《knowledge graph embedding:a survey of approaches and applications》论文阅读
发表于TKDE 2017。
knowledge graph embedding:a survey of approaches and applications
- abstract
- 1. introduction
- 2. notations
- 3. KG embedding with facts alone
-
- 3.1 translational distance models
-
- 3.1.1 TransE and Its Extensions
- 3.1.2 gaussian embeddings
- 3.1.3 other distance models
- 3.2 semantic matching models
-
- 3.2.1 RESCAL and its extensions
- 3.2.2 matching with neural networks
- 3.3 model training
-
- 3.3.1 training under open world assumption
- 3.3.2 training under closed world assumption
- 3.4 model comparison
- 4. incorporating additional information
-
- 4.1 entity types
- 4.2 relation paths
- 4.3 textual descriptions
- 4.4 logical rules
- 4.5 other information
- 5. applications in downstream tasks
-
- 5.1 In-KG applications
-
- 5.5.1 link prediction
- 5.1.2 triple classification
- 5.1.3 entity classification
- 5.1.4 entity resolution
- 5.2 out-of-KG applications
abstract
knowledge graph (KG) embedding是对KG中的实体和关系进行嵌入到连续空间中,在保持KG内部结构的情况下简化操作的计算。本文中的review 基于在embedding任务中用到的信息的种类。
1. introduction
KG是节点和关系构成的多关系图。每个边都具有三元组的形式: ( h e a d e n t i t y , r e l a t i o n , t a i l e n t i t y ) (head entity, relation, tail entity) (headentity,relation,tailentity),也被称为是一个 f a c t fact fact。虽然这种三元组的表达形式能够有效表示结构数据,但是也造成了操作的困难性。于是KG embedding被提出,并获得了很大的关注度,可以被应用于:KG补充,关系挖掘、实体分类、实体解析等。
现在最多的KG embedding方法都只是单单基于observed facts。给定一个KG,将实体和关系变换到连续向量空间,定义一个scoring函数来在每个facts上评价它的合理性。实体和关系embeddings就可以通过观察到的facts的最大合理性来得到。但是这种基于individual fact的方式,可能对于下游任务不够准确,于是越来越多的方法通过使用其他种类的信息来进行研究以获得更加准确的embeddings,e.g. :实体种类,关系路径,文本描述,甚至逻辑规则等。
2. notations
不作介绍
3. KG embedding with facts alone
KG被保存于一些三元组的集合中 D + = { ( h , r , t ) } . \mathbb{D}^+ = \{(h,r,t)\}. D+={(h,r,t)}.一个典型的KG embedding technique包括三步:(1)表示实体和关系 (2)定义一个scoring function (3)学习实体和关系表征。第一步往往定义了实体和关系在连续向量空间中的形式。实体通常被定义为一个向量,如:向量空间中的确定点,最近也有工作考虑了实体的不确定性,通过多维高斯模型进行建模。关系通常被当作向量空间中的操作,也可以被表示为向量、矩阵、张量、多维高斯分布,甚至混合高斯等。之后,一个scoring function f r ( h , t ) f_r(h,t) fr(h,t) 被定义在每一个facts ( h , r , t ) (h,r,t) (h,r,t)上来对合理性进行度量。步骤三则解决了最大化observed facts(facts包含在 D + \mathbb{D}^+ D+上的)上的总合理性优化任务。这些embedding techniques可以被大体分为两类:translational distance models、semantic matching models。前者使用了基于距离的scoring函数,后者则使用了基于相似度的。
3.1 translational distance models
3.1.1 TransE and Its Extensions
TransE是最具代表性的translational distance model。



3.1.2 gaussian embeddings

3.1.3 other distance models
3.2 semantic matching models
3.2.1 RESCAL and its extensions

3.2.2 matching with neural networks
ps:从下面这张图的SME开始,前面两种方法是上一小节的。


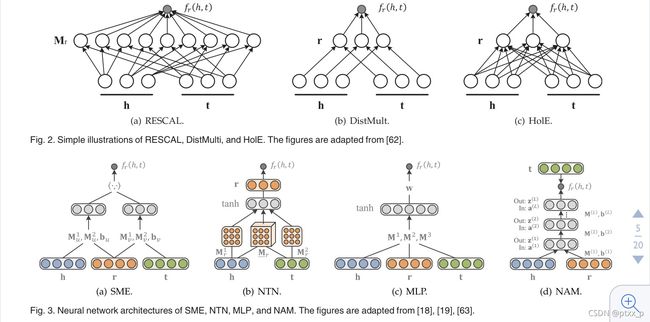
3.3 model training
包括两种广泛使用的假设:the open world assumption,closed world assumption。
3.3.1 training under open world assumption
the open world assumption (OWA)是指KGs只包括true facts,未观察到的facts可能是错的或者只是missing。在这种情况下, D + \mathbb{D}^+ D+只包括了positive examples。negative examples可以通过启发式方法生成,例如:the local closed world assumption。根据positive set D + \mathbb{D}^+ D+以及相应生成的negative set D − \mathbb{D}^- D−,我们可以通过最小化logistic loss(更适用于semantic matching models),pairwise ranking loss(更适用于translational distance models)来学习实体和关系的表征 Θ \Theta Θ。
生成负训练样本:通过随机替换true facts中的h or t来实现。但是这种方法可能会导致引入false-negative training examples,于是可以通过以不同的概率来替换h or t缓解这一情况。有实验表明:生成更多的negative examples可以得到更好的实验结果,每个positive example搭配50个negative examples可以获得最好的性价比(因为训练时间也会相应增加)。
3.3.2 training under closed world assumption
the closed world assumption (CWA)是指凡是未在 D + \mathbb{D}^+ D+中的facts都是错误的。可以通过最小化如squared loss的损失函数来学习实体和关系的representation,使得observed facts具有接近1的分数,non-observed scores接近于0。
这种CWA的world assumption具有很多的缺点:会把缺失的facts强行视作是false,现实中的大多数KG都是incomplete的,CWA-based models常常比OWA-based models表现差;CWA 假设将会引入大量的负样本,可能会在训练过程中导致可扩展性的问题。
3.4 model comparison
根据以上模型的比较,我们有以下结论:1⃣️利用向量来表示实体和关系的模型往往更加efficient。2⃣️将关系建模为矩阵或张量的方法往往具有更高的时空复杂度。3⃣️基于神经网络的模型具有更高的时间复杂度。
4. incorporating additional information
可以综合的信息包括:entity types,relation paths,textual descriptions,logical rules等。
4.1 entity types
4.2 relation paths
4.3 textual descriptions
这个部分讨论了对于实体的描述性信息的加入。
这种加入文本信息描述的方法追溯回NTN模型,文本信息被用来初始化实体表征(descriptions的平均word vectirs)。但是这种方法使得文本信息和KG facts分离,因此fail to 利用它们之间的交互信息。
之后joint model出现,在embedding的过程中更好地利用文本信息。key idea是将KG与附加的文本语料进行对齐,之后同时产生KG embedding和word embedding。这样,实体/关系和words都被表示于相同的向量空间,于是它们之间做的操作(如:内积)就变得meaningful了。joint model具有三个成分:knowledge model,text model,alignment model。knowledge model被用来对KG中的实体和关系进行嵌入。text model被用来对text corpus中的单词进行嵌入。最后,alignment model保证了实体/关系嵌入以及单词嵌入位于同一空间之中。具有不同的alignment mechanisms:通过实体名称、通过实体描述等。jointly embedding同时使用了结构化KGs和无结构的text的信息。
4.4 logical rules
4.5 other information
包括实体属性、时序信息、图结构、从其他关系学习方法中得到的evidence等的。
5. applications in downstream tasks
KG embedding的应用可以被分类为:in-KG applications,out-of-KG applications。
5.1 In-KG applications
In-KG applications是指conducted within the scope of the KG where entity and relation embeddings are learned。我们介绍了四种这样的应用:link prediction,triple classification,entity classification,entity resolution。所有的应用都可以被称为是一种对输入KG的改善(e.g. complication or 重复数据删除等)。
5.5.1 link prediction
预测 ( ? , r , t ) , ( h , r , ? ) , ( h , ? , t ) . (?,r,t),(h,r,?),(h,?,t). (?,r,t),(h,r,?),(h,?,t).由于实体和关系表征之前被学习过了,link prediction可以被简单的认为是一个ranking procedure。常用的评测指标,包括:mean rank(预测的rank的平均值),mean reciprocal rank(相关rank的平均值),Hits@n(不大于n的rank的占比),AUC-PR(precision-recall curve下的area的面积)。
5.1.2 triple classification
判断一个unseen triple fact ( h , r , t ) (h,r,t) (h,r,t)是true or false。评价指标可以用:micro- or macro-averaged accuracy,mean average precision。
5.1.3 entity classification
目标是将实体分类入不同的语义类之中,可以将这种任务视为是一种特殊的link prediction任务(x is a ?)。
5.1.4 entity resolution
用于判断两个实体是否指代同一个object。entity resolution实际上是nodes的去重任务。可以计算两个entity的representation的相似度来判断两者是否是同一个object。AUC-PR是这种任务下最常用的评测指标。
5.2 out-of-KG applications
out-of-KG applications是指打破了输入KG的边界以及扩展到更宽广的domains时。我们介绍了三种应用:relation extraction(目标是从plain text中挖掘relational facts where entities have already been detected),question answering(给定用自然语言表达的问题,目标是返回正确的answer,被KG中的triples所反馈的),recommender systems(提供给user建议购买的items)。