DataX新组件开发<附准备\开发\测试>:阿里云SLS日志服务数据reader组件
DataX介绍:
DataX是一个离线数据同步工具/平台的中间件,是阿里开源的。实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。他们还有一个收费的叫DataWorks。
很贵就是了~ 我没钱!而且开源的也够用了!所以用开源的。
开发该组件的原因:
最近有一些数据需要做采集,这些数据因为一些原因选择投递到阿里云的SLS日志服务(通过消费组消费日志数据 (aliyun.com))里。但又因为一些原因,这些数据的重要程度不是很高,但也不是都没用,还是要采集出来分析的。
那这种情况使用DataWorks、MaxComputer是有点浪费的。而且那玩意还有容量一说。时间长了还得清理啥的。。麻球烦的很
那就用DataX吧,然后发现目前自带的组件里没有能读取SLS数据的。而且民间也没有大神开发,好吧没法施展Ctrl C + Ctrl V大法了~
那就自己开发吧~
一、准备工作
1. 拉取DataX仓库
alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。 (github.com)
git clone https://github.com/alibaba/DataX2. DataX的编译、打包
打包命令
mvn -U clean package assembly:assembly -Dmaven.test.skip=true开发插件之前请熟读DataX文档。熟读并且多看看~ 不说全部都理解,最起码要知道他的原理。
这是开发插件的文档:
DataX/dataxPluginDev.md at master · alibaba/DataX (github.com)
补一下这个文档里瞎掉的两个图:
框架按照如下的顺序执行Job和Task的接口:
黄色表示Job部分的执行阶段,蓝色表示Task部分的执行阶段,绿色表示框架执行阶段。

相关类关系如下:

打包成功后,根目录会有一个target目录的,里面就是完成的datax运行目录~ 线上也是这样的~ 后面第三点说测试的时候会用到
小技巧:
如果觉得组件太多,打包太慢,或者某些组件老报错,那就从根pom里先把这些module给注释了。然后重新编译~
3. python环境 2和3都行
为啥2和3都行,你会发现有些搜到的文档里说必须2.7。那都是老版本了。有人优化了python脚本。
具体可以看这个提交记录:migrate datax.py to python3, and compatible with python2 · alibaba/DataX@c2027ed (github.com)
如果你clone下来的代码依然是2的版本,那就可以从这个提交记录里copy下来覆盖你的python脚本。
需要覆盖的脚本在:

二、开发
然后就是开发插件了~
1. 使用命令脚手架创建组件(我没用这个,因为报错)
参数介绍:
- DgroupId:新项⽬目的groupId 【保持与示例一致即可】
- Dpackage:新项⽬目的package 【保持与示例一致即可】
- Dversion:新项⽬目的version 【保持与示例一致即可】
- DarchetypeGroupId:模板⼯工程的GroupId 【保持与示例一致即可】
- DarchetypeVersion:模板⼯工程的Version 【保持与示例一致即可】
- DarchetypeArtifactId:模板⼯工程的ArtifactId
- DartifactId:新项⽬目的artifactId 建议命名方式为插件名称(在命令的最后面,=后面需要补充插件名称)
jdbc类型:
wirter
mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxwriterplugin-archetype -DartifactId=reader:
mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxreaderplugin-archetype -DartifactId=其他类型:
wirter:
mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxcommonwriterplugin-archetype -DartifactId=reader:
mvn archetype:generate -DarchetypeGroupId=com.dtwave.dipper.datax.plugin -DarchetypeVersion=1.0.0-SNAPSHOT -X -DarchetypeCatalog=local -DgroupId=com.dtwave.datax.plugin -Dpackage=com.dtwave.dipper.datax.plugin -Dversion=1.0.0-SNAPSHOT -DarchetypeArtifactId=dataxcommonreaderplugin-archetype -DartifactId=生成的结构如下:
.
├── doc
│ └── README.md 插件文档
├── pom.xml
├── src
│ └── main
│ ├── assembly
│ │ └── package.xml 打包配置
│ ├── java
│ └── resources
│ └── plugin.json 插件描述2. 使用idea在DataX上面创建一个空依赖的maven module



然后,照着上面的结构,改造一下生成的新组件,记得找一个其他的组件把pom依赖抄过来

上面只是创建的例子,下面的截图部分以我自己新做的插件来说明:
这是结构:

下面这些文件都是什么作用,里面的key是什么含义,为什么要这样写我就不解释了。上面提到的开发文档里说的很清楚
assembly/package.xml文件:
dir
false
src/main/resources
plugin.json
plugin_job_template.json
plugin/reader/aliyunslsreader
target/
aliyunslsreader-0.0.1-SNAPSHOT.jar
plugin/reader/aliyunslsreader
false
plugin/reader/aliyunslsreader/libs
runtime
resources/plugin.json:
{
"name": "aliyunslsreader",
"class": "com.alibaba.datax.plugin.reader.aliyunslsreader.AliyunSlsReader",
"description": "use datax framework to transport data from aliyun sls.",
"developer": "dancoder"
}resources/plugin_job_template.json
{
"name": "aliyunslsreader",
"parameter": {
"endpoint": "",
"accessId": "",
"accessKey": "",
"project": "",
"logstore": "",
"consumeGroup": "",
"threadDuration": 300,
"encoding": "UTF-8",
"column": [
{
"value": "",
"type": "",
"format": ""
}
]
}
}然后就是Reader主要的文件了:
AliyunSlsReader.java

必须继承Reader类,然后也必须使用内部类的方式创建Job和Task类,并分别继承Reader.Job 和Reader.Task。至于啥含义,为啥弄. 官方文档里也有,我就不搬运了。
然后就是其他的一些支持类,比如说我要做阿里云SLS的数据消费,那我就肯定要找阿里云SLS的日志消费文档。
要做kafka的,就找kafka的文档,就照猫画虎的写了
三、测试
这玩意可是重头戏,因为不好测试啊。都没有个Application类啥的带头~ 总不可能盲写。那这东西线上可不经用~
1. 找到Engine类

2. 加入本地编译后的home目录指向、以及加载的json文件目录
打开后,找到最底下的main方法,在try里面加两句:
//设置运行的datax的家目录
System.setProperty("datax.home", "D:\\code\\DataX\\target\\datax\\datax");
//设置datax的运行脚本信息
args = new String[]{"-mode", "standalone", "-jobid", "-1", "-job", "D:\\code\\DataX\\target\\datax\\datax\\job\\job.json"};上面两行代码,有两个地方是个路径,可以看出,是在DataX根目录下的target下。上面有提到过哈,要打包成功才会生成这玩意;
在这:
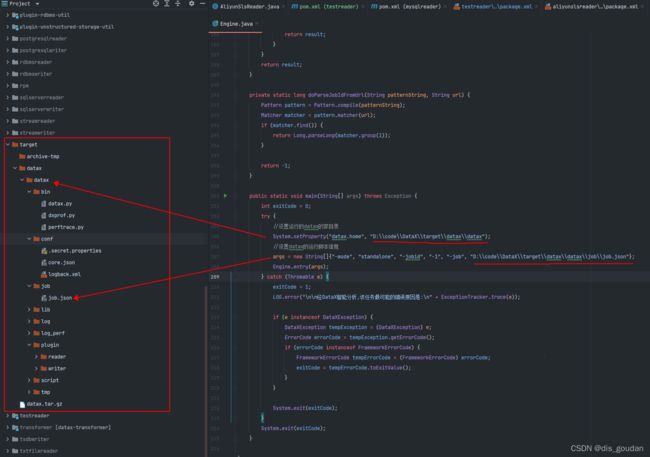
这个必须要弄对,不然后面跑测试的时候就会出现找不到core.json啊,找不到job.json啊。找不到home目录啊,
如果有神经大条的直接把我这个抄去,那目录不一样的肯定开头都跑不起来
到时候人也跑不动,代码也跑不动!两个有一个能跑的定律就被打破了~
3. 相信到这一步的兄弟,你的组件已经开发的差不多了。就算没有读数据或者写数据的能力,但最起码应该能跑起来打印点东西了
那就再编译一次DataX,看看DataX/target/datax/datax/plugin/reader或者wirter/有没有你的组件目录,没有的话,就去对应组件的target下把他copy过来,
比如我这个:

就把这整个aliyunslsreader 目录copy到上面说道的DataX/target/datax/datax/plugin/reader/下面
4. 编辑DataX/target/datax/datax/job/job.json
这个就看自己开发的是啥类型的了,如果自己开发是reader组件,那就把reader改成自己的格式,配置参数。writer默认使用mysqlwriter好了。方便简单~ 大家本地都有mysql的
如果开发的是writer组件,那就使用mysqlreader组件作为读数据的。
我把我的json贴一下:我弄的是reader组件。
{
"job": {
"content": [
{
"reader": {
"name": "aliyunslsreader",
"parameter": {
"endpoint": "cn-shanghai.log.aliyuncs.com",
"accessId": "xxx",
"accessKey": "xxx",
"project": "projectName",
"logstore": "test_logstore",
"consumeGroup": "consumeGroupName",
"threadDuration": 30,
"encoding": "UTF-8",
"column": [
{
"value": "a",
"type": "string",
"format": ""
},
{
"value": "b",
"type": "string",
"format": ""
},
{
"value": "c",
"type": "long",
"format": ""
},
{
"value": "d",
"type": "long",
"format": ""
},
{
"value": "e",
"type": "date",
"format": "yyyy-MM-dd"
},
{
"value": "f",
"type": "bool",
"format": ""
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"cleanRule": 1,
"column": [
"a",
"b",
"c",
"d",
"e",
"f"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/test",
"table": [
"`testtable`"
]
}
],
"password": "123456",
"username": "root",
"writeMode": "insert"
}
}
}
],
"setting": {
"errorLimit": {
"record": 0
},
"speed": {
"channel": 5,
"throttle": false
}
}
}
}5. 启动
在DataX/target/datax/datax/目录使用黑框框,或者洋气一点,用GitBash
python bin/datax.py job/job.json -d然后应该会看到这个出来:
Administrator@DESKTOP-2S5OBR9 MINGW64 /d/code/DataX/target/datax/datax (master)
$ python bin/datax.py job/job.json -d
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.
Listening for transport dt_socket at address: 9999记住这个listening 的9999
转战Idea:
配置Run/Debug Configurations

选择Remote:
Host填写localhost
端口写刚才命令行里出现的9999
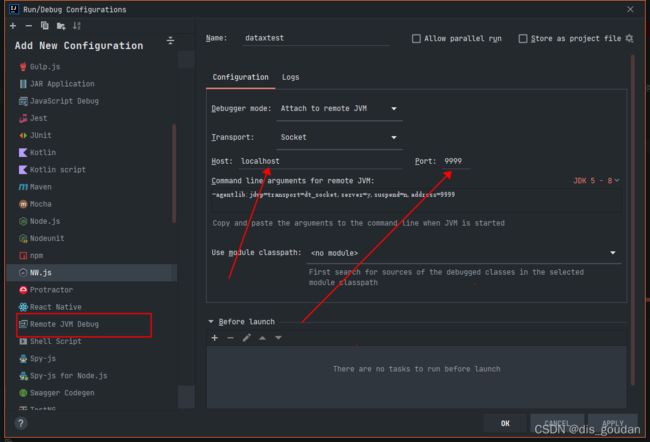
在自己的逻辑里打上断点~

然后启动!

下面是整个启动过程:
至于后面这个演示为啥我刷新页面,控制台里就能有数据刷新,就当浏览器刷新是在往loghub里投递数据。
然后被开发的组件消费到了~
本组件仓库:datax-aliyunslsreader: DataX reader组件 消费阿里云SLS日志服务数据 (gitee.com)
想转载,麻烦附上本文连接,现在搜点东西,千篇一律,错字都抄~
如果被我发现原模原样抄的 。那我也没办法~