用R处理不平衡的数据
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
本文来自云+社区翻译社,作者ArrayZoneYour
在分类问题当中,数据不平衡是指样本中某一类的样本数远大于其他的类别样本数。相比于多分类问题,样本不平衡的问题在二分类问题中的出现频率更高。举例来说,在银行或者金融的数据中,绝大多数信用卡的状态是正常的,只有少数的信用卡存在盗刷等异常现象。
使用算法不能获得非平衡数据集中足以对少数类别做出准确预测所需的信息。所以建议使用平衡的分类数据集进行训练。
在本文中,我们将讨论如何使用R来解决不平衡分类问题。
数据集介绍
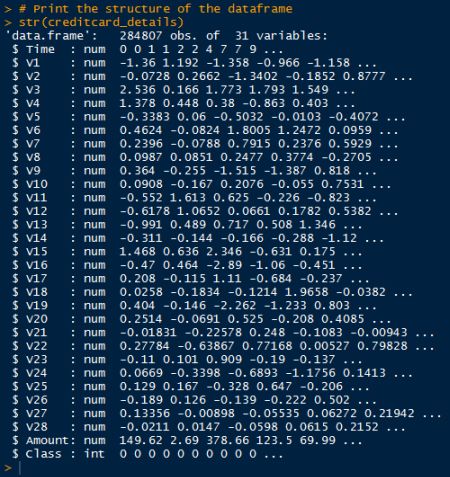
本文使用的数据集为信用卡交易数据集,总的交易信息量为284K条,共有31个信息列,其中包含492次信用卡盗刷(诈骗)信息。
数据列
- Time: 该笔交易距离数据集中第一笔交易的时间(按秒计)。
- V1-V28:用PCA获得的主成分变量。
- Amount:交易金额。
- Class:应变量,值为1代表该条记录为盗刷记录,否则为0
本文概要
- 对数据集进行探索性分析
1. 检查非平衡数据
2. 检查每小时的交易笔数
3. 检查PCA变量的均值
- 数据切分
- 在训练集上训练模型
- 使用抽样的方法来构建平衡数据集
对数据集进行探索性分析
下面让我们使用R来对数据集进行汇总并对其中的关键、显著的特征进行可视化。
检查非平衡数据
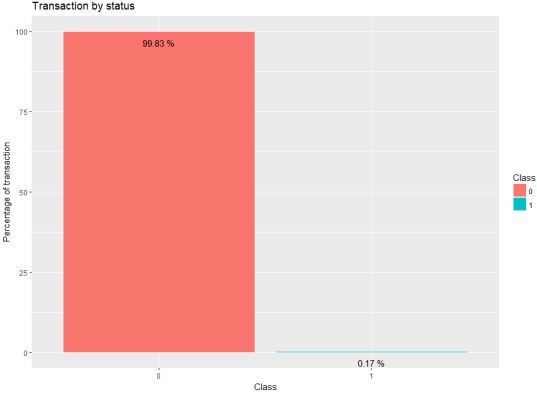
通过下面的操作我们可以看到应变量的不平衡性:
我们可以借助dplyr包中的group_by函数对Class的值进行分组:
library(dplyr)
creditcard_details$Class <- as.factor(creditcard_details$Class)
creditcardDF <- creditcard_details %>% group_by(Class) %>% summarize(Class_count = n())
print(head(creditcardDF))# A tibble: 2 x 2
Class Class_count
<int>
1 0 284315
2 1 492 使用ggplot可以看到每个类别数据所占的比例:
检查每小时的交易笔数
要按填或者小时查看交易笔数,我们需要首先将日期标准化,并且根据每天的时间将一天划分为四等份。
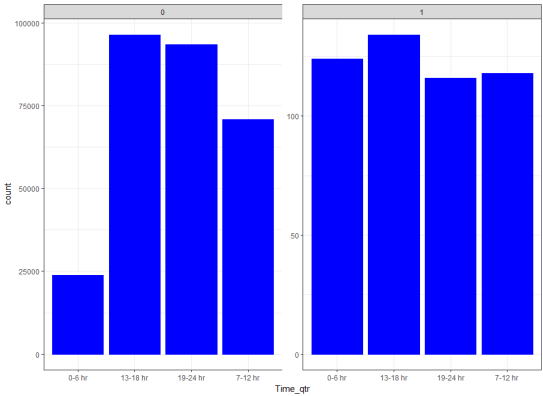
上图展示了两天的交易信息在各个时间段的分布情况。对比可以看到大部分的盗刷交易发生在13-18点。
检查PCA变量的均值
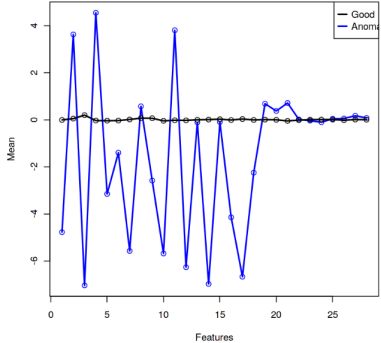
为了发现数据异常,我们计算了V1-V28变量的均值并检查了每个变量的方差。从下图可以看到异常的交易数据(蓝点)具有更大的方差。
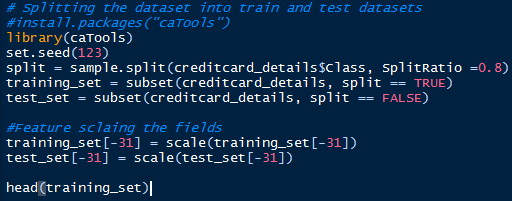
数据切分
在预测问题的建模当中,数据需要被切分为训练集(占数据集的80%)和测试集(占数据集的20%)。在数据切分之后,我们需要进行特征缩放来标准化自变量的范围。
在训练集上训练模型
在训练集上构建模型可以分为以下几步:
- 在训练集上训练分类器。
- 在测试集上进行预测。
- 检测模型在非平衡数据上的预测输出。
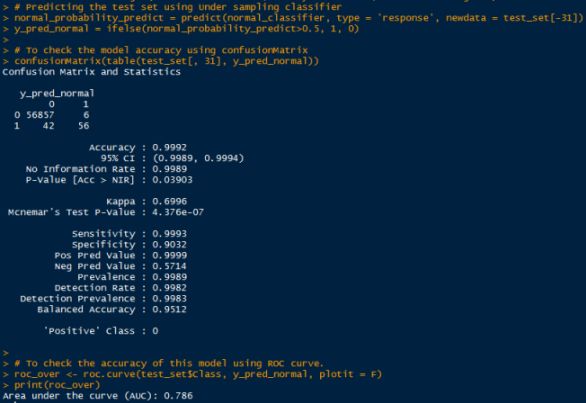
通过混淆矩阵我们可以得到模型在测试集上的准确率达到了99.9%,当然这是由于样本不均衡造成的。所以现在让我们忽略通过混淆矩阵得到的模型准确率。通过ROC曲线,我们得到在测试集上的准确率为78%,这比之前的99.9%要低得多。
使用抽样的方法来构建平衡数据集
下面我们将使用不同的抽样方法来平衡给定的数据集,然后检查抽样后的数据集中正常和异常数据的条数,最终在平衡数据集上构建模型。
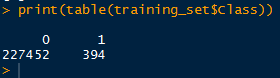
在处理之前,异常的记录有394条,正常的记录有227K条。
在R中,ROSE和DMwR包可以帮助我们快速执行自己的采样策略。ROSE包基于采样方法和平滑的bootstrap方法来生成数据,它提供了良好的调用接口以帮助我们迅速完成任务。
它支持以下采样方法:
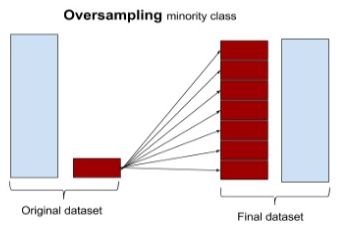
过采样(Oversampling)
通过该方法可以让算法执行过采样。由于原始的数据集有227K条记录,该方法会对持续对样本量少的类别进行采样直至其数据量达到227K。此时数据集样本的总量将达到454K。该方法可以通过指定参数method="over"实现。
欠采样(Undersampling)
这个方法与过采样方法相似,最终获得的数据集中正常记录和异常记录的数量也是相同的,不过欠采样是无放回的抽样,相应地在本文中的数据集上,由于异常记录过少,进行欠采样之后我们不能提取出样本中的关键信息。该方法可以通过指定参数method="under"实现。
Both Sampling
这个方法是过采样和欠采样的结合。多数类使用的是无放回的欠采样,少数类使用的是又放回的过采样。该方法可以通过指定参数method="both"实现。
ROSE Sampling
ROSE抽样方法利用合成的方法来生成数据,可以提供原始数据更好的估计。
Synthetic Minority Over-Sampling Technique (SMOTE) Sampling
此方法可以避免重复添加少数类样本至主数据集时可能发生的过拟合现象。举例来说,我们过采样之后一次获取的数据可能只是少数类数据的一个子集。在了解了这些方法之后,我们分别将这些方法应用到了原始数据集之上,之后统计的两类样本数如下:
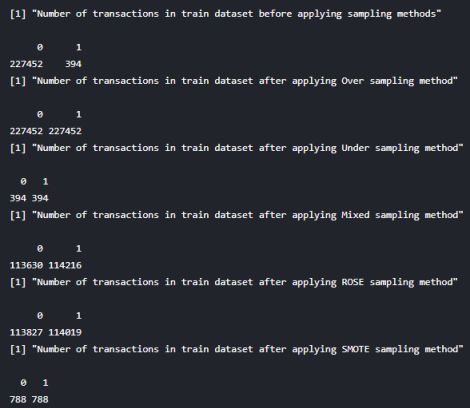
用得到的平衡训练数据集再次对分类模型进行训练,在测试数据上进行预测。由于原始数据集是不平衡的,所以这里我们不再使用混淆矩阵计算得到的准确率作为模型评价指标,取而代之的是roc.curve捕获得到的roc。
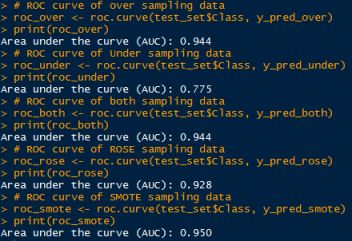
结论
在本文的实验中,使用SMOTE采样方法得到的数据训练的模型性能最优。由于这些采样方法的variation不大,当它们与像随机森林这样鲁棒性很强的算法结合使用时可以得到非常高的数据准确率。
在处理不平衡的数据集时,使用上面的所有采样方法在数据集中进行试验可以获得最适合数据集的采样方法。为了获得更好的结果,还可以使用一些先进的采样方法(如本文中提到的合成采样(SMOTE))进行试验。
这些采样方法在Python中也可以很轻松地实现,如果想要参阅完整的代码,可以查阅下面提供的Github链接。
训练数据集及代码
- 训练数据集
- 本文的R、Python实现代码
问答
如何从源安装R语言包?
相关阅读
用R语言进行文本挖掘和主题建模
协同过滤的R语言实现及改进
用R解析Mahout用户推荐协同过滤算法(UserCF)
此文已由作者授权腾讯云+社区发布,原文链接:https://cloud.tencent.com/developer/article/1142201?fromSource=waitui
欢迎大家前往腾讯云+社区或关注云加社区微信公众号(QcloudCommunity),第一时间获取更多海量技术实践干货哦~