路径和右边的扩张路径。收缩路径就是经结构,包括几个 3 × 3 的卷积加 RELU 激活层再加 2 × 2maxpooling 的结构(stride :2) ,下采样的每一步特征通道数都增加一倍。扩张路径的每一步包括上采样、 2 × 2 卷积(减少一半通道数),和相应收缩路径中的剪裁过的特征层的串联以及两个 3 × 3 卷积加 RELU 。最后一层用了 1 × 1 卷积把64个通道
映射到想要的类别种类数。
很多分割网络都是基于FCNs做改进,包括Unet。 在一些文献中也把这样的结构叫做编码器-解码器结构。由于此网络整体结构类似于大写的英文字母U,故得名U-net。
1、Unet包括两部分,可以看右图,第一部分,特征提取,VGG类似。第二部分上采样部分。由于网络结构像U型,所以叫Unet网络。
特征提取部分,每经过一个池化层就一个尺度,包括原图尺度一共有5个尺度。
上采样部分,每上采样一次,就和特征提取部分对应的通道数相同尺度融合,但是融合之前要将其crop。这里的融合也是拼接。
个人认为改进FCN之处有:
- 多尺度
- 适合超大图像分割,适合医学图像分割
- U-net与其他常见的分割网络有一点非常不同的地方:U-net采用了完全不同的特征融合方式:拼接,U-net采用将特征在channel维度拼接在一起,形成更厚的特征。而FCN融合时使用的对应点相加,并不形成更厚的特征
- 所以语义分割网络在特征融合时有两种办法:
1. FCN式的对应点相加,对应于TensorFlow中的tf.add()函数;
2. U-net式的channel维度拼接融合,对应于TensorFlow的tf.concat()函数,比较占显存。
Unet优点:
- 5个pooling layer实现了网络对图像特征的多尺度特征识别。
- 上采样部分会融合特征提取部分的输出,这样做实际上是将多尺度特征融合在了一起,以最后一个上采样为例,它的特征既来自第一个卷积block的输出(同尺度特征),也来自上采样的输出(大尺度特征),这样的连接是贯穿整个网络的,你可以看到上图的网络中有四次融合过程,相对应的FCN网络只在最后一层进行融合。
2、unet 输入和输出
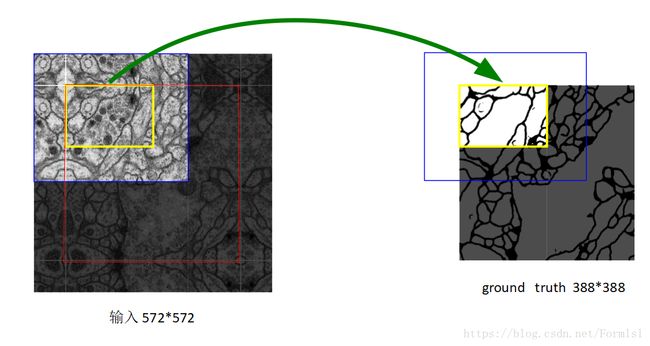
医学图像是一般相当大,但是分割时候不可能将原图太小输入网络,所以必须切成一张一张的小patch,在切成小patch的时候,Unet由于网络结构原因适合有overlap的切图,可以看图,红框是要分割区域,但是在切图时要包含周围区域,overlap另一个重要原因是周围overlap部分可以为分割区域边缘部分提供文理等信息。可以看黄框的边缘,分割结果并没有受到切成小patch而造成分割情况不好。
3、优化方式:这篇论文中优化用的是SGD with momentum, 能量函数十分有趣,用了加权的交叉熵形式,而不是通常的平均形式:
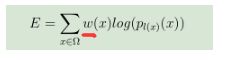
其中
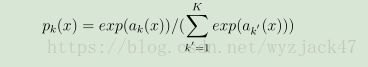
即像素点形式的softmax。
其中 w(x) 表示训练构成中像素点的重要性,越重要权重越大。
由于分割问题边界处的分割一直是难题,因此本文赋予边界处更高的权重以达到精确分割:
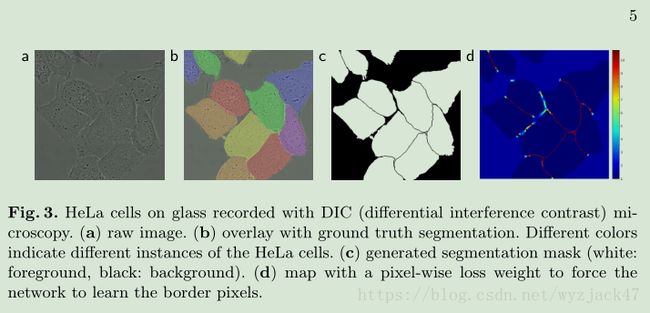
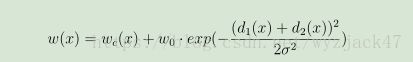
上式 d 1 表示此像素点到离他最近的cell的边界的距离,d 2 表示此像素点到离他第二近的cell的边界的距离。这样离边界越近的像素点权重越大,因而也会被着重训练。此举取得了很好的效果,这个idea也可谓让人拍案叫绝。
4、unet 反向传播
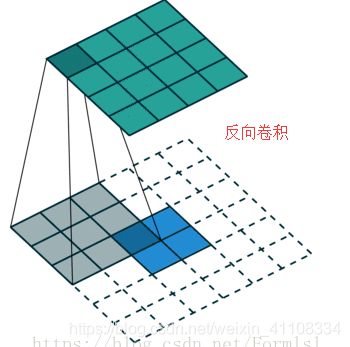
Unet反向传播过程,大家都知道卷积层和池化层都能反向传播,Unet上采样部分可以用上采样或反卷积,那反卷积和上采样可以怎么反向传播的呢?那什么是反卷积呢?先来讲下卷积的过程

反卷积就是转置卷积,也是一种卷积,这个就是转置卷积,由小尺寸到大尺寸的过程。也就是说反卷积也可以表示为两个矩阵乘积,很显然转置卷积的反向传播就是也是可进行的。所以说整体是Unet是可以反向传播的。
5、unet 实现:keras https://blog.csdn.net/qq_16900751/article/details/78251778
https://blog.csdn.net/awyyauqpmy/article/details/79290710
实现 两个 https://blog.csdn.net/sinat_26917383/article/details/80107783