机器学习之高斯混合模型(GMM)及python实现
高斯混合模型
高斯混合模型简介:
高斯混合模型是一种无监督聚类算法,一般使用EM算法进行求解。
Kmeans VS GMM:Kmeans算法本质上用的也是EM算法求解的。
本章节内容参考了李航博士的《统计学习方法》
本节不同之处在于分析讨论了多维度空间的高斯混合模型
1 高斯混合模型推导
1.1 高斯混合模型
定义:高斯混合模型是指具有如下形式的概率分布模型:
p ( y ∣ θ ) = ∑ k = 1 K α k ϕ ( y ∣ θ k ) (1) p(y|\theta) = \sum_{k=1}^K \alpha_k \phi(y|\theta_k) \tag1 p(y∣θ)=k=1∑Kαkϕ(y∣θk)(1)
其中, ϕ k \phi_k ϕk是系数, ϕ k ≥ 0 \phi_k \ge 0 ϕk≥0, ∑ k = 1 K α k = 1 \sum_{k=1}^K \alpha_k = 1 ∑k=1Kαk=1; ϕ ( y ∣ θ k ) \phi(y|\theta_k) ϕ(y∣θk)是高斯分布密度函数, θ k = ( μ k , Σ ) \theta_k=(\mu_k,\Sigma) θk=(μk,Σ),
ϕ ( y ∣ θ k ) = 1 ( 2 π ) D 2 ∣ ∣ Σ ∣ ∣ 1 2 e x p [ − 1 2 ( y − μ ) T Σ − 1 ( y − μ ) ] (2) \phi(y|\theta_k) = \frac {1}{(2\pi)^{\frac{D}2} ||\Sigma||^{\frac{1}{2}}} exp [-\frac{1}{2} (y-\mu)^T \Sigma^{-1} (y - \mu)] \tag2 ϕ(y∣θk)=(2π)2D∣∣Σ∣∣211exp[−21(y−μ)TΣ−1(y−μ)](2)
称为第 k k k个分模型,其中 D D D是当个特征的特征维度。
Σ \Sigma Σ的解释:
Σ \Sigma Σ是对称矩阵, Σ T = Σ \Sigma^T=\Sigma ΣT=Σ
1.2 高斯混合模型参数估计的EM算法
假设观测数据 y 1 , y 2 , . . . , y N y_1,y_2,...,y_N y1,y2,...,yN(每个样本维度是 D D D)由高斯混合模型生成,
p ( y ∣ θ ) = ∑ k = 1 K α k ϕ ( y ∣ θ k ) (3) p(y|\theta) = \sum_{k=1}^K \alpha_k \phi(y|\theta_k) \tag3 p(y∣θ)=k=1∑Kαkϕ(y∣θk)(3)其中, θ = ( α 1 , α 2 , . . . , α K ; θ 1 , θ 2 , . . . , θ K ) \theta=(\alpha_1, \alpha_2,...,\alpha_K;\theta_1,\theta_2,...,\theta_K) θ=(α1,α2,...,αK;θ1,θ2,...,θK).
设想样本是这样产生的:
1.依据概率 α k \alpha_k αk, 选择对应的高斯分布模型;
2.依据高斯分布模型生成观测数据。
对于已知的观测数据,反映某个观测数据 y j y_j yj来自哪一个分模型是未知的,这也就是这个模型中的隐变量,以 γ j k \gamma_{jk} γjk表示。
加入隐变量可以得到全变量的似然函数:
p ( y , γ ∣ θ ) = ∏ j = 1 N ∏ k = 1 K [ α k ϕ ( y ∣ θ k ) ] γ j k (4) p(y,\gamma|\theta)= \prod_{j=1}^{N} \prod_{k=1}^{K} [\alpha_k \phi(y|\theta_k)]^{\gamma_{jk}} \tag4 p(y,γ∣θ)=j=1∏Nk=1∏K[αkϕ(y∣θk)]γjk(4)
这个有一个点需要说明一下:
就是(3)式和(4)的表达式是有区别的。通俗的说(3)式是求和形式,而(4)式是求积的形式。
这是因为(3)式是对模型的表示,即表示模型的构成;而(4)式是所有变量对于单个变量的似然函数表示。
对应的对数似然函数:
log p ( y , γ ∣ θ ) = log ∏ j = 1 N ∏ k = 1 K [ α k ϕ ( y j ∣ θ k ) ] γ j k = ∑ j = 1 N ∑ k = 1 K γ j k log [ α k ϕ ( y j ∣ θ k ) ] = ∑ j = 1 N ∑ k = 1 K γ j k [ log α k + log ϕ ( y j ∣ θ k ) ] = ∑ k = 1 K [ ∑ j = 1 N γ j k log α k + ∑ j = 1 N γ j k log ϕ ( y j ∣ θ k ) ] \begin{aligned} \log p(y,\gamma|\theta) &= \log \prod_{j=1}^{N} \prod_{k=1}^{K} [\alpha_k \phi(y_j|\theta_k)]^{\gamma_{jk}} \\ &= \sum_{j=1}^{N} \sum_{k=1}^{K} {\gamma_{jk}} \log [\alpha_k \phi(y_j|\theta_k)] \\ &= \sum_{j=1}^{N} \sum_{k=1}^{K} {\gamma_{jk}} [\log \alpha_k + \log \phi(y_j|\theta_k)] \\ &= \sum_{k=1}^{K} [\sum_{j=1}^{N} {\gamma_{jk}}\log \alpha_k + \sum_{j=1}^{N} \gamma_{jk} \log \phi(y_j|\theta_k)] \\ \end{aligned} logp(y,γ∣θ)=logj=1∏Nk=1∏K[αkϕ(yj∣θk)]γjk=j=1∑Nk=1∑Kγjklog[αkϕ(yj∣θk)]=j=1∑Nk=1∑Kγjk[logαk+logϕ(yj∣θk)]=k=1∑K[j=1∑Nγjklogαk+j=1∑Nγjklogϕ(yj∣θk)]
E 步:
隐变量 γ j k \gamma_{jk} γjk表示观测数据 y j y_j yj来自哪一个分模型,所以:
γ ^ j k = α k ϕ ( y i ∣ θ k ) ∑ k = 1 K α k ϕ ( y i ∣ θ k ) \hat \gamma_{jk} = \frac {\alpha_k \phi(y_i|\theta_k)}{\sum_{k=1}^{K} \alpha_k \phi(y_i|\theta_k)} γ^jk=∑k=1Kαkϕ(yi∣θk)αkϕ(yi∣θk)
又有:
Q ( θ , θ ( i ) ) = ∑ k = 1 K [ ∑ j = 1 N γ ^ j k log α k + ∑ j = 1 N γ ^ j k log ϕ ( y j ∣ θ k ) ] Q(\theta, \theta^{(i)}) = \sum_{k=1}^{K} [\sum_{j=1}^{N} {\hat \gamma_{jk}}\log \alpha_k + \sum_{j=1}^{N} \hat \gamma_{jk} \log \phi(y_j|\theta_k)] Q(θ,θ(i))=k=1∑K[j=1∑Nγ^jklogαk+j=1∑Nγ^jklogϕ(yj∣θk)]
将(2)式带入得:
Q ( θ , θ ( i ) ) = ∑ k = 1 K { ∑ j = 1 N γ ^ j k log α k + ∑ j = 1 N γ ^ j k log 1 ( 2 π ) D 2 ∣ ∣ Σ k ∣ ∣ 1 2 e x p [ − 1 2 ( y j − μ k ) T Σ k − 1 ( y j − μ k ) ] } Q(\theta, \theta^{(i)}) = \sum_{k=1}^{K} \{\sum_{j=1}^{N} {\hat \gamma_{jk}}\log \alpha_k + \sum_{j=1}^{N} \hat \gamma_{jk} \log \frac {1}{(2\pi)^{\frac{D}2} ||\Sigma_k||^{\frac{1}{2}}} exp [-\frac{1}{2} (y_j-\mu_k)^T \Sigma_{k}^{-1} (y_j - \mu_k)] \} Q(θ,θ(i))=k=1∑K{j=1∑Nγ^jklogαk+j=1∑Nγ^jklog(2π)2D∣∣Σk∣∣211exp[−21(yj−μk)TΣk−1(yj−μk)]}
上式展开得:
Q ( θ , θ ( i ) ) = ∑ k = 1 K { ∑ j = 1 N γ ^ j k log α k − ∑ j = 1 N γ ^ j k log ( 2 π ) D 2 − ∑ j = 1 N γ ^ j k 2 log ∣ ∣ Σ k ∣ ∣ − ∑ j = 1 N γ ^ j k [ 1 2 ( y j − μ k ) T Σ k − 1 ( y j − μ k ) ] } Q(\theta, \theta^{(i)}) = \sum_{k=1}^{K} \{\sum_{j=1}^{N} {\hat \gamma_{jk}}\log \alpha_k - \sum_{j=1}^{N} \hat \gamma_{jk} \log (2\pi)^{\frac{D}2} - \sum_{j=1}^{N} \frac{\hat \gamma_{jk}}{2} \log ||\Sigma_k|| - \sum_{j=1}^{N} \hat \gamma_{jk} [\frac{1}{2} (y_j-\mu_k)^T \Sigma_{k}^{-1} (y_j - \mu_k)] \} Q(θ,θ(i))=k=1∑K{j=1∑Nγ^jklogαk−j=1∑Nγ^jklog(2π)2D−j=1∑N2γ^jklog∣∣Σk∣∣−j=1∑Nγ^jk[21(yj−μk)TΣk−1(yj−μk)]}
可以从matrix cookbook 找到矩阵偏导
1.求 μ \mu μ
先整理出来含有 μ \mu μ的项:
L ( μ k ) = − ∑ j = 1 N γ ^ j k [ 1 2 ( y j − μ k ) T Σ k − 1 ( y j − μ k ) ] L(\mu_k) = - \sum_{j=1}^{N} \hat \gamma_{jk} [\frac{1}{2} (y_j-\mu_k)^T \Sigma_{k}^{-1} (y_j - \mu_k)] L(μk)=−j=1∑Nγ^jk[21(yj−μk)TΣk−1(yj−μk)]
∂ L ( μ k ) ∂ μ k = ∑ j = 1 N γ ^ j k Σ k − 1 ( y j − μ k ) ) \frac {\partial L(\mu_k)}{\partial \mu_k} = \sum_{j=1}^{N} \hat \gamma_{jk} \Sigma_{k}^{-1} (y_j - \mu_k)) ∂μk∂L(μk)=j=1∑Nγ^jkΣk−1(yj−μk))
令 ∂ L ( μ k ) ∂ μ k = 0 \frac {\partial L(\mu_k)}{\partial \mu_k} =0 ∂μk∂L(μk)=0 得:
μ ^ k = ∑ j = 1 N γ ^ j k y j ∑ j = 1 N γ ^ j k \hat \mu_k = \frac {\sum_{j=1}^{N} \hat \gamma_{jk} y_j} {\sum_{j=1}^{N} \hat \gamma_{jk}} μ^k=∑j=1Nγ^jk∑j=1Nγ^jkyj
2.求 Σ k \Sigma_k Σk:
同样的先整理出来含有 Σ \Sigma Σ的项:
L ( Σ k ) = − ∑ j = 1 N γ ^ j k 2 log ∣ ∣ Σ k ∣ ∣ − ∑ j = 1 N γ ^ j k [ 1 2 ( y j − μ k ) T Σ k − 1 ( y j − μ k ) ] L(\Sigma_k) = -\sum_{j=1}^{N} \frac{\hat \gamma_{jk}}{2} \log ||\Sigma_k||- \sum_{j=1}^{N} \hat \gamma_{jk} [\frac{1}{2} (y_j-\mu_k)^T \Sigma_{k}^{-1} (y_j - \mu_k)] L(Σk)=−j=1∑N2γ^jklog∣∣Σk∣∣−j=1∑Nγ^jk[21(yj−μk)TΣk−1(yj−μk)]
求导取零可以得到:
Σ ^ k = ∑ j = 1 N γ ^ j k ( y j − μ k ) ( y j − μ k ) T ∑ j = 1 N γ ^ j k \hat \Sigma_k = \frac {\sum_{j=1}^{N} \hat \gamma_{jk} (y_j-\mu_k)(y_j-\mu_k)^T} {\sum_{j=1}^{N} \hat \gamma_{jk}} Σ^k=∑j=1Nγ^jk∑j=1Nγ^jk(yj−μk)(yj−μk)T
3.最后求 α k \alpha_k αk:
L ( α k ) = ∑ j = 1 N γ ^ j k log α k L(\alpha_k) = {\sum_{j=1}^{N} {\hat \gamma_{jk}}\log \alpha_k} L(αk)=j=1∑Nγ^jklogαk
加上限制条件:
∑ k = 1 K α k = 1 (5) \sum_{k=1}^K \alpha_k = 1 \tag5 k=1∑Kαk=1(5)
用朗格朗日函数:
L ( α k , λ ) = ∑ j = 1 N γ ^ j k log α k + λ ( ∑ k = 1 K α k − 1 ) L(\alpha_k, \lambda) = {\sum_{j=1}^{N} {\hat \gamma_{jk}}\log \alpha_k} + \lambda (\sum_{k=1}^K \alpha_k - 1) L(αk,λ)=j=1∑Nγ^jklogαk+λ(k=1∑Kαk−1)
得到:
∂ L ( α k ) ∂ α k = ∑ j = 1 N γ ^ j k 1 α k + λ = 0 \frac {\partial L(\alpha_k)}{\partial \alpha_k} = {\sum_{j=1}^{N} \hat \gamma_{jk}} \frac {1}{\alpha_k} + \lambda = 0 ∂αk∂L(αk)=j=1∑Nγ^jkαk1+λ=0
则:
α k = ∑ j = 1 N γ ^ j k − λ (6) \alpha_k = \frac {\sum_{j=1}^{N} \hat \gamma_{jk}}{-\lambda} \tag6 αk=−λ∑j=1Nγ^jk(6)
将(5)式带入(6)式得:
∑ k = 1 K ∑ j = 1 N γ ^ j k = − λ \sum_{k=1}^K \sum_{j=1}^{N} \hat \gamma_{jk} = -\lambda k=1∑Kj=1∑Nγ^jk=−λ
因为:
∑ k = 1 K γ ^ j k = 1 \sum_{k=1}^K \hat \gamma_{jk} = 1 k=1∑Kγ^jk=1
所以:
− λ = N -\lambda = N −λ=N
故:
α k = ∑ j = 1 N γ ^ j k N \alpha_k = \frac {\sum_{j=1}^{N} \hat \gamma_{jk}}{N} αk=N∑j=1Nγ^jk
2 高斯混合模型python实现
2.1 模型实现
import numpy as np
np.random.seed(None)
class MyGMM(object):
def __init__(self, K=3):
"""
高斯混合模型,用EM算法进行求解
:param K: 超参数,分类类别
涉及到的其它参数:
:param N: 样本量
:param D: 单个样本的维度
:param alpha: 模型参数,高斯函数的系数,决定高斯函数的高度,维度(K)
:param mu: 模型参数,高斯函数的均值,决定高斯函数的中型位置,维度(K,D)
:param Sigma: 模型参数,高斯函数的方差矩阵,决定高斯函数的形状,维度(K,D,D)
:param gamma: 模型隐变量,决定单个样本具体属于哪一个高斯分布,维度(N,K)
"""
self.K = K
self.params = {
'alpha': None,
'mu': None,
'Sigma': None,
'gamma': None
}
self.N = None
self.D = None
def __init_params(self):
# alpha 需要满足和为1的约束条件
alpha = np.random.rand(self.K)
alpha = alpha / np.sum(alpha)
mu = np.random.rand(self.K, self.D)
Sigma = np.array([np.identity(self.D) for _ in range(self.K)])
# 虽然gamma有约束条件,但是第一步E步时会对此重新赋值,所以可以随意初始化
gamma = np.random.rand(self.N, self.K)
self.params = {
'alpha': alpha,
'mu': mu,
'Sigma': Sigma,
'gamma': gamma
}
def _gaussian_function(self, y_j, mu_k, Sigma_k):
'''
计算高纬度高斯函数
:param y_j: 第j个观测值
:param mu_k: 第k个mu值
:param Sigma_k: 第k个Sigma值
:return:
'''
# 先取对数
n_1 = self.D * np.log(2 * np.pi)
# 计算数组行列式的符号和(自然)对数。
_, n_2 = np.linalg.slogdet(Sigma_k)
# 计算矩阵的(乘法)逆矩阵。
n_3 = np.dot(np.dot((y_j - mu_k).T, np.linalg.inv(Sigma_k)), y_j - mu_k)
# 返回是重新取指数抵消前面的取对数操作
return np.exp(-0.5 * (n_1 + n_2 + n_3))
def _E_step(self, y):
alpha = self.params['alpha']
mu = self.params['mu']
Sigma = self.params['Sigma']
for j in range(self.N):
y_j = y[j]
gamma_list = []
for k in range(self.K):
alpha_k = alpha[k]
mu_k = mu[k]
Sigma_k = Sigma[k]
gamma_list.append(alpha_k * self._gaussian_function(y_j, mu_k, Sigma_k))
# 对隐变量进行迭代跟新
self.params['gamma'][j, :] = np.array([v / np.sum(gamma_list) for v in gamma_list])
def _M_step(self, y):
mu = self.params['mu']
gamma = self.params['gamma']
for k in range(self.K):
mu_k = mu[k]
gamma_k = gamma[:, k]
gamma_k_j_list = []
mu_k_part_list = []
Sigma_k_part_list = []
for j in range(self.N):
y_j = y[j]
gamma_k_j = gamma_k[j]
gamma_k_j_list.append(gamma_k_j)
# mu_k的分母的分母列表
mu_k_part_list.append(gamma_k_j * y_j)
# Sigma_k的分母列表
Sigma_k_part_list.append(gamma_k_j * np.outer(y_j - mu_k, (y_j - mu_k).T))
# 对模型参数进行迭代更新
self.params['mu'][k] = np.sum(mu_k_part_list, axis=0) / np.sum(gamma_k_j_list)
self.params['Sigma'][k] = np.sum(Sigma_k_part_list, axis=0) / np.sum(gamma_k_j_list)
self.params['alpha'][k] = np.sum(gamma_k_j_list) / self.N
def fit(self, y, max_iter=100):
y = np.array(y)
self.N, self.D = y.shape
self.__init_params()
for _ in range(max_iter):
self._E_step(y)
self._M_step(y)
2.1 模型检测
def get_samples(n_ex=1000, n_classes=3, n_in=2, seed=None):
# 生成100个样本,为了能够在二维平面上画出图线表示出来,每个样本的特征维度设置为2
from sklearn.datasets.samples_generator import make_blobs
from sklearn.model_selection import train_test_split
y, _ = make_blobs(
n_samples=n_ex, centers=n_classes, n_features=n_in, random_state=seed)
return y
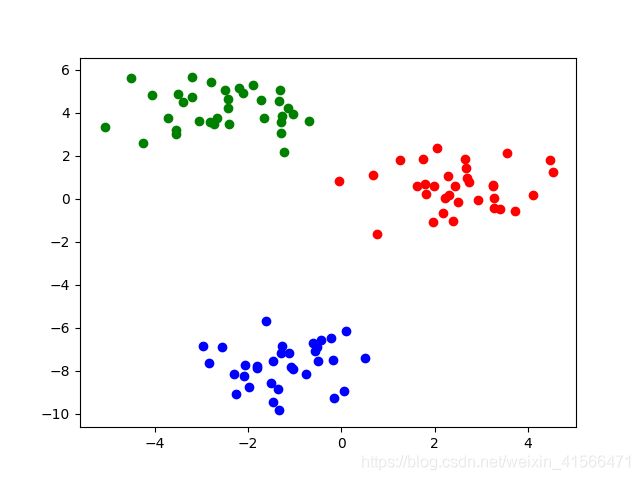
def run_my_model():
from matplotlib import pyplot as plt
my = MyGMM()
y = get_samples()
my.fit(y)
max_index = np.argmax(my.params['gamma'], axis=1)
print(max_index)
k1_list = []
k2_list = []
k3_list = []
for y_i, index in zip(y, max_index):
if index == 0:
k1_list.append(y_i)
elif index == 1:
k2_list.append(y_i)
else:
k3_list.append(y_i)
k1_list = np.array(k1_list)
k2_list = np.array(k2_list)
k3_list = np.array(k3_list)
plt.scatter(k1_list[:, 0], k1_list[:, 1], c='red')
plt.scatter(k2_list[:, 0], k2_list[:, 1], c='blue')
plt.scatter(k3_list[:, 0], k3_list[:, 1], c='green')
plt.show()
留问题:模型里面没有终止条件,该如何办?
参考资料:
《统计学习方法》 李航著