【Linux】进程地址空间
目录
- 一、什么是进程地址空间
-
- 1.进程地址空间回顾
- 2.了解进程地址空间
- 二、如何管理进程地址空间
-
- 1.进程地址空间区域划分
- 2.进程地址空间如何管理
- 三、为什么要存在进程地址空间
一、什么是进程地址空间
1.进程地址空间回顾
本文默认针对32位CPU计算机系统进行阐述
地址空间描述的基本空间大小是字节,而在32位下,CPU去内存中寻址,最多能形成2^32个地址
2^32个字节也就是4GB的大小
我们在之前学习C语言时,学习指针、压栈等知识的时候,肯定画过下面这样的图️
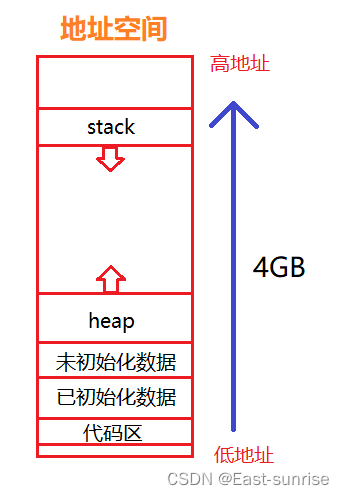
图中这块地址是分布在哪呢?我们在前面已经学习过操作系统、进程方面的知识,那难道图中的这块地址是在内存中吗?
答案:不是!图中这块是叫做虚拟地址空间!
那什么是虚拟地址空间?让我们来慢慢了解
来段代码感受一下
我们定义一个全局变量然后让父子进程分别去打印其值,并将其地址也打印出来
#include 
我们发现,输出出来的变量值和地址是一模一样的,很好理解呀,因为子进程按照父进程为模版,父子并没有对变量进行进行任何修改。可是将代码稍加改动:
#include 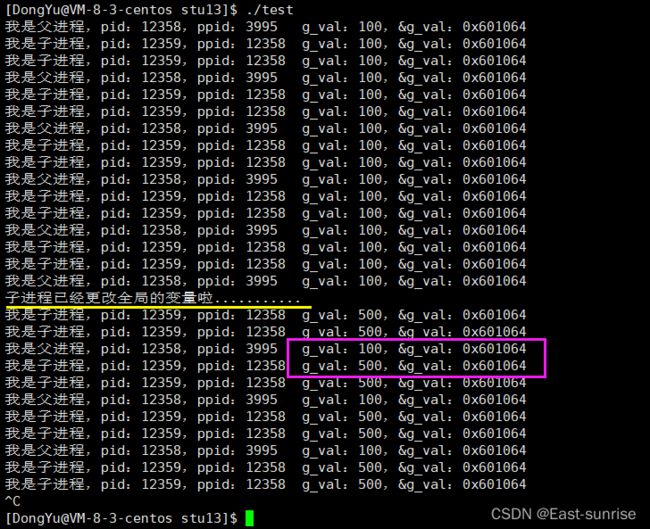
我们发现,父子进程,输出地址是一致的,但是变量内容不一样!能得出如下结论:
- 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量
- 但地址值是一样的,说明,该地址绝对不是物理地址!
真正的物理地址用户是看不到的,交给操作系统统一管理,那这地址是什么? -----> 虚拟地址
虚拟地址又是什么鬼?我们来慢慢了解
2.了解进程地址空间
我们通过一个小故事来切入对进程地址空间的学习️
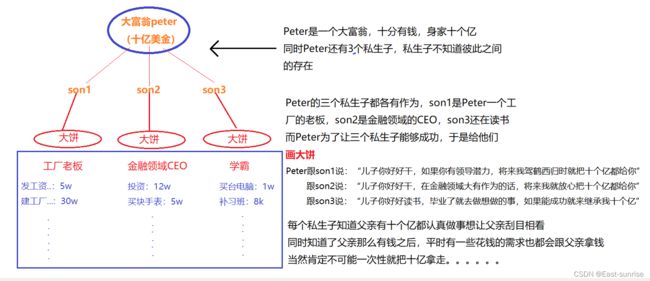
以上的故事对于操作系统对进程的管理其实十分形象,通过以上的故事我们对应来学习一些概念
- 每个进程都以为自己是独占系统资源的(实际上不是)---- 就像几个私生子都不知道彼此的存在,都以为自己能够独占父亲的十个亿
- 在系统中,操作系统就相当于Peter,几个私生子就相当于每个进程,而Peter给私生子们画的大饼,实际上就是操作系统给进程分配的进程地址空间
- 每个son对应的身份、做的事情、向Peter提出的花钱需求就等同于每个进程对应的对象空间(运行着不同的代码…)
- Peter给每个私生子画的大饼都有着不同的说辞,同样操作系统给每个进程分配的进程地址空间也不都相同
画的大饼也就是我们今天学习的重点 — 进程地址空间
那如何画大饼?

画大饼,就是给你描绘一个美好的未来,给你描绘一幅蓝图,比如上面的故事中,Peter在画的大饼里应该包含着:饼是给谁的?什么时候给?什么条件下能给?给多少钱…所以把这些属性汇总起来就像是给每个私生子描绘的一副蓝图。而这副蓝图这块大饼对应到计算机数据结构对象,就是一个结构体。
在画饼的同时也需要管理,Peter给3个私生子画饼,画饼完也还是需要教育管理自己的私生子把?同时Peter也得对他自己画的饼进行管理吧?比如要记住哪个大饼对应的是哪个私生子,画的大饼是否需要随着私生子的成长而进行相对应的改变?
相对应的就是操作系统给每个进程提供的地址空间,每个进程地址空间里面的具体属性不相同,并且地址空间的属性能够动态改变。而操作系统对这些地址空间(大饼)也需要进行管理,那么就需要用到我们操作系统的管理理念:先描述,再组织对管理对象先进行描述,所以在Linux中地址空间的本质是一个结构体,名叫:
mm_struct
Linux中 mm_struct 源码如下: 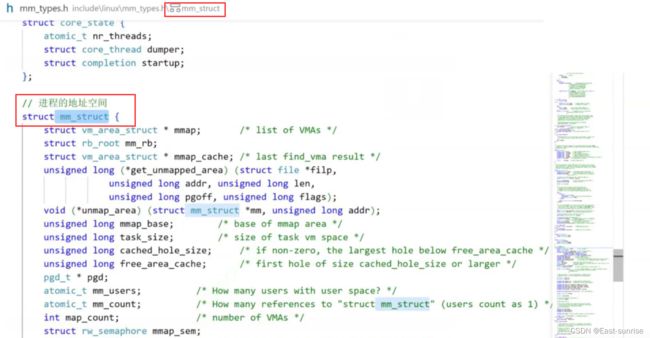
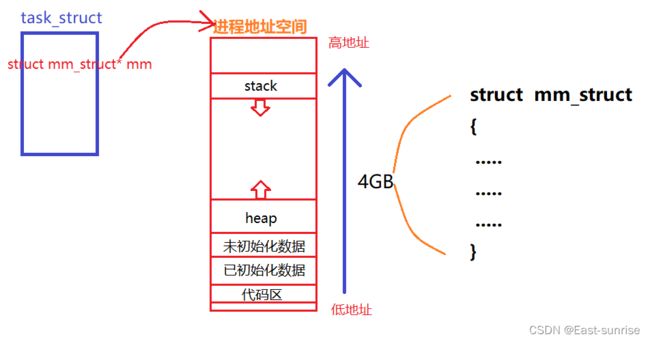
如图是我们对进程地址空间的一张简图,每个进程都拥有一个属于自己的mm_struct
每个进程都认为自己会独占系统资源,所以每个进程的PCB中都会有一个指针,指向其对应的进程地址空间
二、如何管理进程地址空间
1.进程地址空间区域划分
通过以上的了解,我们知道进程地址空间其实就是一个结构体
而进程地址空间在使用的过程中是动态变化的,那我们应该如何对其进行区域划分和区域调整呢?
在32位机器下,一共有2^32个地址(单位:字节)(也就是4GB空间范围)地址最重要的一点便是保持唯一性。
而在进程地址空间中,这些地址都称之为虚拟地址,为了表示这些地址,实际上只需要一个32位的数据即可
通过以上的了解,我们知道进程地址空间中会被划分为不同的区域,所以区域划分的本质就是对4GB的地址范围进行划分,每个区域都给其一个起始地址和结束地址,在这两个地址中间的范围即是这个区域的范围;并且可以根据需求动态改变区域的起始、结束地址来进行区域调整
因此,在mm_struct声明的时候,结构体中会定义许多无符号整型变量,用于代表每个区域的起始地址、结束地址。当创建进程后要实例化其对应的进程地址空间对象时,便根据需求给每个区域的地址赋值
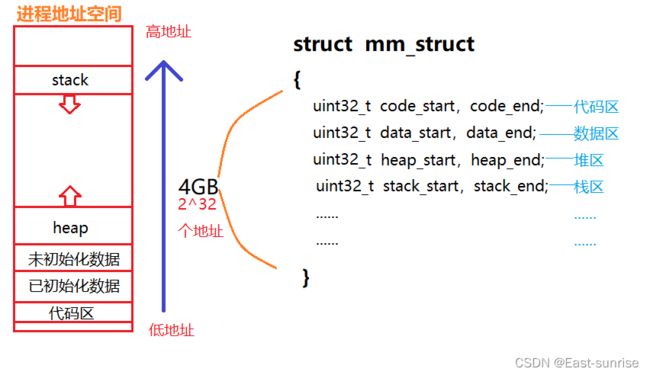

当我们定义局部变量,malloc new堆空间 ----> 扩大堆区或栈区
函数调用完毕,free ----> 缩小栈区或者是堆区
所谓的区域调整,本质就是修改各个区域的end or start
2.进程地址空间如何管理
了解了进程地址空间,但是还是会有疑问❓
你说进程地址空间是虚拟空间,也就是说不是真实存在的?但是我的代码我的数据又是真真正正存在的,加载在内存中的,那我这些代码数据的物理地址在哪?一开始所展示的地址相同值不相同又是怎么一回事?
继续我们对进程地址空间的学习
要了解进程地址空间是如何管理的,我们必须知道一个叫做“页表”的东西,但是页表的原理十分复杂,已经属于超纲了,但是我们要弄清楚进程地址空间如何管理,是绕不开页表的;所以我们今天对其停留在感性地简单地认识,不对页表进行深入研究
在系统内存中,我们的代码、数据加载到内存后,存储的地址叫做物理地址;而进程地址空间又被称为虚拟地址,于是乎就出现了“页表”其作用是将虚拟地址和物理地址联系起来
页表,可以简单地理解为就像我们书籍的目录,目录有书中各个部分的主要内容以及其对应的页码,我们可以通过目录找到我们想要的那部分内容的页码
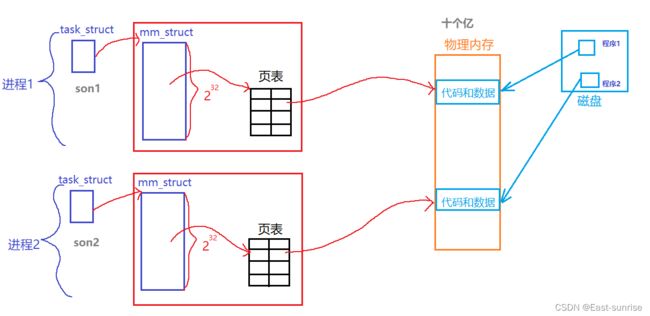
当程序加载到内存中(物理内存),其程序创建的进程便会拥有一个进程地址空间(虚拟内存),并且每个进程的进程地址空间都是完整的32GB,但是一般情况下每次只会占用一小部分(就像上面的故事中:每个私生子都以为自己以后能独占十个亿,但是在日常生活中只会花一小部分)
程序中的代码数据在进程地址空间中使用的是虚拟地址,而当CPU去运行进程时,便通过页表映射找到物理内存中真实存在的代码数据,但是我们平时打印一个变量、使用变量的地址…都是使用虚拟地址。
在系统底层中,对于每个进程的地址占用管理、页表映射寻址…都是由操作系统进行管理的
三、为什么要存在进程地址空间
学习到这的兄弟可能会一直有疑问,代码数据加载到内存中就直接使用物理内存不就好了,为什么总得多此一举还创建个什么进程地址空间❓
举个例子
就像小时候过年拿了压岁钱,妈妈是不是总是说:儿子你把压岁钱放我这,我帮你保管!以后你要买东西就来找我拿(画大饼)
于是儿子就把几千几百都放妈妈那里,以后想买棒棒糖想买玩具,就去找妈妈拿(就像上面故事中:私生子在日常生活中有各种花钱需求)
有一天,儿子去到小卖部,老板看他好像很有钱的样子,便一直给他洗脑,想让他买一个很昂贵的玩具,当儿子去找妈妈要钱时,妈妈发现这个玩具并不值那么多钱,于是乎拒绝了儿子的请求并教育他(就像上面故事中:假如哪个私生子一下子就想要拿几千万去投资,大富翁Peter肯定不会轻易答应)通过以上的例子,假如母亲没有帮儿子保管压岁钱,可能儿子会一整天去吃辣条等垃圾食品,不利于身体健康;或者由于年纪小轻易就相信别人,可能压岁钱都被人给骗走了…
我们在之前对操作系统的学习中了解到,操作系统不会相信任何人。所以操作系统要创建进程地址空间也是为了安全起见。
假如不通过操作系统管理的页表进行映射寻址再运行,而是直接对物理内存进行访问运行的话,当代码中有bug可能会直接导致系统崩溃,假如代码中有越界访问,可能会影响到其他人的数据(导致数据泄露等危害)…所以系统创建进程地址空间,在运行进程时是先通过虚拟地址再经过页表进行映射寻址,这便保证了系统的安全。假如有一些非法请求,在通过页表映射时操作系统便会直接拦截你的操作;假如有一些bug,比如我们日常中写代码会出现的野指针、越界访问…也不会导致系统直接奔溃,因为我们使用的都是虚拟地址,真正执行操作是需要经过操作系统的,所以能够保证系统的安全
接下来我们来解释开头的那个问题
通过之前对进程的学习,我们知道进程具有独立性: 多进程运行,需要独享各种资源,多进程运行期间互不干扰
虽然创建子进程,是以父进程为模板进行拷贝的(包括进程地址空间)但是地址空间能够保证进程的独立性
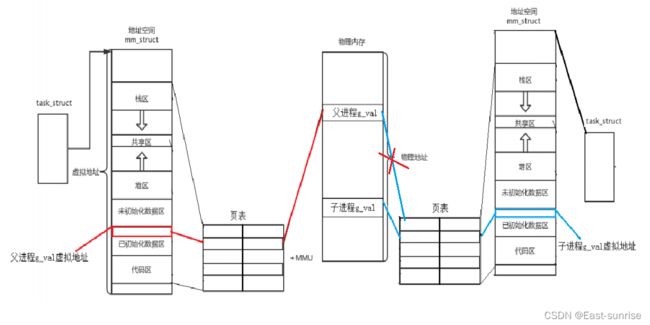
子进程是以父进程为模板进行拷贝的,所以一开始子进程和父进程中,g_val的虚拟地址都是一样的,由于g_val是全局变量,所以一开始父子进程的g_val的虚拟地址通过页表映射到物理内存中指向的地址也是相同的。但是一旦有一方尝试对此共同的全局变量进行写入时,操作系统会先进行数据拷贝,更改页表的映射,再让进程进行写入;这样的操作叫做“写时拷贝“,是操作系统自动做的,为了让不同的进程的数据进行分离,保证进程的独立性。
因此,这便能够很好的对开头的情况进行解释:由于子进程是以父进程为模板拷贝创建的,所以当我们打印出g_val的地址时,有即是取其虚拟地址,父子进程中g_val的虚拟地址都是相同的,当子进程改变g_val的值后,由于”写时拷贝“所以其值也便改变了,但是地址变得是物理地址,虚拟地址并没有改变。
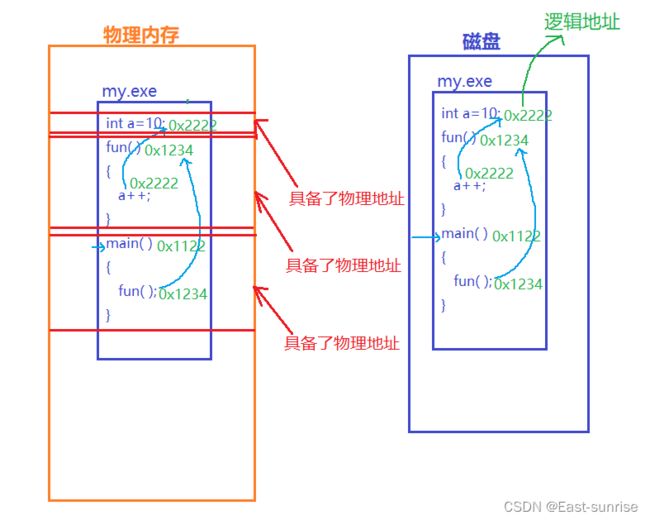
在对进程地址空间最后一个作用进行解释时,有一个问题:磁盘中我们编写的可执行程序的代码有没有存在地址❓
有✔️
我们的代码中有各种函数,在函数进行跳转调用时,如果没有地址,怎么知道要跳转到哪里?又好比我们的代码中会调用许多C标准库的函数,而在程序变为可执行程序时有一个步骤叫做链接链接就是把我们需要用的库函数的地址填入到我们的程序中,当程序运行时才能找到库函数。
⭕在系统中,不只是操作系统会遵守进程地址空间对应的规则,编译器也要遵守!
当编译器在编译我们的代码在磁盘中形成可执行程序时,便会按照虚拟地址空间的方式对我们的代码和数据进行编址,这里的地址称为”逻辑地址“
而当可执行程序加载到内存时,可执行程序的逻辑地址也会原封不动地保留加载进内存(编译器也是遵循着进程地址空间对应的规则进行编址的)
程序加载进内存后,程序的代码、数据便在物理内存中有了自己的位置 —> 具备了物理地址
⭕所以此时我们有了两套地址!
- 标识物理内存中代码和数据的物理地址
- 在程序内部中互相跳转时的虚拟地址(逻辑地址)
重点:
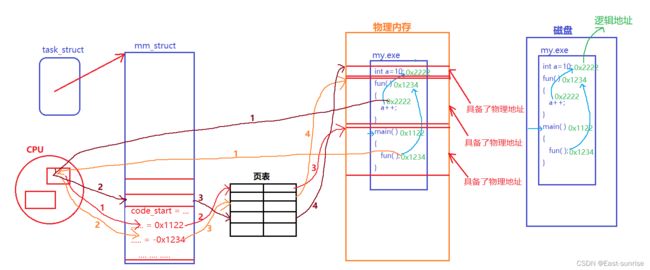
⭕与此同时,操作系统会为程序对应的进程构建进程地址空间,并让进程中的指针指向其对应的进程地址空间。
当CPU要运行这段进程时,操作系统会把地址空间代码区的code_start送入CPU,CPU进入代码区后从main函数作为入口开始执行程序
而因为编译器在编译程序代码内部的逻辑地址时,同样也是遵循进程地址空间的规则来编址的,所以当为进程构建地址空间时,其地址空间中的各个虚拟地址是直接使用编译器在编译可执行程序时生成的逻辑地址。
所以当CPU要开始执行程序时,是拿到了main函数的虚拟地址,再通过页表映射到物理内存中的物理地址,找到main函数加载到内存中的代码数据并运行,而在main函数运行的过程中进行了fun函数的调用,这时CPU读取到的依旧是fun函数的虚拟地址(可执行程序中的逻辑地址),然后再次通过页表映射到物理内存中的物理地址…
⭕CPU在运行时,读取的都是指令,指令中便包含了地址,而自始至终,CPU读取的都是虚拟地址,没有见过物理地址
综上所述,地址空间存在的意义如下:
- 避免进程直接访问内存,保证了系统的安全
- 有利于进程和进程之间的数据代码的解耦,保证了进程的独立性
- 给程序的编址定了一个模板,方便系统和编译器都以统一的的视角来处理代码(规则是一样的,编译器编译完可以直接用)