DataX 源码调试及打包
文章目录
-
-
-
- 1、源码分析
- 2、打包
- 3、任务测试
- 4、job配置详解
-
- Reader(读插件)
- Writer(写插件)
- 通用配置
-
-
前文回顾:
《DataX 及 DataX-Web 安装使用详解》
除了前文介绍的我们可以直接安装使用外,还可以下载源码打包,并且对源码进行适当修改,比如我这里在同步数据到 oracle 时,由于 datax 只能做 oracle 的 insert,如果主键重复的数据就冲突了。
源码地址:https://github.com/alibaba/DataX
1、源码分析
找到 core 这个包下的datax.py
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (DEFAULT_PROPERTY_CONF, CLASS_PATH)
可以看到程序入口是com.alibaba.datax.core.Engine,进入这个类,main方法如下
public static void main(String[] args) throws Exception {
int exitCode = 0;
try {
Engine.entry(args);
} catch (Throwable e) {
exitCode = 1;
LOG.error("\n\n经DataX智能分析,该任务最可能的错误原因是:\n" + ExceptionTracker.trace(e));
if (e instanceof DataXException) {
DataXException tempException = (DataXException) e;
ErrorCode errorCode = tempException.getErrorCode();
if (errorCode instanceof FrameworkErrorCode) {
FrameworkErrorCode tempErrorCode = (FrameworkErrorCode) errorCode;
exitCode = tempErrorCode.toExitValue();
}
}
System.exit(exitCode);
}
System.exit(exitCode);
}
然后就,就自己顺着看吧。
2、打包
打包的时候测试失败导致打包失败,所以跳过测试打包,idea控制台输入如下命令。
mvn -U clean package assembly:assembly '-Dmaven.test.skip=true'

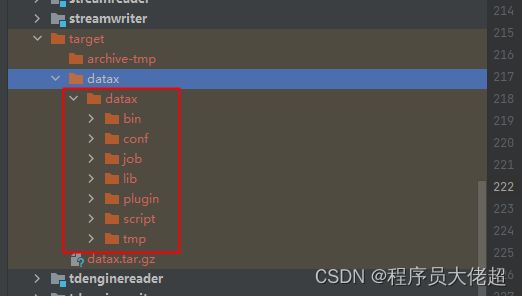
打包成功后的 datax 包位于 {DataX_source_code_home}/target/datax/datax/,结构如下
最后执行下自检脚本
python datax.py ../job/job.json
我这里执行任务时,提示了如下错误
[job-0] ERROR Engine -
经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Framework-03], Description:[DataX引擎配置错误,该问题通常是由于DataX安装错误引起,请联系您的运维解决 .]. - 在有总bps限速条件下,单个channel的bps值不能为空,也不能为非正数
at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:30)
at com.alibaba.datax.core.job.JobContainer.adjustChannelNumber(JobContainer.java:430)
at com.alibaba.datax.core.job.JobContainer.split(JobContainer.java:387)
at com.alibaba.datax.core.job.JobContainer.start(JobContainer.java:117)
at com.alibaba.datax.core.Engine.start(Engine.java:93)
at com.alibaba.datax.core.Engine.entry(Engine.java:175)
at com.alibaba.datax.core.Engine.main(Engine.java:208)
原因:DataX的配置有问题,单个 channel 的 bps 值不能为空,也不能为非正数。所以查看 datax 源码,core\src\main\conf下的 core.json 文件,内容如下。
注:如果是安装的 datax,则位置在 datax/conf/core.json。
{
"entry": {
"jvm": "-Xms1G -Xmx1G",
"environment": {}
},
"common": {
"column": {
"datetimeFormat": "yyyy-MM-dd HH:mm:ss",
"timeFormat": "HH:mm:ss",
"dateFormat": "yyyy-MM-dd",
"extraFormats":["yyyyMMdd"],
"timeZone": "GMT+8",
"encoding": "utf-8"
}
},
"core": {
"dataXServer": {
"address": "http://localhost:7001/api",
"timeout": 10000,
"reportDataxLog": false,
"reportPerfLog": false
},
"transport": {
"channel": {
"class": "com.alibaba.datax.core.transport.channel.memory.MemoryChannel",
"speed": {
"byte": -1,
"record": -1
},
"flowControlInterval": 20,
"capacity": 512,
"byteCapacity": 67108864
},
"exchanger": {
"class": "com.alibaba.datax.core.plugin.BufferedRecordExchanger",
"bufferSize": 32
}
},
"container": {
"job": {
"reportInterval": 10000
},
"taskGroup": {
"channel": 5
},
"trace": {
"enable": "false"
}
},
"statistics": {
"collector": {
"plugin": {
"taskClass": "com.alibaba.datax.core.statistics.plugin.task.StdoutPluginCollector",
"maxDirtyNumber": 10
}
}
}
}
}
可以看到core -> transport -> channel -> speed -> byte的默认值为:-1
解决办法:
修改内容:将byte值设置为: 1048576,代表单个channel容纳的最多字节数,可以适当调大,不oom就行。
"speed": {
"byte": 1048576,
"record": -1
},
3、任务测试
创建一个job,json文件内容如下
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "chaodev123",
"column": [
"`id`",
"`user_id`",
"`message`",
"`send_date`",
"`channel`",
"`sendUser`",
"`receiver`",
"`contentType`",
"`pictureUrl`",
"`longitude`",
"`latitude`",
"`coordinateType`",
"`isRead`",
"`msgType`",
"`readTime`",
"`create_time`",
"`state`",
"`fileName`",
"`fileDownloadUrl`"
],
"splitPk": "",
"connection": [
{
"table": [
"message"
],
"jdbcUrl": [
"jdbc:mysql://192.168.152.40:3306/im"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "123456",
"column": [
"`id`",
"`user_id`",
"`message`",
"`send_date`",
"`channel`",
"`sendUser`",
"`receiver`",
"`contentType`",
"`pictureUrl`",
"`longitude`",
"`latitude`",
"`coordinateType`",
"`isRead`",
"`msgType`",
"`readTime`",
"`create_time`",
"`state`",
"`fileName`",
"`fileDownloadUrl`"
],
"preSql": [
"truncate table message"
],
"connection": [
{
"table": [
"message"
],
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/im"
}
]
}
}
}
]
}
}
执行任务,如下
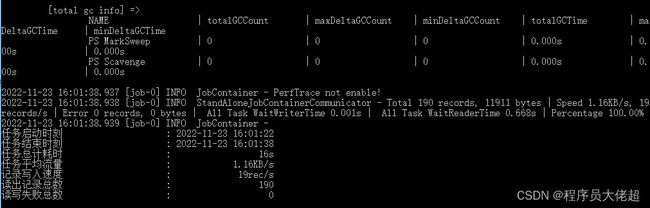
python datax.py ../job/im_message.json
可以看到,任务执行成功。
4、job配置详解
Reader(读插件)
name:与要读取的数据库一致(字符串)jdbcUrl:数据库链接(数组)username:数据库用户名(字符串)password:数据库密码(字符串)table:要同步的表名(数组),需保证表结构一致column:要同步的列名(数组)where:选取的条件(字符串)querySql:自定义查询语句, 会自动忽略上述的同步条件
Writer(写插件)
name:与要读取的数据库一致(字符串)jdbcUrl:数据库链接(字符串)username:数据库用户名( 字符串)password: 数据库密码 (字符串)table:要同步的表名(数组),需保证表结构一致column:列名可以不对应,但是类型和总的个数要一致( 数组),需保证表结构一致preSql: 写入前执行的语句(数组),比如清空表等,如TRUNCATE TABLE @table(或指定表名)postSql: 写入后执行的语句 (数组)writeMode:写入模式,默认insert ,可选(insert/replace/update)。
insert 模式就是直接插入,如果主键冲突就无法插入;replace 模式如果存在记录则先删除该条记录再插入;update 模式则是有重复进行更新。需要注意的是oracle只支持insert配置项。session:DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性。batchSize:默认值1024,一次性批量提交的记录数大小,该值可以极大减少DataX与数据库交互次数,但是该值设置过大可能会造成OOM。
通用配置
job.setting.speed(流量控制):channel的值控制同步时的并发数,byte的值控制单个channel容纳的最多字节数。job.setting.errorLimit(脏数据控制):对脏数据的自定义监控和告警,包括对脏数据最大记录数阈值(record值)或者脏数据占比阈值(percentage值),当Job传输过程出现的脏数据大于指定的数量/百分比,DataX Job报错退出。
后续继续更新datax-web源码打包、二次开发支持Oracle更新数据等,如果觉得有帮助就给大佬超点个关注点个赞吧。
更多技术干货,请持续关注程序员大佬超。
原创不易,转载请注明出处。