WIDER FACE六项第一!阿里达摩院提出MogFace:人脸检测新工作 | CVPR 2022
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> 【人脸检测】微信技术交流群
一、开源

MogFace: Towards a Deeper Appreciation on Face Detection
1. 论文链接:
https://openaccess.thecvf.com/content/CVPR2022/papers/Liu_MogFace_Towards_a_Deeper_Appreciation_on_Face_Detection_CVPR_2022_paper.pdf
2. 代码模型:
https://modelscope.cn/models/damo/cv_resnet101_face-detection_cvpr22papermogface/summary
3. 可玩应用:
https://modelscope.cn/studios/baigui/face_album/summary
二、背景
人脸检测算法是在一幅图片或者视频序列中检测出来人脸的位置,给出人脸的具体坐标,一般是矩形坐标。它是人脸关键点、属性、编辑、风格化、识别等模块的基础。本文通过实验观察发现,对应设计出如下三个模块构建出一个高性能的人脸检测器MogFace:1.)动态标签分配策略(dynamic label assignment),2.)误检上下文相关性分析(FP context analysis),3.)金字塔层级监督信号分配(pyramid layer level GT assignment)。该方法的模型在WIDER FACE榜单上取得了截止目前将近两年的六项第一。
三、观察
1.1 动态标签分配策略(dynamic label assignment)
为每个anchor点定义cls和reg目标是训练检测器的必要过程,在人脸检测中这个过程称之为标签分配(Label Assignment)。最近,标签分配吸引了诸多研究人员的注意,在人脸检测及通用物体检测领域提出了一系列方法,例如:OTA、PAA,ATSS以及HAMBox。如示例图(a),标签分配过程依赖4个元素。分别是:1.)offline information: a.)IoU (anchor与ground-truth框的IoU) , b.)CPD (anchor与ground-truth中心点的距离) ,2.)online information: a.)PCS (cls分支对anchor的前景分类概率值) ,b.)PLC (reg分支对anchor的预测坐标值)。
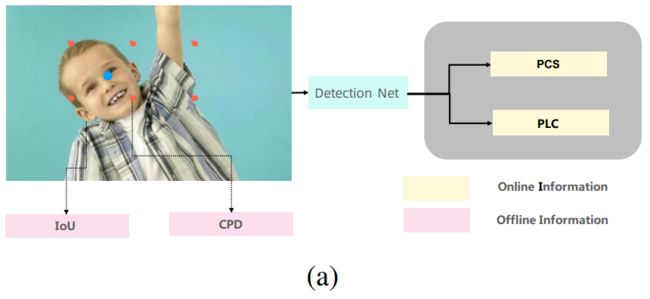
但是,目前的标签分配方法存在三个问题。1.)若只用offline information做静态标签分配,那么会有很多具备更强回归能力的negative anchor无法被有效利用起来,会导致标签分配策略欠饱和。2.)若过度信任online information动态调整正负anchor时(如OTA和Hambox),由于online information属于预测信息可信度不高,会导致标签分配策略错误多, 极端情况下会陷入trivial 的分配结果。3.) 若引入大量超参 (K in ATSS, alpha in OTA)做标签分配,则当数据集分布发生变化时,需要大量的调参时间。
1.2 误检上下文相关性分析(FP context analysis)
在实际应用中,人脸检测器并不会十分care AP的指标,而对误检(false positive [FP])的数量十分敏感。针对这个问题,目前的做法是收集大量带有FP的图片去fine-tune或者from scratch训练检测器,来帮助检测器了解更多范式的FP,但是我们发现有些频繁出现在训练集中的的FP在这种策略下无法有效解决。这篇文章,我们发现了一个有趣的现象:对于同一个FP,当它的context发生变化时,对于同一个检测器来说它可能就不是FP了。如下图(c),最左面的图片里日历是FP,剩余两张日历都不是FP。

1.3 金字塔层级监督信号分配(pyramid layer level GT assignment)
scale-level 数据增强策略常常作通用物体检测以及人脸检测中解决scale variance主要手段。如图(b)所示,相对于COCO,人脸检测数据集Wider Face 中人脸的尺度分布更为严峻。为此,我们分提出了一个新的问题,如何合理的分配ground-truth 在不同pyramidlayer上的分布?即检测器的性能与每个pyramidlayer匹配ground-truth的个数之间的关系是什么?是否越多越好?通过严格的对比实验我们发现:“对于所有的pyramid layer来说,并不是这个pyramid layer匹配到越多的ground-truth就越好”。这说明要挖掘每一个pyramidlayer的最好性能,需要控制在这个pyramidlayer上的ground-truth分配的比例。

四、方法
2.1 Adaptive Online Incremental Anchor Mining Strategy (Ali-AMS)
针对上述“动态标签分配策略(dynamic label assignment)”观察分析,本文提出了在里面一种自适应的在线增量锚挖掘策略(Ali-AMS),它基于standard anchor matching 策略,并进一步adaptive 帮助outlier face匹配anchor。如下:

2.2 Hierachical Context-Aware Module (HCAM)
基于上述“误检上下文相关性分析(FP context analysis)”观察分析,发现“对于同一个FP,当它的context发生变化时,对于同一个检测器来说他可能就不是FP了”,我们进一步提出了一个two-step的模块来显示的encode context 信息来帮助区分FP和TP,显著减少了FP的数量。

2.3 Selective Scale Enhancement Strategy (SSE)
基于上述的“金字塔层级监督信号分配(pyramid layer level GT assignment)”观察分析,发现“对于所有的pyramid layer来说,并不是这个pyramid layer匹配到越多的ground-truth就越好”,我们提出通过控制pyramid layer 匹配的ground-truth的数量来最大化pyramid layer 的性能。

五、实验
3.1 Ablation Study

3.2 Comparison with sota

点击进入—> CV 微信技术交流群
CVPR/ECCV 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:ECCV2022,即可下载CVPR 2022论文和代码开源的论文合集后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
人脸检测 交流群成立
扫描下方二维码,或者添加微信:CVer222,即可添加CVer小助手微信,便可申请加入CVer-人脸检测 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如人脸检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer222,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看