论文-阅读翻译+笔记-深度玻尔兹曼机
我们提出了一种新的玻尔兹曼机器学习算法,其中包含许多隐藏变量层。依赖于数据的期望是使用趋于关注单一模式的变分近似来估计的,并且使用持续马尔可夫链来近似数据依赖期望。使用两种截然不同的技术来估计进入对数似然梯度的两种期望类型,使得学习具有多个隐藏层和数百万个参数的玻尔兹曼机器变得切实可行。 通过使用逐层“预训练”阶段,可以使得学习变得更有效率,从而允许使用单一自底向上通过初始化变量指数。我们在MNIST和NORB数据集上展示结果,显示深玻尔兹曼机器学习良好的生成模型,并且在手写数字和视觉对象识别任务上表现良好。
1介绍
Boltzmann机器的原始学习算法(Hinton和Sejnowski,1983)需要随机初始化马尔可夫链来逼近它们的均衡分布,以估计相关联的一对二进制变量都将处于开启状态的数据依赖以及期望。这两个期望的差异是最大似然学习所需的梯度。即使在模拟退火的帮助下,这种学习过程也太慢而不切实际。学习可以在有限制的玻尔兹曼机器(RBM)中提高效率,后者在隐藏单元之间没有联系(Hinton,2002)。通过将一个RBM的隐藏活动视为训练后面更高级RBM的数据(Hinton et al。,2006; Hinton and Salakhutdinov,2006),可以学习多个隐藏层。然而,如果以这种贪心的,逐层的方式学习多层,那么最终的复合模型不是多层玻尔兹曼机器(Hinton et al。,2006)。这是一种混合生成模式,称为“深层信仰网络”,其顶层两层之间无直接连接,所有底层之间有向下连接。
在本文中,我们提出了一个更为有效的完全一般玻尔兹曼机器的学习过程。我们还表明,如果隐藏单元之间的连接受到限制,使得隐藏单元形成多个层,那么在应用我们的新学习过程之前,可以使用一些RBM的略微修改来初始化深玻尔兹曼机器的权重。
2 玻尔兹曼机器(BM's)
注:只有两层神经元,一层叫做显层(visible layer),由显元 (visible units) 组成,用于输入训练数据。另一层叫做隐层 (Hidden layer),相应地,由隐元 (hidden units) 组成,用作特征检测器 (feature detectors)。(深度学习思想就是通过多层次模型,自动的学习数据的特征,这样不仅能最大程度的保持原有的重要信息,也可以让模型效果更好。)
玻尔兹曼机是一个对称耦合的随机二元单位网络。 它包含一组可见单位v∈{0,1} D和一组隐含单位h∈{0,1} P(见图1)。 状态{v,h}的能量定义为:

其中θ= {W,L,J}是模型参数1:W,L,J表示可见 - 隐藏,可见 - 可见和隐藏对称交互项。 L和J的对角元素设置为0.模型分配给可见向量v的概率为:

其中p *表示非标准化概率,Z(θ)是分区函数。 隐藏单元和可见单元的条件分布由下式给出:

(上式意思是,在给定所有显元的值的情况下,每一个隐元取什么值是互不相关的。同样,在给定隐层时,所有显元的取值也互不相关。这个结论非常重要。)
(当我们输入v的时候,通过p(h|v) 可以得到隐藏层h,而得到隐藏层h之后,通过p(v|h)又能得到可视层,通过调整参数,我们就是要使得从隐藏层得到的可视层v1与原来的可视层v一样,那么得到的隐藏层可以视作与可视层等价,也就是说隐藏层可以作为可视层输入数据的特征。因此隐层又叫做特征检测器。)
其中σ(x)= 1 /(1 + exp(-x))是逻辑函数。 参数更新,最初由Hinton和Sejnowski(1983)推导出来,需要在对数似然中执行梯度上升,可以从等式2:

其中α是学习率,EPdata [·]表示相对于完成的数据分布Pdata(h,v;θ)= p(h | v;θ)Pdata(v)的期望,其中Pdata(v)= 1/N Pnδ(v - vn)表示经验分布,而EPmodel [·]是相对于模型定义的分布的期望(见方程2)。 有时我们将EPdata [·]作为数据相关期望,而EPmodel [·]作为模型的期望。
在这个模型中精确的极大似然学习是棘手的,因为精确计算数据相关期望值和模型的期望值需要隐藏单位数目指数的时间。 Hinton和Sejnowski(1983)提出了一种使用Gibbs抽样来近似两种期望的算法。 对于每次迭代学习,对每个训练数据向量运行单独的马尔可夫链以近似EPdata [·],并且运行额外的链以近似EPmodel [·]。 这种学习算法的主要问题是逼近固定分布所需的时间,特别是在估计模型的期望值时,因为Gibbs链可能需要探索高度多模态能量
同时设定J = 0和L = 0可以恢复众所周知的受限玻尔兹曼机(RBM)模型(Smolensky,1986)(见图1右图)。与一般的BM相比,RBM的推论是确切的。 尽管RBM中的准确最大似然学习仍然是棘手的,但是使用对比分歧(CD)(Hinton,2002)可以有效地进行学习。 进一步观察到(Welling和Hinton,2002;Hinton,2002)为了对比发散性能良好,重要的是从条件分布p(h | v;θ)中获得精确的样本,这在学习完整玻尔兹曼时是难以处理的机器。

2.1使用持久马氏链估计模型的期望
可以使用随机逼近程序(SAP)来逼近模型的期望(Tieleman,2008; Neal,1992),而不是使用CD学习。 SAP属于Robbins-Monro类型的一类经过深入研究的随机逼近算法(Robbins and Monro,1951; Younes,1989,2000)。 这些方法背后的想法很简单。 设θt和Xt是当前参数和状态。 然后Xt和θt按顺序更新如下:
•给定Xt,从一个转换算子Tθt(Xt + 1; Xt)中抽取一个新的状态Xt + 1,使得pθt不变。
•然后通过将难以模拟的期望值替换为关于Xt + 1的期望值来获得新的参数θt+ 1。
(Younes,1989,2000; Yuille,2004)给出了保证几乎可以肯定收敛于渐近稳定点的精确充分条件。一个必要条件要求学习率随时间降低,即P∞t = 0αt=∞且P∞t =0α2t <∞。 这个条件可以通过设置αt= 1 / t来满足。 通常,在实践中,序列|θt| 是有界的,并且由转移核心Tθ支配的马尔可夫链是遍历的。 加上学习率的条件,这确保了几乎可靠的收敛。
该程序有效的直观原因如下:由于与马尔可夫链的混合率相比,学习率变得足够小,这个“持久性”链将始终保持非常接近固定分布,即使它只是为了几个MCMC更新每个参数更新。 持续链中的样本对于连续的参数更新是高度相关的,但是如果学习速率足够小,那么在参数变化足以明显改变估计值之前,链会混合。许多持续性链可以并行运行,我们将把每个链中的当前状态称为“幻想”粒子
2.2一种估计数据相关期望的变分方法
在变分学习中(Hinton和Zemel,1994; Neal和Hinton,1998),每个训练向量v的潜变量p(h | v;θ)的真后验分布被近似后验q(h | v; μ)并且更新参数遵循对数似然下界的梯度:
其中H(·)是熵函数。 变分学习具有很好的特性,除了尝试最大化训练数据的对数似然性之外,它还试图找到最小化逼近和真实后验之间的Kullback-Leibler散度的参数。 使用一个朴素的均值场方法,我们选择一个完全因式分布来逼近真正的后验:q(h;μ)= QP j = 1 q(hi),其中q(hi = 1)=μi其中P是 隐藏单位的数量。 数据的可能性的下限采用如下形式:
通过将固定θ的变分参数μ的下限最大化,得到平均场定点方程:
接下来是应用SAP来更新模型参数θ(Salakhutdinov,2008)。我们强调变分近似不能用于近似Boltzmann机器学习规则中关于模型分布的期望值,因为负号(见方程6)将导致变分学习改变参数,以便最大化 近似和真实的分布。 但是,如果使用持续性链来估计模型的期望值,则可以应用变分学习来估计与数据相关的期望值。
天真的平均场的选择是故意的。 首先,融合通常非常快,这极大地方便了学习。其次,对于图像或语音的解释等应用,我们预期给定数据的后验隐藏状态具有单一模式,因此简单快速的变化近似(如均值场)应该足够。 事实上,牺牲一些对数似然性来使真正的后验单峰对于必须使用后验来控制其行为的系统来说可能是有利的。具有相同感官输入的许多完全不同且同样好的表示增加了对数似然性,但使得将适当的动作与该感觉输入相关联变得困难得多。

3.DBM
一般情况下,我们很少对复杂的全连接的玻尔兹曼机(BM)感兴趣,而是对一个深度多层的BM感兴趣,具体见图2的左边部分。图中的每一层都能从下一层隐藏特征的激活值中提取出更高阶的特征。我们对DBM感兴趣有如下几个原因。第一,与DBN一样,DBM也有学习内部特征的能力且DBM在目标和语音识别方面的作用非常有前途;第二,DBM能从大量的无标签数量中学习出高阶特征,然后再用少量有标签数据对整个模型微调;第三,与DBN不一样,DBM的逼近推导过程,除了有自底向上的传播之外,还包含了自顶向下的反馈,从而使DBM能更好地传播模糊输入的不确定性,因此它的鲁棒性更好。

图2. 左图:一个三层的DBN和一个三层的DBM;右图:预训练一系列RBM,然后把它们组合成一个DBM
对于一个无层内连接的2层的BM(即:RBM),它的能量函数(其可见变量v和隐藏变量h的联合配置(joint configuration)的能量)如下:
![]()
可视层向量V的概率密度函数(通过能量函数的概率分布)如下,其中,Z(θ)是归一化因子,也称为配分函数(partition function):

注:得到了概率分布后,我们要学习参数{W,a,b},表示出概率分布的最大似然函数(最后只要让这函数最大化,就是求偏导):

对可视单元和两层隐藏单元的条件概率分布如下:

对于DBM的最大似然函数的逼近学习,仍可用上面提到的普通BM的学习方法,但是学习速率会非常慢,特别是隐含层越多学习速率会越慢。下面一节提出一种快速的算法来初始化模型参数。
3.1 利用逐层贪婪算法预训练DBM
hinton在2006年的论文“A Fast LearningAlgorithm for Deep Belief Nets”中介绍了一种逐层贪婪无监督学习算法。在一系列堆叠的RBM中,该算法一次只学习一个RBM,依次学习。在学习完整个堆叠的RBM后,可以把这个用RBM堆积起来的模型看作成一个概率模型,叫“深度信念网络(DBN)”。特别注意,这个模型并不是一个DBM。DBN的最上面两层是一个RBM,它是一个无向图模型,但DBN其余下面的层是一个有向生成模型(见图2)。在学习完DBN中的第一个RBM后,生成模型可写成如下形式:

其中,p(h1;w1)是h1的隐式先验概率。对DBM中的第二个RBM,实际上就是用p(h1;w2)代替原来的p(h1;w1)。如果第2个RBM按照论文“A Fast LearningAlgorithm for Deep Belief Nets”中的方法进行正确的初始化,p(h1;w2)就会变为一个更好的h1的后验分布模型,在这个模型中,这个后验分布对于所有训练样本都是一个简单的阶乘后验组合成的非阶乘混合。因为第2个RBM用了一个更好地模式取代了p(h1;w1),那么就可能通过对这两个模型中的h1求平均从而推导出p(h1;w1,w2),具体方法就是把自底向上得到的w1的一半和自顶向下得到的w2的一半相加。这里利用的自底向上得到的w1和自顶向下得到的w2,就相当于重复计算了,因为h2对v是独立的。
为了初始化DBM的模型参数,本文提出了逐层贪婪预训练RBM堆的算法,但是同论文“A Fast LearningAlgorithm for Deep Belief Nets”中方法相比,有一个小小的变化,这是为了消除把自顶向下和自底向上联合在一起所带来的重复计算问题。对于最下层的RBM,我们使输入单元加倍且约束住可视层与隐含层间的权值,见图2右边部分。这个用相关参数修改过的RBM对隐藏单元和可视单元的条件概率分布如下:
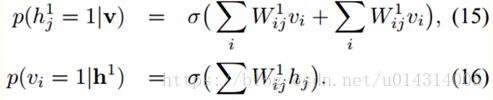
CD算法用于这个RBM的预训练可得到非常好的结果,而这个修改过的RBM也能很好地重建训练数据。相反地,可把最顶层的RBM的隐藏单元数加倍。最顶层RBM的条件分布如下:

当这两个模块组合成一个模型后,进入第一个隐含层的总输入,有如下h1的条件分布:
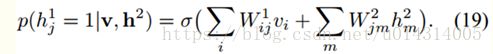
对V和h2的条件分布同式16和18一样。
通过观察可发现,上面现个RBM组合而成的模型的条件分布与DBM的条件分布(式11、12、13)是一样的。因此,用贪婪算法预训练这两个修改过的RBM可得到一个权值对称的无向模型——DBM。当用贪婪算法预训练2个以上RBM时,只需要修改最底和最顶的2个RBM。对所有中间的RBM,只需要在组合成DBM的时候,简单把两个方向上的权值均分即可。
以上面的贪婪算法预训练DBM的权值,有2个目的。第一,使权值初始化到一个合适的值,见实验结果部分。第二,有一个快速方法进行逼近推导,该方法以通过RBM堆单一向上传播的方式进行。在可视层给一个数据向量,通过自底向上的传递,每个隐含层单元都能被激活,且用自底向上翻倍输入的方式来弥补自上而下反馈的缺乏(除了最高一层没有自上而下的输入外)。这种快速逼近推导方法通常用来初始化平均场方法,该初始化方法比随机初始化法收敛更快。
3.2评估DBM
最近,Salakhutdinov 和Murray在2008年提出了一种利用退火式重要性抽样(AIS,基于蒙特卡罗的算法,Radford M. Neal于1998年在论文“Annealed Importance Sampling”中首次提出)来评估RBM的配分函数的方法(Estimating PartitionFunctions of RBM's)。本小节介绍了怎样利用AIS来评估DBM的配分函数。与变分推导一起,就会较好地评估出测试数据对数概率的下界。
3.3DBM的微调
完成上面的学习后,DBM中每一层的二进值特征由原来的激活值变为一个确定的真实概率。DBM将会以下面的方式初始化为一个层数确定的多层神经网络。对于每个输入向量v,通过平均场推导可得到一个近似后验分布q(h|v)。这个近似后验分布的边缘分布q(h2j=1|v)与样本数据一起作为这个深度多层神经网络的“增广”输入,见图3。然后通过标准的后向传播微调这个模型。
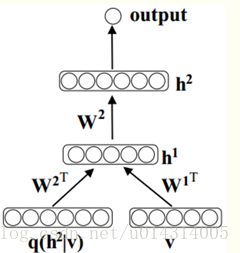
图3:学习完成后,DBM被初始化为一个多层神经网络。边缘后验概率q(h2|v)作为另外一个输入。这个网络通过后向传播进行微调
上面这个不同寻常的输入,实际上只是把DBM转换为一个确定层数的神经网络所得到一个副产品。基于梯度的微调一般会忽略q(h2|v),比如,使第一层的连接权值W2为0就会得到一个标准神经网络模型。相反地,这个模型使第一层的连接权值W1为0就会忽略数据的输入。在我做的实验中,这个模型是用整个增广输入来作预测。
4 实验结果
在实验中,利用了MNIST和NORB数据集。为了加快学习速率,数据集被细分为了很多个mini-batches。每个mini-batches包含了100个样本,每完成一个mini-batches的学习就更新一次权值。fantasy particles(理解:就是一对(vi,hi)形成的系统)用于追踪模型的统计,它的数量为100的平方。对于随机逼近算法,本实验用5步Gibbs采样更新fantasyparticles。学习速率初始化为0.005,然后逐渐降到0。对于DBM的微调,实验中在5000个mini-batches基础上用共轭梯度算法进行微调,在每次迭代中对每个mini-batches进行3次线性搜索。
4.1MNIST数据集
文章中说,通过这个实验发现DBM比DBN要好。原话:Table 1 shows that theestimates of the lower bound on the average test logprobability were −84.62 and−85.18 for the 2- and 3-layer BM’s respectively. This result is slightlybetter compared to the lower bound of −85.97, achieved by a two-layerdeep belief network (Salakhutdinov and Murray, 2008).

图4: 左图:实验中的2个DBM; 右图:训练集中随机抽样出的样本和从2个DBM中通过10万步Gibbs采样所得到对应的样本。图中显示的是已知隐藏单元状态条件下的可视单元概率密度。
2层的BM错误识别率只有0.95%,在该论文之前,这个错误率是最低的。3层的BM的错误识别率为1.01%,而SVM的错误率是1.4%,随机初始化后向传播错误率是1.6%,DBN的错误率是1.2%(hinton 2006)。
4.2NORB数据集
本实验中的2层BM的错误率为10.8%,SVM的错误率是11.6%,逻辑回归的错误率是22.5%,K均值的错误率是18.4%。
1.如何使用受限玻尔兹曼机
现在玻尔兹曼机已经学习完毕,我们接下来怎么使用呢?现在假设有一条新的数据:
![]()
首先我们计算出每个隐元的激励值 (activation) :
![]()
将每个隐元的激励值都用 SigMod 函数进行标准化,变成它们处于开启状 (用 1 表示) 的概率值:
![]()
接下来就是与我们预设的阈值进行比较:

这样我们就知道是否该开启隐层。
2.其中提到的高效CD(ContrastiveDivergence)算法(为了在求解最大似然函数最大化时求偏导的中间表达式中的式子涉及到v,h的全部2|v|+|h|种组合,计算量非常大(基本不可解)。)基本如下:
利用之前我们说到的各维之间独立的性质,首先根据数据v得到h的状态,然后通过h来重构(Reconstruct)可见向量v1,然后再根据v1来生成新的隐藏向量h1。因为RBM的特殊结构(层内无连接,层间有连接),所以在给定v时,各个隐藏单元hj的激活状态之间是相互独立的,反之,在给定h时,各个可见单元的激活状态vi也是相互独立的,即:
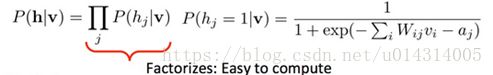
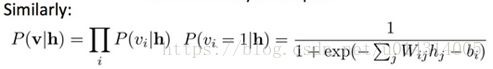
其实,这个算法就是对比散列算法,通过这个算法,可以通过迭代得到所有的参数:
①将可见变量状态,设置为当前训练的样本状态{0,1}
②利用上面第一个公式更新隐藏变量的状态,计算P(hj=1|v)的概率决定。
③对于每个边vihj,计算Pdata(vihj)=vi*hj
(注意,vi和hj的状态都是取{0,1})。
④根据上面第二个公式重构v1
⑤根据v1上面的第一个公式再求得h1,计算Pmodel(v1ih1j)=v1i*h1j
⑥更新边vihj的权重Wij为Wij=Wij+L*(Pdata(vihj)=Pmodel(v1ih1j))。
⑦取下一个数据样本,重复这个过程。