航空公司客户价值分析(附完整代码)
一、什么是客户价值分析:
客户价值分析是以客户为中心,从客户需求出发,搞清楚客户需要什么,他们有怎样的一个特征,需要什么样的产品,然后设计相应的产品,通过对客户分群从而满足客户的需求。进行客户价值分析,可以避免商家闭门造车以及主观臆断客户的需求。
二、项目背景:
项目背景为某航空公司需要以客户为中心,按照客户的需求,在对客户的特点了解上使用不同的营销手段,目的是争取更多新客户,降低客户流失率,降低服务成本,提高业务收入,增加ARPU值(average revenue per user每个用户的平均收益,一般以月为单位),精准的市场营销策略制定。
为什么使用聚类模型?
对于航空公司而言根据过往运营经验,可以大概知道客户类型,但是随着数据量越来越大的时候必须要是用数据挖掘方法对数据做更精准的分析,并得到定量的分析结果。同时由于客户数量很多,且消费行为复杂,人工很难事先对客户打标签,得到训练数据。
三、项目需求:
本项目的目标客户是公众客户(分为公众客户、商业客户即公司、大客户),因而只对公众客户进行分群。初步的目标是中高端用户、中端用户、趋势用户、其他需求用户。但这是经验而言,最终结果需要看模型的运行结果,不能主观臆断。
四、项目的输出:
(1)通过聚类,将公众客户合理地分为多个类别。
(2)聚类完成后,分组观察每个类别的具体情况。分组对数据的各方面做一个观察,包括年龄,性别以及消费情况等等。
五、聚类模型方法步骤:
先用层次聚类逐步聚拢的方式筛选出距离最远的比较合适的k类别数(簇),用dendrogram(scipy.cluster.hierachy.linkage层次聚类,scipy.cluster.hierarchy.dendrogram画图)作图,子树的高度表示它两个后代相互之间的距离,确定k之后放入kmeans模型进行聚类。
六、项目数据
给出了关于62988个客户的基本信息和在观测窗口内的消费积分等相关信息,其中包含了会员卡号、入会时间、性别、年龄、会员卡级别、在观测窗口内的飞行公里数、飞行时间等44个特征属性。
七、代码实现:
为了便于观察数据,采用anaconda的notebook进行分析及可视化
#-*- coding: utf-8 -*-
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
data = pd.read_csv(r'.\\data\\air_data.csv', encoding="utf-8")
print(data.shape)
print(data.info())
data = data[data["SUM_YR_1"].notnull() & data["SUM_YR_2"].notnull()]
index1 = data["SUM_YR_1"] != 0
index2 = data["SUM_YR_2"] != 0
index3 = (data["SEG_KM_SUM"] == 0) & (data["avg_discount"] == 0)
data = data[index1 | index2| index3]
print(data.shape)
filter_data = data[[ "FFP_DATE", "LOAD_TIME", "FLIGHT_COUNT", "SUM_YR_1", "SUM_YR_2", "SEG_KM_SUM", "AVG_INTERVAL" , "MAX_INTERVAL", "avg_discount"]]
filter_data[0:5]
data["LOAD_TIME"] = pd.to_datetime(data["LOAD_TIME"])
data["FFP_DATE"] = pd.to_datetime(data["FFP_DATE"])
data["入会时间"] = data["LOAD_TIME"] - data["FFP_DATE"]
data["平均每公里票价"] = (data["SUM_YR_1"] + data["SUM_YR_2"]) / data["SEG_KM_SUM"]
data["时间间隔差值"] = data["MAX_INTERVAL"] - data["AVG_INTERVAL"]
deal_data = data.rename(
columns = {"FLIGHT_COUNT" : "飞行次数", "SEG_KM_SUM" : "总里程", "avg_discount" : "平均折扣率"},
inplace = False
)
filter_data = deal_data[["入会时间", "飞行次数", "平均每公里票价", "总里程", "时间间隔差值", "平均折扣率"]]
print(filter_data[0:5])
filter_data['入会时间'] = filter_data['入会时间'].astype(np.int64)/(60*60*24*10**9)
print(filter_data[0:5])
print(filter_data.info())
filter_zscore_data = (filter_data - filter_data.mean(axis=0))/(filter_data.std(axis=0))
filter_zscore_data[0:5]
def distEclud(vecA, vecB):
"""
计算两个向量的欧式距离的平方,并返回
"""
return np.sum(np.power(vecA - vecB, 2))
def test_Kmeans_nclusters(data_train):
"""
计算不同的k值时,SSE的大小变化
"""
data_train = data_train.values
nums = range(2, 10)
SSE = []
for num in nums:
sse = 0
kmodel = KMeans(n_clusters=num, n_jobs=4)
kmodel.fit(data_train)
# 簇中心
cluster_ceter_list = kmodel.cluster_centers_
# 个样本属于的簇序号列表
cluster_list = kmodel.labels_.tolist()
for index in range(len(data)):
cluster_num = cluster_list[index]
sse += distEclud(data_train[index, :], cluster_ceter_list[cluster_num])
print("簇数是", num, "时; SSE是", sse)
SSE.append(sse)
return nums, SSE
nums, SSE = test_Kmeans_nclusters(filter_zscore_data)
#画图,通过观察SSE与k的取值尝试找出合适的k值
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = 'SimHei'
plt.rcParams['font.size'] = 12.0
plt.rcParams['axes.unicode_minus'] = False
# 使用ggplot的绘图风格
plt.style.use('ggplot')
## 绘图观测SSE与簇个数的关系
fig=plt.figure(figsize=(10, 8))
ax=fig.add_subplot(1,1,1)
ax.plot(nums,SSE,marker="+")
ax.set_xlabel("n_clusters", fontsize=18)
ax.set_ylabel("SSE", fontsize=18)
fig.suptitle("KMeans", fontsize=20)
plt.show()
kmodel = KMeans(n_clusters=5, n_jobs=4)
kmodel.fit(filter_zscore_data)
# 简单打印结果
r1 = pd.Series(kmodel.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(kmodel.cluster_centers_) # 找出聚类中心
# 所有簇中心坐标值中最大值和最小值
max = r2.values.max()
min = r2.values.min()
r = pd.concat([r2, r1], axis=1) # 横向连接(0是纵向),得到聚类中心对应的类别下的数目
r.columns = list(filter_zscore_data.columns) + [u'类别数目'] # 重命名表头
# 绘图
fig = plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, polar=True)
center_num = r.values
feature = ["入会时间", "飞行次数", "平均每公里票价", "总里程", "时间间隔差值", "平均折扣率"]
N = len(feature)
for i, v in enumerate(center_num):
# 设置雷达图的角度,用于平分切开一个圆面
angles = np.linspace(0, 2 * np.pi, N, endpoint=False)
# 为了使雷达图一圈封闭起来,需要下面的步骤
center = np.concatenate((v[:-1], [v[0]]))
angles = np.concatenate((angles, [angles[0]]))
# 绘制折线图
ax.plot(angles, center, 'o-', linewidth=2, label="第%d簇人群,%d人" % (i + 1, v[-1]))
# 填充颜色
ax.fill(angles, center, alpha=0.25)
# 添加每个特征的标签
ax.set_thetagrids(angles * 180 / np.pi, feature, fontsize=15)
# 设置雷达图的范围
ax.set_ylim(min - 0.1, max + 0.1)
# 添加标题
plt.title('客户群特征分析图', fontsize=20)
# 添加网格线
ax.grid(True)
# 设置图例
plt.legend(loc='upper right', bbox_to_anchor=(1.3, 1.0), ncol=1, fancybox=True, shadow=True)
# 显示图形
plt.show()
# 详细输出原始数据及其类别
res = pd.concat([data,
pd.Series(kmodel.labels_, index=data.index)],
axis=1) # 详细输出每个样本对应的类别
res.columns = list(data.columns) + [u'class'] # 重命名表头
res.to_excel('.\\data\\result2.xls') # 保存结果
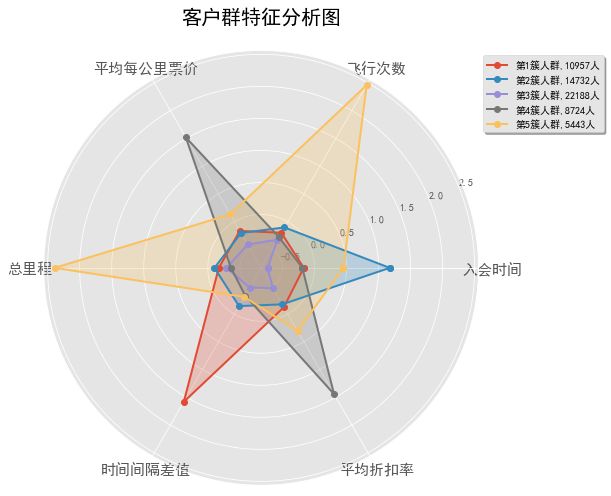
本案例,主要采用数据变换的方式为属性构造和数据标准化 3.需要构造LRFMC的五个指标
L=LOAD_TIME-FFP_DATE(会员入会时间距观测窗口结束的月数=观测窗口的结束时间-入会时间(单位:月))
R=LAST_TO_END(客户最近一次乘坐公司距观测窗口结束的月数=最后一次。。。)
F=FLIGHT_COUNT(观测窗口内的飞行次数)
M=SEG_KM_SUM(观测窗口的总飞行里程)
C=AVG_DISCOUNT(平均折扣率)
客户关系长度L,消费时间间隔R,消费频率F,飞行里程M,折扣系数的平均值C。
横坐标上,总共有五个节点,按顺序对应LRFMC。
对应节点上的客户群的属性值,代表该客户群的该属性的程度。
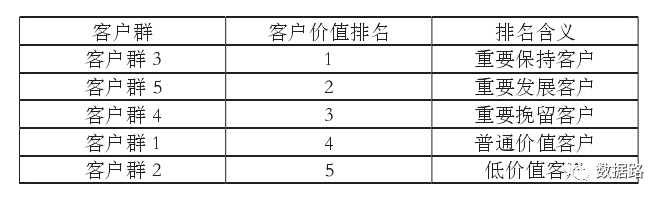
八、客户价值分析

我们重点关注的是L,F,M,从图中可以看到:
1、客户群4[blue]的F,M很高,L也不低,可以看做是重要保持的客户;
2、客户群3[yellow] 重要发展客户
3、客户群1[red] 重要挽留客户,原因:入会时间长,但是F,M较低
4、客户群2[green] 一般客户
5、客户群5[black] 低价值客户
-
重要保持客户:R(最近乘坐航班)低,F(乘坐次数)、C(平均折扣率高,舱位较高)、M(里程数)高。最优先的目标,进行差异化管理,提高满意度。
-
重要发展客户:R低,C高,F或M较低,潜在价值客户。虽然说,当前价值不高,但是却有很大的发展潜力,促使这类客户在本公司消费和合作伙伴处消费。
-
重要挽留客户:C、F、M较高,但是较长时间没有乘坐(R)小。增加与这类客户的互动,了解情况,采取一定手段,延长客户生命周期。
-
一般与低价值客户:C、F、M、L低,R高。他们可能是在公司打折促销时才会乘坐本公司航班。
九、模型应用
-
会员的升级与保级(积分兑换原理相同)
会员可以分为,钻石,白金,金卡,银卡…
部分客户会因为不了解自身积分情况,错失升级机会,客户和航空公司都会有损失
在会员接近升级前,对高价值客户进行促销活动,刺激他们消费达到标准,双方获利
-
交叉销售
通过发行联名卡与非航空公司各做,使得企业在其他企业消费过程中获得本公司的积分,增强与本公司联系,提高忠诚度。
-
管理模式
企业要获得长期的丰厚利润,必须需要大量稳定的、高质量的客户。
维持老客户的成本远远低于新客户,保持优质客户是十分重要的。
精准营销中,也有成本因素,所以按照客户价值排名,进行优先的,特别的营销策略,是维持客户的关键。
十.小结
本文结合航空公司客户价值案例的分析,重点介绍了数据挖掘算法中K-Means聚类算法的应用。
针对,传统RFM模型的不足,结合案例进行改造,设定了五个指标的LRFMC模型。最后通过聚类的结果,选出客户价值排行,并且制定相应策略。
完整代码和数据集下载地址:https://download.csdn.net/download/u010963246/11391738
参考链接:
基于聚类(Kmeans)算法实现客户价值分析系统(电信运营商)
数据挖掘–基于KMeans算法的客户价值分析
数据挖掘——航空公司客户价值分析(代码完整)
数据分析实战-利用K-Means进行航空公司客户价值识别
利用K-Means聚类进行航空公司客户价值分析