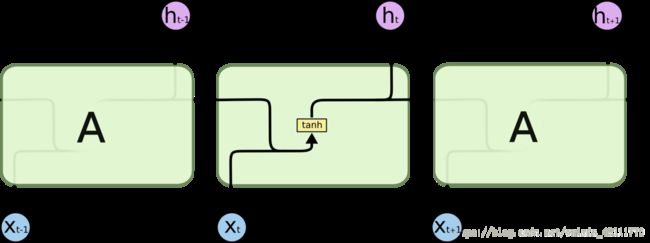
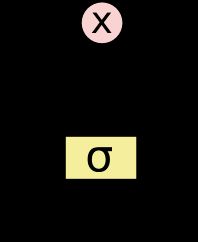
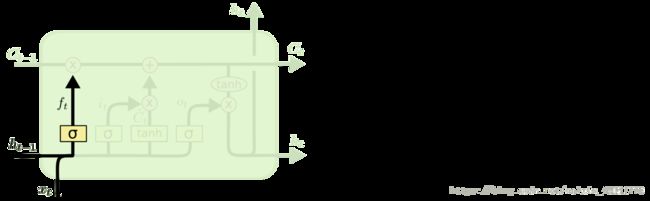
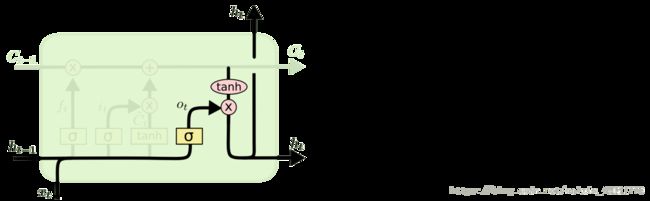
- ReBEL模型的本地部署与运行,用于三元组抽取任务(事件抽取、知识抽取)
1.服务器CUDA11.72.依赖condacreate-nrebel_envpython=3.10-ycondaactivaterebel_env#安装PyTorch(建议与CUDA11.7配合)pipinstalltorchtorchvisiontorchaudio--index-urlhttps://download.pytorch.org/whl/cu117#安装Transformers和
- pytorch官方文档60分钟入门笔记
xiaodidadada
机器学习
文章目录1.张量(Tensors)定义张量张量操作2.自动求导(autograd)变量Variable3.神经网络4.训练一个分类器载入数据5.数据并行day63参考:官方文档https://blog.csdn.net/u014630987/article/details/786690511.张量(Tensors)tensors和numpy的ndarray类似,但是tensors可以使用GPU加快
- 边缘人工智能与医疗AI融合发展路径:技术融合与应用前景(下)
Allen_Lyb
数智化医院2025人工智能健康医疗数据库矩阵
医疗边缘AI的市场趋势医疗边缘AI市场正经历着显著的增长,根据市场研究公司的数据,2024年的边缘AI市场价值为125亿美元,估计在2025至2034年之间,由于各部门越来越多地采用边缘装置,CAGR为24.8%。保健、制造业、零售业和汽车业的企业拥有综合边缘计算解决方案[36]。这一增长趋势表明,边缘AI技术正在各行各业得到广泛应用,其中医疗保健是一个重要的应用领域。2023年全球边缘人工智能市
- AI 编程对决:Gemini CLI vs Claude Code,谁是最佳 AI 编码工具?
charieli-fh
人工智能大模型
1.引言:AI编码工具的崛起在软件开发的快节奏世界中,人工智能(AI)工具正迅速从辅助角色转变为不可或缺的伙伴。它们不再仅仅是提供代码补全,而是能够理解复杂上下文、执行多步骤任务,甚至自动化整个工作流的智能代理。这种转变正在重塑开发者的日常工作,提高生产力,并加速创新。在众多涌现的AI编码工具中,Google的GeminiCLI和Anthropic的ClaudeCode脱颖而出,各自代表了AI辅助
- 全平台QQ聊天数据库解密项目常见问题解决方案
管旭韶
全平台QQ聊天数据库解密项目常见问题解决方案qq-win-db-keyQQNT/WindowsQQ聊天数据库解密项目地址:https://gitcode.com/gh_mirrors/qq/qq-win-db-key项目基础介绍本项目是一个开源项目,旨在为用户提供全平台QQ聊天数据库的解密方法。项目主要使用Python、JavaScript和C++等编程语言实现。新手常见问题及解决步骤问题一:如何
- 百度颠覆了自己,飞算JavaAI造福了中国程序员!
飞算JavaAI开发助手
百度
在当今这个科技日新月异的时代,企业纷纷寻求技术突破,以期在激烈的市场竞争中脱颖而出。百度,作为中国互联网行业的领军企业之一,凭借其强大的科技实力和创新能力,在人工智能等多个领域取得了显著成就,并正在逐步颠覆自身的传统形象。百度自成立之初,就将技术创新视为企业的生命线。从最初的搜索引擎技术,到如今的深度学习、自然语言处理、计算机视觉等前沿领域,百度始终走在技术革新的前沿。其自主研发的飞桨深度学习平台
- Java AI 开发智能体:从入门到实践
培风图南以星河揽胜
javajava人工智能开发语言
在人工智能(AI)技术蓬勃发展的今天,智能体作为AI领域的核心概念之一,正逐渐渗透到各个行业与应用场景。而Java凭借其跨平台性、丰富的类库和强大的生态系统,成为开发智能体的热门选择。本文将深入探讨如何使用Java进行AI开发智能体,从基础概念到实践应用,解答常见问题,为你揭开JavaAI开发智能体的神秘面纱。一、Java在AI开发中的优势1.跨平台性Java的“一次编写,到处运行”特性,使得基于
- ollama v0.9.4 详解:联网功能、模型目录自定义及macOS性能优化全面升级
近年来,随着人工智能技术的快速发展,模型管理与调用变得尤为重要。作为一款备受关注的本地AI模型管理工具,Ollama在最新发布的v0.9.4版本中带来了多项重磅改进和全新功能,提升了用户体验和应用场景的灵活性。本文将深入解析Ollamav0.9.4版本的功能亮点、技术改进以及实用操作指南,帮助广大开发者和AI爱好者全面掌握这款工具的最新动态。一、版本概述Ollamav0.9.4版本于2025年7月
- 【深度学习】卷积神经网络(CNN)原理
chaser&upper
深度学习神经网络卷积计算机视觉
【深度学习】卷积神经网络原理1.卷积神经网络的组成2.卷积层2.1卷积运算过程3.padding-零填充3.1ValidandSame卷积3.2奇数维度的过滤器4.stride-步长5.多通道卷积5.1多卷积核(多个Filter)6.卷积总结7.池化层(Pooling)8.全连接层9.总结1.卷积神经网络的组成定义卷积神经网络由一个或多个卷积层、池化层以及全连接层等组成。与其他深度学习结构相比,卷
- 深度学习学习经验——卷积神经网络(CNN)
Linductor
深度学习学习经验深度学习学习cnn
卷积神经网络卷积神经网络(CNN)1.卷积神经网络的基本组成2.卷积操作3.激活函数(ReLU)4.池化操作5.全连接层6.卷积神经网络的完整实现项目示例项目目标1.加载数据2.卷积层:图像的特征探测器2.1第一个卷积层3.激活函数:增加非线性4.池化层:信息压缩器5.多层卷积和池化:逐层提取更高层次的特征6.全连接层:分类器7.模型训练和测试完整的项目示例代码总结卷积神经网络(CNN)卷积神经网
- 用鸿蒙打造真正的跨设备数据库:从零实现分布式存储
网罗开发
HarmonyOS实战源码实战harmonyos数据库分布式
网罗开发(小红书、快手、视频号同名) 大家好,我是展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、HarmonyOS、Java、Python等方向。在移动端开发、鸿蒙开发、物联网、嵌入式、云原生、开源等领域有深厚造诣。图书作者:《ESP32-C3物联网工程开发实战》图书作者:《SwiftUI入门,进阶与实战》超级个体:CO
- Python Day58
别勉.
python机器学习python信息可视化数据分析
Task:1.时序建模的流程2.时序任务经典单变量数据集3.ARIMA(p,d,q)模型实战4.SARIMA摘要图的理解5.处理不平稳的2种差分a.n阶差分—处理趋势b.季节性差分—处理季节性建立一个ARIMA模型,通常遵循以下步骤:数据可视化:观察原始时间序列图,判断是否存在趋势或季节性。平稳性检验:对原始序列进行ADF检验。如果p值>0.05,说明序列非平稳,需要进行差分。确定差分次数d:进行
- Python Day56
别勉.
python机器学习python开发语言
Task:1.假设检验基础知识a.原假设与备择假设b.P值、统计量、显著水平、置信区间2.白噪声a.白噪声的定义b.自相关性检验:ACF检验和Ljung-Box检验c.偏自相关性检验:PACF检验3.平稳性a.平稳性的定义b.单位根检验4.季节性检验a.ACF检验b.序列分解:趋势+季节性+残差记忆口诀:p越小,落在置信区间外,越拒绝原假设。1.假设检验基础知识a.原假设与备择假设原假设(Null
- Python Day57
别勉.
python机器学习python开发语言
Task:1.序列数据的处理:a.处理非平稳性:n阶差分b.处理季节性:季节性差分c.自回归性无需处理2.模型的选择a.AR§自回归模型:当前值受到过去p个值的影响b.MA(q)移动平均模型:当前值收到短期冲击的影响,且冲击影响随时间衰减c.ARMA(p,q)自回归滑动平均模型:同时存在自回归和冲击影响时间序列分析:ARIMA/SARIMA模型构建流程时间序列分析的核心目标是理解序列的过去行为,并
- Python Day44
别勉.
python机器学习python开发语言
Task:1.预训练的概念2.常见的分类预训练模型3.图像预训练模型的发展史4.预训练的策略5.预训练代码实战:resnet181.预训练的概念预训练(Pre-training)是指在大规模数据集上,先训练模型以学习通用的特征表示,然后将其用于特定任务的微调。这种方法可以显著提高模型在目标任务上的性能,减少训练时间和所需数据量。核心思想:在大规模、通用的数据(如ImageNet)上训练模型,学习丰
- Python Day42
别勉.
python机器学习python开发语言
Task:Grad-CAM与Hook函数1.回调函数2.lambda函数3.hook函数的模块钩子和张量钩子4.Grad-CAM的示例1.回调函数定义:回调函数是作为参数传入到其他函数中的函数,在特定事件发生时被调用。特点:便于扩展和自定义程序行为。常用于训练过程中的监控、日志记录、模型保存等场景。示例:defcallback_function():print("Epochcompleted!")
- Python-什么是集合
難釋懷
python开发语言数据库
一、前言在Python中,除了我们常用的列表(list)、元组(tuple)和字典(dict),还有一种非常实用的数据结构——集合(set)。集合是一种无序且不重复的元素集合,常用于去重、交并差运算等场景。本文将带你全面了解Python中集合的基本用法、操作方法及其适用场景,并通过大量代码示例帮助你掌握这一重要数据类型。二、什么是集合(set)?✅定义:集合是Python中的一种可变数据类型,它存
- Python Day53
别勉.
python机器学习python开发语言
Task:1.对抗生成网络的思想:关注损失从何而来2.生成器、判别器3.nn.sequential容器:适合于按顺序运算的情况,简化前向传播写法4.leakyReLU介绍:避免relu的神经元失活现象1.对抗生成网络的思想:关注损失从何而来这是理解GANs的关键!传统的神经网络训练中,我们通常会直接定义一个损失函数(如均方误差MSE、交叉熵CE),然后通过反向传播来优化这个损失。这个损失的“来源”
- 〖Python零基础入门篇⑮〗- Python中的字典
哈哥撩编程
#①-零基础入门篇Python全栈白宝书python开发语言后端python中的字典
>【易编橙·终身成长社群,相遇已是上上签!】-点击跳转~<作者:哈哥撩编程(视频号同名)图书作者:程序员职场效能宝典博客专家:全国博客之星第四名超级个体:COC上海社区主理人特约讲师:谷歌亚马逊分享嘉宾科技博主:极星会首批签约作者文章目录⭐️什么是字典?⭐️字典的结构与创建方法⭐️字典支持的数据类型⭐️在列表与元组中如何定义字典
- python换行输出字典_Python基础入门:字符串和字典
weixin_39959236
python换行输出字典
10、字符串常用转义字符转义字符描述\\反斜杠符号\'单引号\"双引号\n换行\t横向制表符(TAB)\r回车三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符para_str="""这是一个多行字符串的实例多行字符串可以使用制表符TAB(\t)。也可以使用换行符[\n]。"""print(para_str)#这是一个多行字符串的实例#多行字符串可以使用制表符#TAB()。
- Python----Python中的集合及其常用方法
redrose2100
Pythonpython开发语言后端
【原文链接】1集合的定义和特点(1)集合是用花括号括起来的,集合的特点是元素没有顺序,元素具有唯一性,不能重复>>>a={1,2,3,4}>>>type(a)>>>a={1,2,3,1,2,3}>>>a{1,2,3}2集合的常用运算(1)集合元素没有顺序,所以不能像列表和元组那样用下标取值>>>a={1,2,3}>>>a[0]Traceback(mostrecentcalllast):File""
- langchain+langserver+langfuse整合streamlit构建基础智能体中心
Messi^
人工智能-大模型应用langchain人工智能
ServerApi******#!/usr/bin/python--coding:UTF-8--importuvicornfromfastapiimportFastAPIfrombaseimportFaissEnginefromlangserve.serverimportadd_routesfromlangchain_core.promptsimportPromptTemplatefromlang
- pycharm两种运行py之路径问题
hellopbc
software#pycharmpythonpycahrmpath
文章目录pycharm两种运行py之路径问题pycharm两种运行py之路径问题运行python代码在pycharm中有两种方式:一种是直接鼠标点击runxxx运行,还有一种是使用#In[]:点击该行左边的绿色三角形按钮运行有可能在pythonconsole窗口运行有可能在你当前运行文件的窗口(就是run之后产生的那个窗口)**问题:**你会发现,涉及到路径问题时(使用相对路径),可能在这两种运行
- Python元组的遍历
難釋懷
python前端linux
一、前言在Python中,元组(tuple)是一种非常基础且常用的数据结构,它与列表类似,都是有序的序列,但不同的是,元组是不可变的(immutable),一旦创建就不能修改。虽然元组不能被修改,但它支持高效的遍历操作,非常适合用于存储不会变化的数据集合。本文将系统性地介绍Python中元组的多种遍历方式,包括基本遍历、索引访问、元素解包、结合函数等,并结合大量代码示例帮助你掌握这一重要技能。二、
- Python集合生成式
一、前言在Python中,我们已经熟悉了列表生成式(ListComprehension),它为我们提供了一种简洁高效的方式来创建列表。而除了列表之外,Python还支持一种类似的语法结构来创建集合——集合生成式(SetComprehension)。集合生成式不仅可以帮助我们快速构造一个无序且不重复的集合,还能有效提升代码的可读性和执行效率。本文将带你全面了解:✅什么是集合生成式✅集合生成式的语法结
- Python开发从新手到专家:第三章 列表、元组和集合
caifox菜狐狸
Python开发从新手到专家python元素集合列表元组数据结构字典
在Python开发的旅程中,数据结构是每一位开发者必须掌握的核心知识。它们是构建程序的基石,决定了代码的效率、可读性和可维护性。本章将深入探讨Python中的三种基本数据结构:列表、元组和集合。这三种数据结构在实际开发中有着广泛的应用,从简单的数据存储到复杂的算法实现,它们都扮演着不可或缺的角色。无论你是刚刚接触Python的新手,还是希望进一步提升编程技能的开发者,本章都将是你的宝贵指南。我们将
- python入门之字典
二十四桥_
python入门python
文章目录一、字典定义二、字典插入三、字典删除四、字典修改五、字典查找六、字典遍历七、字典拆包一、字典定义#{}键值对各个键值对之间用逗号隔开#1.有数据的字典dict1={'name':'zmz','age':20,'gender':'boy'}print(dict1)#2.创建空字典dict2={}print(dict2)dict3=dict()print(dict3)二、字典插入dict1={
- python类的定义与使用
菜鸟驿站2020
python
class01.py代码如下classTicket():#类的名称首字母大写#在类里定义的变量称为属性,第一个属性必须是selfdef__init__(self,checi,fstation,tstation,fdate,ftime,ttime,notes):self.checi=checiself.fstation=fstationself.tstation=tstationself.fdate
- Python爬虫设置代理IP
菜鸟驿站2020
python
配置代理ipfrombs4importBeautifulSoupimportrequestsimportrandom#从ip代理网站获取ip列表defget_ip_list(url,headers):web_data=requests.get(url,headers=headers)soup=BeautifulSoup(web_data.text,'lxml')ips=soup.find_all(
- Tensorflow 回归模型 FLASK + DOCKER 部署 至 Ubuntu 虚拟机
准备工作:安装虚拟机,安装ubuntu,安装python3.x、pip和对应版本的tensorflow和其他库文件,安装docker。注意事项:1.windows系统运行的模型文件不能直接运行到虚拟机上,需在虚拟机上重新运行并生成模型文件2.虚拟机网络状态改为桥接Flask代码如下:fromflaskimportFlask,request,jsonifyimportpickleimportnump
- Enum 枚举
120153216
enum枚举
原文地址:http://www.cnblogs.com/Kavlez/p/4268601.html Enumeration
于Java 1.5增加的enum type...enum type是由一组固定的常量组成的类型,比如四个季节、扑克花色。在出现enum type之前,通常用一组int常量表示枚举类型。比如这样:
public static final int APPLE_FUJI = 0
- Java8简明教程
bijian1013
javajdk1.8
Java 8已于2014年3月18日正式发布了,新版本带来了诸多改进,包括Lambda表达式、Streams、日期时间API等等。本文就带你领略Java 8的全新特性。
一.允许在接口中有默认方法实现
Java 8 允许我们使用default关键字,为接口声明添
- Oracle表维护 快速备份删除数据
cuisuqiang
oracle索引快速备份删除
我知道oracle表分区,不过那是数据库设计阶段的事情,目前是远水解不了近渴。
当前的数据库表,要求保留一个月数据,且表存在大量录入更新,不存在程序删除。
为了解决频繁查询和更新的瓶颈,我在oracle内根据需要创建了索引。但是随着数据量的增加,一个半月数据就要超千万,此时就算有索引,对高并发的查询和更新来说,让然有所拖累。
为了解决这个问题,我一般一个月会进行一次数据库维护,主要工作就是备
- java多态内存分析
麦田的设计者
java内存分析多态原理接口和抽象类
“ 时针如果可以回头,熟悉那张脸,重温嬉戏这乐园,墙壁的松脱涂鸦已经褪色才明白存在的价值归于记忆。街角小店尚存在吗?这大时代会不会牵挂,过去现在花开怎么会等待。
但有种意外不管痛不痛都有伤害,光阴远远离开,那笑声徘徊与脑海。但这一秒可笑不再可爱,当天心
- Xshell实现Windows上传文件到Linux主机
被触发
windows
经常有这样的需求,我们在Windows下载的软件包,如何上传到远程Linux主机上?还有如何从Linux主机下载软件包到Windows下;之前我的做法现在看来好笨好繁琐,不过也达到了目的,笨人有本方法嘛;
我是怎么操作的:
1、打开一台本地Linux虚拟机,使用mount 挂载Windows的共享文件夹到Linux上,然后拷贝数据到Linux虚拟机里面;(经常第一步都不顺利,无法挂载Windo
- 类的加载ClassLoader
肆无忌惮_
ClassLoader
类加载器ClassLoader是用来将java的类加载到虚拟机中,类加载器负责读取class字节文件到内存中,并将它转为Class的对象(类对象),通过此实例的 newInstance()方法就可以创建出该类的一个对象。
其中重要的方法为findClass(String name)。
如何写一个自己的类加载器呢?
首先写一个便于测试的类Student
- html5写的玫瑰花
知了ing
html5
<html>
<head>
<title>I Love You!</title>
<meta charset="utf-8" />
</head>
<body>
<canvas id="c"></canvas>
- google的ConcurrentLinkedHashmap源代码解析
矮蛋蛋
LRU
原文地址:
http://janeky.iteye.com/blog/1534352
简述
ConcurrentLinkedHashMap 是google团队提供的一个容器。它有什么用呢?其实它本身是对
ConcurrentHashMap的封装,可以用来实现一个基于LRU策略的缓存。详细介绍可以参见
http://code.google.com/p/concurrentlinke
- webservice获取访问服务的ip地址
alleni123
webservice
1. 首先注入javax.xml.ws.WebServiceContext,
@Resource
private WebServiceContext context;
2. 在方法中获取交换请求的对象。
javax.xml.ws.handler.MessageContext mc=context.getMessageContext();
com.sun.net.http
- 菜鸟的java基础提升之道——————>是否值得拥有
百合不是茶
1,c++,java是面向对象编程的语言,将万事万物都看成是对象;java做一件事情关注的是人物,java是c++继承过来的,java没有直接更改地址的权限但是可以通过引用来传值操作地址,java也没有c++中繁琐的操作,java以其优越的可移植型,平台的安全型,高效性赢得了广泛的认同,全世界越来越多的人去学习java,我也是其中的一员
java组成:
- 通过修改Linux服务自动启动指定应用程序
bijian1013
linux
Linux中修改系统服务的命令是chkconfig (check config),命令的详细解释如下: chkconfig
功能说明:检查,设置系统的各种服务。
语 法:chkconfig [ -- add][ -- del][ -- list][系统服务] 或 chkconfig [ -- level <</SPAN>
- spring拦截器的一个简单实例
bijian1013
javaspring拦截器Interceptor
Purview接口
package aop;
public interface Purview {
void checkLogin();
}
Purview接口的实现类PurviesImpl.java
package aop;
public class PurviewImpl implements Purview {
public void check
- [Velocity二]自定义Velocity指令
bit1129
velocity
什么是Velocity指令
在Velocity中,#set,#if, #foreach, #elseif, #parse等,以#开头的称之为指令,Velocity内置的这些指令可以用来做赋值,条件判断,循环控制等脚本语言必备的逻辑控制等语句,Velocity的指令是可扩展的,即用户可以根据实际的需要自定义Velocity指令
自定义指令(Directive)的一般步骤
&nbs
- 【Hive十】Programming Hive学习笔记
bit1129
programming
第二章 Getting Started
1.Hive最大的局限性是什么?一是不支持行级别的增删改(insert, delete, update)二是查询性能非常差(基于Hadoop MapReduce),不适合延迟小的交互式任务三是不支持事务2. Hive MetaStore是干什么的?Hive persists table schemas and other system metadata.
- nginx有选择性进行限制
ronin47
nginx 动静 限制
http {
limit_conn_zone $binary_remote_addr zone=addr:10m;
limit_req_zone $binary_remote_addr zone=one:10m rate=5r/s;...
server {...
location ~.*\.(gif|png|css|js|icon)$ {
- java-4.-在二元树中找出和为某一值的所有路径 .
bylijinnan
java
/*
* 0.use a TwoWayLinkedList to store the path.when the node can't be path,you should/can delete it.
* 1.curSum==exceptedSum:if the lastNode is TreeNode,printPath();delete the node otherwise
- Netty学习笔记
bylijinnan
javanetty
本文是阅读以下两篇文章时:
http://seeallhearall.blogspot.com/2012/05/netty-tutorial-part-1-introduction-to.html
http://seeallhearall.blogspot.com/2012/06/netty-tutorial-part-15-on-channel.html
我的一些笔记
===
- js获取项目路径
cngolon
js
//js获取项目根路径,如: http://localhost:8083/uimcardprj
function getRootPath(){
//获取当前网址,如: http://localhost:8083/uimcardprj/share/meun.jsp
var curWwwPath=window.document.locati
- oracle 的性能优化
cuishikuan
oracleSQL Server
在网上搜索了一些Oracle性能优化的文章,为了更加深层次的巩固[边写边记],也为了可以随时查看,所以发表这篇文章。
1.ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理,表之间的连接必须写在其他WHERE条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。(这点本人曾经做过实例验证过,的确如此哦!
- Shell变量和数组使用详解
daizj
linuxshell变量数组
Shell 变量
定义变量时,变量名不加美元符号($,PHP语言中变量需要),如:
your_name="w3cschool.cc"
注意,变量名和等号之间不能有空格,这可能和你熟悉的所有编程语言都不一样。同时,变量名的命名须遵循如下规则:
首个字符必须为字母(a-z,A-Z)。
中间不能有空格,可以使用下划线(_)。
不能使用标点符号。
不能使用ba
- 编程中的一些概念,KISS、DRY、MVC、OOP、REST
dcj3sjt126com
REST
KISS、DRY、MVC、OOP、REST (1)KISS是指Keep It Simple,Stupid(摘自wikipedia),指设计时要坚持简约原则,避免不必要的复杂化。 (2)DRY是指Don't Repeat Yourself(摘自wikipedia),特指在程序设计以及计算中避免重复代码,因为这样会降低灵活性、简洁性,并且可能导致代码之间的矛盾。 (3)OOP 即Object-Orie
- [Android]设置Activity为全屏显示的两种方法
dcj3sjt126com
Activity
1. 方法1:AndroidManifest.xml 里,Activity的 android:theme 指定为" @android:style/Theme.NoTitleBar.Fullscreen" 示例: <application
- solrcloud 部署方式比较
eksliang
solrCloud
solrcloud 的部署其实有两种方式可选,那么我们在实践开发中应该怎样选择呢? 第一种:当启动solr服务器时,内嵌的启动一个Zookeeper服务器,然后将这些内嵌的Zookeeper服务器组成一个集群。 第二种:将Zookeeper服务器独立的配置一个集群,然后将solr交给Zookeeper进行管理
谈谈第一种:每启动一个solr服务器就内嵌的启动一个Zoo
- Java synchronized关键字详解
gqdy365
synchronized
转载自:http://www.cnblogs.com/mengdd/archive/2013/02/16/2913806.html
多线程的同步机制对资源进行加锁,使得在同一个时间,只有一个线程可以进行操作,同步用以解决多个线程同时访问时可能出现的问题。
同步机制可以使用synchronized关键字实现。
当synchronized关键字修饰一个方法的时候,该方法叫做同步方法。
当s
- js实现登录时记住用户名
hw1287789687
记住我记住密码cookie记住用户名记住账号
在页面中如何获取cookie值呢?
如果是JSP的话,可以通过servlet的对象request 获取cookie,可以
参考:http://hw1287789687.iteye.com/blog/2050040
如果要求登录页面是html呢?html页面中如何获取cookie呢?
直接上代码了
页面:loginInput.html
代码:
<!DOCTYPE html PUB
- 开发者必备的 Chrome 扩展
justjavac
chrome
Firebug:不用多介绍了吧https://chrome.google.com/webstore/detail/bmagokdooijbeehmkpknfglimnifench
ChromeSnifferPlus:Chrome 探测器,可以探测正在使用的开源软件或者 js 类库https://chrome.google.com/webstore/detail/chrome-sniffer-pl
- 算法机试题
李亚飞
java算法机试题
在面试机试时,遇到一个算法题,当时没能写出来,最后是同学帮忙解决的。
这道题大致意思是:输入一个数,比如4,。这时会输出:
&n
- 正确配置Linux系统ulimit值
字符串
ulimit
在Linux下面部 署应用的时候,有时候会遇上Socket/File: Can’t open so many files的问题;这个值也会影响服务器的最大并发数,其实Linux是有文件句柄限制的,而且Linux默认不是很高,一般都是1024,生产服务器用 其实很容易就达到这个数量。下面说的是,如何通过正解配置来改正这个系统默认值。因为这个问题是我配置Nginx+php5时遇到了,所以我将这篇归纳进
- hibernate调用返回游标的存储过程
Supanccy2013
javaDAOoracleHibernatejdbc
注:原创作品,转载请注明出处。
上篇博文介绍的是hibernate调用返回单值的存储过程,本片博文说的是hibernate调用返回游标的存储过程。
此此扁博文的存储过程的功能相当于是jdbc调用select 的作用。
1,创建oracle中的包,并在该包中创建的游标类型。
---创建oracle的程
- Spring 4.2新特性-更简单的Application Event
wiselyman
application
1.1 Application Event
Spring 4.1的写法请参考10点睛Spring4.1-Application Event
请对比10点睛Spring4.1-Application Event
使用一个@EventListener取代了实现ApplicationListener接口,使耦合度降低;
1.2 示例
包依赖
<p