使用X2MindSpore 迁移PyTorch脚本
视频教程可以在Bilili观看哦!
使用X2MindSpore进行Pytorch脚本迁移_哔哩哔哩_bilibili
1 任务介绍
X2MindSpore是一款脚本转换工具,使用X2MindSpore可以快速实现迁移PyTorch框架的训练/测试脚本到MindSpore框架下。
脚本转换工具会根据适配规则,对用户脚本进行转换,大幅度提高了脚本迁移速度,降低了开发者的工作量。但是需要注意的是,除使用官网模型支持列表(https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/msug/msug_000109.html)的脚本转换成功后可直接运行外,其他脚本的转换结果仅供参考,仍需用户根据实际情况做少量适配。
目前,此脚本转换工具支持PyTorch框架和TensorFlow2.X框架的训练脚本转换。仅能支持所列模型中的工程转换后训练成功且收敛,对最终精度和性能暂不做保证。此脚本转换工具转换后的训练工程支持在MindSpore1.6及更新版本上运行。
2 环境搭建和配置
2.1 MindStudio简介及安装
使用X2MindSpore 迁移PyTorch脚本MindStudio提供了AI开发所需的一站式开发环境,提供图形化开发界面,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。同时还支持网络移植、优化和分析等功能。依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助用户在一个工具上就能高效便捷地完成AI应用开发。同时,MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。
MindStudio支持Windows和Linux两大主流平台。可以根据需要,进行选择下载安装包,具体安装流程,可以参考官网。本图文教程,将基于Windows系统进行X2MindSpore使用介绍。
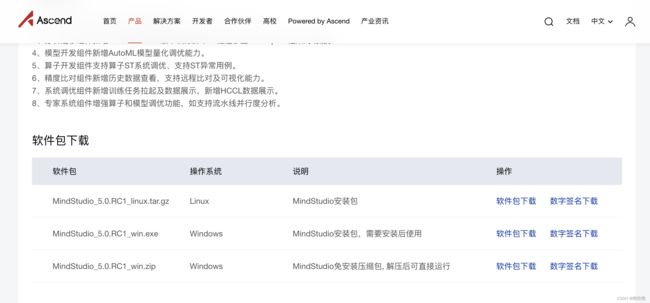
MindStudio软件包下载地址:https://www.hiascend.com/software/mindstudio
/download
Windows平台下载安装流程: https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000018.html
Linux平台下载安装流程: https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000007.html
2.2 CANN简介及安装
CANN(Compute Architecture for Neural Networks)是华为公司针对AI场景推出的异构计算架构,通过提供多层次的编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。
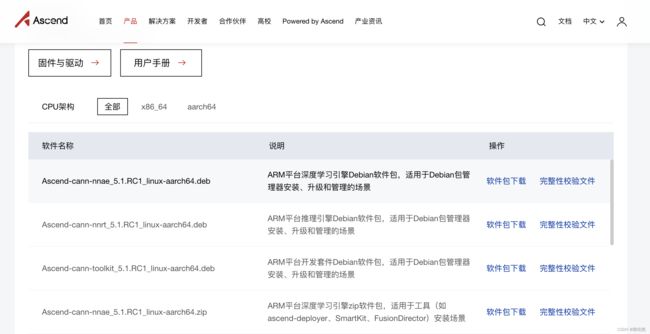
用户根据实际使用需要,下载对应的CANN软件包,具体安装流程可以参考官网的用户手册。
CANN软件包下载地址https://www.hiascend.com/software/cann/commercial
CANN安装流程:https://www.hiascend.com/document/detail/zh/canncomme
rcial/51RC1/envdeployment/instg
2.3 本地Python安装和配置
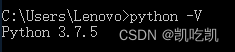
安装Python3.x及以上版本,并检查环境,本图文教程以Python3.7.5为例。
依次安装两个包:
pip3 install pandas #pandas版本号需大于或等于1.2.4
pip3 install libcst #libcst版本号需小于或等于0.3.23
配置完上述环境,使用MindStudio进行脚本迁移的准备工作就已经完成了,下面将具体介绍如何进行脚本转换。
3 选择迁移脚本和创建工程
除使用官网模型支持列表(https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/msug/msug_000109.html)的脚本转换成功后可直接运行外,其他脚本的转换结果仅供参考,仍需用户根据实际情况做少量适配。

其他的一些使用限制:
- MindSpore支持两种运行模式(Graph模式和PyNative模式),由于Graph模式存在Python语法限制,当前仅支持转换到PyNative模式,训练性能较Graph模式有所降低。具体差异详见MindSpore文档(https://www.mindspore.cn/docs/zh-CN/r1.7/index.html)。
- 当前为了规避MindSpore中数据处理不支持创建Tensor的限制,将运行模式设置成了算子同步下发模式,可能存在训练性能的部分降低;用户可通过将context.set_context中的pynative_synchronize=True去除,使用算子异步下发模式提升性能;此时若报错,可检查数据处理部分代码,去除其中的创建Tensor行为,改为使用numpy的ndarry。
本教程选择迁移ResNet脚本进行说明。下载原始工程训练代码(https://github.com/pytorch/examples/tree/master/imagenet),用MindStudio打开。
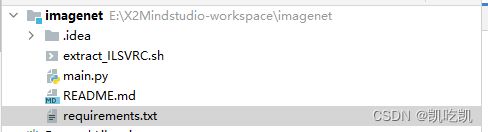
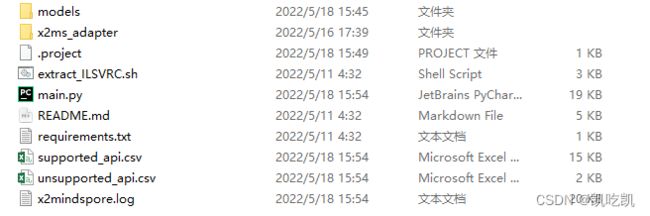
项目结构如下所示,其中main.py就是所需要迁移的训练/测试脚本。
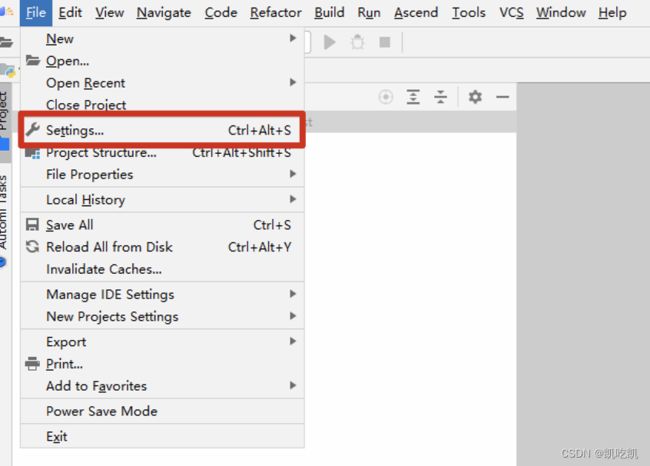
配置CANN环境。首先,点击菜单栏的“File>Settings”按钮,如下图所示:
选择如下图所示的“Appearance & Behavior>System Settings>CANN”选项,点击“Change CANN”按钮。
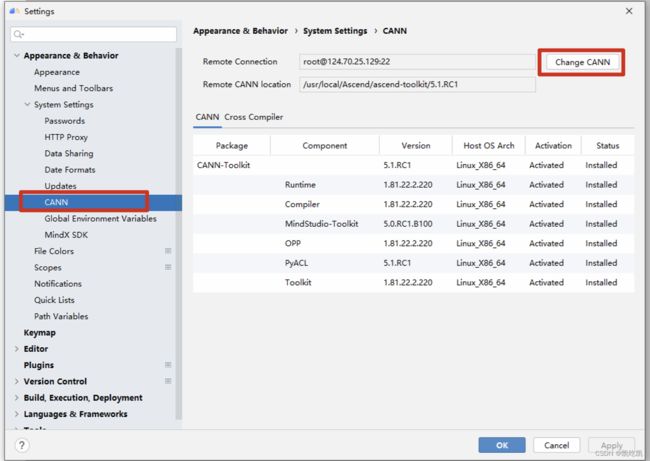
出现如下界面:
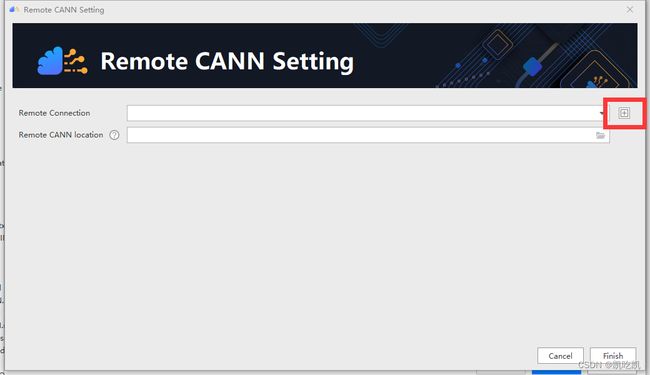
首先配置远程连接,点击红框中“+”号按钮,出现如下界面:
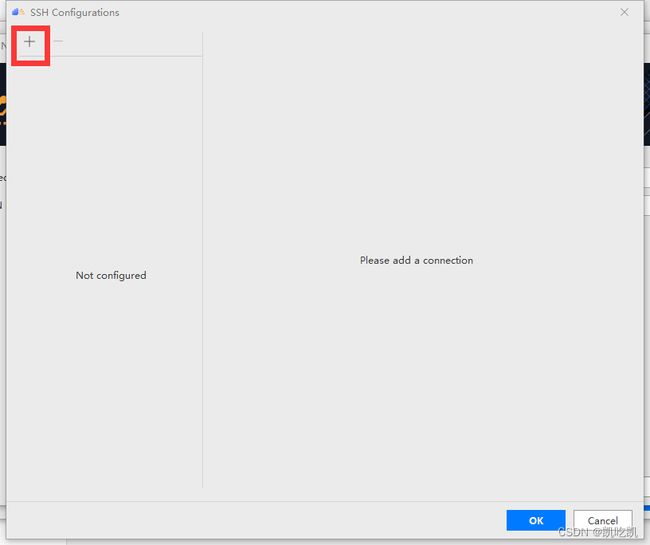
点击上面界面红框中的“+”号按钮,出现以下界面:
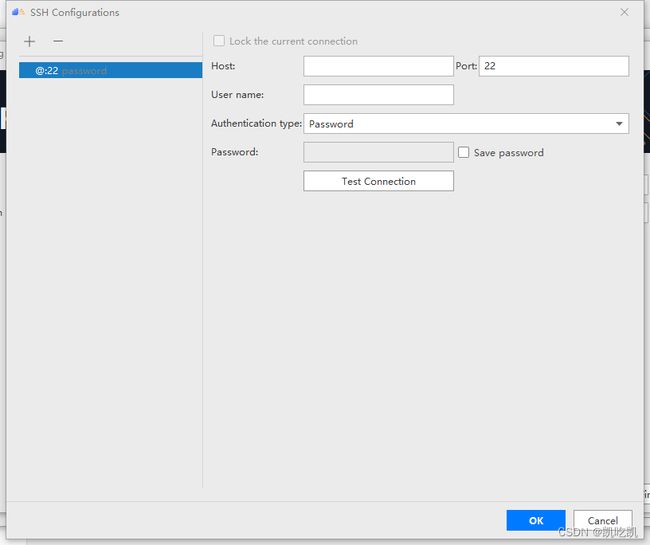
下面,是一些参数说明:
| 参数 |
说明 |
| Host |
远程服务器IP地址 |
| Port |
远程服务器端口号 |
| Username |
用户名 |
| Authentication type |
验证类型 |
| Password |
密码 |
完成填写好,如下所示:
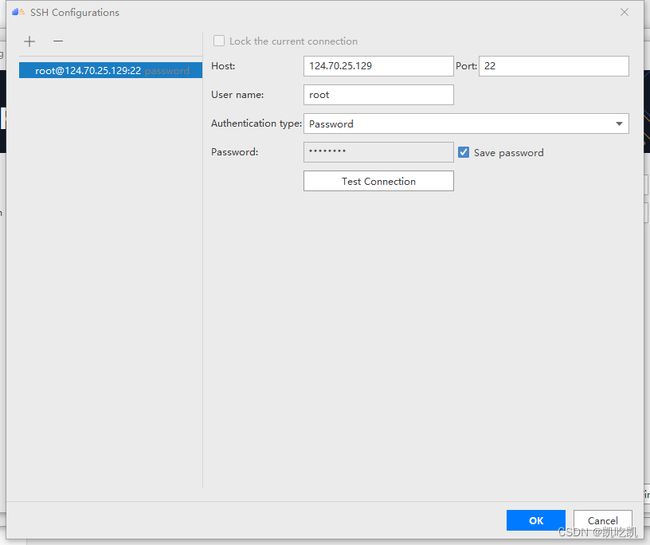
点击“Test Connection”按钮,测试连通性,如果出现如下界面,点击“OK”按钮。

最后显示下图,表示远程连接可用:

一路点击“OK”按钮,完成远程连接配置,如下图所示,然后配置CANN开发工具路径,点击红框中的文件夹图标。
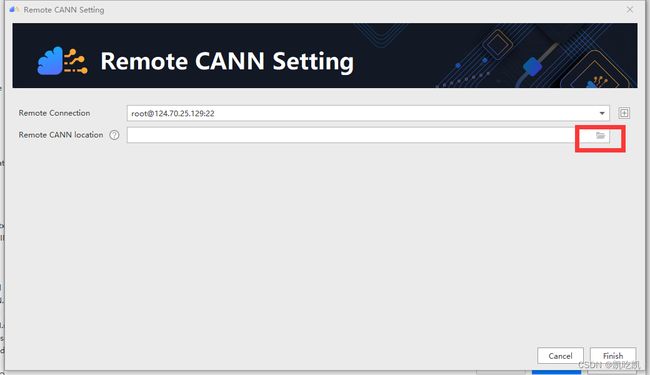
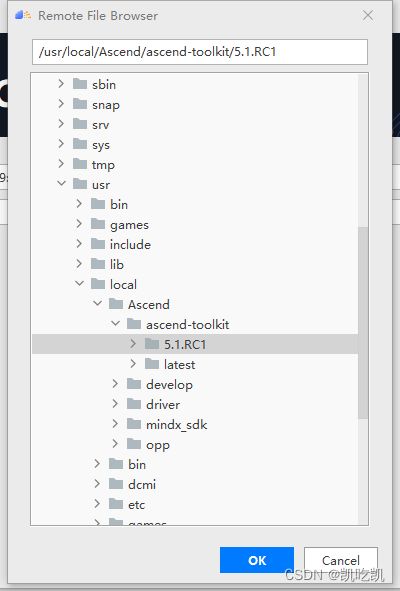
例如:我们这里的路径为“usr/local/Ascend/ascend-toolkit/5.1.RC1”。
最后点“Finish”按钮,等待同步完成,即可完成远程的CANN配置工作。
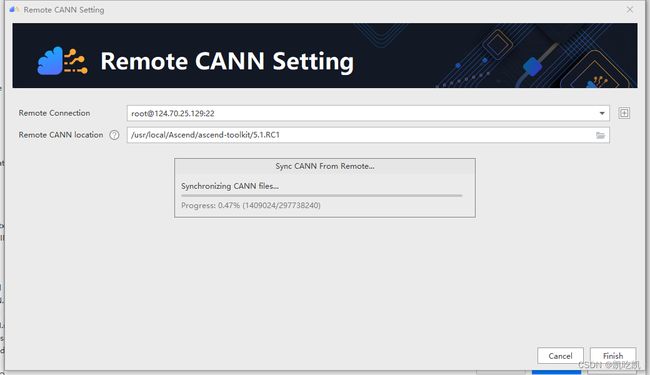
4脚本迁移
根据官网教程,迁移ResNet系列脚本时,需要按照官网备注进行一定修改。同理,如果选择迁移其他支持列表里的脚本,可以查阅官网手册(https://support.huaweicloud.com/usermanual-mindstudio304/atlasms_02_0109.
html),安装官网中的“备注”进行修改。
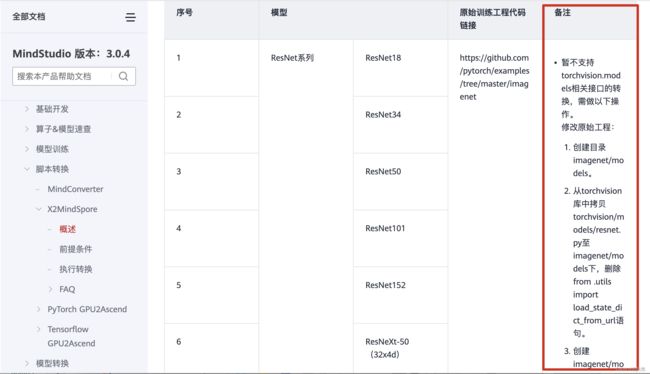
完成对应修改后,在最上面菜单栏中点击“Ascend”按钮,将项目变成Ascend项目。

出现参数设置框,并进行如下配置。

点击“OK”按钮,即可完成项目转换。
下面,介绍如何使用X2MindSpore,有三种方式:
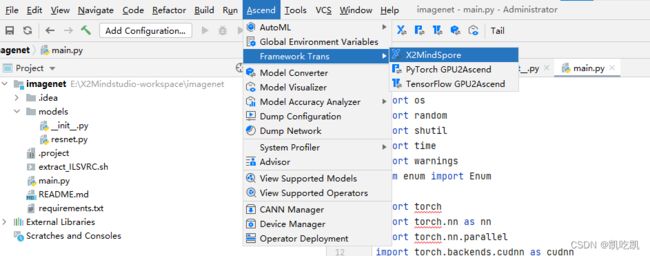
第一种:
在工具栏选择“Ascend > Framework Trans > X2MindSpore”,如下图所示。
第二种:
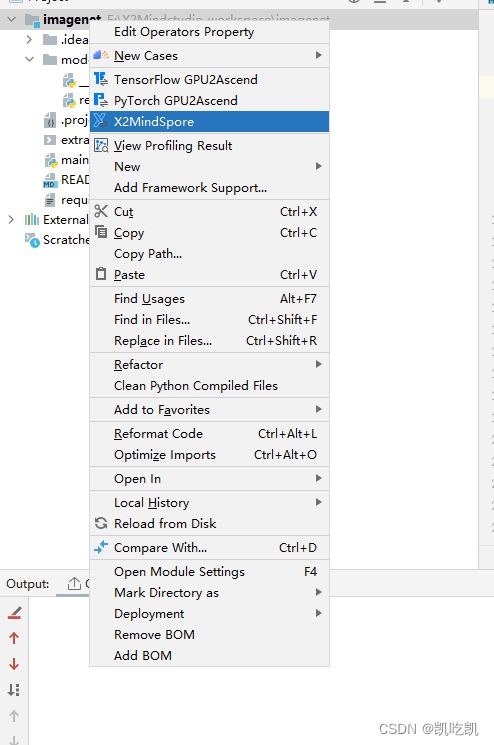
右键单击工程目录中的文件夹,选择“X2MindSpore”,如下图所示:
第三种:
单击工具栏中
![]()
图标,如下所示:

通过三种方式,点击之后,会跳出配置界面,进行相关配置,如下所示。
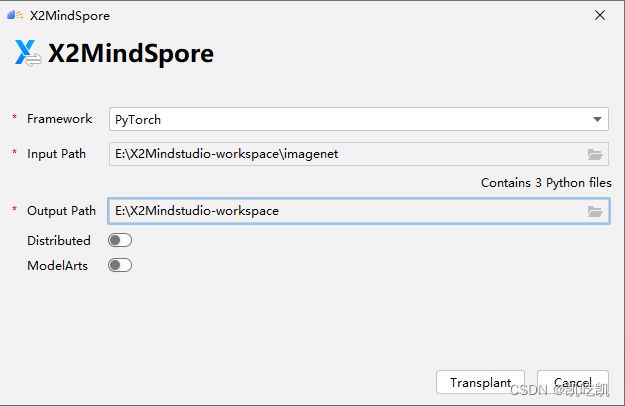
下面,是一些参数说明:
| 参数 |
说明 |
| Framework |
原脚本框架,支持PyTorch和TensorFlow |
| Input Path |
原脚本所在目录 |
| Output Path |
转换结果的保存目录,注意“Output Path”不能在“Input Path”内 |
| Distributed |
可选,多卡运行 |
| ModelArts |
可选,需要配置好映射路径 |
最后,点击“Transplant”按钮,即可开始脚本迁移。显示信息如下,表示成功完成脚本迁移。
![]()
完成后,Output Path输出目录下会生成转换后的xxx_x2ms脚本文件、x2ms_adapter适配层文件、supported_api.csv支持算子列表文件和unsupported_api.csv不支持算子列表文件。目录如下:
├── imagenet_x2ms // 脚本转换结果输出目录。
│ ├── 转换后的脚本文件 // 与转换前的脚本文件目录结构一致
│ ├── x2ms_adapter // 适配层文件
│ ├── unsupported_api.csv // 不支持API列表文件。
│ ├── supported_api.csv // 支持API列表文件。
│ ├── x2mindspore.log // 转换日志,日志文件限制大小为1M,若超过限制将分多个文件进行存储,最多不会超过10个。
点击查看supported_api.csv支持算子列表文件和unsupported_api.csv不支持算子列表文件。
supported_api.csv支持算子列表文件如下所示:
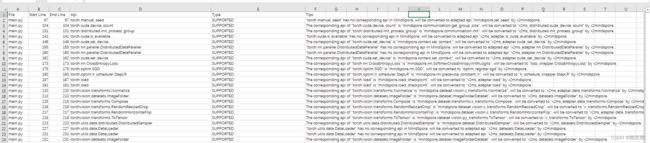
unsupported_api.csv不支持算子列表文件如下所示:

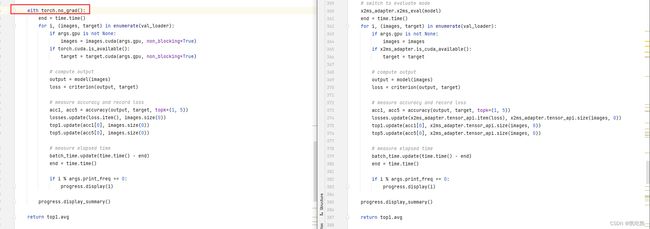
然后,对于不支持的算子,通过查阅MindSpore文档,进行相应替换。下面将以“torch.nn.DataParallel”和“torch.no_grad”为例,介绍如何进行替换。
“torch.nn.DataParallel”算子:
首先,从上图(左边为原始pytorch训练脚本,右边为转换后的脚本)可以对比发现,迁移后,“nn.DataParallel”语句被删除了。然后,我们查看官方教程MindSpore(https://www.mindspore.cn/tutorials/experts/zh-CN/r1.7/parallel/introduction.html),可以知道Mindspore的并行模式需要在context中设置。

所以就在迁移的脚本中加入相应语句,如下图所示,加入红框中的语句。

通过“unsupported_api.csv”不支持算子列表文件可以发现,原始脚本有两处(分别是167、170行)使用了该算子,对于迁移后的脚本对应的两处都要做如上修改,保证转换后脚本与原始脚本保持功能一致。
“torch.no_grad”算子:
通过分析“unsupported_api.csv”不支持算子列表文件和对比原始脚本代码和转换后的脚本代码,可以发现,迁移脚本直接将其进行了删除。为了保证转换后的脚本的功能的一致性。通过论坛咨询、请教华为工程师的方式,了解到在MindSpore中,可以通过set_grad(False)和set_train(False)的方式实现梯度反向传播的控制,如下图所示:
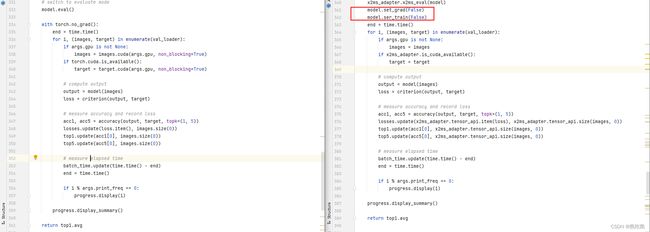
同样,对于两处都作如上修改。如果遇到其他算子不支持的情况,有以下几种方式可以帮助到你,了解MindSpore中的对应算子解决方案:
- MindSpore官方文档https://www.mindspore.cn/docs/zh-CN/r1.7/index.html
- 昇腾社区中的昇腾论坛:https://www.huaweicloud.com/s/JU1pbmRTdHVkaW_mkK3lu7ol/t_60_p_1
- Gitee上的MindSpore项目的issue:https://gitee.com/mindspore/mindspore?_from=gitee_search
- 官方的MindSpore技术交流群等。
我们的脚本参数设置如下所示,下图中的红框中表示我们所设置的数据集路径、模型类型(resnet18)、batch_size为32,当然,其他的可以根据具体需求进行修改。

点击下图绿色箭头,开始运行脚本:

出现报错,如下所示:
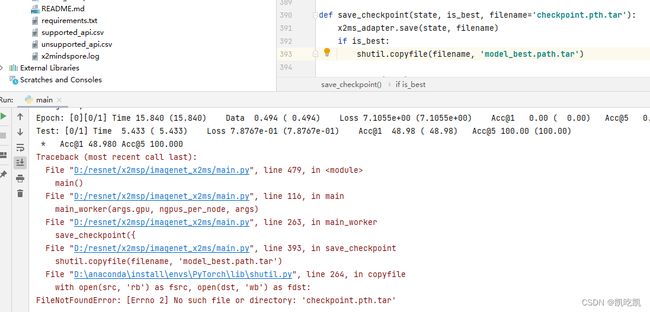
查阅发现,MindSpore中load_checkpoint和save_checkpoint接口仅支“.ckpt”后缀的文件,当文件名为非“.ckpt”后缀时,会自动加上“.ckpt”的后缀,所以将权重文件名改为“.ckpt”结尾,如下所示:

再次运行脚本,显示可以进行正常训练和推理评估,模型也被对应保存,如下所示:

其中,checkpoint.ckpt保存的是最近一代的训练权重,model_best.ckpt保存的是指标性能表现最好的模型权重。
5可能会遇到的问题
问题1:
执行转换后的脚本时提示以下pillow和numpy版本不符合信息。
pillow版本不符合提示信息:
numpy版本不符合提示信息:
解决方法:旧版本的pillow和numpy存在安全漏洞,漏洞详情请参见https://mindspore.cn/security和https://nvd.nist.gov/vuln/detail/CVE-2021-41496。用户需升级pillow版本至8.2.0或以上,numpy升级至1.22.0或以上。
问题2:
保存Checkpoint文件后,对该文件进行操作时,显示该文件不存在。
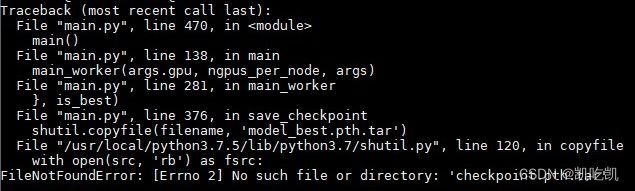
解决方案:MindSpore中load_checkpoint和save_checkpoint接口仅支“.ckpt”后缀的文件,当文件名为非“.ckpt”后缀时,会自动加上“.ckpt”的后缀,因此实际保存的文件名可能和传入的文件名不一致,此时需要用户将传入文件名末尾加上“.ckpt”。
问题3:
数据处理时出现如下错误。

解决方法:在MindSpore中,数据处理过程中需要保持中间处理结果为numpy array,且数据处理过程中不建议与MindSpore网络计算的算子混合使用。请检查数据处理中是否包含转换为Tensor和使用MindSpore网络算子的操作,若有,请使用numpy中的等效操作替换。
如果遇到其他问题,也可以在昇腾社区中的昇腾论坛(https://www.huaweicloud.com/s/JU1pbmRTdHVkaW_mkK3lu7ol/t_60_p_1)里进行查询或者提问,会有华为内部技术人员对其进行解答,帮助你更好使用MindStudio。