卷积神经网络入门,卷积神经网络有哪些?新手入门卷积必看,真保姆级教程!
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一 [1-2] 。卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),因此也被称为“平移不变人工神经网络(Shift-Invariant Artificial Neural Networks, SIANN)” [3]
卷积神经网络可以算是深度神经网络中很流行的网络了。本文从基础入手,介绍了卷积网络的基本原理以及相关的其它技术,并利用卷积网络做了一个简单项目作为示例参考。想入手 CNN 的朋友不可错过~

首先,我们先看看下面这张照片:

这不是一张真实的照片,你可以新建一个窗口来打开它,放大看看,可以看到马赛克。
实际上,这张照片是由 AI 生成的,是不是看起来很真实?
从 Alex Krizhevsky 及其朋友通过 ImageNet 公布这项技术至今,不过才七年。ImageNet 是一个大规模图像识别竞赛,每年都会举办,识别种类达 1000 多种,从阿拉斯加雪橇犬到厕纸应用尽有。之后,他们又创建了 AlexNet,获得了 ImageNet 竞赛冠军,远超第二名。
这项技术就是卷积神经网络。它是深度神经网络的一个分支,处理图像的效果格外好。
上图是几年来赢得 ImageNet 挑战赛的软件产生的误差率。可以发现,2016 年误差率降到了 5%,已经超越人类水平。
深度学习的引入与其说是改变规则,不如说是在打破规则。
卷积神经网络架构
那么问题来了,卷积神经网络到底是怎么运作的呢?
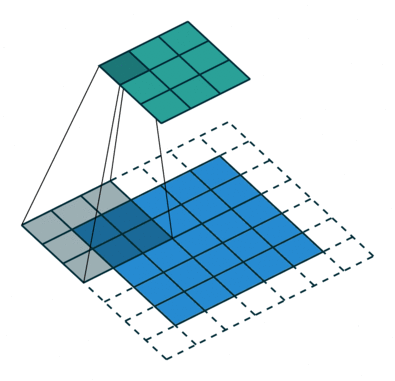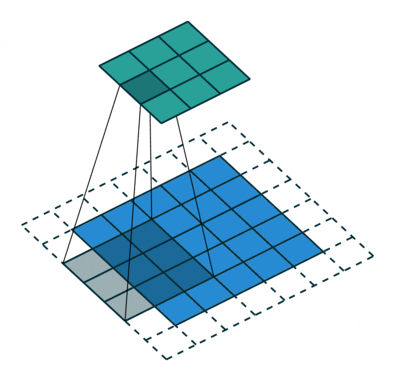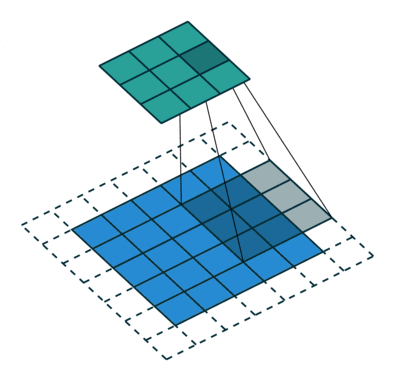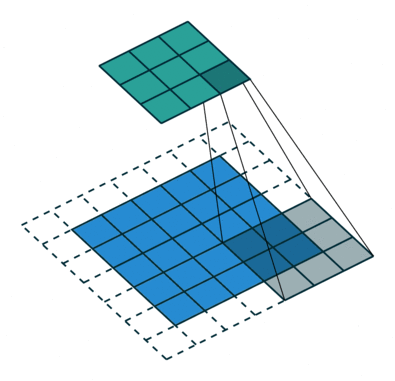
卷积神经网络之所以优于其它深度神经网络是由于它特殊的操作。相比一次只计算图像中的单个像素,CNN 将多个像素的信息组合在一起(比如上图中计算了 3*3 的像素),因此能够理解时间模式。
另外,CNN 可以「看到」一组像素组合成一条直线或者曲线。由于深度神经网络通常都是多层卷积的堆叠,通过上一层得到了直线或者曲线后,下一层不再组合像素,而是将线组合成形状,一层一层进行下去,直到形成完整的图片。
要想深入理解 CNN,你需要学习很多基础知识,比如什么是核,什么是池化层。但是现在有很多优秀的开源项目,你可以直接在他们的基础上进行研究并加以利用。
这就引入了另一门技术——迁移学习。
迁移学习
迁移学习使用训练好的深度学习模型来学习特定的任务。
举个栗子,比如你在火车调度公司工作,你们想在不增加劳动力的情况下,预测火车是否晚点。
你完全可以利用 ImageNet 上的卷积神经网络模型,比如说 2015 年的冠军 ResNet。用火车图片重新训练网络,相信我,结果不会让你失望的。
迁移学习主要有两大优势:
- 相比于从头开始训练,只需要少量图片就可以得到很好的效果。ImageNet 竞赛提供了一百万张图片用于训练。使用迁移学习,你只需要 1000 甚至 100 张图片就可以训练出一个很好的模型,因为你的预训练模型已经在一百万张图片上训练过了。
- 较少的训练时间就能实现良好的性能。为了得到和 ImageNet 模型同样好的效果,你可能需要训练数天,这还不包括模型效果不好时对其进行调整所需的时间。然而使用迁移学习,你可能只需要几个小时甚至几分钟就可以完成特定任务的训练,大大节省了时间。
图像分类到图像生成
有了迁移学习之后大家产生了许多有趣的想法。既然我们可以处理图像、识别图像中的信息,那我们为什么不自己生成图像呢?
因吹斯汀!
生成对抗网络由此应运而生。

朱俊彦等人提出的 CycleGAN
给定某些输入,这项技术可以生成对应的图片。
如上图所示,CycleGAN 可以根据一幅画生成对应的真实照片,也可以根据草图生成背包的照片,甚至可以进行超分辨率重建。

超分辨率生成对抗网络
很神奇,对吗?
当然,你可以学习构建这些网络。但如何开始呢?
卷积神经网络教程
首先你要知道,入门很简单,但掌握就不是那么容易了。
我们先最基础的开始。

航拍仙人掌识别
这是 Kaggle 上的学习项目,你的任务是识别航拍图像中是否有柱状仙人掌。
是不是看起来非常简单?
Kaggle 提供了 17500 张图片,其中 4000 张未标注的作为测试集。如果你的模型能够正确标注 4000 张图片,就会得满分 1 或者 100%。
我找了好久,终于找到下面这个非常适合新手入门的项目。

仙人掌
这张图像与上面的类似。它大小为 32*32,其中包含或者不包含柱状仙人掌。因为是航拍图片所以包含各种不同角度。
所以你需要什么呢?
用 Python 构建卷积神经网络
是的,Python——深度学习领域最受欢迎的语言。至于深度学习框架,你有很多种选择,可以自己逐一尝试:
- Tensorflow,最受欢迎的深度学习框架,由谷歌工程师构建,并且拥有最多的贡献者和粉丝。由于社群比较庞大,当你有问题时可以很容易找到解决方案。它们的高阶 API keras,在入门者中很受欢迎。
- Pytorch,我最喜欢的深度学习框架。纯 Python 实现,因此继承了 Python 的各种优缺点。Python 开发者会很容易上手。它还有 FastAI 库提供抽象,就像 Keras 之于 Tensorflow。
- MXNet,Apache 开发的深度学习框架。
- Theano,Tensorflow 的前身。
- CNTK,微软开发的深度学习框架。
这篇教程中使用的就是我最喜欢的 Pytorch,并且使用 FastAI。
开始之前,你需要安装 Python。浏览 Python 的官网,下载你需要的版本。需要确保的是一定要用 3.6+的版本,否则将不支持你需要用到的一些库。
现在,打开你的命令行或者终端,安装下面这些库:
pip install numpy pip install pandas pip install jupyter
Numpy 用于存储输入图像,pandas 用于处理 CSV 文件,Jupyter notebook 用于编码。
然后,去 Pytorch 官网下载需要的版本,并且如果你想加速训练的话,要安装 CUDA 版本的 Pytorch,并且版本至少是 1.0 以上。
上面这些搞定之后,安装 torchvision 和 FastAI:
pip install torchvision pip install fastai
运行 Jupyter notebook 命令,打开 Jupyter,它将打开一个浏览器窗口。

这样所需环境就配置好了,我们开始吧。
准备数据
导入需要的代码:
import numpy as np import pandas as pd from pathlib import Path from fastai import * from fastai.vision import * import torch %matplotlib inline
Numpy 和 Pandas 基本是做什么任务都会需要的。FastAI 和 Torch 是你的深度学习库。Matplotlib Inline 用于显示图表。
下面就可以从 Kaggle 竞赛官网上下载数据了。
解压 zip 文件,并放置于 Jupyter notebook 文件夹中。
假设你的 notebook 被命名为 Cacti。你的文件夹结构会是下面这样:

Train 文件夹里包含所有的训练图片。
Test 文件夹是用于提交的测试图片。
Train CSV 文档里包含训练数据的信息,将图片名与列 has_cactus 映射,如果该列有 cactus,则值为 1,否则为 0。
Sample Submission CSV 中是提交所需的格式。文件名和 Test 文件夹中的图片相对应。
train_df = pd.read_csv("train.csv")
将 Train CSV 文档加载到数据帧中。
data_folder = Path(".")
train_images = ImageList.from_df(train_df, path=data_folder, folder='train')
利用 ImageList from_df 方法创建加载生成器,以便将 train_df 数据帧和 train 文件夹中的图像进行映射。
数据增强
这是一种根据现有数据创建更多数据的技术。一张猫的图片水平翻转之后仍然是猫的图片。但通过这样做,你可以把你的数据扩增至两倍、四倍甚至 16 倍。
如果你数据量比较少,可以尝试这种方法。
transformations = get_transforms(do_flip=True, flip_vert=True, max_rotate=10.0, max_zoom=1.1, max_lighting=0.2, max_warp=0.2, p_affine=0.75, p_lighting=0.75)
FastAI 提供了 get_transform 函数来做这些事情。你可以水平翻转、垂直翻转、旋转、放大、提高光度/亮度或者加仿射变换来增强数据。
你可以用我上边提供的参数试一下图片会变成什么样。或者你可以详细阅读官方文档。
然后,对你的图像序列做上述预处理。
train_img = train_img.transform(transformations, size=128)
参数大小将用于放大或缩小输入,以匹配你将使用的神经网络。我所用的网络是 DenseNet——ImageNet 2017 最佳论文奖的成果,它要输入的图像大小为 128*128。
准备训练
读取数据之后,就到了深度学习最关键的一步——训练。这个过程也是深度学习中学习的由来。网络从你的数据中学习并且依据学习到的结果调整自身参数,直到在数据上得到比较好的效果。
test_df = pd.read_csv("sample_submission.csv")
test_img = ImageList.from_df(test_df, path=data_folder, folder='test')
train_img = train_img
.split_by_rand_pct(0.01)
.label_from_df()
.add_test(test_img)
.databunch(path='.', bs=64, device=torch.device('cuda:0'))
.normalize(imagenet_stats)
在训练这一步,你需要把训练数据分出一小部分做验证集。你不可以用这部分数据来训练,因为它们只是用来做验证的。当你的卷积神经网络在验证集上效果较好时,很有可能在测试集上也可以提交一个比较好的结果。
FastAI 提供了 split_by_rand_pct 函数,可以很方便地进行以上操作。
databunch 函数可以进行批处理。由于 GPU 内存限制,我的批大小为 64。如果你没有 GPU,忽略 device 参数这一项。
之后,由于你使用的是预训练网络,用 normalize 函数来进行图像归一化。imagenet_stats 函数会根据 ImageNet 预训练模型的训练方式归一化输入图像。
把测试数据也加入训练数据列表里,可以使稍后预测更容易,免得再进行一次预处理。记住,这些图像不能用于训练,也不可以用来做验证。这样做只是为了确保训练图片和测试图片采用了完全相同的预处理方式。
learn = cnn_learner(train_img, models.densenet161, metrics=[error_rate, accuracy])
现在数据准备工作已经做完了。现在,用 cnn_leaner 创建一个训练器。如上所述,我是采用 DenseNet 作为预训练网络的,当然你也可以选择 TorchVision 提供的其他网络。
单周期技术
现在你可以开始训练了。但是,包括卷积神经网络在内,深度学习训练的一大难题就是,如何选择正确的学习率。学习率决定了进行梯度下降时更新参数减小误差的幅度。
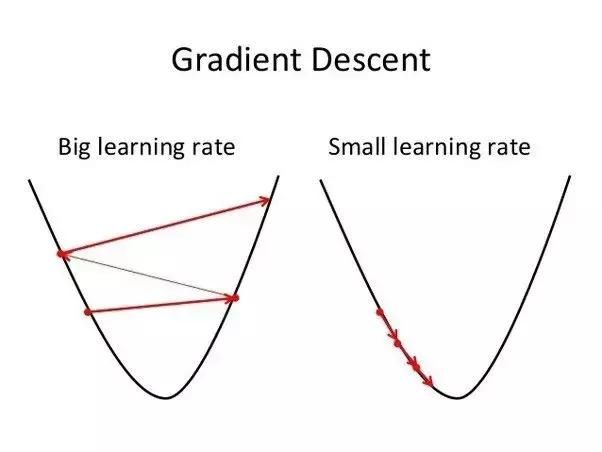
如上图所示,大一些的学习率使训练过程更快,但更容易错过误差边界,甚至会跳出可控范围,无法收敛。然而,当使用稍微小一点的学习率时,训练过程会更慢,但不会发散。
所以,选择合适的学习率非常重要。我们要找到的是足够大却又不会使训练发散的恰当学习率。
但说起来容易做起来难。
所以,一个叫 Leslie Smith 的人提出了单周期策略。
简单来说,就是先暴力查找几个不同的学习率,然后选择一个最接近最小误差但还有进步空间的。代码如下:
learn.lr_find() learn.recorder.plot()
你会得到如下输出:
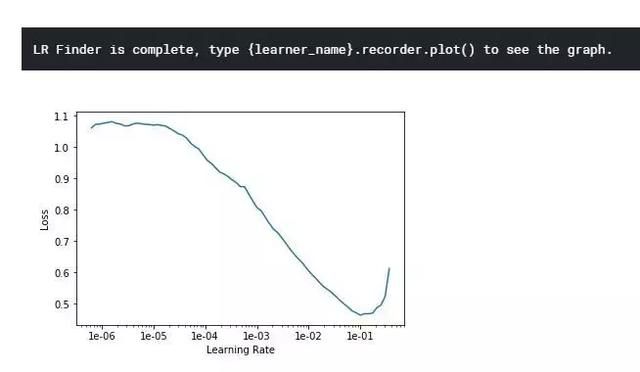
误差最小值在 10^-1 位置,所以我们可以使用略小于这个值的学习率,比如 3*10^-2。
lr = 3e-02 learn.fit_one_cycle(5, slice(lr))
训练几个 epoch(这里我选择 5,不太大也不太小),然后看看结果。
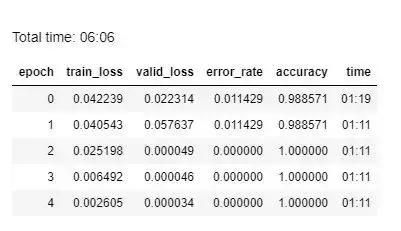
等等,怎么回事?!
验证集准确率达到了 100%!训练过程实际上是非常高效的,只用了六分钟时间。多么幸运!实际上,你可能需要数次迭代才能找到合适的算法。
我等不及要提交了!哈哈。下面让我们预测并提交测试集结果吧。
preds,_ = learn.get_preds(ds_type=DatasetType.Test) test_df.has_cactus = preds.numpy()[:, 0]
由于之前已经把测试图片放入训练图片列表中了,因此不需要再对测试图片做预处理。
test_df.to_csv('submission.csv', index=False)
上面这行代码会创建一个 CSV 文件,其中包含 4000 张测试图像的名称以及每张图像是否包含仙人掌的 label。
当我尝试提交时,我发现需要通过 Kaggle 核来提交 CSV,这是我之前没有注意到的。

幸运的是,核的操作和 Jupyter notebook 非常相似。你完全可以把 notebook 里创建的东西复制粘贴过来,然后提交。
然后,Duang~完成了!

天呐!得分竟然为 0.9999,这已经非常好了。当然如果第一次尝试就得到这么好的分数,应该还有进步的空间。
所以,我调整了网络结构,又尝试了一次。

得分为 1!我做到了!!所以你也可以,实际上并不是那么困难。
(另外,这个排名是 4 月 13 号的,我的排名现在很有可能已经下降了…)
我学到了什么
这个项目很简单,你在解决任务的过程中也不会遇到什么奇怪的挑战,所以这个项目非常适合入门。
并且由于已经有很多人得满分了,我觉得主办方应该另外创建一个用于提交的测试集,难度最好更高一点。
不管怎么样,从这个项目开始基本没有什么困难。你可以马上尝试并且获得高分。

卷积神经网络对各种不同的任务都很有效,不论是图像识别还是图像生成。现在分析图像并不像以前那么难。当然,如果你尝试的话也可以做到。
所以,选择一个好的卷积神经网络项目,准备好高质量的数据,开始吧!
关卷积神经网络CNN方面的使用,前景,就业还有很多很多,此处就不多做介绍了,为了方便大家,我也整理了很多计算机视觉,机器学习,深度学习方面的学习资料,包含:论文,视频,文章,行业报告,书籍,项目代码等
免费分享给大家,整理了很久,非常全面。包括一些人工智能基础入门视频+AI常用框架实战视频、图像识别、OpenCV、NLP、YOLO、机器学习、pytorch、计算机视觉、深度学习与神经网络等视频、课件源码、国内外知名精华资源、AI热门论文等。
由于站内屏蔽外链【易失效】
以上课程资料+500G人工智能资料都已放置在
vx公众号【咕泡AI 回复888】白嫖 ~领哈
这是一些资料截图,先到先得!喜欢就点赞收藏吧!