多GPU上的分布式训练
(说明:如果您认为下面的文章对您有帮助,请您花费一秒时间点击一下最底部的广告以此来激励本人创作,谢谢)
GPU与CPU在机器学习中的实用性;为什么多GPU的分布式训练对于更大的数据集是最佳的;以及如何开始。
为什么以及如何使用多个GPU进行分布式训练
大规模训练人工智能模型的数据科学家或机器学习爱好者将不可避免地达到上限。当数据集大小增加时,处理时间可以从分钟增加到小时,从几天增加到几周!数据科学家转向包括多个GPU以及机器学习模型的分布式训练,以在一小部分时间内加速和开发完整的人工智能模型。
我们将讨论GPU与CPU在机器学习中的实用性,为什么多GPU的分布式训练对于更大的数据集是最优的,以及如何使用最佳实践开始训练机器学习模型。
为什么GPU适合训练神经网络?
训练阶段是构建神经网络或机器学习模型中资源最密集的部分。神经网络在训练阶段需要数据输入。该模型根据数据集之间的变化,输出基于层中处理数据的相关预测。第一轮输入数据基本上形成机器学习模型要理解的基线;后续数据集计算权重和参数,以训练机器预测精度。
对于简单或数量较少的数据集,等待几分钟是可行的。然而,随着输入数据的大小或数量的增加,训练时间可能达到数小时、数天甚至更长。
CPU很难处理大量数据,例如对数十万浮点数的重复计算。深度神经网络由矩阵乘法和向量加法等操作组成。
提高此过程速度的一种方法是使用多个GPU切换分布式训练。基于分配给训练阶段的张量核的数量,用于分布式训练的GPU可以比CPU更快地移动进程。
GPU或图形处理单元最初设计用于处理视频游戏图形中数十万个三角形的外推和定位过程中的重复计算。加上巨大的内存带宽和天生的执行数百万计算的能力,GPU非常适合神经网络数百次(或模型迭代)训练所需的快速数据流,非常适合深度学习训练。
什么是机器学习中的分布式训练?
分布式训练承担训练阶段的工作量,并将其分布在多个处理器上。这些微型处理器协同工作以加快训练过程,而不会降低机器学习模型的质量。当数据被并行分割和分析时,每个微型处理器在一批不同的训练数据上训练机器学习模型的副本。
结果在处理器之间传递(当批次完全完成时,或当每个处理器完成其批次时)。下一次迭代再次从稍微新训练的模型开始,直到达到预期结果。
有两种最常见的方法可以在微型处理器(在我们的例子中是GPU)之间分配训练:数据并行和模型并行。
数据并行性
数据并行性是对数据的划分,并将其分配给每个GPU,以使用相同的AI模型进行评估。一旦所有GPU完成前向传递,它们将输出梯度或模型的学习参数。由于存在多个梯度,只有1个AI模型需要训练,因此对梯度进行编译、平均,并将其缩减为单个值,以最终更新模型参数,用于下一次的训练。这可以同步或异步完成。
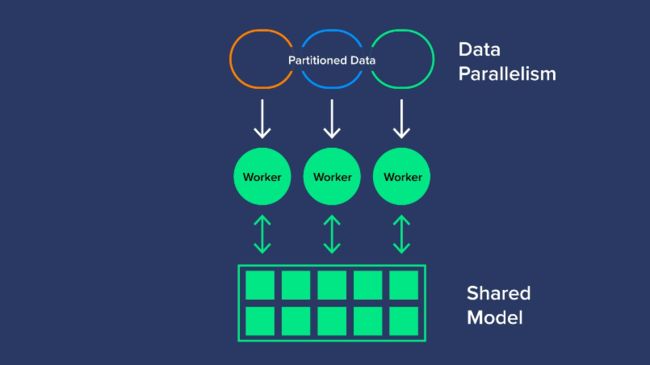
同步数据并行性是指我们的GPU组必须等到所有其他GPU完成梯度计算后,才能进行平均并减少梯度以更新模型参数。一旦更新了参数,模型就可以继续下一轮。
异步数据并行是GPU独立训练而不必执行同步梯度计算的地方。相反,梯度在完成时会传回参数服务器。每个GPU不等待另一个GPU完成计算,也不计算梯度平均,因此是异步的。异步数据并行需要一个单独的参数服务器用于模型的学习部分,因此成本稍高。
在每个步骤之后计算梯度并平均训练数据是计算最密集的。由于它们是重复计算,GPU一直是加速这一步骤以获得更快结果的选择。数据并行是相当简单和经济高效的,但是,有时模型太大,无法安装在单个微型处理器上。
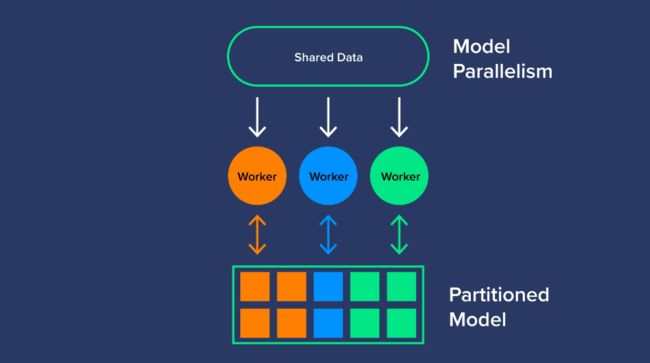
模型并行性
与分割数据不同,模型并行性在工作GPU之间分割模型(或训练模型的工作负载)。分割模型将特定任务分配给单个工作人员或多个工作人员,以优化GPU的使用。模型并行可以被认为是一条人工智能装配线,它创建了一个多层网络,可以处理无法实现数据并行的大型数据集。模型并行需要专家来确定如何划分模型,但会带来更好的利用率和效率。
多GPU分布式训练更快吗?
购买多个GPU可能是一项昂贵的投资,但要比其他选择快得多。CPU也很昂贵,不能像GPU那样扩展。跨多个层次和多个GPU为分布式训练机器学习模型可提高训练阶段的生产率和效率。
当然,这意味着减少了训练模型的时间,但它也让您能够更快地产生(和再现)结果,并在任何事情失控之前解决问题。就为您的努力产生结果而言,这是训练周数与训练小时数或分钟数之间的差异(取决于使用的GPU数量)。
您需要解决的下一个问题是如何开始在机器学习模型中利用多个GPU进行分布式训练。
如何使用多个GPU进行训练?
如果您想使用多个GPU处理分布式训练,首先必须认识到您是需要使用数据并行还是模型并行。这个决定将基于数据集的大小和范围。
您是否能够让每个GPU使用数据集运行整个模型?或者,使用更大的数据集跨多个GPU运行模型的不同部分会更省时吗?通常,数据并行是分布式学习的标准选项。在深入研究模型并行或异步数据并行之前,先从同步数据并行开始,其中需要单独的专用参数服务器。
我们可以在您的分布式训练过程中开始将您的GPU链接在一起。
根据并行性决策分解数据。例如,您可以使用当前数据批(全局批)并将其划分为八个子批(本地批)。如果全局批处理有512个样本,而您有八个GPU,则八个本地批处理中的每一个都将包含64个样本。
八个GPU或微型处理器中的每一个都独立运行一个本地批处理:正向传递、反向传递、输出权重梯度等。
来自局部梯度的权重修改在所有八个处理器中有效混合,因此所有内容都保持同步,并且模型已经进行了适当的训练(当使用同步数据并行时)。
重要的是要记住,用于分布式训练的一个GPU需要在训练阶段托管其他GPU的收集数据和结果。如果您不密切关注,可能会遇到一个GPU内存不足的问题。
除此之外,在考虑使用多个GPU进行分布式训练时,好处远远大于成本!最后,当您为模型选择正确的数据并行化时,每个GPU都会减少训练阶段的时间,提高模型效率,并产生更多高端结果。