MNN源码阅读之模型转换
模型转换
每一个开源框架,都有自己的模型格式,MNN中支持,CAFFE,TensorFLow,ONNX等格式的网络结构转换成mnn格式。
为了方便大多都会将训练好的网络模型转成ONNX第三方通用的结构,这里主要分析mnn如何将ONNX的结构转换成自己支持的mnn格式。
模型转换的流程:
0. onnx结构
在此之前,需要先了解下onnx的结构。
onnx最外层是model,包含一些基础信息,onnx版本,来源框架/工具,来源工具版本等信息,当然还有最重要的计算图Graph(网络图结构)。
Model成员表
| 成员名称 | 解释 |
|---|---|
| ir_version | onnx版本 |
| opset_import | 模型的操作算计集合。必须支持集合中的所有算子,否则模型无法加载。 |
| producer_name | 模型来源框架或者工具,pytorch等 |
| producer_version | 来源工具版本 |
| domain | 表示模型名称空间或域的反向DNS名称,例如“org.onnx” |
| doc_string | 此模型的可读文档 |
| graph | 模型计算图以及权重参数 |
| metadata_props | metadata和名称的映射表 |
| training_info | 包含训练的一些信息 |
Graph成员表
| 成员名称 | 解释 |
|---|---|
| name | 模型计算图名称 |
| node | 计算图中的节点列表,基于输入/输出数据依赖性形成一个部分有序的计算图。它是拓扑顺序的。 |
| initializer | 一个tensor的列表。当与计算图中输入具有相同名称时,它将为该输入指定默认值。反之,它将指定一个常量值。 |
| doc_string | 此模型的可读文档 |
| input | 计算图中所有节点的输入 |
| output | 计算图所有节点的输出 |
| value_info | 用于存储非输入或输出值的类型和shape |
Node成员表
| 成员名称 | 解释 |
|---|---|
| name | 节点名称 |
| input | 节点输入,计算图输入,或者initializer或者其他节点的输出 |
| output | 节点的输出 |
| op_type | 算子操作类型 |
| domain | 算子的操作域, |
| attribute | 算子的一些信息,或者不会用于传播的常量 |
| doc_string | 可读的文档信息 |
Attribute的成员表
| 成员名称 | 解释 |
|---|---|
| name | 属性名称 |
| doc_string | 可读的文档信息 |
| type | 属性的类型,确定剩余字段中用于保存属性值的字段。 |
| f | 32位的浮点值 |
| i | 64位整数 |
| s | UTF-8字符串 |
| t | 一个tensor |
| g | 一个计算图 |
| floats | 浮点数组 |
| ints | 整型数组 |
| strings | 字符串数组 |
| tensors | tensor数组 |
| graphs | 计算图数组 |
1. 模型转换
先看模型转换的主要流程。
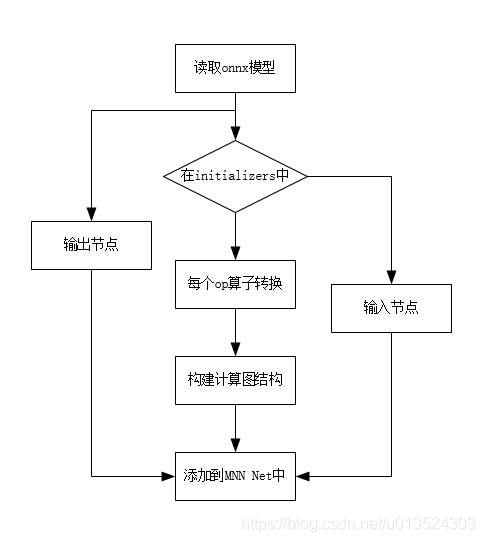
int onnx2MNNNet(const std::string inputModel, const std::string bizCode,
const common::Options& options, std::unique_ptr<MNN::NetT>& netT) {
onnx::ModelProto onnxModel;
// 读取onnx模型
bool success = onnx_read_proto_from_binary(inputModel.c_str(), &onnxModel);
DCHECK(success) << "read onnx model failed: " << inputModel;
LOG(INFO) << "ONNX Model ir version: " << onnxModel.ir_version();
const auto& onnxGraph = onnxModel.graph();
const int nodeCount = onnxGraph.node_size();
std::shared_ptr<OnnxTmpGraph> onnxTempGraph(new OnnxTmpGraph(&onnxGraph));
// op_name: name
// get mnn op pointer conveniently, then manipulate the mnn op
std::map<std::string, MNN::OpT*> mnnNodesMap;
// all tensors container
std::map<std::string, int> tensorsName;
// find the inputs which do not have initializer
// initializers是一个list,即是一个权重的tensor列表,并且每个元素都有明确的名字,和输出列表中的名字对应
const auto& initializers = onnxTempGraph->mInitializers;
// 模型中所有的输入和输出,包括最开始输入的图像以及每个结点的输入输出信息
const auto& inputs = onnxTempGraph->mInputs;
const auto& outputs = onnxTempGraph->mOutputs;
const auto& constantNodeToDelete = onnxTempGraph->mConstantNodeToDelete;
for (const auto& iter : inputs) {
bool notHaveInitializer = initializers.find(iter.first) == initializers.end();
// 找到不在initializers列表中的输入,从下面的代码可以看出,不在initializers中的是输入节点。
if (notHaveInitializer) {
netT->tensorName.push_back(iter.first);
tensorsName.insert(std::make_pair(iter.first, tensorsName.size()));
}
}
// 把没有initializers的输入节点添加到net中
for (const auto& iter : tensorsName) {
// here tensorsName are true Input node name
MNN::OpT* MNNOp = new MNN::OpT;
MNNOp->name = iter.first;
MNNOp->type = MNN::OpType_Input;
MNNOp->main.type = MNN::OpParameter_Input;
auto inputParam = new MNN::InputT;
const auto it = inputs.find(iter.first);
DCHECK(it != inputs.end()) << "Input Paramter ERROR ==> " << iter.first;
const auto& tensorInfo = (it->second)->type().tensor_type();
const int inputDimSize = tensorInfo.shape().dim_size();
inputParam->dims.resize(inputDimSize);
for (int i = 0; i < inputDimSize; ++i) {
inputParam->dims[i] = tensorInfo.shape().dim(i).dim_value();
}
inputParam->dtype = onnxOpConverter::convertDataType(tensorInfo.elem_type()); // onnx数据类型转换成mnn的数据类型
inputParam->dformat = MNN::MNN_DATA_FORMAT_NCHW; // 数据格式为NCHW
MNNOp->outputIndexes.push_back(tensorsName[iter.first]);
MNNOp->main.value = inputParam;
mnnNodesMap.insert(std::make_pair(iter.first, MNNOp));
netT->oplists.emplace_back(MNNOp);
}
// onnx的节点导入到mnn的节点中
for (int i = 0; i < nodeCount; ++i) {
const auto& onnxNode = onnxGraph.node(i);
const auto& opType = onnxNode.op_type();
// name maybe null, use the first output name as node-name
const auto& name = onnxNode.output(0);
// TODO not to use constantNodeToDelete anymore
if (constantNodeToDelete.find(name) != constantNodeToDelete.end()) {
continue;
}
// 找到对应op类型的转换器
auto opConverter = onnxOpConverterSuit::get()->search(opType);
MNN::OpT* MNNOp = new MNN::OpT;
MNNOp->name = name;
MNNOp->type = opConverter->opType();
MNNOp->main.type = opConverter->type();
mnnNodesMap.insert(std::make_pair(name, MNNOp));
// convert initializer to be Constant node(op) 将权重转换为常量节点
for (int k = 0; k < onnxNode.input_size(); ++k) {
const auto& inputName = onnxNode.input(k);
const auto it = initializers.find(inputName);
if (it != initializers.end() && tensorsName.find(it->first) == tensorsName.end()) {
// Create const Op
MNN::OpT* constOp = new MNN::OpT;
constOp->type = MNN::OpType_Const;
constOp->main.type = MNN::OpParameter_Blob;
constOp->main.value = onnxOpConverter::convertTensorToBlob(it->second); // onnx的tensor转换为mnn的tensor
mnnNodesMap.insert(std::make_pair(inputName, constOp));
auto outputIndex = (int)netT->tensorName.size();
constOp->name = it->first;
constOp->outputIndexes.push_back(outputIndex);
tensorsName.insert(std::make_pair(it->first, outputIndex));
netT->tensorName.emplace_back(constOp->name);
netT->oplists.emplace_back(constOp);
}
}
// TODO, delete the run() args opInitializers 删除一些不在opInitializers中的节点。
std::vector<const onnx::TensorProto*> opInitializers;
for (int k = 0; k < onnxNode.input_size(); ++k) {
const auto& inputName = onnxNode.input(k);
const auto it = initializers.find(inputName);
if (it != initializers.end()) {
opInitializers.push_back(it->second);
}
}
// 执行算子转换
opConverter->run(MNNOp, &onnxNode, opInitializers);
netT->oplists.emplace_back(MNNOp);
const int outputTensorSize = onnxNode.output_size();
for (int ot = 0; ot < outputTensorSize; ++ot) {
netT->tensorName.push_back(onnxNode.output(ot));
tensorsName.insert(std::make_pair(onnxNode.output(ot), tensorsName.size()));
}
}
// set input-output tensor's index
for (int i = 0; i < nodeCount; ++i) {
const auto& onnxNode = onnxGraph.node(i);
auto iter = mnnNodesMap.find(onnxNode.output(0));
DCHECK(iter != mnnNodesMap.end()) << "Can't find node: " << onnxNode.name();
auto curOp = mnnNodesMap[onnxNode.output(0)];
// set input index
const int inputSize = onnxNode.input_size();
for (int j = 0; j < inputSize; ++j) {
const auto& inputName = onnxNode.input(j);
// onnx have optional input, which may be a placeholder when pytorch export onnx model, so drop this input, but we should check it out sometimes.
if(inputName == ""){
LOG(INFO) << "Check it out ==> " << curOp->name << " has empty input, the index is " << j;
continue;
}
auto iterTensor = tensorsName.find(inputName);
DCHECK(iterTensor != tensorsName.end()) << "Can't find tensor: " << inputName;
curOp->inputIndexes.push_back(iterTensor->second);
}
// set output index
const int outputSize = onnxNode.output_size();
for (int j = 0; j < outputSize; ++j) {
const auto& outputName = onnxNode.output(j);
auto iterTensor = tensorsName.find(outputName);
DCHECK(iterTensor != tensorsName.end()) << "Can't find tensor: " << outputName;
curOp->outputIndexes.push_back(iterTensor->second);
}
}
netT->tensorNumber = tensorsName.size();
// set MNN net output name
for (const auto& iter : outputs) {
netT->outputName.push_back(iter.first);
}
netT->sourceType = MNN::NetSource_ONNX;
netT->bizCode = bizCode;
return 0;
}
这里opConverter->run(MNNOp, &onnxNode, opInitializers);是算子转换的执行入口,onnx的不同的算子转换器都是继承自onnxOpConverter类,根据操作类型会找到对应的算子转换器,例如卷积,池化,argmax等都有自己的实现。
查找函数如下
onnxOpConverter* onnxOpConverterSuit::search(const std::string& name) {
auto iter = mConverterContainer.find(name);
if (iter == mConverterContainer.end()) {
static DefaultonnxOpConverter defaultConverter;
return &defaultConverter;
}
return iter->second;
}
如果没有找到,则使用默认的转换器。
先来看下通用转换方法的实现:
virtual void run(MNN::OpT* dstOp, const onnx::NodeProto* onnxNode,
std::vector<const onnx::TensorProto*> initializers) override {
auto extra = new ExtraT;
dstOp->main.type = OpParameter_Extra;
dstOp->main.value = extra;
extra->engine = "ONNX";
extra->type = onnxNode->op_type();
for (auto srcAttr : onnxNode->attribute()) { // 读取节点中的每个属性,并写入mnn的op中
std::unique_ptr<AttributeT> attr(new AttributeT);
attr->key = srcAttr.name();
switch (srcAttr.type()) {
case onnx::AttributeProto_AttributeType_INTS: // 整型值属性,即i的值
attr->list.reset(new ListValueT);
attr->list->i.resize(srcAttr.ints_size());
for (int i = 0; i < srcAttr.ints_size(); ++i) {
attr->list->i[i] = _limit(srcAttr.ints(i));
}
break;
case onnx::AttributeProto_AttributeType_FLOATS: // 浮点值属性,即f值
attr->list.reset(new ListValueT);
attr->list->f.resize(srcAttr.floats_size());
for (int i = 0; i < srcAttr.floats_size(); ++i) {
attr->list->f[i] = srcAttr.floats(i);
}
break;
case onnx::AttributeProto_AttributeType_TENSOR: // tensor 即t值
attr->tensor.reset(convertTensorToBlob(&srcAttr.t()));
break;
default:
break;
}
attr->i = _limit(srcAttr.i());
attr->s = srcAttr.s();
attr->f = srcAttr.f();
extra->attr.emplace_back(std::move(attr));
}
}
2. 模型优化
std::unique_ptr<MNN::NetT> optimizeNet(std::unique_ptr<MNN::NetT>& originNet, bool forTraining) {
if (originNet->sourceType == NetSource_TENSORFLOW) {
GenerateSubGraph(originNet);
}
std::vector<MNN::SubGraphProtoT*> subgraphs;
for (auto& subgraph : originNet->subgraphs) {
subgraphs.push_back(subgraph.get());
}
OptimizeContext ctx;
ctx.subgraphs = subgraphs;
ctx.is_training = forTraining;
ctx.verbose = true;
ctx.source = originNet->sourceType;
ctx.completed_subgraphs = {};
ctx.RunOptimize = optimizeNetImpl;
// 初始化OptimizeContext, Global将其设置为单例
Global<OptimizeContext>::Reset(&ctx);
std::unordered_map<std::string, VARP> empty;
for (auto& subGraph : originNet->subgraphs) {
CompleteSubGraph(empty, subGraph.get()); // 子图优化
}
// 执行网络优化
std::unique_ptr<MNN::NetT> net = ctx.RunOptimize(originNet, empty);
fuseConstIntoSubgraph(net.get(), ctx.completed_subgraphs);
for (auto* subgraph : ctx.completed_subgraphs) {
net->subgraphs.emplace_back(subgraph);
}
return std::move(net);
}
模型优化具体实现函数如下,包括了post优化,两步program优化。
std::unique_ptr<MNN::NetT> optimizeNetImpl(std::unique_ptr<MNN::NetT>& originNet,
const std::unordered_map<std::string, VARP>& inputs) {
auto* ctx = Global<OptimizeContext>::Get();
MNN_ASSERT(ctx != nullptr);
if (ctx->is_training) {
LOG(INFO) << "convert model for training, reserve BatchNorm and Dropout";
}
if (originNet->oplists.size() <= 0) {
return nullptr;
}
// post优化
std::vector<std::string> postConvertPass;
postConvertPass = { // 所有的优化方法
// Seperate Tensor for inplace op 直接运算得分离tensor
"RemoveInplace",
// Remove Unuseful Op such as NoOp, Identity, Seq2Out, 删除一些无用的操作
"RemoveUnusefulOp",
// Remove Dropout, if `forTraining` flag is set, Dropout will be reserved 不训练得时候移除dropout
"RemoveDropout",
// Turn InnerProduct from Caffe / Onnx to Convolution 将caffe/onnx得内积转换为卷积运算
"TransformInnerProduct",
// Turn Im2Seq from Caffe to Reshape 将caffe得im2seq转换为reshape操作
"TransformIm2Seq",
// Turn Caffe's ShuffleChannel to compose op 将caffe得通道混洗操作转换为组合操作
"TransformShuffleChannel",
// Turn Onnx's Pad to Tensorflow's Pad 将onnx得pad转换为tf得pad
"TransformOnnxPad",
};
if (ctx->is_training) { // 如果训练就山去掉移除dropout优化项
std::vector<std::string>::iterator iter;
for (iter = postConvertPass.begin(); iter != postConvertPass.end(); iter++) {
if (*iter == "RemoveDropout") {
postConvertPass.erase(iter);
}
}
}
// 执行上述所有的优化方法
RunNetPass(postConvertPass, originNet);
std::unique_ptr<MNN::NetT> newNet;
newNet = std::move(RunExtraPass(originNet, inputs));
newNet = std::move(RunMergePass(newNet, inputs, PASS_PRIORITY_HIGH));
// program优化
std::vector<std::string> afterProgramConvert = {
// Turn BatchNormal to Scale When inference, if `forTraining` flag is set, BN will be reserved
"TransformBatchNormal",
// expand ShapeN to N Shapes
"ResolveTfShapeN",
// WARNNING: should merge BN and Scale before Relu and Relu6
// Merge BN info Convolution, if `forTraining` flag is set, BN will be reserved
"MergeBNToConvolution",
// Merge Scale info Convolution
"MergeScaleToConvolution",
// Merge Relu Convolution
"MergeReluToConvolution",
// Merge Relu6 Convolution
"MergeRelu6ToConvolution",
};
if (ctx->is_training) {
std::vector<std::string>::iterator iter;
for (iter = afterProgramConvert.begin(); iter != afterProgramConvert.end(); iter++) {
if (*iter == "TransformBatchNormal" || *iter == "MergeBNToConvolution") {
afterProgramConvert.erase(iter);
}
}
}
RunNetPass(afterProgramConvert, newNet);
newNet = std::move(RunMergePass(newNet, inputs, PASS_PRIORITY_MIDDLE));
afterProgramConvert = {
// Add tensor dimension format convert for NC4HW4 - NHWC / NC4HW4 - NCHW
"AddTensorFormatConverter",
// Turn group convolution to Slice - Convolution - Concat
"TransformGroupConvolution",
// Remove output tensor convert
"RemoveOutputTensorConvert",
};
RunNetPass(afterProgramConvert, newNet);
// Maybe eliminate the redundant quantize and dequantize ops, then remove
// the unuseful `Identity`.
newNet = std::move(RunMergePass(newNet, inputs, PASS_PRIORITY_LOW));
// Maybe eliminate the redundant tensor format ops, then remove the unuseful
// `Identity`.
newNet = std::move(RunMergePass(newNet, inputs, PASS_PRIORITY_LOW));
newNet = std::move(RunMergePass(newNet, inputs, PASS_PRIORITY_FINAL));
RunNetPass({"ReIndexTensor"}, newNet);
return std::move(newNet);
}
void RunNetPass(const std::vector<std::string>& passes, std::unique_ptr<MNN::NetT>& originNet) {
for (auto pass : passes) {
// 先找到指定的优化方法
auto convert = PostConverter::get(pass);
if (nullptr == convert) {
LOG(INFO) << "Can't find pass of " << pass << "\n";
continue;
}
// 执行优化
bool valid = convert->onExecute(originNet);
if (!valid) {
LOG(INFO) << "Run " << pass << "Error\n";
}
}
}
下面以MergeBNToConvolution为例,分析是如何优化的。
class MergeBNToConvolution : public MergeToConvolution {
public:
bool merge2Convolution(const MNN::OpT* inplaceOp, MNN::OpT* convolutionOp) const {
...
}
bool merge2Convolution3D(const MNN::OpT* inplaceOp, MNN::OpT* convolutionOp) const {
...
}
}
static PostConverterRegister<MergeBNToConvolution> __l("MergeBNToConvolution");
可见先将MergeBNToConvolution注册进PostConverter中的转换器map中,所以通过key可以找到指定的优化器。
接下来再分析如何对BN和Convolution进行融合。
首先来看卷积和BN的计算公式:
卷积运算:
Y = W x + b Y = Wx + b Y=Wx+b
BN运算:
第一步,减均值,除以标准差
x o = x − m e a n v a r x_o = \frac{x - mean}{\sqrt{var}} xo=varx−mean
第二步,旋转和偏移
Y = γ ( x o ) + β Y = \gamma(x_o) + \beta Y=γ(xo)+β
在融合后,可以得出如下结果:
Y = γ W v a r x + γ b − m e a n v a r + β Y = \gamma \frac{W}{\sqrt{var}} x + \gamma \frac{b - mean}{\sqrt{var}} + \beta Y=γvarWx+γvarb−mean+β
此时可以得到新的W和b
W n e w = γ W v a r W_{new} = \gamma \frac{W}{\sqrt{var}} Wnew=γvarW
b n e w = γ b v a r − γ m e a n v a r + β b_{new} = \gamma \frac{b}{\sqrt{var}} - \gamma \frac{mean}{\sqrt{var}} + \beta bnew=γvarb−γvarmean+β
bool merge2Convolution(const MNN::OpT* inplaceOp, MNN::OpT* convolutionOp) const {
const auto& convCommon = convolutionOp->main.AsConvolution2D()->common;
if (convCommon->relu || convCommon->relu6 || convolutionOp->inputIndexes.size() > 1) {
return false;
}
if (inplaceOp->type == MNN::OpType_BatchNorm) {
std::vector<float> alpha;
std::vector<float> bias;
auto l = inplaceOp->main.AsBatchNorm();
alpha.resize(l->channels);
bias.resize(l->channels);
const float* slopePtr = l->slopeData.data();
const float* meanDataPtr = l->meanData.data();
const float* varDataPtr = l->varData.data();
const float* biasDataPtr = l->biasData.data();
const float eps = l->epsilon;
for (int i = 0; i < l->channels; i++) {
float sqrt_var = sqrt(varDataPtr[i] + eps);
bias[i] = biasDataPtr[i] - slopePtr[i] * meanDataPtr[i] / sqrt_var;
alpha[i] = slopePtr[i] / sqrt_var;
}
auto conv2D = convolutionOp->main.AsConvolution2D();
int outputCount = conv2D->common->outputCount;
for (int i = 0; i < outputCount; ++i) {
conv2D->bias[i] = conv2D->bias[i] * alpha[i] + bias[i]; // b_new
}
if (nullptr != conv2D->quanParameter.get()) {
for (int i = 0; i < outputCount; ++i) {
conv2D->quanParameter->alpha[i] *= alpha[i];
}
} else {
int weightPartSize = conv2D->weight.size() / outputCount;
if (convolutionOp->type == OpType_Deconvolution) {
int inputCount =
conv2D->weight.size() / outputCount / conv2D->common->kernelX / conv2D->common->kernelY;
for (int i = 0; i < inputCount; ++i) {
auto dstPos = i * outputCount * conv2D->common->kernelY * conv2D->common->kernelX;
for (int j = 0; j < outputCount; ++j) {
auto dstPosJ = dstPos + j * conv2D->common->kernelY * conv2D->common->kernelX;
float a = alpha[j];
for (int k = 0; k < conv2D->common->kernelY * conv2D->common->kernelX; ++k) {
conv2D->weight[dstPosJ + k] *= a; // w_bew
}
}
}
} else {
for (int i = 0; i < outputCount; ++i) {
float a = alpha[i];
for (int j = 0; j < weightPartSize; ++j) {
conv2D->weight[i * weightPartSize + j] *= a;
}
}
}
}
return true;
}
return false;
}
这里先大致了解下优化的流程,后续在具体分析如何实现优化。
3.写入文件
int writeFb(std::unique_ptr<MNN::NetT>& netT, const std::string& MNNModelFile, modelConfig config) {
auto RemoveParams = [](std::unique_ptr<MNN::OpT>& op) {
const auto opType = op->type;
switch (opType) {
case MNN::OpType_Convolution:
case MNN::OpType_Deconvolution:
case MNN::OpType_ConvolutionDepthwise: {
auto param = op->main.AsConvolution2D();
param->weight.clear();
param->bias.clear();
break;
}
case MNN::OpType_TfQuantizedConv2D: {
auto param = op->main.AsTfQuantizedConv2D();
param->weight.clear();
param->bias.clear();
break;
}
case MNN::OpType_MatMul: {
auto param = op->main.AsMatMul();
param->weight.clear();
param->bias.clear();
break;
}
case MNN::OpType_BatchNorm: {
auto param = op->main.AsBatchNorm();
param->slopeData.clear();
param->meanData.clear();
param->varData.clear();
param->biasData.clear();
param->Adata.clear();
param->Bdata.clear();
break;
}
case MNN::OpType_Scale: {
auto param = op->main.AsScale();
param->scaleData.clear();
param->biasData.clear();
break;
}
default:
break;
}
};
if (config.benchmarkModel) {
for (auto& op : netT->oplists) {
RemoveParams(op);
}
for (auto& subgraph : netT->subgraphs) {
for (auto& op : subgraph->nodes) {
RemoveParams(op);
}
}
}
// 参数转换为半精度参数,主要用于卷积层
auto CastParamsToHalf = [](std::unique_ptr<MNN::OpT>& op) {
const auto opType = op->type;
switch (opType) {
case MNN::OpType_Convolution:
case MNN::OpType_ConvolutionDepthwise: {
auto param = op->main.AsConvolution2D();
const int weightSize = param->weight.size();
// const int biasSize = param->bias.size();
std::vector<half_float::half> quantizedFp16Weight;
quantizedFp16Weight.resize(weightSize);
std::transform(param->weight.begin(), param->weight.end(), quantizedFp16Weight.begin(),
[](float w) { return half_float::half(w); });
// std::vector quantizedFp16Bias;
// quantizedFp16Bias.resize(biasSize);
// std::transform(param->bias.begin(), param->bias.end(), quantizedFp16Bias.begin(), [](float
// b){return half_float::half(b); });
param->weight.clear();
// param->bias.clear();
param->quanParameter.reset(new MNN::IDSTQuanT);
param->quanParameter->type = 3;
int8_t* halfWeight = reinterpret_cast<int8_t*>(quantizedFp16Weight.data());
param->quanParameter->buffer.assign(halfWeight, halfWeight + sizeof(half_float::half) * weightSize);
break;
}
case MNN::OpType_Const: {
auto blob = op->main.AsBlob();
if (blob->dataType == MNN::DataType_DT_FLOAT) {
blob->dataType = MNN::DataType_DT_HALF;
blob->uint8s.resize(sizeof(half_float::half) * blob->float32s.size());
auto size = blob->float32s.size();
auto dst = (half_float::half*)blob->uint8s.data();
for (int i=0; i<size; ++i) {
dst[i] = blob->float32s[i];
}
blob->float32s.clear();
}
break;
}
default:
break;
}
};
if (config.saveHalfFloat) {
for (auto& op : netT->oplists) {
CastParamsToHalf(op);
}
for (auto& subgraph : netT->subgraphs) {
for (auto& op : subgraph->nodes) {
CastParamsToHalf(op);
}
}
}
// 8bit或者2bit量化
auto WeightQuantAndCoding = [&](std::unique_ptr<MNN::OpT>& op) {
const auto opType = op->type;
// config.weightQuantBits only control weight quantization for float convolution
// by default, do coding for convint8 and depthwiseconvint8, if there is any
if ((config.weightQuantBits == 0) && (
opType != MNN::OpType_ConvInt8 && opType != MNN::OpType_DepthwiseConvInt8)) {
return;
}
if (opType != MNN::OpType_Convolution && opType != MNN::OpType_ConvolutionDepthwise &&
opType != MNN::OpType_Deconvolution && opType != MNN::OpType_DeconvolutionDepthwise &&
opType != MNN::OpType_ConvInt8 && opType != MNN::OpType_DepthwiseConvInt8) {
return;
}
int bits = 8;
if ((config.weightQuantBits > 0) && (
opType != MNN::OpType_ConvInt8 && opType != MNN::OpType_DepthwiseConvInt8)) {
bits = config.weightQuantBits;
}
// Bits must from 2-8
bits = std::max(bits, 2);
bits = std::min(bits, 8);
auto param = op->main.AsConvolution2D();
auto& common = param->common;
if (param->quanParameter.get() != nullptr) {
return;
}
int weightSize = param->weight.size();
if (opType == MNN::OpType_ConvInt8 || opType == MNN::OpType_DepthwiseConvInt8) {
weightSize = param->symmetricQuan->weight.size();
}
int kernelNum = common->outputCount;
int kernelSize = weightSize / kernelNum;
auto gConverterConfig = Global<modelConfig>::Get();
bool asymmetricQuantFlag = gConverterConfig->weightQuantAsymmetric;
std::vector<float> weightData, scales;
switch (opType) {
case MNN::OpType_Convolution:
case MNN::OpType_ConvolutionDepthwise:
case MNN::OpType_Deconvolution:
case MNN::OpType_DeconvolutionDepthwise: {
float thredhold = (float)(1 << (bits - 1)) - 1.0f;
weightData = param->weight;
if (asymmetricQuantFlag) {
scales.resize(kernelNum*2);
for (int k = 0; k < kernelNum; k++) {
int beginIndex = k * kernelSize;
auto minAndMax = findMinMax(weightData.data() + beginIndex, kernelSize);
float min = minAndMax[0];
float max = minAndMax[1];
float scale = (max - min) / (127 + 128);
scales[2*k] = min;
scales[2*k+1] = scale;
}
} else {
scales.resize(kernelNum);
for (int k = 0; k < kernelNum; k++) {
int beginIndex = k * kernelSize;
auto absMax = findAbsMax(weightData.data() + beginIndex, kernelSize);
scales[k] = absMax / thredhold;
}
}
break;
}
case MNN::OpType_ConvInt8:
case MNN::OpType_DepthwiseConvInt8: {
auto& int8Params = param->symmetricQuan;
for (int i = 0; i < int8Params->weight.size(); i++) {
weightData.emplace_back(float(int8Params->weight[i]));
}
scales.resize(kernelNum, 1.0f);
if (asymmetricQuantFlag) {
scales.resize(kernelNum*2, 1.0f);
}
break;
}
default:
break;
}
std::ostringstream outputStringStreamCQ, outputStringStreamSQ;
WriteCQBlobs(outputStringStreamCQ, weightData.data(), scales.data(), kernelSize, kernelNum, asymmetricQuantFlag);
WriteSparseQuanBlobs(outputStringStreamSQ, weightData.data(), scales.data(), kernelSize, kernelNum, asymmetricQuantFlag);
if (opType == MNN::OpType_ConvInt8 || opType == MNN::OpType_DepthwiseConvInt8) {
if (weightSize < (outputStringStreamCQ.str().size() + sizeof(float)) && weightSize < (outputStringStreamSQ.str().size() + sizeof(float))) {
return; // only encode when it is smaller
}
}
param->quanParameter.reset(new MNN::IDSTQuanT);
auto tempString = outputStringStreamCQ.str();
param->quanParameter->type = 1;
if (outputStringStreamSQ.str().size() < tempString.size()) {
tempString = outputStringStreamSQ.str();
param->quanParameter->type = 2;
}
param->quanParameter->buffer.resize(tempString.size());
::memcpy(param->quanParameter->buffer.data(), tempString.data(), tempString.size());
param->quanParameter->quantScale = 1.0f;
if (asymmetricQuantFlag) {
param->quanParameter->readType = kernelNum;
}
if (opType == MNN::OpType_ConvInt8 || opType == MNN::OpType_DepthwiseConvInt8) {
param->symmetricQuan->weight.clear();
param->quanParameter->alpha = {1.0f}; // fake scales
param->quanParameter->has_scaleInt = true;
} else {
param->weight.clear();
param->quanParameter->alpha = std::move(scales);
}
};
{
for (auto& op : netT->oplists) {
WeightQuantAndCoding(op);
}
for (auto& subgraph : netT->subgraphs) {
for (auto& op : subgraph->nodes) {
WeightQuantAndCoding(op);
}
}
}
// 检测不支持的算子
std::set<std::string> notSupportOps;
auto CheckIfNotSupported = [&] (const std::unique_ptr<MNN::OpT>& op) {
if (op->type == MNN::OpType_Extra) {
if (op->main.AsExtra()->engine != "MNN") {
notSupportOps.insert(op->main.AsExtra()->engine + "::" + op->main.AsExtra()->type);
}
}
};
for (auto& op : netT->oplists) {
CheckIfNotSupported(op);
}
for (auto& subgraph : netT->subgraphs) {
for (auto& op : subgraph->nodes) {
CheckIfNotSupported(op);
}
}
std::ostringstream notSupportInfo;
if (!notSupportOps.empty()) {
for (auto name : notSupportOps) {
notSupportInfo << name << " | ";
}
auto opNames = notSupportInfo.str();
LOG(FATAL) << "These Op Not Support: " << opNames.substr(0, opNames.size() - 2);
}
flatbuffers::FlatBufferBuilder builderOutput(1024);
builderOutput.ForceDefaults(true);
// 序列化
auto len = MNN::Net::Pack(builderOutput, netT.get());
builderOutput.Finish(len);
int sizeOutput = builderOutput.GetSize();
auto bufferOutput = builderOutput.GetBufferPointer();
if (config.saveStaticModel && netT->usage != MNN::Usage_INFERENCE_STATIC) {
std::map<std::string, std::vector<int>> inputConfig;
// get config to set input size
if (config.inputConfigFile.size() > 0) {
ConfigFile conf(config.inputConfigFile);
auto numOfInputs = conf.Read<int>("input_size");
auto inputNames = splitNames(numOfInputs, conf.Read<std::string>("input_names"));
auto inputDims = splitDims(numOfInputs, conf.Read<std::string>("input_dims"));
for (int i = 0; i < numOfInputs; i++) {
inputConfig.insert(std::make_pair(inputNames[i], inputDims[i]));
}
}
const Net* net = flatbuffers::GetRoot<MNN::Net>(bufferOutput);
converToStaticModel(net, inputConfig, MNNModelFile);
} else {
std::ofstream output(MNNModelFile, std::ofstream::binary);
output.write((const char*)bufferOutput, sizeOutput); // 写入文件
}
#ifdef MNN_DUMP_SUBGRAPH
for (int i = 0; i < netT->subgraphs.size(); ++i) {
std::unique_ptr<MNN::NetT> subnet(new MNN::NetT);
auto& subgraph = netT->subgraphs[i];
subnet->oplists = std::move(subgraph->nodes);
subnet->tensorName = subgraph->tensors;
subnet->sourceType = netT->sourceType;
subnet->bizCode = netT->bizCode;
flatbuffers::FlatBufferBuilder builder(1024);
builder.ForceDefaults(true);
auto len = MNN::Net::Pack(builder, subnet.get());
builder.Finish(len);
int output_size = builder.GetSize();
auto* output_ptr = builder.GetBufferPointer();
std::string filename =
MNNModelFile + "_subgraph_" + std::to_string(i) + ".mnn";
std::ofstream output(filename.c_str(), std::ofstream::binary);
output.write((const char*)output_ptr, output_size);
}
#endif
return 0;
}
模型文件得写入,可以对模型进行精度转换,或者bit量化,然后将参数序列化,将序列化后的字符串写入文件中。