labelme批量制作数据集教程
labelme数据标注及json标签文件批量处理
文章目录
- labelme数据标注及json标签文件批量处理
- 前言
- 一、Labelme安装
-
- 1. windows
- 2. Ubuntu
- 二、Labelme制备分割数据集
-
- 1. 启动
- 2. 数据标注
- 三、labelme标签批量转换
-
- 1. 单张图片转换
- 2. 多张图片批量转换
- 3. 标注图片提取
- 4. 标注图片转单通道
前言
最近在学习图像语义分割,需要制作自己的数据集,用到labelImg进行标注,这里将整个过程记录下来。一、Labelme安装
第一步就是需要安装labelme
1. windows
# python3
conda create --name=labelme python=3.6
activate labelme
pip install pyqt5
pip install labelme
说明:
也可以不创建虚拟环境,直接pip install labelme安装
虚拟环境只是便于管理,即使出现什么错误,也不至于把本地环境弄蹦
2. Ubuntu
# Python3
sudo apt-get install python3-pyqt5 # PyQt5
sudo pip3 install labelme
二、Labelme制备分割数据集
1. 启动
说明:
- 在cmd中输入activate labelme激活labelme环境。
- 在激活环境中输入labelme即可打开labelme界面。
- 退出输入deactivate即可。
打开界面如下:

2. 数据标注
点击open dir,选择标注文件所在的文件夹,会导入文件内所有图片,由于实验数据不变展示,借用其他博客的图像
如下图
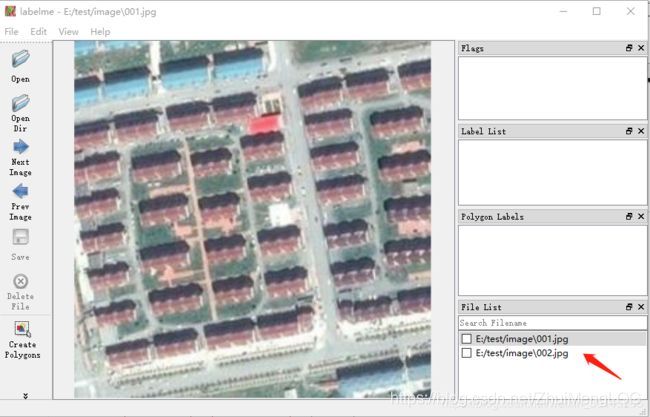
然后开始标注:点击左下角的CreatePolygons,单击鼠标左键添加多边形顶点,Ctrl+Z撤销上一个顶点,最后点击起始点完成多边形的选择,弹出命名框。同一类下有多个实体对象时,如城区对象时,用City1,City2区分,Ctrl+S保存生成json文件,同时右下角文件目录下该图像前打钩显示已标注,如下图所示:
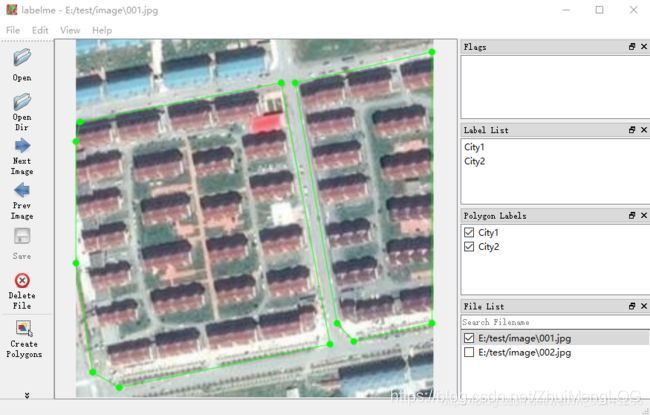
标注完成后,会生成一个json文件。
三、labelme标签批量转换
1. 单张图片转换
json文件需要转换成png文件,基本转换方法是在安装了labelme的环境下,输入下面的代码:
labelme_json_to_dataset E:\test\image\001.json
在001.json所在文件夹内,会生成一个001_json的文件夹,里面有5个文件,其中的label.png为所要的分割掩膜,新版本的labelme没有.yaml文件
分割掩膜示意图:

2. 多张图片批量转换
但是当数据文件很多时,需要批量处理的方法
2.1 bat脚本循环法:
@echo off
for %%i in (*.json) do labelme_json_to_dataset %%i
pause
新建一个txt文件,把这个复制进去,然后改名为test.bat,和要转换的文件放在一起。然后在激活相应环境下,进入所在文件目录,命令行输入test.bat就可以了。
2.2 程序法:
import os
import glob
path = r'D:\data_count\WLI' # 这里是指.json文件所在文件夹的路径
json_file = glob.glob(os.path.join(path, "*.json"))
os.system("activate labelme")
for file in json_file:
os.system("labelme_json_to_dataset.exe %s" % (path + '/' + file))
使用时,根据自己的情况修改json文件所在路径和自己的虚拟环境。
3. 标注图片提取
生成的label图片均在文件中,且图片名均是label.png,所以需要批量提取label.png,其他4个文件没有用,代码如下
# 将标签图从json文件中批量取出
import os
import shutil
path = 'D:/LCI/'
dirpath = 'D:/annotations/LCI/'
for eachfile in os.listdir(path):
if os.path.isdir(path + eachfile):
if os.path.exists(path + eachfile + '/label.png'):
shutil.copy(path + eachfile + '/label.png', dirpath + eachfile.split('_')[0] + '.png')
print(eachfile + ' successfully moved')
使用时,只需将path和dirpath修改为你自己的路径即可。
4. 标注图片转单通道
由于我的数据集是做二分类分割,所以,需要将ground_truth转换为8位的单通道黑白图像,才能作为训练时的label使用。
代码如下
import os
import cv2
import numpy as np
bace_path = r"D:\research\data\train\mask"
save_path = r'D:\research\data\train'
for im in os.listdir(bace_path):
img = cv2.imread(os.path.join(bace_path, im))
b, g, r = cv2.split(img)
r[np.where(r != 0)] = 255
cv2.imwrite(os.path.join(save_path, im), r)