2022吴恩达机器学习课程学习笔记(第二课第三周)
2022吴恩达机器学习课程学习笔记(第二课第三周)
- 决定接下来该做什么
- 模型评估
- 模型选择和训练/交叉验证/测试集
- 通过偏差和方差进行诊断
- 正则化和偏差/方差
- 制定一个用于性能评估的基准
- 学习曲线
- (修订)决定下一步做什么
- 偏差/方差和神经网络
- 机器学习开发的迭代
- 错误分析
- 添加更多数据
-
- 添加数据的类型
- 数据增强
- 数据合成
- 讨论
- 迁移学习:使用其他任务中的数据
-
- 迁移学习原理
- 迁移学习有效的原因
- 总结
- 机器学习项目中的完整周期
- 公平、偏见与伦理
- 偏斜数据集的误差指标
- 精准率和召回率的权衡
决定接下来该做什么
本周将分享一些关于如何在机器学习项目中决定下一步该做什么的实用建议。
有效构建机器学习算法的关键在于找到一种对于在哪里投入时间做出正确选择的办法。
模型评估
我们将数据集分成训练集和测试集两个子集,在训练集上训练模型、参数,在测试集上测试性能。
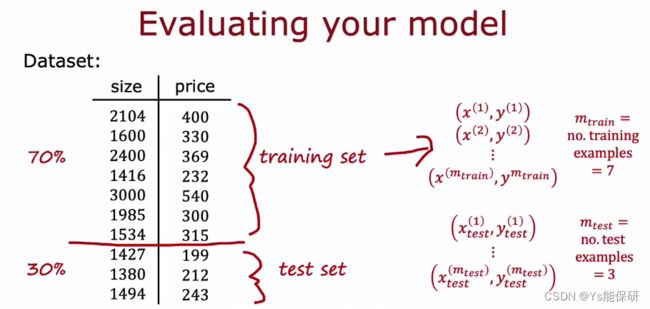 对于线性回归问题:
对于线性回归问题:

Jtest 衡量模型在测试集上的性能。
Jtrain 衡量模型在训练集上的性能。
对于分类问题:
除了和回归问题类似的计算方法,还有另一种方法。

计算在训练集或者测试集上分类错误的比例。
模型选择和训练/交叉验证/测试集
一旦模型参数 w 和 b 已经适合训练集,Jtrain 要比实际的泛化误差(不在训练集中的新示例的平均误差)要低,而 Jtest 能较好地(相对于 Jtrain)估计泛化误差。

直观上,我们在选择模型的时候会选择一个 Jtest 最小的模型,当我们想估计这个模型表现如何时,可以之间报告 Jtest。
但这个过程有一个缺陷就是 Jtest 很可能是泛化误差的乐观估计(低于实际的泛化误差)。
可以类比到使用训练集训练 w 和 b 会使 Jtrain 成为泛化误差的一个过度乐观估计,使用测试集训练 d(多项式次数) 也会使 Jtest 成为泛化误差的乐观估计。
PS:我自己的理解,使用训练集我们想选择的就是适当的 w 和 b 使得 Jtrain 最小,对于未知数据集来讲,这是一个最乐观的估计,使用测试集选择模型时,我们选择的也是合适的 d 使得 Jtest 最小,此时再用 Jtest 作为泛化误差,肯定也是偏小的。
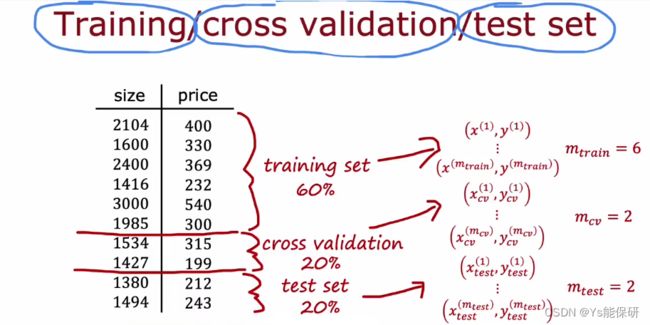
所以,我们将数据集分为训练集、交叉验证集、测试集。
交叉验证集用于检查不同模型的有效性和真实性,也叫做验证集、开发集。

所以我们选择合适模型的方法是:使用训练集拟合参数,使用交叉验证集选择模型,使用测试集估计泛化误差。
通过偏差和方差进行诊断
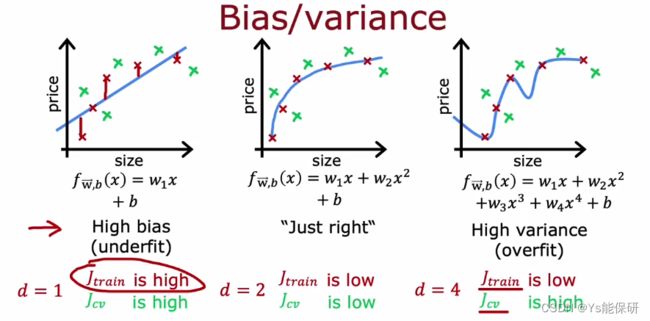
我们在之前学习的,欠拟合也叫高偏差;过拟合也叫高方差。
不通过作图,我们也可以通过计算 Jtrain 和 Jcv 来判断模型是否具有高偏差或者高方差。
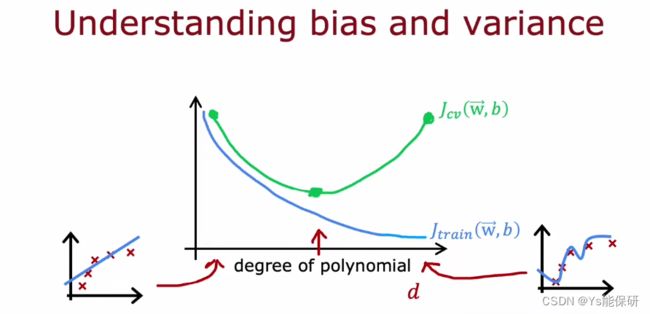
随着多项式次数的增加,显示发生欠拟合、然后是恰好拟合、最后发生过拟合,Jtrain 越来越低,Jcv 先降低后升高。

综上,诊断学习算法的偏差和方差的方法:
- 如果 Jtrain 很高,则具有高偏差。
- 如果 Jcv 远高于 Jtrain,则具有高方差。
- 如果 Jtrain 很高,并且 Jcv 远高于 Jtrain,则同时具有高偏差和高方差。
对于部分数据发生过拟合,对于部分数据发生欠拟合时,会出现同时具有高偏差和高方差的情况。
正则化和偏差/方差

λ 很大时,代价函数会过于注重减小参数的值,极端情况参数为 0,发生欠拟合;
λ 很小时,代价函数会过于注重拟合数据,极端情况 λ 为 0,发生过拟合。

和选择多项式次数 d 时的方法一样,计算不同 λ 值对应的 Jcv 值,选择最小的 Jcv 对应的 λ 值,然后以此时的 Jtest 作为泛化误差。
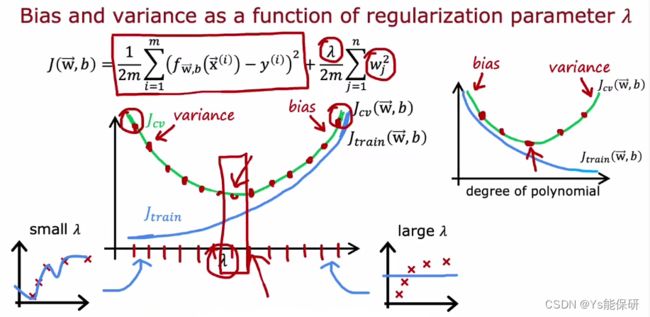
以 λ 为自变量和以 d 为自变量时对应的 Jtrain 和 Jcv 图像是非严格镜像的,因为 λ 较小时和 d 较大时 对应的是过拟合,相反,λ 较大和 d 较小时对应的是欠拟合。
制定一个用于性能评估的基准
以语音识别为例看看学习算法是否具有高偏差或高方差,此时训练误差意味着音频中没有被正确识别的音频百分比。

Jtrain = 10.8% 意味着训练集中有 89.2% 的音频被正确识别。
直观上看来,训练集误差和交叉验证集误差都很高,但事实上我们还有另一项有用的标准,人类表现性能,即人类识别的正确率,训练误差仅比人类识别误差高 0.2%,而交叉验证误差比训练误差高 4.0%,因此可以看出此模型具有高方差问题而不是高偏差问题。

当判断训练误差是否高时,通常建立一个性能评估基准。

前两个数据之间的差距决定了是否存在高偏差问题,后两个数据之间的差距决定了是否存在高方差问题。
学习曲线
学习曲线是一种学习算法性能和实验数量之间的函数。
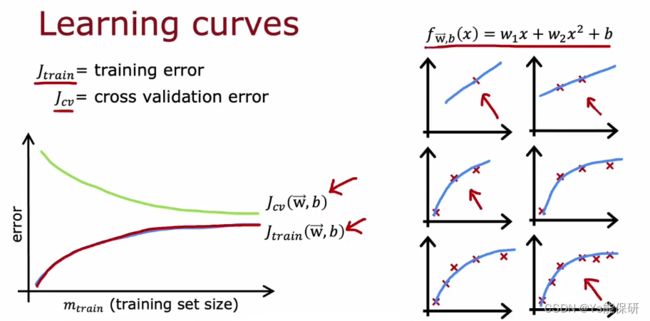
通常情况下,随着数据量的增多,交叉验证误差随之下降,而训练误差会上升,因为数据越多,模型很难完美的契合每个数据,但是训练误差会低于交叉验证误差,因为我们拟合数据的时候是希望训练误差尽量小。
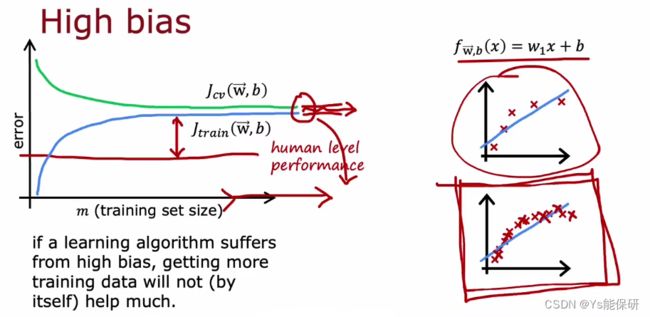
当学习算法具有高偏差时,增加数据量不会降低训练误差。
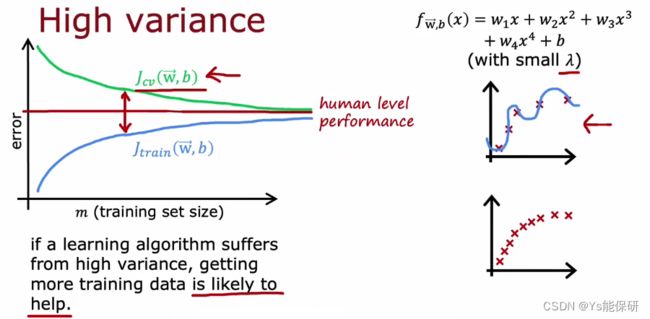
当学习算法具有高方差时,增加数据量会有所帮助。
综上,当我们发现模型性能没有达到我们的预期时,不要盲目地增加数据量,要看看问题出现在了哪里,才能有效地解决。
(修订)决定下一步做什么

如果发现你的算法具有很高的方差,解决方法是:
- 获得更多的训练数据。
- 简化模型(获得更小的特征集或者增加正则化参数 λ)
如果发现你的算法具有很高的偏差,解决办法是:
- 使模型更强大(获得更大的特征集或者减小正则化参数 λ)
偏差/方差和神经网络
神经网络出现之前,机器学习工程师必须在偏差和方差之间权衡,即平衡多项式次数的复杂性或者正则化参数 λ 以使偏差和方差不会太高。
而神经网络让我们摆脱了必须权衡偏差与方差的困境。

当神经网络足够大时,只要训练集不是太大,几乎总能适应训练集,唯一不足是会使速度减慢。
当模型在训练集上表现不好时,即高偏差问题,则需要使用更大的神经网络,直至在训练集上表现良好。
当在交叉验证集上表现不好时,即高方差问题,则需获取更多的数据并重新训练。
但这个方法也有局限性,训练更大的神经网络虽然会减少偏差,但是也会使计算速度变慢,而且有时我们无法得到更多的数据。
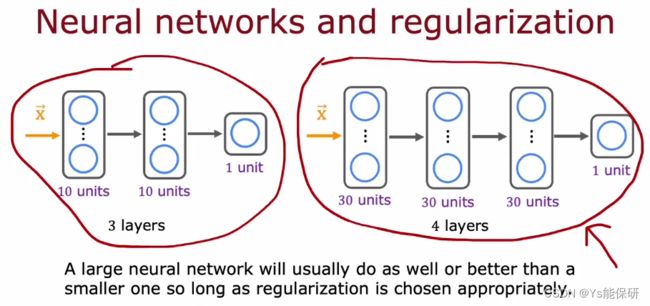
事实证明,一个具有良好正则化的大型神经网络通常要比较小的网络做得更好。

如图所示,是使用 Tensorflow 实现神经网络的正则化。
机器学习开发的迭代
错误分析
错误分析是继偏差与方差之后最重要的诊断模型的方法。
错误分析是指手动查看出现错误的样例,并试图深入了解算法出错的地方,一般是按照共同的属性将他们分组。

此时我们会发现什么问题是重要的,什么问题是相对次要的。
而当我们拥有一个很大的数据集时,通常是选择一部分数据进行分析。
添加更多数据
添加数据的类型
当我们在训练机器学习算法时,我们总是希望拥有更多的数据。因此,有时我们想获得更多所有类型的数据,但是有时候既慢又贵,此时我们专注于添加对我们的分析更有帮助的数据会更高效。
也就是说,如果我们有办法添加更多的各种类型的数据,那是最好,否则,如果错误分析表明在某些问题上我们的算法性能非常差,我们就专注于获取这部分数据可能会更有效。
数据增强
利用现有的训练样例创建一个新的训练样例。
可能通过旋转、缩放、改变对比度、镜像等方式。
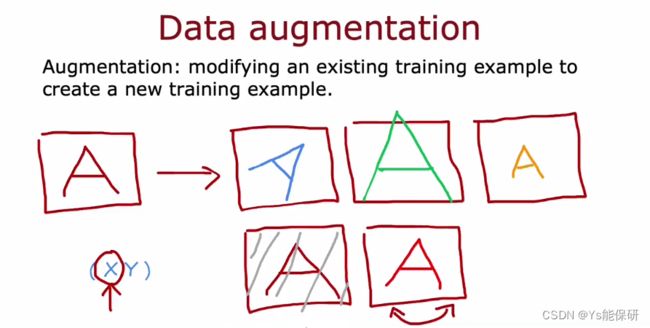
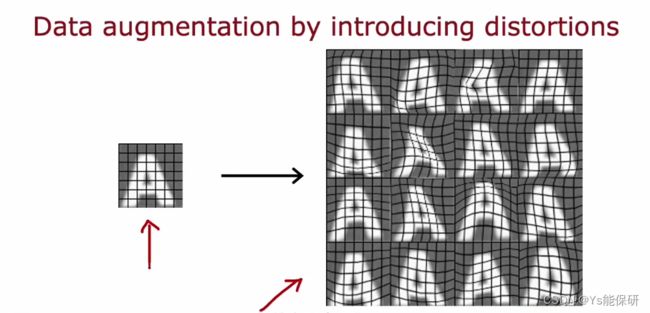
也可以通过引入网格进行随机扭曲。
 同样的数据增强也适用于声音识别。
同样的数据增强也适用于声音识别。

数据增强的一个技巧是对数据所做的更改或扭曲,应该代表测试集中的噪声类型;而对于数据纯粹随机无意义的噪声通常没有多大帮助。

数据合成
不是通过修改现有的示例,而是从头构建全新的示例。
以 photo OCR (自动让计算机读取图像中显示的文本)为例,用电脑生成的图片看起来也很逼真。

数据合成多数用于计算机视觉,而较少用于其他应用程序。
讨论

机器学习在过去的几十年发展中,大多数机器学习研究人员的注意力都集中在以传统的模型为中心,也就是说他们下载固定的数据集,并专注于改进算法或模型。
而今天很多算法已经非常好了,并且适用于许多应用程序,因此,有时花更多时间采用以数据为中心的算法会更有成效。
迁移学习:使用其他任务中的数据
迁移学习原理
假设我们想识别手写数字,但没有那么多的数据,但是我们发现了一个非常大的数据集,我们就可以首先在这个大的数据集上训练一个神经网络,然后复制这个神经网络,但是要替换输出层。

也就是说,在迁移学习中,我们使用除输出层外的所有层的参数作为新神经网络参数的起点,然后运行优化算法,具体来说,有两种方法可以训练这个神经网络的参数。
- 保持输出层以前的参数不变,只训练输出层参数。
- 以输出层以前的参数为起点,训练网络中的所有参数。
第一种方法适用于非常非常小的数据集,第二种方法适用于稍大一些的数据集。
直觉上,我们是希望神经网络通过学习大的数据集学到了一些东西,然后稍微在新的数据集上一训练,就能起到较好的效果。
总结一下,迁移学习分为两步:监督预训练和微调。
迁移学习有效的原因
第一层能够检测图像边缘,第二层能够检测图像角落,第三层能够检测图像曲线或者其他一些基本的形状。
通过学习大量数据,我们已经教会神经网络检测边缘、角落和一些基本形状,这些对于其他计算机视觉的任务也很有帮助。
预训练的一个限制就是预训练和微调步骤的图片尺寸必须相同。
总结

机器学习项目中的完整周期
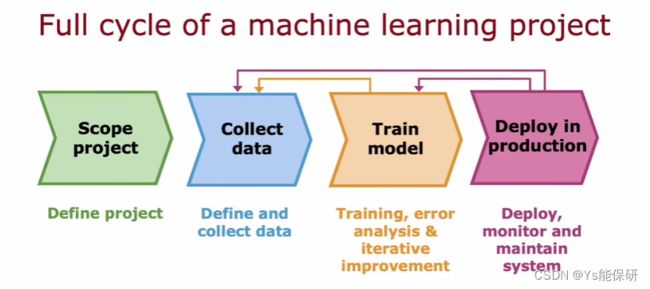
一个完整的机器学习周期包括:
- 确定项目范围,即决定你想要做什么。
- 收集数据。
- 训练模型。
- 部署在生产环境中,这意味着可以供用户使用。
-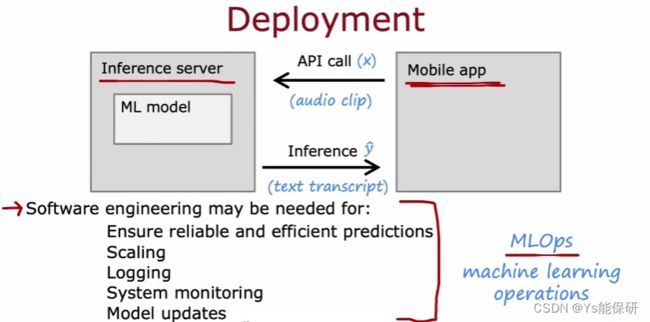
部署模型的一种常见方法就是采用你的机器学习模型并在服务器中实现它,移动应用程通过 API 调用,将音频传给服务器,服务器将翻译文本传回应用程序。
公平、偏见与伦理
不要设计不公平、有偏见、违反伦理道德的机器学习算法,例如性别歧视、种族歧视等。
偏斜数据集的误差指标
偏斜数据集指的是正例和反例比例失衡的数据集。
只用准确率来衡量算法是否有效通常是不可靠的。

比如我们设计了一个算法,准确率在 99%,但实际上这是一种非常罕见的疾病,发病率仅有 0.5%,那如果我们让另一个算法只输出 0(即没患病),那么准确率达到了 99.5%,但是很明显这不是一个更好的算法。
所以,一种常见的度量就是精准率和召回率。
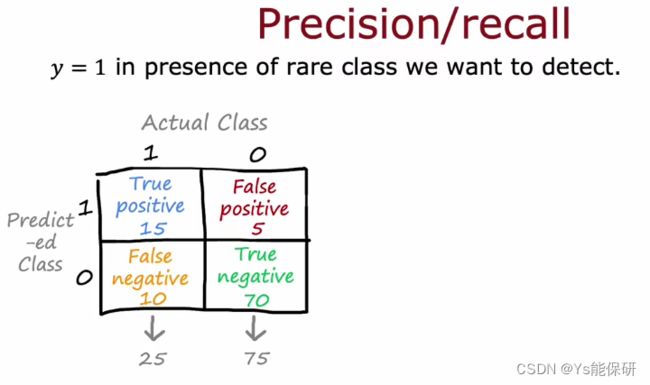
首先给出下面四个定义(总觉得着这些定义挺吓人 bushi):
真阳性:实际患病,预测患病。
假阳性:实际没患病,预测患病。
假阴性:实际患病,预测没患病。
真阴性:实际没患病,预测没患病。

精准率:所有我们预测患病的群体中,真正患病的比例,即 真阳性 / 预测为阳性 或 真阳性 / (真阳性 + 假阳性)。
召回率:所有真正患病的群体中,我们预测患病的比例,即 真阳性 / 实际为阳性 或 真阳性 /( 真阳性 + 假阴性)。
使用这两个标准衡量算法时,如果算法只输出 0,那召回率将为 0,精准率为 0 / 0,有时也说其等于 0。
精准率和召回率的权衡
高精准率意味着如果诊断出患有这种罕见疾病的患者,很可能就患病,即这是一个准确的诊断。
高召回率意味着如果有一个还有这种罕见病的患者,算法很可能会正确识别出他们确实患有这种病。
那么如何在精准率和召回率之间权衡呢?
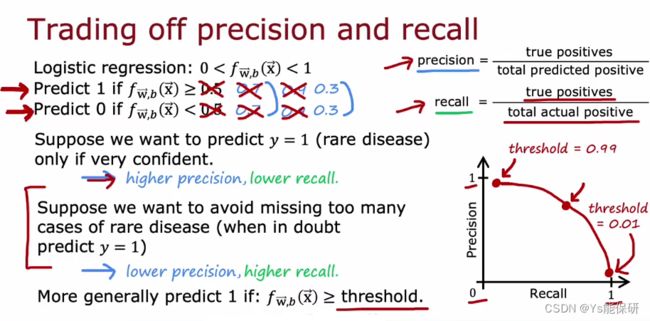
假设我们使用逻辑回归算法,当提高阈值时,准确率提高,召回率降低;降低阈值时,准确率降低,召回率提高。
根据不同的阈值我们可以画出精准率和召回率曲线。
除了手动选择阈值以外,我们话可以定义一个指标,F1 分数*。
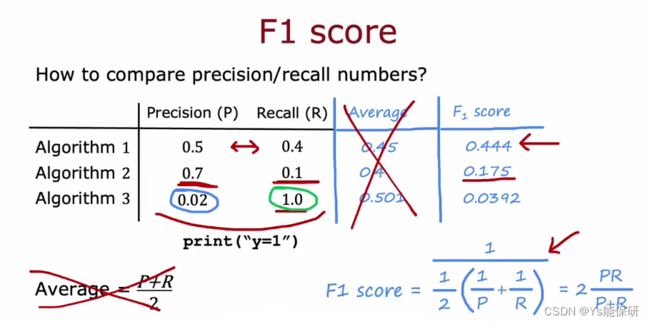
F1 分数是一种计算平均分数的方法,它更关注较低的分数,也叫调和均值。