慢查询 MySQL 定位优化技巧,从10s优化到300ms
点击关注公众号,Java干货及时送达

文章目录
如何定位并优化慢查询SQL?
如何使用慢查询日志?
慢查询例子演示,新手都能看懂
查询语句慢怎么办?explain带你分析sql执行计划
当主键索引、唯一索引、普通索引都存在,查询优化器如何选择?
1.如何定位并优化慢查询SQL?
一般有3个思考方向 1.根据慢日志定位慢查询sql 2.使用explain等工具分析sql执行计划 3.修改sql或者尽量让sql走索引
2.如何使用慢查询日志?
先给出步骤,后面说明
有3个步骤
1.开启慢查询日志
首先开启慢查询日志,由参数slow_query_log决定是否开启,在MySQL命令行下输入下面的命令:
set global slow_query_log=on;默认环境下,慢查询日志是关闭的,所以这里开启。
2.设置慢查询阈值
set global long_query_time=1;只要你的SQL实际执行时间超过了这个阈值,就会被记录到慢查询日志里面。这个阈值默认是10s,线上业务一般建议把long_query_time设置为1s,如果某个业务的MySQL要求比较高的QPS,可设置慢查询为0.1s。
发现慢查询及时优化或者提醒开发改写。一般测试环境建议long_query_time设置的阀值比生产环境的小,比如生产环境是1s,则测试环境建议配置成0.5s。便于在测试环境及时发现一些效率的SQL。
甚至某些重要业务测试环境long_query_time可以设置为0,以便记录所有语句。并留意慢查询日志的输出,上线前的功能测试完成后,分析慢查询日志每类语句的输出,重点关注Rows_examined(语句执行期间从存储引擎读取的行数),提前优化。
3.确定慢查询日志的文件名和路径
show global variables like 'slow_query_log_file'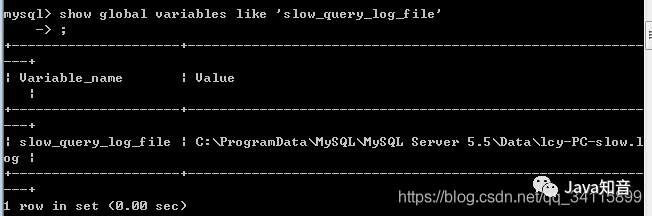
结果会发现慢日志默认路径就是MySQL的数据目录,我们可以来看一下MySQL数据目录
show global variables like 'datadir';
不用关注这里为什么不是MySQL 8.0,这和版本没什么关系的。
来,直接上菜,干巴巴的定义我自己都看不下去
我们先来查看一下变量,我框出了需要注意的点
查询带有quer的相关变量
show global variables like '%quer%';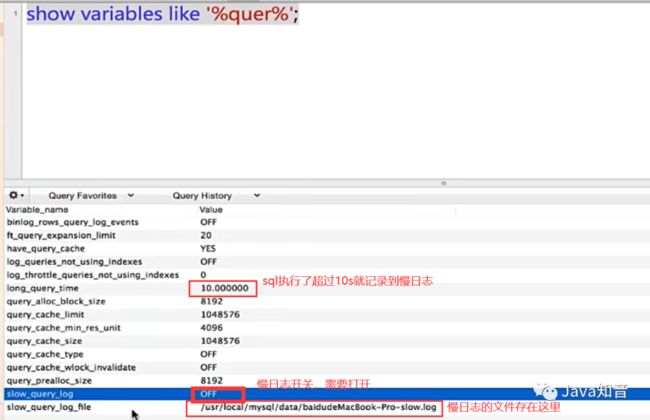
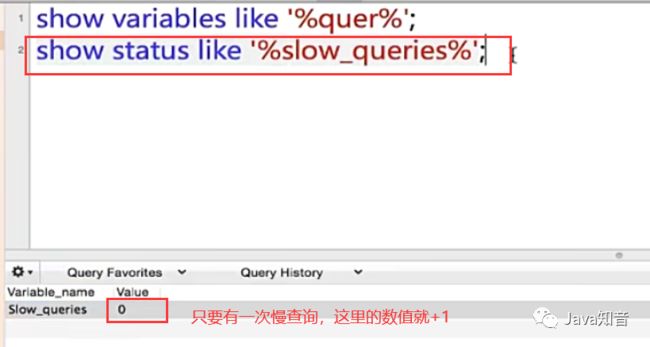
这里设置慢查询阈值为1s
set global long_query_time=1;可以看到已经修改过来了

但是重启mysql客户端设置和统计慢查询日志条数就会清零,即所有配置修改会还原
命令修改配置之后,在命令行net stop mysql关闭MySQL服务,再net start mysql开启MySQL服务,接着执行show global variables like '%quer%';会发现配置还原了。
在配置文件修改才能永久改变,否则重启数据库就还原了
3.慢查询例子演示,新手都能看懂
数据表结构,偷懒没写comment
CREATE TABLE `person_info_large` (
`id` BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
`account` VARCHAR (10),
`name` VARCHAR (20),
`area` VARCHAR (20),
`title` VARCHAR (20),
`motto` VARCHAR (50),
PRIMARY KEY (`id`),
UNIQUE(`account`),
KEY `index_area_title`(`area`,`title`)
) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8这里的数据是200W条。请注意表结构,记住哪几个字段有索引即可,后续围绕这个表进行分析。
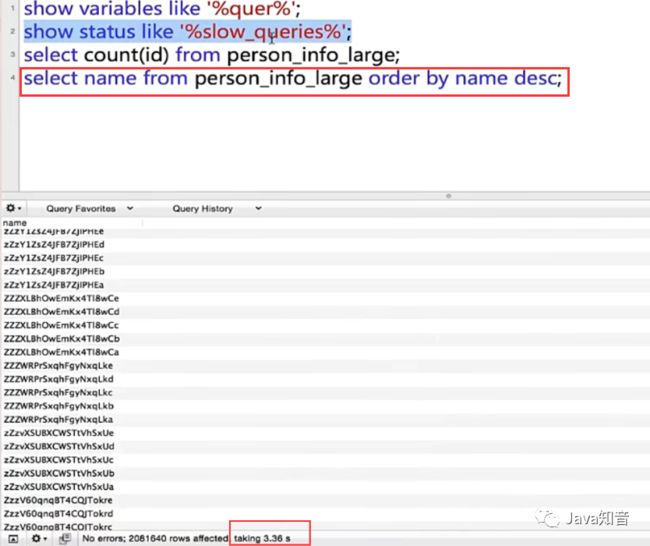
这个3.36s并不是实际执行时间,实际执行时间得去慢查询日志去看Query_time参数

可以看到Query_time: 6.337729s,超过了1s,所以会被记录,一个select语句查询这么久,简直无法忍受。
图中其他的参数解释如下:
Time:慢查询发生的时间
Query_time:查询时间
Lock_time:等待锁表的时间
Rows_sent:语句返回的行数
Rows_exanined:语句执行期间从存储引擎读取的行数
上面这种方式是用系统自带的慢查询日志查看的,如果觉得系统自带的慢查询日志不方便查看,可以使用pt-query-digest或者mysqldumpslow等工具对慢查询日志进行分析。
注意:有的慢查询正在执行,结果已经导致数据库负载过高,而由于慢查询还没执行完,因此慢查询日志看不到任何语句,此时可以使用
show processlist命令查看正在执行的慢查询。show processlist显示哪些线程正在运行,如果有PROCESS权限,则可以看到所有线程。否则,只能看到当前会话线程。
4.查询语句慢怎么办?explain带你分析sql执行计划
根据上一节的表结构可以知道,account是添加了唯一索引的字段。explain分析一下执行计划。

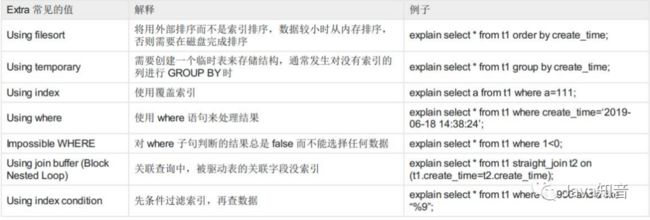
我们重点需要关注select_type、type、possible_keys、key、Extra这些列,我们来一一说明,看到select_type列,这里是SIMPLE简单查询,其他值下面给大家列出。

type列,这里是index,表示全索引扫描

表格从上到下代表了sql查询性能从最优到最差,如果是type类型是all,说明sql语句需要优化。
注意:如果
type = NULL,则表明个MySQL不用访问表或者索引,直接就能得到结果,比如explain select sum(1+2);
possible_keys代表可能用到的索引列,key表示实际用到的索引列,以实际用到的索引列为准,这是查询优化器优化过后选择的,然后我们也可以根据实际情况强制使用我们自己的索引列来查询。
Extra列,这里是Using index
![]()
一定要注意,Extra中出现Using filesort、Using temporary代表MySQL根本不能使用索引,效率会受到严重影响,应当尽可能的去优化。
出现Using filesort说明MySQL对结果使用一个外部索引排序,而不是从表里按索引次序读到相关内容,有索引就维护了B+树,数据本来就已经排好序了,这说明根本没有用到索引,而是数据读完之后再排序,可能在内存或者磁盘上排序。也有人将MySQL中无法利用索引的排序操作称为“文件排序”。
出现Using temporary表示MySQL在对查询结果排序时使用临时表,常见于order by和分组查询group by
回到上一个话题,我们看到account是添加了唯一索引的字段。explain分析了执行计划后
直接按照account降序来查

查看慢查询日志发现,使用索引之后,查询200W条数据的速度快了2s
接着我们分析一下查询name的sql执行计划
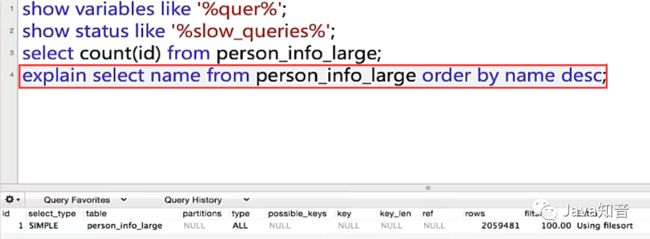
然后给name字段加上索引

加上索引之后,继续看看查询name的sql执行计划
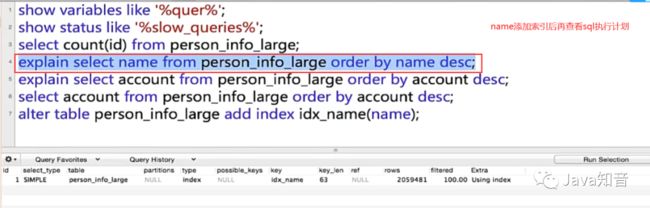
对比一下前面name不加索引时的执行计划就会发现,加了索引后,type由ALL全表扫描变成index索引扫描。order by并没有 using filesort,而是using index,这里B+树已经将这个非聚集索引的索引字段的值排好序了,而不是等到查询的时候再去排序。
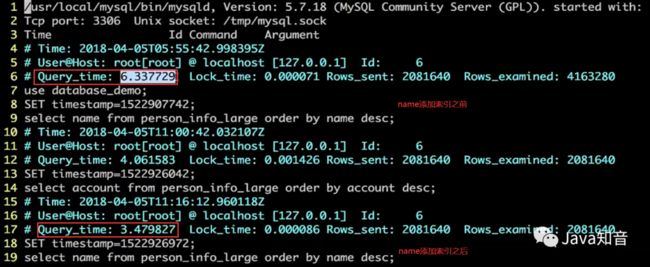
接着我们继续执行查询语句,此时name已经是添加了索引的。

结果发现,name添加索引之前,降序查询name是花费6.337729s,添加索引之后,降序查询name花费了3.479827s,原因就是B+树的结果集已经是有序的了。
5.当主键索引、唯一索引、普通索引都存在,查询优化器如何选择?
查询一下数据的条数,这里count(id),分析一下sql执行计划
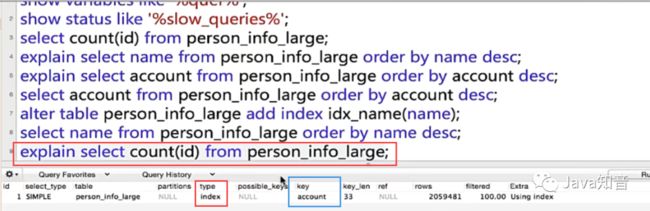
这里实际使用的索引是account唯一索引。
分析一下:实际使用哪个索引是查询优化器决定的,B+树的叶子结点就是链表结构,遍历链表就可以统计数量,但是这张表,有主键索引、唯一索引、普通索引,优化器选择了account这个唯一索引,这肯定不会使用主键索引,因为主键索引是聚集索引,每个叶子包含具体的一个行记录(很多列的数据都在里面),而非聚集索引每个叶子只包含下一个主键索引的指针,很显然叶子结点包含的数据是越少越好,查询优化器就不会选择主键索引
当然,也可以强制使用主键索引,然后分析sql执行计划
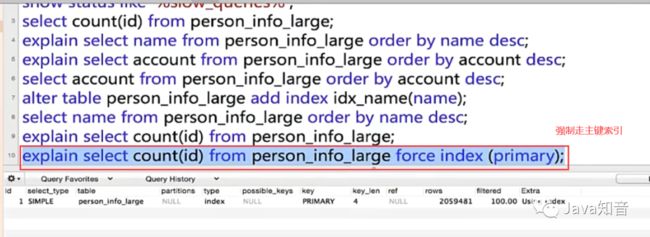
我们看一下优化器默认使用唯一索引大致执行时间676ms
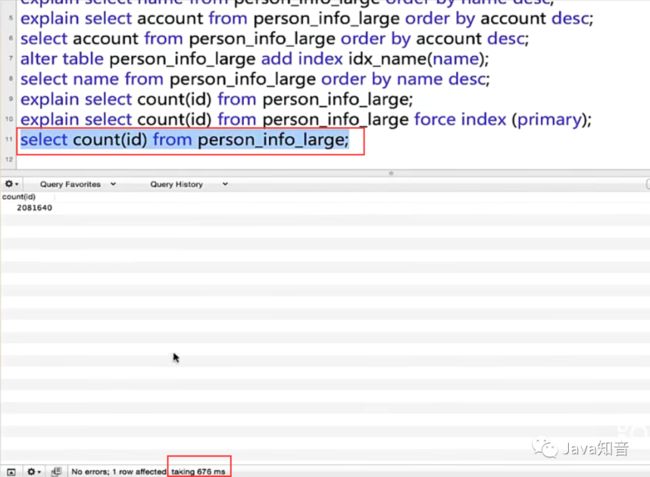
强制使用主键索引大致执行时间779ms
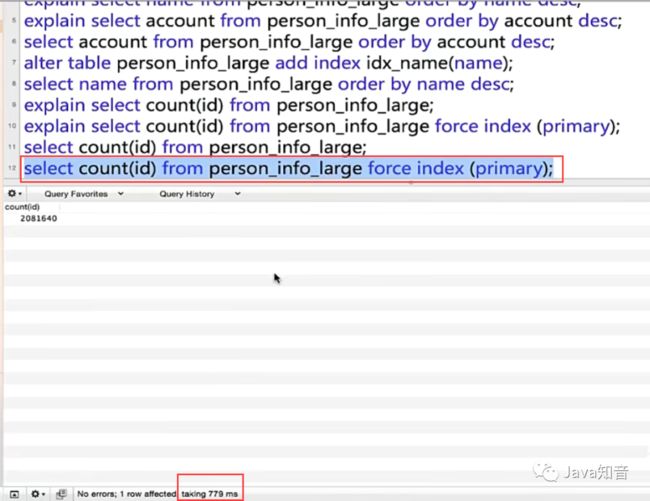
我们可以用force index强制指定索引,然后去分析执行计划看看哪个索引是更好的,因为查询优化器选择索引不一定是百分百准确的,具体情况可以根据实际场景分析来确定是否使用查询优化器选择的索引。
来源:liuchenyang0515.blog.csdn.net/article/
details/117020580
(完)码农突围资料链接1、卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
2、计算机基础知识总结与操作系统 PDF 下载
3、艾玛,终于来了!《LeetCode Java版题解》.PDF
4、Github 10K+,《LeetCode刷题C/C++版答案》出炉.PDF
欢迎添加鱼哥个人微信:smartfish2020,进粉丝群或围观朋友圈。