【大数据】Hadoop—— 三大核心组件理论入门 | 完全分布式集群搭建 | 入门项目实战
文章目录
- 前言
- 大数据概述
-
- 时代背景
- 4V特点
- 大数据思维
- 核心技术
-
- 储存
- 计算
- 相关技术
-
- 云计算
- 物联网
- Hadoop简介
-
- 简介
- 版本之分
- 项目生态结构
- 安装和部署
- HDFS
-
- 简介
-
- 集群结构
- 实现目标(优点)与缺陷
- 基本概念
-
- 块
- 名称节点(Name Node)
-
- FsImage
- 文件块分布信息
- EditLog
- 第二名称节点(Secondary Name Node)
- 数据节点(Data Node)
- HDFS体系结构
-
- 运行过程
- 命名空间
- 通信协议
- 局限性
- 储存原理
-
- 冗余数据策略
- 数据存取策略
- 数据错误与恢复策略
- 数据读写
-
- 读取
- 写入
- HBase
-
- 简介
- 数据模型
- 实现原理
-
- HBase功能组件
- 表和Region
- Region三级定位
- 运行机制
-
- HBase系统架构
- Region服务器工作原理
- 数据读写与Store原理
- HLog工作原理
- 应用方案
- NoSQL(Not Only SQL)和云数据库概览
- MapReduce
-
- 概览
-
- 分布式并行计算框架
- 分布式思想
- 硬件架构
- Map/Reduce函数
- 体系结构
-
- Client
- JobTracker/Task Scheduler
- TaskTracker
- 工作流程
-
- 分片
- map任务
- shuffle过程
-
- map端shuffle
- reduce端shuffle
- reduce任务
- 整体流程
- 实例分析
-
- 词频分析(world count)
- 实现自然连接
- Hadoop再探讨
-
- 概览
-
- Hadoop 1.0 缺陷
- Hadoop 2.0改进
- 生态概览
-
- Spark基于内存的计算框架
- Flume日志采集
- Hive数据仓库
- Sqoop数据迁移
- YARN资源调度框架
- Kafka消息队列
- Flink数据处理
- Storm实时计算
- 实战部分
-
- 完全分布式集群配置(虚拟机)
-
- 概述:为什么要用完全分布式
- 虚拟机创建与系统安装
- 虚拟网络环境搭建
- JDK和Hadoop安装 | 环境变量
- 文件批量分发脚本
- 集群配置
- 集群启动与关闭
- 故障修复
- 使用hadoop自带jar包——wordcount
- 自己本地搭建java项目后放到hadoop集群上运行
-
- 基本流程
- windows搭建简易hadoop环境
- Maven项目的配置
- MapReduce项目的编写机制
- 具体案例——倒排索引
-
- Mapper
- Combiner
- Reducer
- Driver
- 具体案例——1.4GB级别txt的倒排索引
-
- 题目描述与基本情况
- 解题思路
- 集群部署与虚拟内存调优
- 只有在分布式环境下才会有的Bug
- 最终代码
前言
学校大三小学期的第二阶段:大数据系统开发到了。
不过这一个礼拜感觉很轻松,再好不过了,可惜的是老师因为录音设备的问题,在线上课的效果非常差,所以我找了一个很不错的慕课听。有趣的是,这个慕课和老师讲的基本重合,甚至老师要讲什么我都能猜出来,我都有点怀疑老师是不是借鉴了视频的讲法。
废话不多说,先上课程:
厦门大学《大数据技术原理与应用》——林子雨老师
本文是这门课程前半部分的总结与理解,综合了老师ppt的内容,足以应对考试与大作业。
大数据概述
时代背景
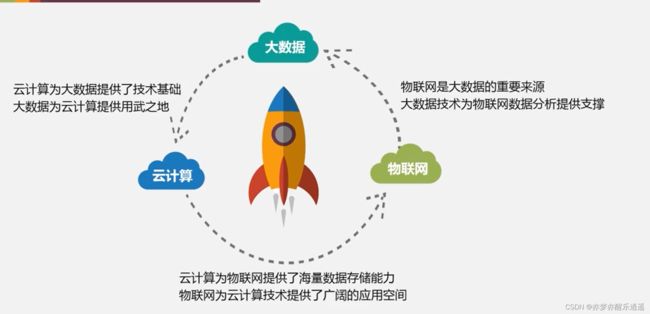
现在是第三次信息浪潮,由以下三种技术组成:
- 大数据。大数据提供了对海量数据的储存和运算支持
- 云计算。云计算提供了对海量数据在云端的运算
- 物联网。物联网的感知系统,比如摄像头,传感器,可以生成海量数据。
实现以上技术的硬件基础如下:
- 硬件成本,储存空间飞速增长。
- 显卡和cpu的换代大大提升了算力。
- 带宽飞速增长加快了数据传输速度
4V特点
大数据经常把4V提到嘴边
- volume(大容量)
- variety(多样化)。曾经的数据都是结构化数据,存在关系表中,但是现在有各种形式的非结构化,半结构化数据,比如视频,文本,图像,各种日志,文档,文本。
- velocity(高速度)。保证低延迟是大数据的原则,即使数据量巨大。
- value(低价值密度)。大数据有很大的价值,但是密度很低,需要从海量数据中挖掘。
大数据思维
- 全样而非抽样。以前是抽样分析,现在直接把所有样本,海量数据,直接丢进去分析。
- 效率而非精确。以前是抽样,如果不精确,本来抽样就损失了一些精确度,再不精确结果就很可能是错的,但是现在是全样了,已经可以容忍局部的错误,只要整体方向正确就好。
- 相关而非因果。我不需要知道前因后果,只需要堆数据,确定联系就好。类似于古代很朴素的思想,属实是返璞归真了,现在的深度学习技术就是这种思想的体现,我也不管是不是黑盒,反正我就丢一大堆数据进去,让网络拟合。
核心技术
储存
储存,分文件系统和假设在文件系统上的数据库系统。
文件系统有两个:
- 谷歌GFS。
- HDFS,是谷歌GFS的开源版本
同样的,数据库也是:
- 谷歌BigTable。
- HBase,是BigTable的开源版本。
计算

相关技术
云计算
云计算本质上是一种封装,解耦。
何以见得?你写代码的时候是不是需要调库,调库意味着你不需要从头开始实现。
从一个计算系统的角度来说,你从机器的购买,配置,搭建,部署,到软件开发,发布一系列流程本来都是你自己走下来的,如果有了云计算,你就可以直接跳到软件开发那一步,这和代码库的封装本质是一样的。
同时,云计算的解耦特性,可以让云计算服务商专心搞计算硬件服务,让客户专心搞软件层面的东西,这种解耦也可以提高社会分工程度。
所以云计算的意义是很大的,同时这个概念出来也并不新奇。
云计算可以分成三种层次的服务:
- IaaS(Infrastructure as a service)。基础设施即服务,这种是最常见的,比如我们到阿里云上租一个服务器,租一个弹性计算服务等等,实际上我们是在租他的硬件。
- PaaS(platform)。这种封装的比较高,可以理解为给你提供一个SDK,你可以用这个云计算SDK开发程序,这让我想到了科大讯飞之类公司,官网上提供的接口,我猜这个就是PaaS吧。
- SaaS(software)。这个封装到了极点,直接写个基于云计算的软件,让你用(我感觉定制也是ok的)。
云计算还有一个关键概念:数据中心
所有的数据最终还是要存到硬件中的,只不过云计算是集中了起来罢了。
数据中心的成本很高,所以需要满足以下需求:
- 地质结构稳定,气候良好。
- 电费便宜。
- 气候凉爽。
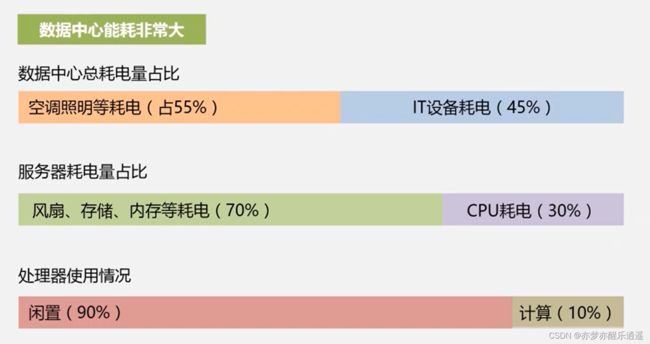
实际上,数据中心能量利用率很低:
关于政务云。
曾经我就在思考,为什么不同政府平台的数据就不统一呢?现在我明白了,当时各有各的服务器集群,而现在时代变了,可以全国公用一个平台了。
这个平台就叫政务云。
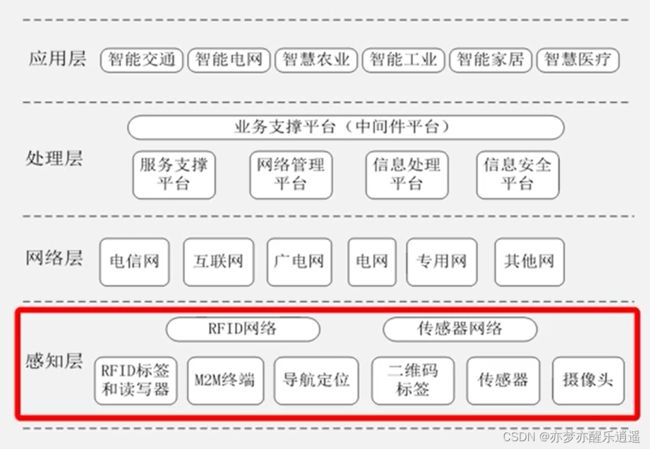
物联网
Hadoop简介
简介
Hadoop是一个开源项目,用Java原生开发,有其他语言的接口。
Hadoop将底层的分布式技术细节隐藏,令用户在体验上保持原状。
Hadoop的核心组件有HDFS,MapReduce,分别解决了大数据储存和计算的问题。
Hadoop有以下优点:
- 可靠性。集群中出故障几乎是必然的,而Hadoop采用冗余数据,保证除了故障依旧能正常运行。
- 高效性。集群中多个节点同时并行计算,传输,效率很高。(这里和冗余数据也有关系,冗余的也不是完全没用的)
- 可扩展性(水平)。水平扩展指的是不断增加机器数量,而垂直扩展就是把一台机器的素质提升。Hadoop集群的扩展很简单,就堆节点就好
- 低成本。集群中每一台机器的质量可以很一般,但是只要数量多,就可以达到很好的效果
Hadoop现在广泛用于包括Facebook在内的各种公司的项目中。
版本之分
hadoop版本很乱。

1.0到2.0,将MapReduce中负责计算资源调度的模块抽取出来变成YARN,提高了效率。
同时提出来的模块还可以用于其他项目上,比如Spark

Hadoop有很多不同的发行版本,学生用就用Apache开源,企业可以考虑另外两个,如果想要在中国获取较好的支持,可以用星环。
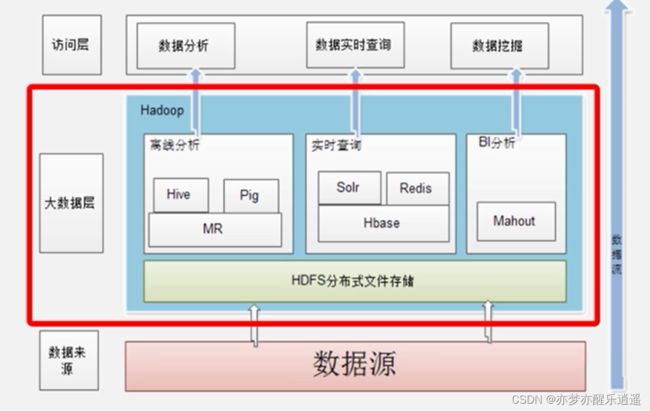
项目生态结构
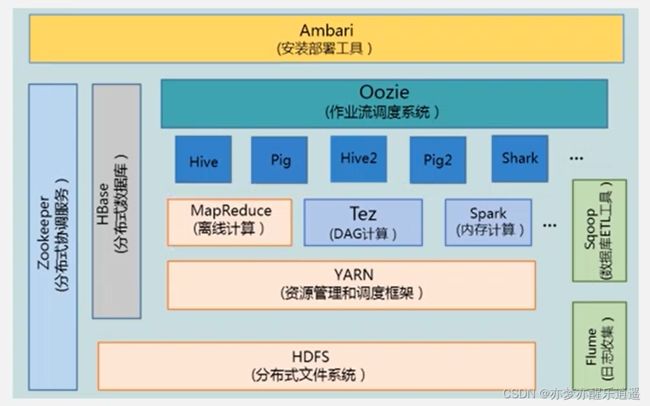
Tez将计算任务变成一个DAG,通过解决类似于流水车间调度之类的问题,将任务安排出最优效率的顺序。
Spark的计算基于内存,而MP基于磁盘,内存的读写速度远大于磁盘,所以Spark性能高一个数量级。
Hive是一个高层次的数据仓库产品。Hive中写的是SQL,这保证了用户的体验,但是后台其实将SQL转化成分布式命令。
Pig是流处理的组件,而不是Hive这样的批处理。还可以提供类似于SQL的语句,并嵌入到程序中去,有一种SQLite的感觉,只不过是大数据流处理的领域。
安装和部署
暂时不写。
HDFS
HDFS解决了海量数据的存储问题,是基础的文件系统,类比于Windows的文件管理器。
简介
集群结构
当前计算机集群的架构,由不同机架上的服务器构成。机架内部有光线通信,速度较快,机架之间也有光纤交换机。
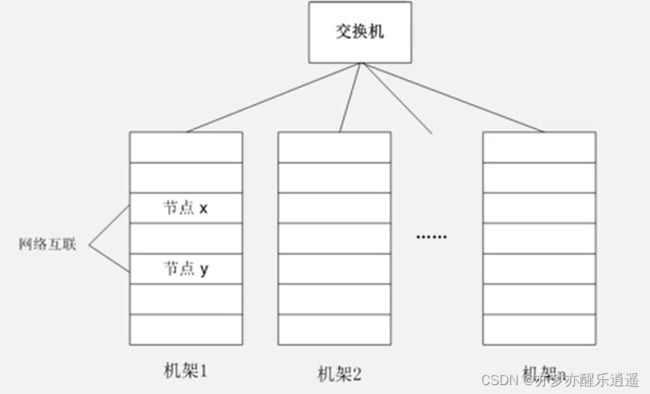
HDFS采用主从节点结构,并且主节点只负责调度,指挥,从节点只负责根据命令做出操作,而读写实际上都是客户端和具体的数据节点(从节点)之间交流,交流的凭证就是从主节点那边拿过来的(颇有一种令牌的感觉,主节点给出令牌,客户端拿着令牌去找从节点提取资源)。

实现目标(优点)与缺陷
一个核心:大容量,但没必要灵活,或者无法灵活。
- 支持大数据集。这个不用说是核心。
- 兼容廉价的硬件设备。大量硬件是大数据的容纳场所,如果这个无法实现,那还不如纵向扩展呢。
- 实现流数据读写。只允许一次性读写几乎全部数据,不允许传统的少部分读,同样是舍弃灵活换来效率。
- 简单的文件模型。只允许追加,不允许修改,舍弃了灵活性,换来效率,这也是没办法的事情,如果要修改那么一大堆文件,效率就会很低。
- 跨平台兼容特性。Java开发。
大数据带来如下缺陷:
- 不适合低延迟数据访问。大数据+流读写决定了不可以灵活地读写。
- 无法高效储存大量小文件。因为分布式储存需要主节点存元数据,文件太多,主节点首先就存不下了。
- 不允许修改。同样是受制于大数据,不允许修改是效率的保证。
从上面来看,实际上并不是说优缺点,只不过是一个系统向着大数据方向进行特异化,更适应大数据场景。
基本概念
块
文件块就是文件存储的最小单位。
实际上,Windows系统也是将文件按块来储存,只不过块比较小。而大数据场景把文件块变大,比如64M之类的。
块的设计有如下优点:
- 适应大数据。把大数据切割成块有利于存到不同的数据节点中
- 简化系统设计。块的大小是固定的,这个信息在底层逻辑中很有用。
- 适合数据备份。同样,以块为单位备份很好统计与执行。
限制:
理论上,块越大越好,因为可以降低寻址开销。但是如果太大,储存是方便了,但是用的时候,一次性消耗的资源太大了,MapReduce一次只能处理一个块,并行的优势就荡然无存。
名称节点(Name Node)
名称节点就是主节点。
名称节点不储存数据本身,而是储存相关的元数据。相当于总管。

当然,元数据没有那么简单,他是被存在FsImage和EditLog两个文件中去的。
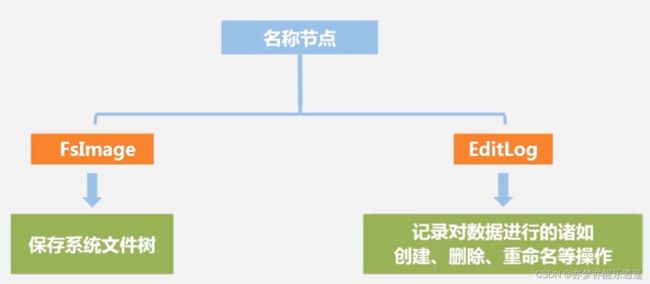
FsImage
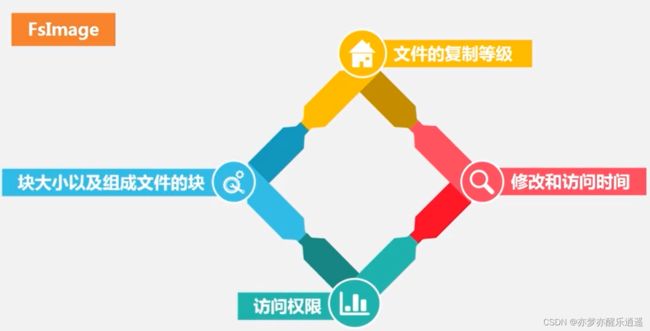
FsImage保存了系统中文件的状态,类似于Windows资源管理器中的信息,是直接与用户打交道的信息。
文件块分布信息
这时可能会好奇,FsImage里缺了一项数据:文件存在哪个节点中,即底层的文件块分布信息存在哪?
FsImage不存这个信息,用户实际使用也不需要这个信息。
这个信息是在运行过程中,由另外一片内存管理的。具体说,就是数据节点向名称节点发送信息,告诉他自己存了那些文件的哪些副本,名称对所有数据节点的信息汇总,得到数据的分布信息。
理论上,FsImage也可以存分布信息,但是设计之初就把这个信息单独分离出去,让FsImage只存放与用户打交道的信息,有利于解耦和设计系统。
EditLog
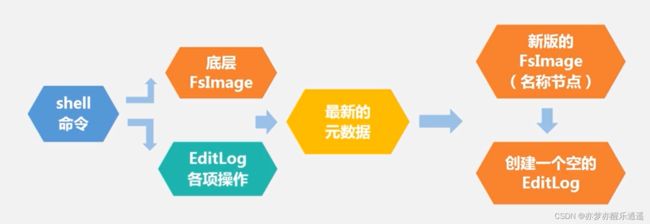
在Windows中,文件修改是即刻发生的,但是在大数据系统中,FsImage是一个很大的文件,如果要频繁修改,会导致效率低下。
这个时候用一个EditLog记录各项操作,因为这个文件小,所以频繁变化也不会有任何影响。当EditLog变大或者是启动机器的时候,就会进行合并,生成新的FsImage与空的EditLog。
实际上,这个EditLog,可以看做是日志+缓冲。
第二名称节点(Secondary Name Node)
两个作用:
- 用于合并FsImage和EditLog(主要目的)
- 冷备份(顺便的)
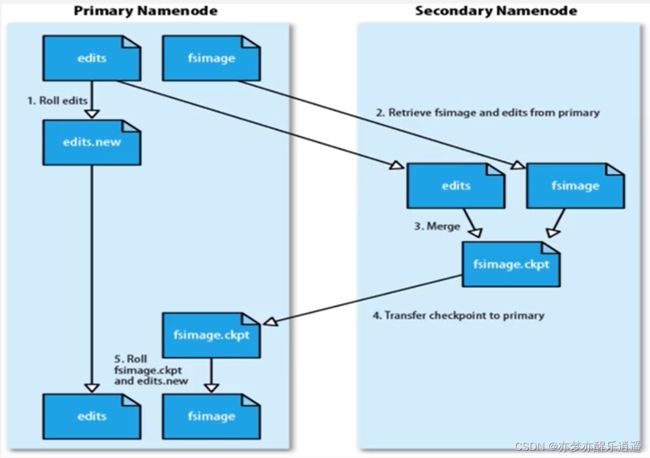
上面说到,FsImage要和EditLog合并,那必不可能在Name Node里直接合并,这样会干扰运行,所以要放在第二名称节点中进行合并。
具体合并过程如下:
- 第二名称节点把两个文件复制过来,这个时候名称节点的EditLog清空,变成edits.new,继续记录最新操作。
- 第二名称节点中进行合并,生成新的FsImage: fsimage.ckpt文件
- 名称节点把fsimage.ckpt文件 复制回来
- 把edits.new和fsimage.ckpt重命名成EditLog和FsImage,这样这两个就分别是最新的文件目录树+文件日志
同时,在第二名称节点中,也存了一份最新的FsImage,相当于冷备份。
数据节点(Data Node)
只是被动接受命令,要存就存,要取就取。
HDFS体系结构
运行过程

读取的时候,客户端向名称节点询问,获取数据节点的位置,然后客户端去和数据节点直接打交道。
写的时候也是,名称节点告诉客户端可以存到那些数据节点中,之后客户端分别去存进去。
有人可能好奇为什么不直接走名称节点,那是因为名称节点的吞吐量是有限的,只负责任务分配而不去管执行可以有效降低名称节点负载。
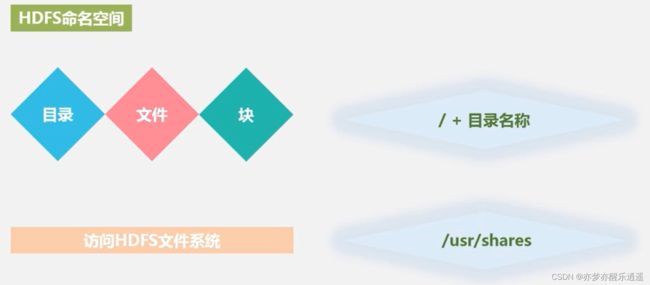
命名空间
除了最底层的块以外,访问HDFS文件和访问Windows文件一样,实际上分布式底层存取都已经被Hadoop隐藏了,保证了客户的体验。
通信协议
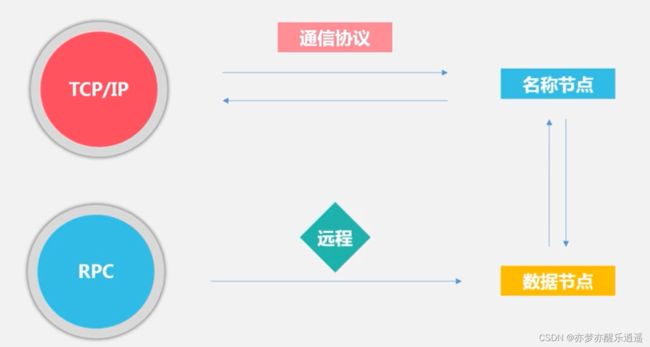
三个通信分别采用三个协议,但是这些协议都是基于TCP/IP的。
客户端可以和名称节点以及数据节点建立通信,分别用通信协议和RPC协议。而名称节点和数据节点的通信被隐藏在底层,和客户端没关系。
局限性

- 注意是内存。内存一般只有2G-10G,很小。
- 因为具体执行时,客户端是和数据节点进行分布式的交流的,所以名称节点只需要负责调度,指派。但即使是这样,名称节点的负载仍然是最大的,限制了HDFS的上限。
- 经典的单点故障问题。
- 第二名称节点是冷备份,所以不能立即顶上,HDFS 2.0进行了优化,变成了热备份。
储存原理
冗余数据策略
在分布式系统中,故障是常态。所以要利用冗余数据,来保证即使除了故障也有备份可用。
其实冗余还有一些其他好处:
- 加快数据传输速度。多个副本的并行读取是真正的并行,可以加速。
- 很容易检查数据错误。比如三个副本,错了一个,另外两个正确,一致,就可以判断出第三个是错误的。
- 保证数据可靠性。即使是出了故障,也有备份可用,不至于一次性被团灭。
数据存取策略
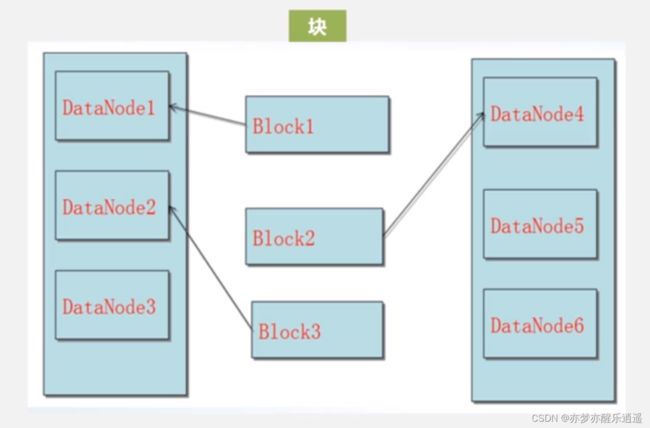
左右分别是两个机架。
假如有三个副本,数据块分布的原则如下:
- 在本地节点放一个副本。这个本地节点,有说法。实际上,数据节点上也可以有应用,那么如果这个应用发起了存数据的请求,那本地节点最合理的位置就是在这个数据节点上,这样不需要进行额外的网络传输。另一种情况,应用来自于集群外部,即应用并不在任何一个数据节点上,那这时就会用算法找出一个磁盘不太满,CPU不太忙的节点上。
- 第二副本放在同一机架上。注意,虽然是同一个机架,但是数据节点不应该和本地节点相同。
- 第三副本放在另一个机架上。
读取原则:
就近原则,如果在本地就直接读取,在同一个机架上次之,最差的就是在另一个机架上。

数据错误与恢复策略
三种情况:
- 名称节点出错。这种情况,整个系统就都寄了,此时就会先暂停系统,然后提取第二名称节点的冷备份进行恢复。如果是2.0,就会直接采用热备份。
- 数据节点出错(故障或者是通信)。数据节点本身会以心跳机制定时像名称节点报告自己是活着的,如果名称节点收不到某个数据节点的心跳,就知道数据节点寄了。此时会把这个数据节点中的数据转移到其他地方,当然不是直接转移,而是调用其他副本,这里可见冗余数据的作用。
- 数据本身出错。最开始存放(追加)的时候会有一个校验码,如果取出来的数据计算出的校验码和名称节点储存的校验码不同,就会判定错误。
数据读写
这一部分涉及到代码相关,仅放图做参考。
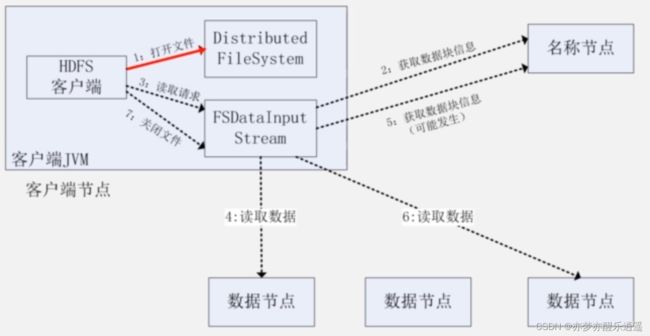
读取
大致上,是客户端向名称节点获取数据分布信息,然后自己去找数据节点进行读取。
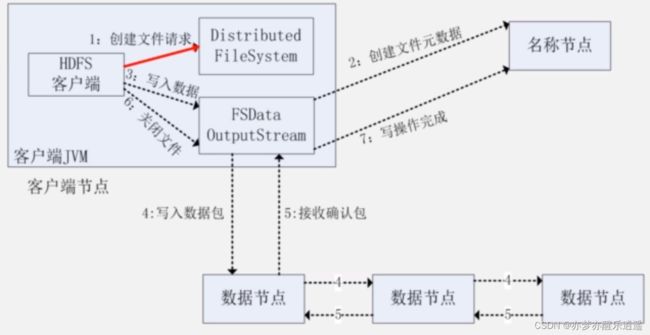
写入
写入也是先像名称节点请求,然后获取目标节点位置。
这里稍微有点不同,在存了第一个副本之后,副本会进行数据节点间的复制,复制到末端以后,末端节点会沿着原来的路径返回一个信息,表明已经复制完毕。
HBase
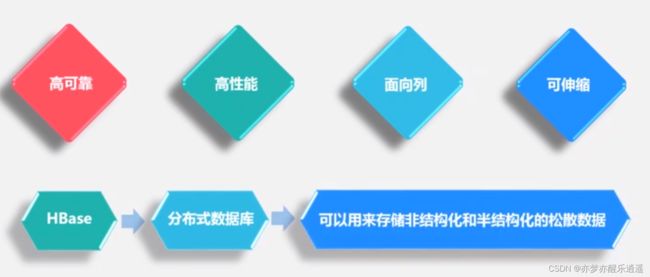
HBase是建立在HDFS上的分布式数据库。
简介
HBase是BigTable的开源实现。BigTable最初用于谷歌搜索引擎的搜索功能。
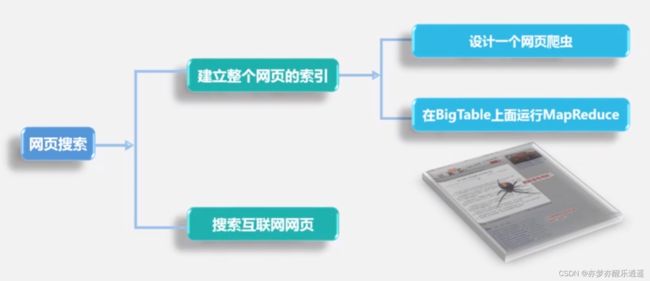
BigTable建立在GFS上,HBase类似,建立在HDFS上。
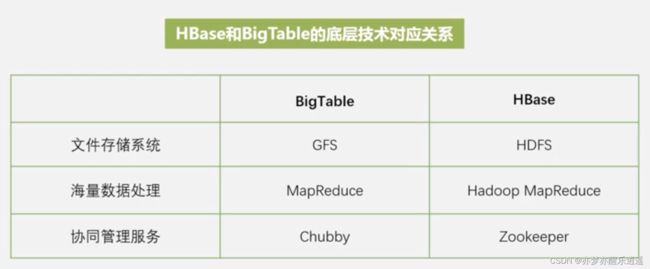
之所以建立HBase,是因为目前没有满足大批量数据的实时读取的技术,现有的HDFS是流式批量读取,关系数据库的扩展性很差,也没办法搞定大数据场景,尤其是现在的数据库经常要变化模式(列)。
HBase继承了大数据的特点,做出简化,适应大数据,特征如下:
- 简化数据类型。只有字符串,解析交给程序员。
- 简化数据操作。只有追加和写入,而诸如连接之类的操作通通简化。其实连接也没必要有了,因为大数据是直接存一个完整的稀疏表的,不需要去做范式分解。
- 简化数据索引。关系数据库可以构建复杂的索引,HBase只提供简单的索引。
- 简化数据维护。只有追加,用时间戳区分,不可以修改。
- 基于列储存。
- 可伸缩性较强。因为基于分布式集群,所以水平扩展很容易,直接加机器就好。
数据模型

一个行拥有若干个列族,一个列族里面有若干列限定符,每一个单元格里可以容纳若干个时间戳版本的数据。
如果要定位一个数据,就需要给出4个维度。
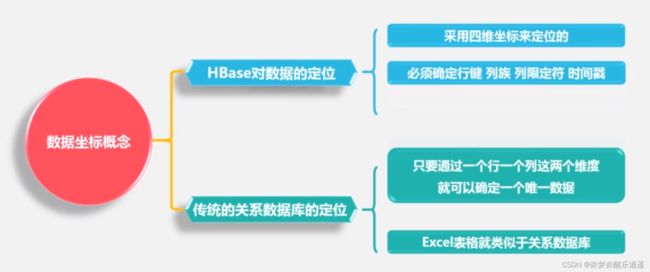
同时,数据只是Bytes格式,解析需要交给程序员处理。
HBase的概念视图如下,对于一个行键,表的行是时间戳,列是列族。单元格里面的数据是
列族:列限定符=数据。由此可见,HBase是稀疏的。
这个概念视图和前面的图不太一样,以这个为准,前面那个只是过渡用的,毕竟,一个单元格肯定是不能存n个数据的。
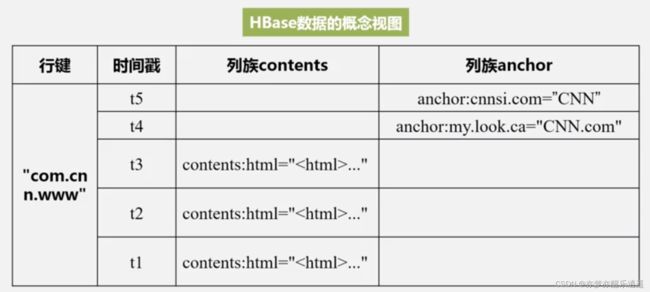
这是物理视图。虽然HBase是稀疏的,但是空间肯定是不能浪费的,于是将列族拆分开储存,一个列族存到一个空间里去。
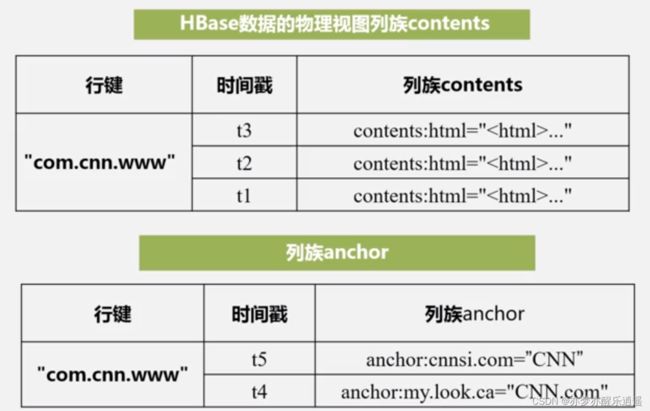
之所以采用面向列操作,是因为分析的时候,都是对一列分析的。如果数据量太大,行式存储效率就很低,因为要取出一列就意味着要遍历全表。
而列存储,分析的时候直接取出一列就ok,效率反而高起来了。
同时,按列存储可以做到极高的数据压缩率。
总之,如果是用于大数据应用(通常用于分析),就用列储存,数据量不多的情况直接用关系数据库就好。
实现原理
HBase功能组件
-
库函数。
-
Master服务器。类比于名称节点。

-
Region服务器。类比于数据节点。
表和Region
一个HBase按照行键分割成若干个Region,可以吧Region理解为部分表,是不可分割的单位。
一个Region可以是100M-1G不等,存到Region服务器中,一个Region服务器可以存10-1000个Region。
最开始肯定只有一个Region,但是随着数据增加,就会进行分裂。
Region三级定位
之所以分级,只因为一级存不下。
最开始,META表承担类似于名称节点的作用,简单说META表有两列,一列是Region的id,另一列是Region服务器的id,这样就可以找到对应Region服务器上对应的Region数据。
但是,因为数据是海量的,导致数据的指针也变成了海量数据,Meta表也存不下了,一个Meta表甚至超过了100M,1G,1T,这个时候肯定要进行分布式储存。幸运的是,META表本身也是一个HBase表,所以还是可以套用数据表的模式,于是就出现了Meta服务器和Meta的Region。
而记录Meta表的Meta数据的,就叫ROOT表,这个表只有一个Region,且地址是写死的。
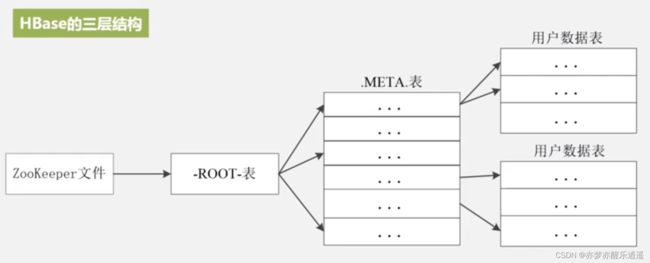
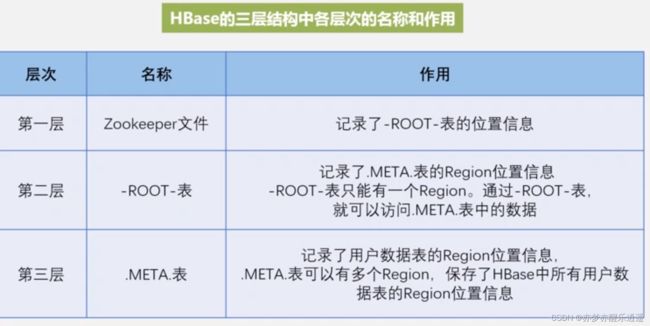
刚开始可能会好奇,ROOT就不会膨胀么?
实际上,不会再有更多的分级了,可以简单计算一下,三级可以容纳的储存上限已经足够广大企业使用了。

三级寻址实际上是有点慢的,所以每次寻址以后会保留缓存。
如果文件发生改变,就会导致缓存找不到,这个时候就会重新进行寻址,这是一种惰性的缓存策略,但是很有效。
运行机制
HBase系统架构
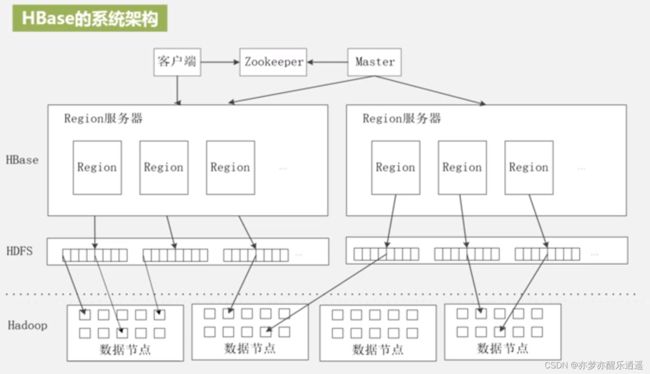
Zookeeper服务器负责统筹运行,负责整个HBase系统的维护。
Master服务器负责日常的指挥,类似于名称节点,负责HBase表和Region的管理。

Region服务器可以类比于数据节点。
Region服务器工作原理
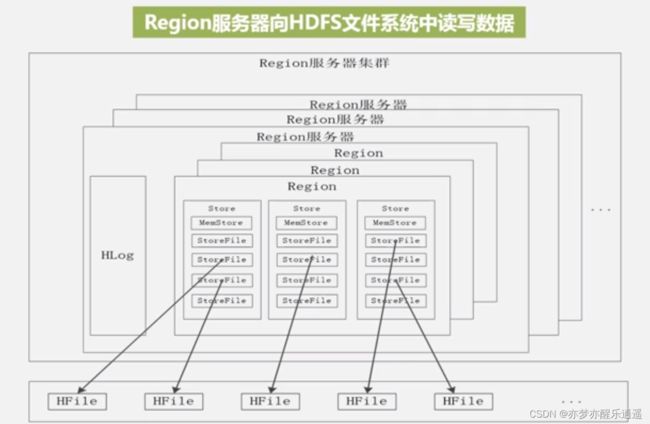
一个Region服务器里有若干个Region,这些Region公用一个HLog。
一个Region是一个表按照行键切分的一部分,在这一部分中,还可以按照列族继续切分,每一个列族都用一个Store储存。
而且,对某一个列族写入数据的时候,也不是直接写入的,毕竟是大数据,每次只写一点没意思,所以就有了MemStore缓存,等MemStore满了,再一次性刷写到StoreFile中去。
StoreFile在HDFS中以HFile格式储存。
数据读写与Store原理
用户写的时候,先写到MemStore中,然后写到日志。等到MemStore塞满了,再刷写到磁盘的StoreFile中。
用户读的时候,先读MemStore,因为可能这里还有一些未被刷写进去的最新数据,如果没有目标数据才去磁盘的StoreFile中去找。
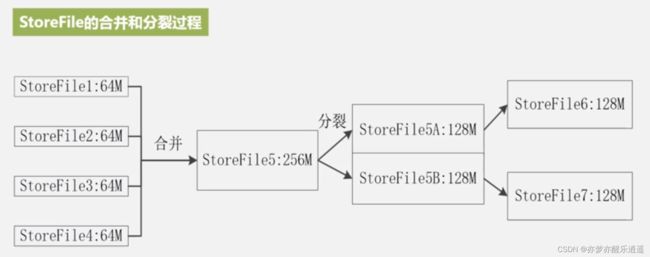
MemStore并不大,所以StoreFile可以说是又多又小,不符合大数据的风格,影响效率,所以必然要合并。
合并还没完,有时候合并太大了,就会分裂,这个分裂是把一个Region分裂成两个Region。刚开始一个Region服务器只有一个Region,就这样逐渐刷写,合并,分裂,Region就逐渐增加起来了。
HLog工作原理
前面提到,一个Region服务器用一个HLog,这样可以提高效率。那么当一个Region服务器出现故障,HLog又是如何发挥作用的?

如果一个Region服务器故障,那么上面所有的Region就都不能用了。如果要恢复所有的Region,就要先把HLog拉到新的Region服务器,然后拆分HLog,拆分原则是按照Region拆分的,用每一个部分去还原每一个Region。
虽然这样拆分比较麻烦,但是总好过管理一大堆HLog。
应用方案
涉及到应用,暂时不写。
NoSQL(Not Only SQL)和云数据库概览
因为我以后不往这一块发展,所以我看NoSQL和云数据库仅仅是开一下眼界,作为像MapReduce的过渡罢了。如果有人想认真研究,这一章帮不到你。
NoSQL和关系型数据库是相对的概念。
传统关系型数据库遵循ACID原则,对数据的质量严格把关,不允许一点错误发生。但是缺点在于不够灵活,难以进行扩展,同时对于大数据场景的适应性不够强。
新型数据库大致上,舍弃了对一致性,稳定性,安全性的极致追求,容忍一点点失误几率,反过来去适应大数据的场景。NoSQL强就强在架构灵活,但是这也是缺点,灵活代表着还没有坚实的理论。总的来说,目前有四种NoSQL,各有优缺点:
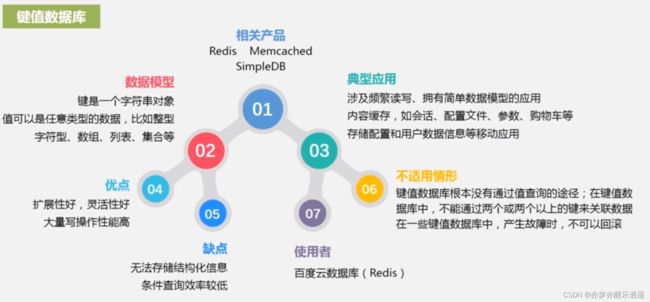
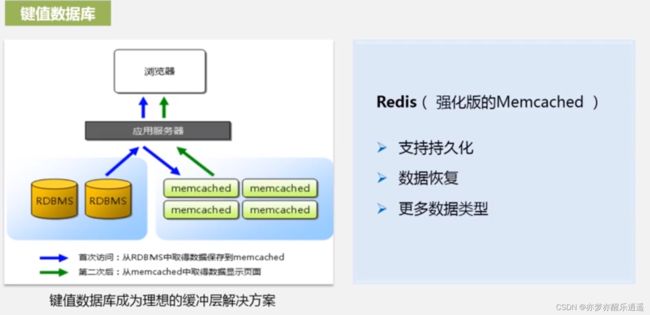
- 键值数据库
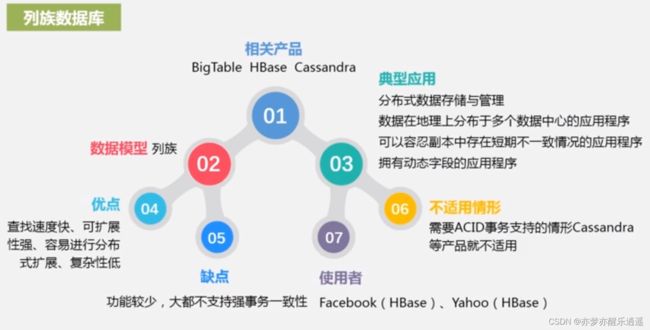
- 列族数据库
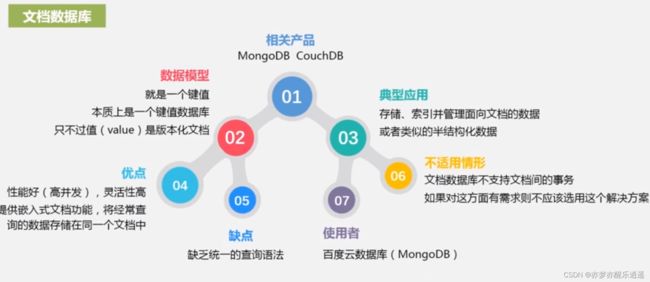
- 文档数据库

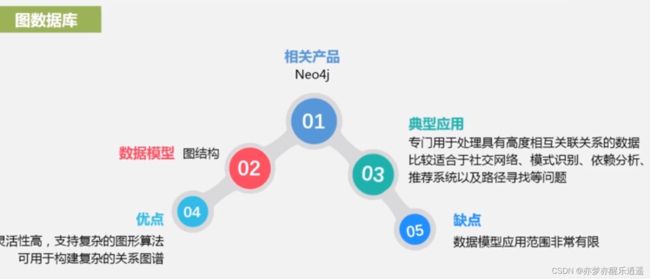
- 图数据库
所谓云数据库,实际上对应于PaaS或者SaaS层次,就是把数据库产品直接放到云计算平台上,有的,仅此而已。
云数据库产品中,既有关系型数据库,又有NoSQL数据库。
MapReduce
概览
分布式并行计算框架
MapReduce是分布式并行计算框架。
之所以需要用到分布式并行计算框架,同样是因为计算单元的纵向扩展难度较大,CPU,GPU的算力增长跟不上数据量膨胀,于是人们将主意打到了水平扩展的分布式集群上。
分布式并行计算框架有很多种,比如MPI消息传递接口,OpenCL,CUDA,各有优缺点,虽然传统并行计算框架有很多缺点,但是其应用场景和MapReduce还是差异很大,难以互相替代的:
分布式思想
MapReduce继承了大数据的简化风格,只给用户保留了Map函数和Reduce函数的自定义接口,包括并行计算在内的细节全部由框架解决。所以不需要程序员学习大量的函数,核心只需要编写两个函数即可。
MapReduce采用分而治之的策略,流程如下:
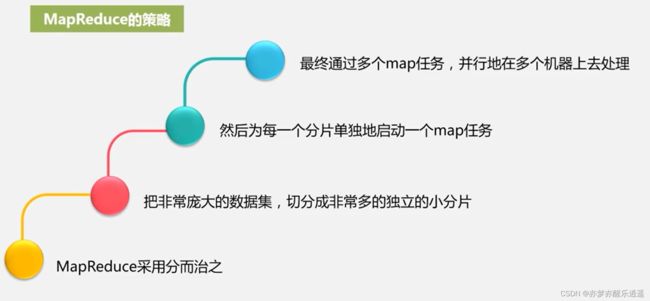
这里就可以看出一个缺点,map任务之间是没有任何依赖关系的,互不干扰,完全是平行,这也意味着,凡是要在MapReduce上运算的程序,都必须能够进行分治,所以虽然能够用多个MapReduce任务相互配合,但是并不是所有问题都可以通过MapReduce进行解决。
硬件架构
具体到架构,首先是计算向数据靠拢的思想:
在大数据时代,数据的移动成本很高,所以不如反过来移动程序,把中心节点的程序分发到不同的数据节点进行Map操作,之后再进行Reduce操作,就可以显著降低数据移动成本。
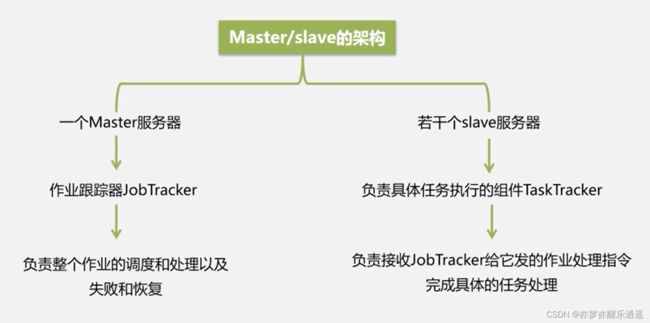
之后就是节点分工:
Map/Reduce函数
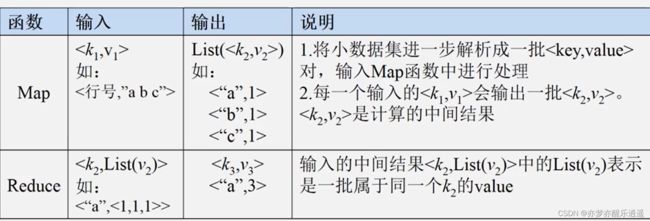
Map函数,输入一个key:value,输出n个key:value。这样,通过Map函数,可以把若干个输入的key:value解析成更多的,更有利于处理的信息,解析后的信息可以充分进行分治计算。
Map后的信息还要经过一系列处理,才能变成key:value-list形式。
Reduce就是对解析后的信息进行处理,得到最后的信息。
整个过程就像是先分再合,这也是分治的思想。
体系结构

Client
两个交互:
- 用户到系统。
- 系统反馈用户。
JobTracker/Task Scheduler
其实JobTracker并不是任务调度的计算地,真正进行任务调度计算的是TaskScheduler,这是一个可插拔模块,支持按照用户自定义的规则来安排任务。

TaskTracker
同样是主从节点。
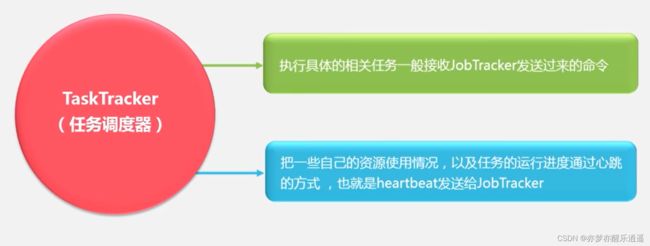
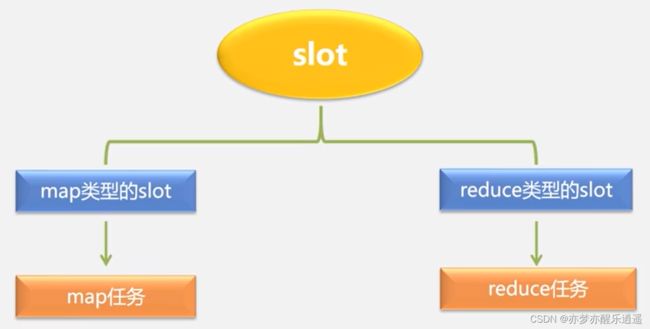
这里有一个问题,什么是计算资源?
在MapReduce中,使用slot作为资源的最小单位,slot分为两种,对应可以执行不同的任务。如果一台机器的map-slot已经被占满,即使有reduce-slot空闲,新来的map任务也不可以运行。
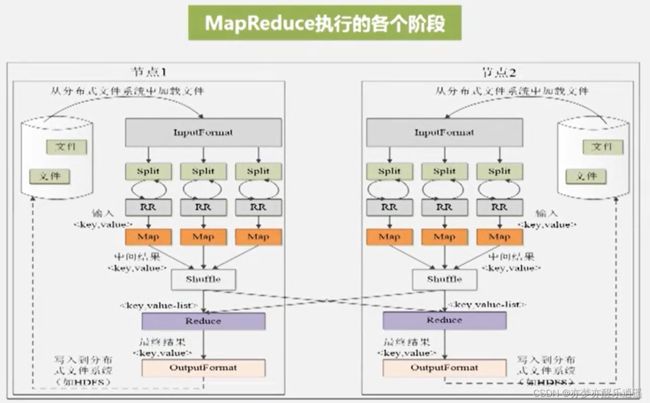
工作流程
大体来看,就是先分后合。
map任务的数量大致和分片数量相同,如果分m片,一般就是m个map函数。
某一个 map函数的结果,如果被分成n组,那么就要对应n个reduce任务,即一个map任务的结果要被划分为n部分,分别给到对应的reduce任务。
这个颇有一种神经网络全连接的感觉了。当然,很多时候n=1(虽然这样做没有并行优势)。
需要注意的是,并不是map以后就直接输入reduce,中间还要经过包括shuffl在内的一些中间处理,形成中间文件。

分片

首先InputFormat模块对输入进行验证。
之后进行分片,形成若干个split,当然这个分片只是逻辑上分一下,不会影响到物理空间
最后就是RR模块(Record Reader)把物理空间中的分片读出来,转化成key:value形式,送到Map函数中作为输入。
因为是逻辑分片,所以可以随便分,但是实际上如果一个split太大,就会牺牲掉并行度优势,如果split太小太碎,又会导致并行成本剧增,反而把并行优势抵消掉。
理想中分片的方法就是直接用数据节点中的HDFS数据块。如果一个分片中包含了1.5个数据块,可能1个数据块是本地的,0.5个数据块就要从另一个节点去拉,那还不如直接就只要一个数据块,100%保证本地。
map任务
map任务是自定义的,形式上就是输入1个key:value与输出若干个key-value结果。
输出并不是直接输出,而是先写到缓存里。
shuffle过程
我至今不明白shuffle过程的明确的界限,我将shuffle理解为:
从map结果到缓存到中间文件,以及被reduce节点拉取,处理,直到reduce前的一系列流程
所以我姑且用缓存作为shuffle的开端。
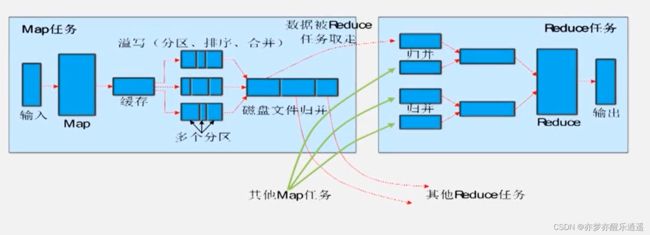
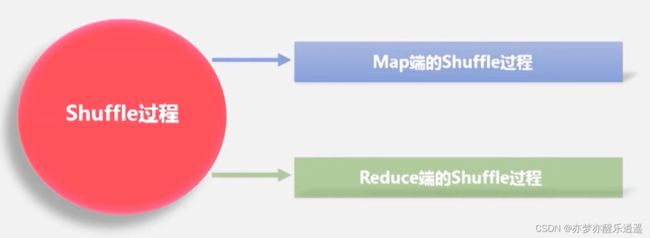
map端shuffle
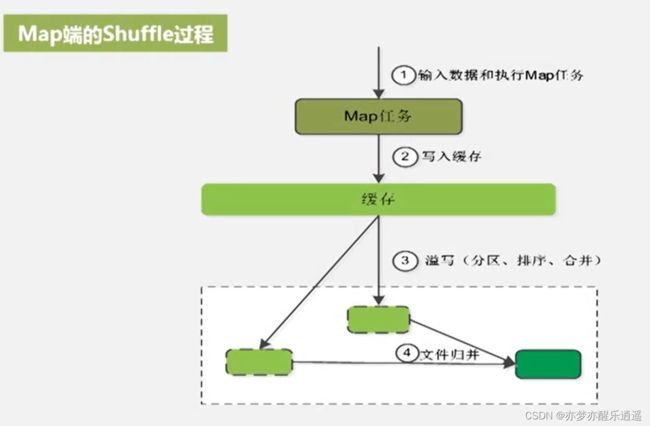
实际上,map任务并不能一次性把输入全部算完,所以是要分多次搞定的,结果也是一部分一部分输出。
因为结果不可能一条一条写,太麻烦,每写一条都要寻址,所以就要先写到缓存里。当map函数的输出把缓存填充到一定程度,就会进行溢写。
溢写要经过分区,排序,合并(非归并),结果就是形成一个小的磁盘文件,这个磁盘文件是排序好且分n个区的,这n个区代表后续n个reduce任务。
把若干次map计算的小磁盘文件整合以后,可以形成一个大磁盘文件,这个文件仍然是分为n个区,是小磁盘文件对应区域的归并。
形成大磁盘文件后,JobTracker就会监控到,就可以通知reduce任务拉数据了。
以上过程有一些细节:
- 缓冲不能填满,否则新的结果没地方放
- 注意区分合并和归并。这里的合并指
- 合并操作是可选的,这样可以减少写入磁盘的数据量。但是这个过程是一个定制化的过程,贸然合并可能会导致后续任务逻辑出错。
reduce端shuffle
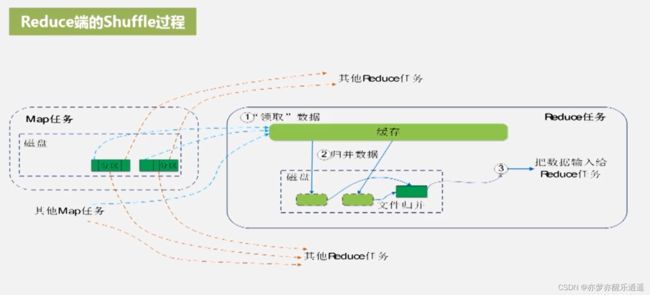
reduce任务接到JobTracker的通知后,就会从多个map任务的大磁盘文件中拉取属于自己的一部分。
因为reduce任务的输入是key:value-list,所以要先对若干个key:value进行归并。这个归并就是前面说的
归并的结果先写到缓存,之后快满了就溢写到磁盘中。
小磁盘文件再次进行文件的整合,形成一些大磁盘文件,喂到reduce任务中。
reduce任务

有时候会采用0.8的reduce任务比,保留20%的slot以作备用。
reduce同样是自定义的,形式上输入1个key:value-list与输出1个key-value结果。
整体流程
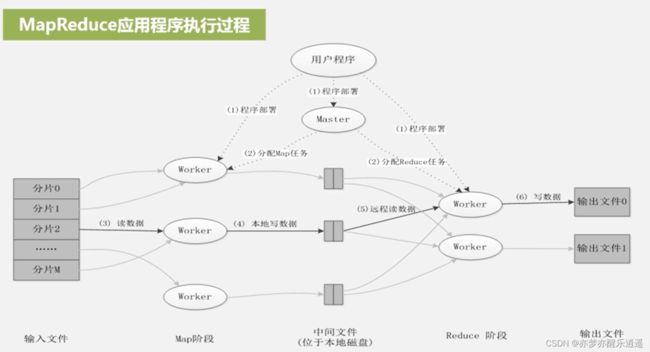
这个图从上往下看。
首先把程序分发下去,选定1个master-worker,m个map-worker,n个reduce-worker。
之后就是先分片,然后读取,map,shuffle,reduce,输出,如前面所述,此处不再赘述。
需要注意的是,中间文件是直接写到磁盘的,不会写到HDFS中,这样反而会麻烦。
实例分析
词频分析(world count)

最起码,这个任务是可以进行分治计算的,所以可以用MapReduced
第一步是要确定RR模块的转化方式+map运算,即如何将任务的文件转化成key:value形式。key可以用行号,value用一行文本做。实际上这个key没有意义,但是map只要这样的形式,所以没办法。
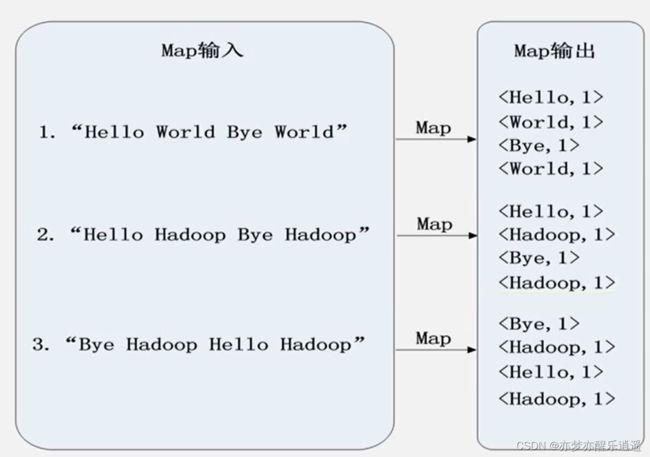
第二步就是shuffle,构建出reduce的输入。
最后就是喂到reduce函数里得到结果。
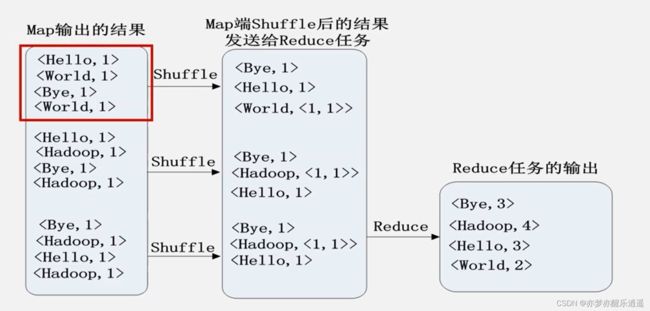
上面的shuffle还可以加入combine(合并)环节,结果是不变的。

实现自然连接
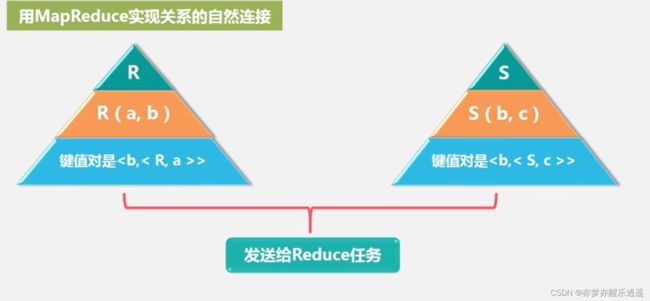
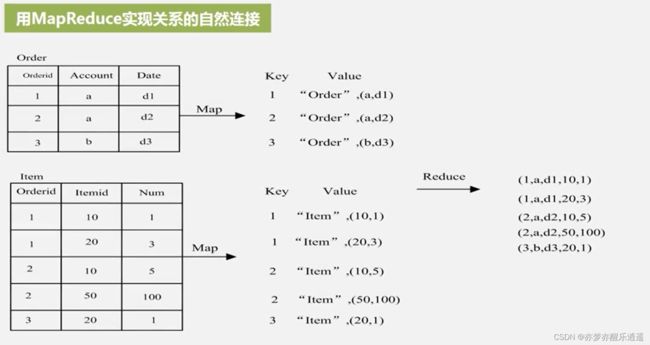
两个表的公共字段是order。所以就用order作为key。
value中的第一个变量是关系名,用于区分关系,如果是来自一个关系,自然不会被reduce。图里面把不同来源的value分开了,实际上是混起来的,程序中可能会用关系名将value分成两份。
最后就是reduce操作,寻找key相同的进行归并,因为key已经排序过了,所以归并的过程是非常顺利的。其实在关系型数据库里,有一种连接技术就叫索引连接,通过借助索引实现 O ( 2 n ) O(2n) O(2n)的算法速度,这里的reduce和索引连接思想一样。
Hadoop再探讨
这一章我没有细听,仅对第一部分进行宏观总结。
概览
Hadoop 1.0 缺陷
- 抽象层次低,需要人工编码。即使需要完成很简单的任务,都需要手动去写map,reduce函数。
- 表达能力有限。MapReduce函数的简化抽象虽然简化了难度,但是也限制了表达能力,有很多问题无法通过MapReduce解决
- 开发者自己管理作业(Job)之间依赖关系。实际问题常常需要多个MapReduce任务互相配合,这种依赖关系需要手动编写。
- 难以看到程序的整体逻辑。程序对用户的反馈很差,用户无法从高层直接看到逻辑,只能看代码。
- 执行迭代操作效率低。在一个迭代任务中,MapReduce会先把结果写到HDFS中,再重新读取,如果反复迭代进行任务,就会造成低效率。
- 资源浪费。reduce需要等待map完成以后才能运行,这个过程造成资源浪费。
- 实时性差。MapReduce框架针对的是批处理情景,对实时处理支持较差。
Hadoop 2.0改进
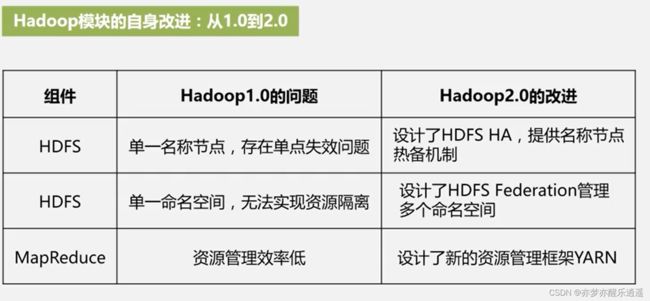
生态概览
这些技术仅做了解。
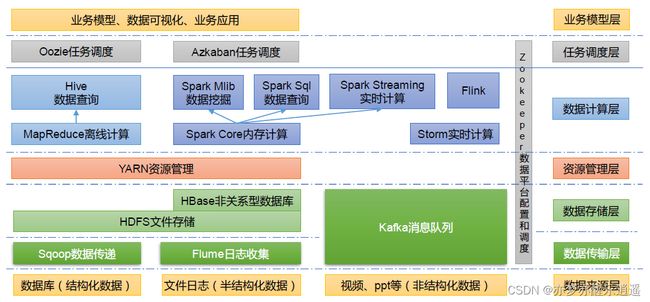
Spark基于内存的计算框架
Spark可以作为MapReduce的补充或者是替代,提高一些迭代式运算的性能,比如基于Spark的分布式机器学习框架MLib。


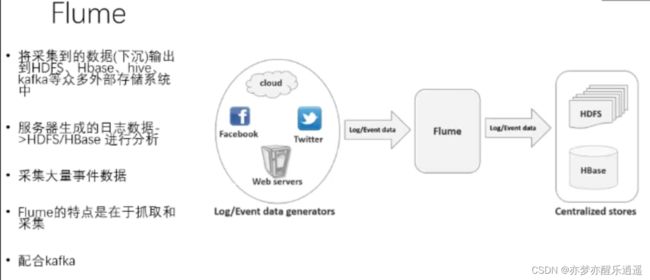
Flume日志采集
Flume用于采集服务器运行日志,生成分布式数据,输出到HDFS或者HBase中。
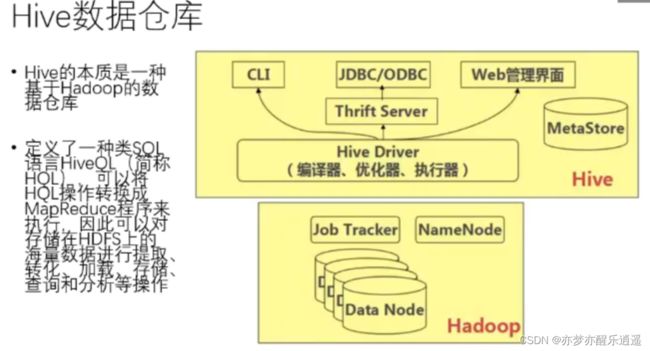
Hive数据仓库
数据仓库不同于数据库,感觉像是一种加强版本的数据库系统,不仅限于储存,还包括提取,转化,加载,储存,查询,分析等一系列操作,而且支持类SQL语句,系统会自动转化为MapRecude程序。
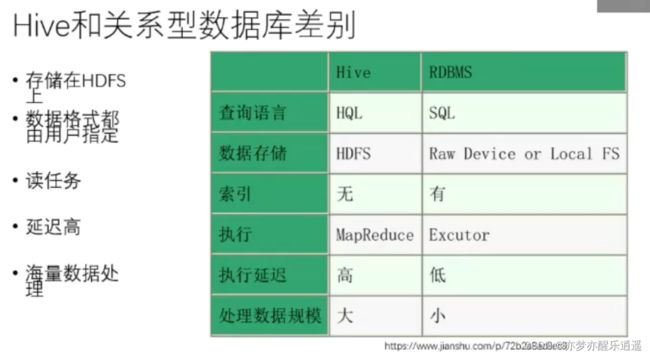
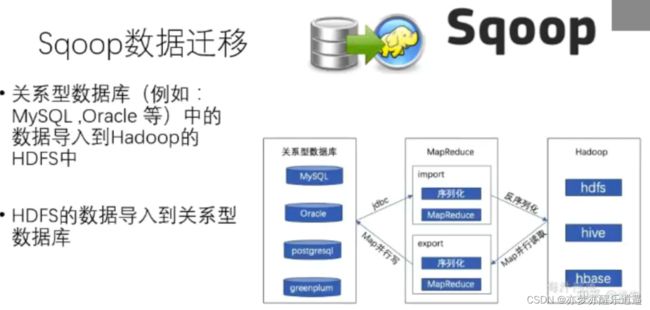
Sqoop数据迁移
实现关系型数据库和HDFS/Hive/HBase之间的双向转换。
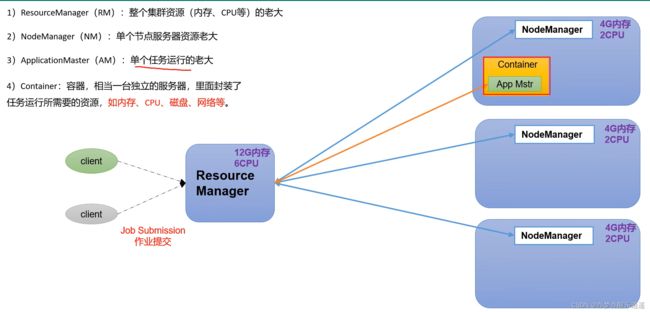
YARN资源调度框架

- ResourceManager。可以理解为所有资源的老大。
- NodeManager。一个服务器的老大。
- Container。相当于一台服务器,但是这个是可以虚拟出来的。比如一个真实的服务器可以虚拟出10个虚拟服务器,阿里云的虚拟技术就是这样的,你自己电脑里的VmWare也是这样。
- ApplicationMaster。单个任务的老大,必须运行在Container里。这样的好处在于,运行完以后可以自动释放资源。
- Task。这是正在执行的任务,App Mstr只是任务的管理者,而真正执行的任务是Task,分为MapTask,reduceTask。一个AppMstr下属的若干个Task可以分布在不同的NodeManager上。
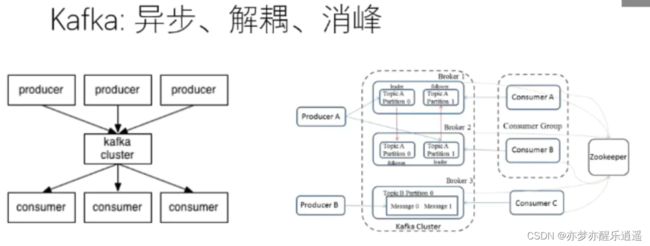
Kafka消息队列
Kafka是一种消息队列,主要用来处理大量数据状态下的消息队列,一般用来做日志的处理。
Flink数据处理

Storm实时计算
Storm是计算系统。


实战部分
完全分布式集群配置(虚拟机)
概述:为什么要用完全分布式
这里重点在于完全分布式这几个字
hadoop有三种搭建方式,一种是本地,另一种是伪分布式,最后就是分布式。
在厦门大学的课程中,是采用伪分布式搭建的。但是这种方式只是一种委曲求全的过渡方式,并不能真正锻炼一个人的能力。
分布式搭建方法可以锻炼一个人的这些能力:
- 虚拟机安装,配置,linux系统安装
- 计算机网络基础知识,虚拟机网络配置
- ssh连接,免密登录,xshell远程开发与xftp远程传输文件技术
- linux基本命令,linux文件目录结构
- vim编辑器的用法
- shell脚本基本写法
如果你只用伪分布式写法,其中大部分知识你是学不到的,你只能学到和hadoop紧密相关的,hadoop本身的知识,但是这些知识不具有迁移性,对未来的成长帮助有限。
所以说,如果时间比较充足,建议用分布式配置,虽然过程会比较麻烦,但是跟着视频走,同时在csdn上多查阅资料,就可以很轻松的跟上,并不会出现bug。(此处表扬一下尚硅谷,这个品牌真的是良心,讲的特别好,我本人没系统学过linux和计网,也能跟下来,一遍过)
我的这一节文章主要是对视频提供一些辅助,补充,帮助人更好的跟上。
尚硅谷Hadoop视频
这个课程不错,侧重于实战,和这个理论帖相互配合。
hadoop实战
这个帖子和尚硅谷课程一样。完全就是尚硅谷那个资料里面的笔记(word版),但是实际上课程视频里讲的顺序和尚硅谷word的顺序有所差异。
虚拟机创建与系统安装
VmWare是收费的,但是确是本地注册,这也意味着,只要你有注册码,就可以反复用来注册。所以网上流传着各种版本的注册码,都可以拿来即用(当然,原则上我们推荐购买注册码)
虚拟机创建里面,有一个是磁盘大小选择。很多人看到磁盘那么大就被吓住了,实际上这只是给一个上限,如果你去看虚拟机文件大小的话,你会发现可能刚开始就只有9G,远达不到40G的上限,所以可以放心选择40G的大小,最终估计走下来也只会用到15G左右。
另一个是系统的选择。我的建议是,使用centos 7,我第一次用centos6配,设置界面大不相同,而且关键在于没有ens33网卡,所以如果你要照视频学,一定要选择centos7
有人搞不懂位数,在虚拟机创建里,镜像选择有centos 7 和centos 7 64位。很明显,没说64位就是32位喽。如何判断镜像文件是64为还是32位呢?一般来说,x86_64或者x64就是64位的 x86就是32位的。
虚拟网络环境搭建
这个时候,虚拟机还没网,虚拟机之间也是独立的,不能互联。所以要配置网络。
这里就要用到计网知识。
计网基础
网关概念
学完这些以后,再看视频,你就会觉得很爽了。
这里需要注意,你配完windows的DNS以后,你会感觉网络变慢了,这个我初步估计是DNS的问题,你指定了8.8.8.8的广域网DNS,但是原来是什么就不好说了,所以如果仅仅是学习的话,后面还是把windows的网络设置还原吧,如果以后要用再设成hadoop的就行了。
突然想到,这里开始你就要改文件了,改文件要用vim编辑器。
vim基础
JDK和Hadoop安装 | 环境变量
关于版本,我们这里用hadoop3.1.3,官网可以直接下载tar.gz包,jdk老师用的是jdk 8u212,实际上,我看过官网文档以后,发现用jdk8都可以,所以我用了一个镜像网站上的8u202,结果表示运行是ok的。这也合理,好歹也是跨平台的东西,要是随便一个小版本变化就不能用了未免太过儿戏。
在windows中安装软件过程比较复杂,但是在linux中,直接把tar.gz压缩包解压了,就算安装好了。
但是这样安装的程序,你只能找到对应的二进制启动程序(类似windows中的.exe文件)才能运行,所以要配置环境变量。
所谓环境变量,一般狭义上指PATH变量,这个变量的意义在于,比如当你在某个目录下运行一个程序,如果你没有找到这个程序,PATH就能提供一些路径让你去找这个程序。如果没有PATH或者当前目录没有这个程序,这时就会提醒你找不到应用程序。
配置环境变量的时候,export声明需要有,不过这是具体的内容了,视频里有。
文件批量分发脚本
这个脚本在集群应用中很有用。
首先会学scp命令,这个用于文件的单点传输,rsync命令,用于单点同步。
基于单点通信,我们可以编写shell脚本,循环发送给出的文件,循环选择主机,进行群发。
我们还配置了ssh免密登录,我以前还以为这个有多难,实际上理论和操作都很简单。
集群配置

当时我在学理论的时候,我还以为namenode之类的管理类主节点和datanode是分开的,到这里我才明白,管理类节点是完全可以和datanode在一个服务器上的。甚至你把NameNode,ResourceManager都放在一个节点上都ok。但是一台机器的内存是有限的,管理类节点对内存占用很大,所以尽量分开,把NameNode,2nn,NodeManager都分到三个服务器上。
具体的操作也就很简单了,就是用vim去改自定义的4个xml。
视频中会给出默认xml,但是这个默认xml只是用于讲解的,真正改的还是4个自定义xml
很多人看到故障修复就不看了,实际上后面还有个历史服务器配置,我建议到这里直接跳过故障修复再一次性把历史服务器配了。
集群启动与关闭
启动与关闭都在sbin文件夹里。
可喜的是,如果你已经启动了,你再重新启动也不会有bug,这就有了很高的容错率,能让你随便试。
不过需要注意的是,脚本运行的主机,比如你的namenode在hadoop102上,你就在102运行hdfs的启动脚本,这样可以一次性启动所有节点的。
如果你在其他节点上启动hdfs,你只会启动datanode进程,namenode进程不会启动。我不太理解为什么会有这种问题,毕竟xml里已经配置好了,大概是下属不能指点老板罢。
同理,如果ResourceMangeer在hadoop103上,你就去103启动yarn,historyserver在102上,你就去102启动历史服务器,否则就也是上面这种情况。
同理,关闭也是这样。
总的来说,最好还是到对应的管理节点(nn,yarn,historyserver)上去管理集群中其他节点,否则会出现问题(我感觉还是子节点无法影响主节点,打工人指挥不动老板)
故障修复
没啥可说的,按视频里。
不过学习阶段,只要你正常启动和关闭,是不会有事的()
使用hadoop自带jar包——wordcount
首先你要往hdfs系统中创建目录和传文件。
这里要区分开,hdfs和linux本地的区别。hdfs是把集群作为一个整体对象,去存文件,而本地仅仅针对于linux,传文件就是把linux本地传到hdfs集群中。
有人刚开始只弄个txt,以为本地和hdfs没啥区别,实际上如果你传大文件,你就会发现文件被拆成128M的块了,如果你只读一个块,就会乱码(比如视频中的jdk,我试过,只读一个直接乱,把两个压缩起来才能读)
之后就是运行MapReduce任务了。这是没有加输入输出参数的部分命令
首先声明hadoop,之后告诉他要运行jar包,指定jar包目录,还要指定jar包中具体的程序wordcount。
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount
之后就是加输入和输出路径了。
在本地运行模式中,输入输出这么写:
wcinput wcoutput
或者
./wcinput ./wcoutput
在hdfs中,输入输出用 / 根目录去找,这个根是相对于hdfs说的,而不是linux本地
/wcinput /wcoutput
从这里可以看出,hadoop是不会显示指定本地模式还是hdfs分布式模式的。但是实际上是有隐形区分的,这个区分就在根目录上。
如果是 / ,那正常人肯定不会把文件放到linux根目录,所以自然hadoop就会去hdfs中去找。
而你加了 ./ 或者啥也不加,那就默认是本地了。你可能会想出一些“例外”情况,但是我想说没那么多例外,本来本地运行就很少,没必要整花里胡哨的。
自己本地搭建java项目后放到hadoop集群上运行
基本流程
代码易找,流程难找,我这里重点讲实现流程,至于代码只是附带的。
这一部分同样不建议去网上找文章,尚硅谷hadoop视频第67集开始讲MapReduce部分,耐心看视频,把wordcount案例看完以后你就可以自己写倒排索引了。你最后会发现,网上的帖子你都能看懂了,虽然他们只给代码,但是你可以自己导包,可以debug,可以自己部署,你花的时间远小于从网上到处找文章的时间。这就是走对路的好处。
总的来说:
- 在windows(或者其他自己趁手的地方)搭建hadoop环境,编写Maven项目,用idea或者eclipse都可以。
- 按照MapReduce写法,构建类,配置依赖,调试无误。
- 打包成jar,上传到linux本地
- 使用hadoop jar命令运行这个jar包,至于具体的写法,后面说。
这里以wordcount和倒排索引来举两个例子,并且探讨一些hadoop jar命令中关于项目中类路径是否应该加的问题。
windows搭建简易hadoop环境
尚硅谷视频里没有给出windows配置,所以我写。
说实话,我感觉windows真的麻烦,linux虽然看起来麻烦,但是实际上是全知的,不会出bug,但是windows配置就很容易出bug,一堆破事。
言归正传,开配,可以按照参考文章1 来走,我会指出一些坑点。
1 大致配置流程
其他参考:
2 修改路径bug
3 多版本jdk安装
4 hadoop3.1.3对应的winutil.exe 提取码cyyy
- JDK安装。如果你系统里本来就有jdk,那么就要参考上面给出的多版本jdk安装指南,尤其是注意环境变量能否生效
- hadoop安装——安装包问题。hadoop只给出tar.gz包,这个包在windows下也可以用适当的工具解压,和linux使用没什么区别,除了.sh文件变成了.cmd文件,这点在命令行运行的时候要注意。
- hadoop安装——配置bug修改。jdk 8的默认安装目录是C:\Program Files\Java。但是在hadoop的一个配置文件中,JAVA_HOME是不允许有空格的,所以应该在hadoop的配置文件中改一下,用PROGRA~1替代Program Files,参见上面的2 修改路径bug
- 这几步走不走无所谓,不影响运行。因为你不是要在本地搭建伪分布式,你也不需要在浏览器看,因为你只是需要跑通,如果你需要用浏览器之类的那就配。
- winutil.exe注入。配好上面的后,还会有系统bug,这是windows本身的问题,所以你需要把hadoop-3.1.3\bin目录中的东西替换成我上面给出的那一堆。
- 最后再格式化集群,用sbin\start-all.cmd启动本地集群(会自动生成4个黑窗口),之后就可以先尝试跑一个hadoop自带的wordcount,这里我就ok了。
Maven项目的配置
视频里的maven配置并不一定要完全照做:
- 关于maven版本的选择。视频中用了本地的maven,弹幕中有人说这是为了用阿里云的仓库(因为自带的maven可能导致国内访问速度变慢,但是我感觉用自带的也OK)
- pom.xml中添加依赖以后出现红字。这是因为本地没有依赖,这个时候从右边的maven符号里调出菜单,从网上自动拉取依赖。
MapReduce项目的编写机制
代码部分需要编入的信息如下:
- Map,Reduce之类的业务逻辑
- Driver类中指定各种类型,以及输入输出路径(或者指定使用命令行参数模式)
- 写好以后直接运行main方法就好,不需要启动集群之类的命令行操作,只需要去看结果就好了。
- 有很多注意点,我们后面实战会逐一点出。
再次表扬尚硅谷,大海哥太细了,甚至教我debug。
具体案例——倒排索引
wordcount尚硅谷已经给出,这里给倒排索引。
通常来说,给出一个文件,我们可以找到里面的关键词,那搜索就是反过程。先给出关键词,再反过来找出哪些文件里有这个词,这就是我们平时进行网页搜索时的基本原理。
倒排索引的输入:n个文件,每个文件里有关键词
输出:若干个key(关键词):value(对应文件,且按照词频排序)
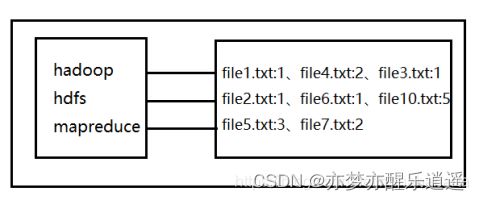
参考案例
这个里面的代码估计是hadoop2的,我对其中的一小部分进行了修改,保证可以用3.1.3运行。
在本地测试好以后就可以打包送到hadoop分布式集群上运行了,注意输入的文件要传到HDFS中。
Mapper
首先是导包问题,一定要导对。
- Mapper类,选用org.apache.hadoop.mapreduce
- Text类,选用org.apache.hadoop.io
然后是一些理解:
- Mapper类的run()函数会循环读取一条一条的key:value,调用map()函数。输出key:value。
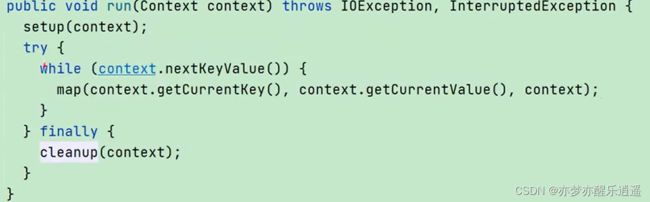
- 那这一条一条的key:value从何而来?当然是context,那context又是从何而来?当然是从split来,从split到context可迭代对象的过程,是通过一个类来设置读取方法的,当然,默认都是逐行读取的。
- context.write这个函数,将key:value写到某个地方,我的初步猜测是那个缓冲区,总之,输出是通过这个write实现的,而不是简单的return
最后给出代码:
package com.cyy.mapreduce.invertedindex;
import com.ctc.wstx.util.StringUtil;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
public class InvertedIndexMapper extends Mapper<LongWritable,Text,Text,Text>{
private static Text keyInfo=new Text();
private static final Text valueInfo=new Text("1");
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String line=value.toString();
String[] fields= StringUtils.split(line,' ');//切分
FileSplit fileSplit = (FileSplit) context.getInputSplit();//得到文件信息
String fileName=fileSplit.getPath().getName();//获取文件名
for(String field:fields){
keyInfo.set(field+":"+fileName);
context.write(keyInfo,valueInfo);
}
}
}
Combiner
可以看出,Combiner实际上是Recuder。
- reduce的输入是key:value-list。这个value-list是吧同一个key的所有value变成一个list一次性输入到一个reduce函数中,至于value-list怎么来的,还是这个牛逼的context。
- combiner的存在意义是进行分级reduce中的第一级。一个split(这里是一个文件)内key:value中必然有重复的key,所以先进行reduce,之后不同文件中还会有重复key,再进行reduce,输出结果。
package com.cyy.mapreduce.invertedindex;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class InvertedIndexCombiner extends Reducer<Text,Text,Text,Text> {
private static Text info=new Text();
@Override
protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException,InterruptedException {
int sum=0;
//计算词频
for(Text value:values){
sum+=Integer.parseInt(value.toString());
}
int splitIndex=key.toString().indexOf(":");//符号位置
//用URL(文件名)+词频作为value
info.set(key.toString().substring(splitIndex+1)+":"+sum);
//用单词作为key
key.set(key.toString().substring(0,splitIndex));
context.write(key,info);
}
}
Reducer
package com.cyy.mapreduce.invertedindex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class InvertedIndexReducer extends Reducer<Text,Text,Text,Text> {
private static Text result=new Text();
@Override
protected void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException {
//生成文档列表
String fileList = new String();
for (Text value : values) {
fileList += value.toString() + ";";
}
result.set(fileList);
context.write(key, result);
}
}
Driver
package com.cyy.mapreduce.invertedindex;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.yarn.webapp.hamlet2.Hamlet;
import org.apache.hadoop.io.Text;
import java.io.FileInputStream;
import java.io.IOException;
public class InvertedIndexDriver {
public static void main(String[] args)
throws IOException,ClassNotFoundException,InterruptedException{
//获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置jar包路径
job.setJarByClass(InvertedIndexDriver.class);
//关联计算组件
job.setMapperClass(InvertedIndexMapper.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
//设置最终输出,map和combine没有设置?
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置输入路径与输出路径
//FileInputFormat.setInputPaths(job,new Path("C:\\Programs\\Hadoop\\hadoop-3.1.3\\input"));
//FileOutputFormat.setOutputPath(job,new Path("C:\\Programs\\Hadoop\\hadoop-3.1.3\\output"));
//通过参数确定目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交job
System.exit(job.waitForCompletion(true)?0:1);
}
}
这是我一遍过的结果,看这个样子,还没有进行排序,不过影响不大。
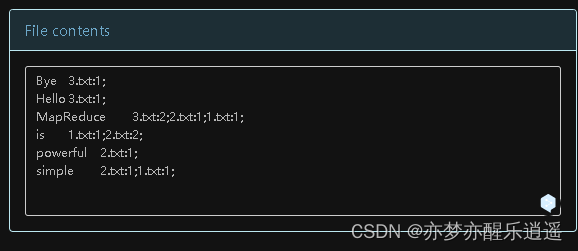
具体案例——1.4GB级别txt的倒排索引
题目描述与基本情况
数据集下载
提取码:cyyy
这是北京理工大学2020级大三学生的大数据小学期项目的实践部分。

这么大的txt,在windows本地是打不开的,我们直接上传到hdfs集群中,进行查看。这里我放到了/biginput文件夹里。
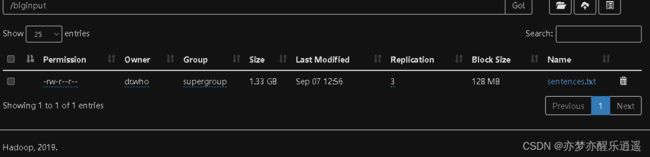
来看一眼这个文件的概况,首先文件被分成了10个块,一个128M,这比较合理,我们前面,每一个txt都有128M大小,而实际中一个txt才一点点,无疑是非常浪费空间的,而这里的一个块确确实实是塞满了,block存储方式只有在大数据的时候才能体现出优势。
看文件尾部的32K数据,发现是以一个句子编号开头,然后跟一串句子,这一整个txt文件里,大约有 1 × 1 0 7 1\times 10^{7} 1×107级别的句子,1.4G也就不稀奇了。正因为文本的重复率比较高,这1.4G才能被压缩成500M。
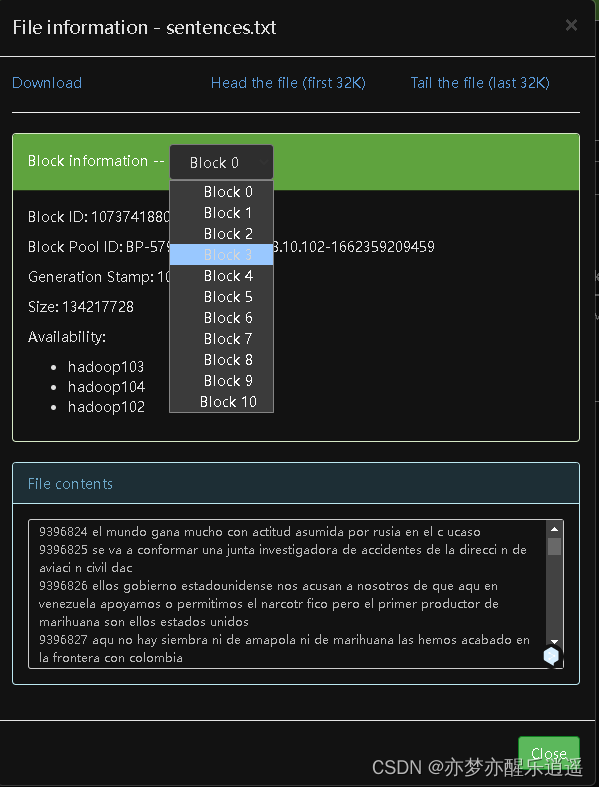
只是此处还有疑点,难道一个句子是被分成好几行的?那我怎么去切分呢?
当我尝试先把千32K的数据copy下来送到windows本地的data.txt文件里的时候,我发现原来是一行一个句子啊,那就简单了。

解题思路
扯远了,我们思考一下如何解题。
关键在于文件切割,假设文件名是简单的1.txt这种数字型的。
最直接的想法是按照10个句子(10行)一个文件来把这个大文件切分成小文件。但是我转念一想,一个小文件就要用128M的块存储,那肯定要爆炸,所以只能一次性处理这一大个文件了。
那必然就要有另外一种处理方式了。
我最初的猜想(比较晦涩,看不懂跳过也无妨):
Mapper类里我弄一个int型的counter,每调用一次map,我就把counter++,到10就清0,同时令文件名+1,其他类不需要变。
但是这里有一个问题,一个大文件是有多个split的,一个split就会有一个Map任务,对应于一个Mapper类,那这样的话,每个Mapper类中的文件名会不会重复?如果不想重复,可以选择用static,所有Mapper类共享一个文件名。但是问题又来了,这些任务是并行的,好几个并行任务同时对一个变量进行操作,且不说锁的问题,单是你这边++,他这边又++,绝对会破坏文件名的。
综上,最初的猜想是无效的。
但是,我又想到了新的办法(这个是有效的):
我直接用行号来切分就好了啊,比如0-9是一组,10-19是一组。
那如何通过行号计算出分组呢?
10以内的,x/10==0
10-100的,0
我们在32K小样本(大约前200行)上运行一下,看下结果:
首先抽样,选取file0中比较高频的两个词作为测试。
silverlight这个单词在file0中出现了3次
para这个单词在file0中出现了5次
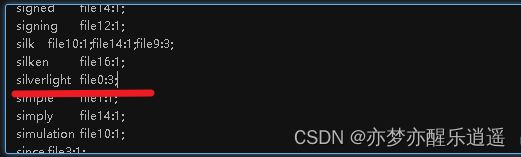

看一下file0,是否真的有5个para和3个silverlight?
这里我用红字标出,不信邪的小伙伴可以ctrl+F搜索一下,由此,这个32K的小样本就没问题了,那想必1.4G的大样本也只是时间问题以及你的内存问题,只要完整的跑完,那必然是可以的。
0 how to create property binding in a visual webgui silverlight control
1 videoplayer silverlight controls videoplayer videoplayer silverlight controls version 1 0 0 0 culture neutral publickeytoken null
2 our continuing strategic priority is to provide a safe and efficient group of airports while pursuing development opportunities which improve the air transport network serving the region
3 our results for the year demonstrate that we have delivered against these targets and ensured that our airports have continued to play a central role in the economic and social life of the highlands and islands and tayside
4 every time i visit a fishing community in scotland i am asked to take steps to protect fishing rights for future generations
5 est o lan ados os dados para que possamos ser os actores principais do nosso futuro a viagem n o terminou
6 manter a rede energizada enquanto for a pessoa indicada para o fazer
7 foi uma promessa que fiz hoje quinta feira ao presidente da rep blica que esteve presente no encontro
8 independente para que n o haja confus o com interesses privados
9 a inclus o social de outros talentos de outras partes do mundo que portugal seja um local atraente para que todos os que est o l fora queiram vir para aqui
集群部署与虚拟内存调优
那就到HDFS集群上跑一下完整的1.4G文件把!
果不其然,第一次就报错,鉴于我们上一次测试无误,所以问题肯定不在代码。
看一下日志,直接内存爆了,蚌。
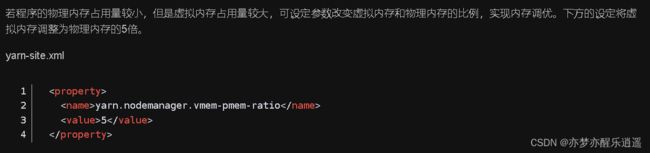
所以接下来的任务就是集群调优
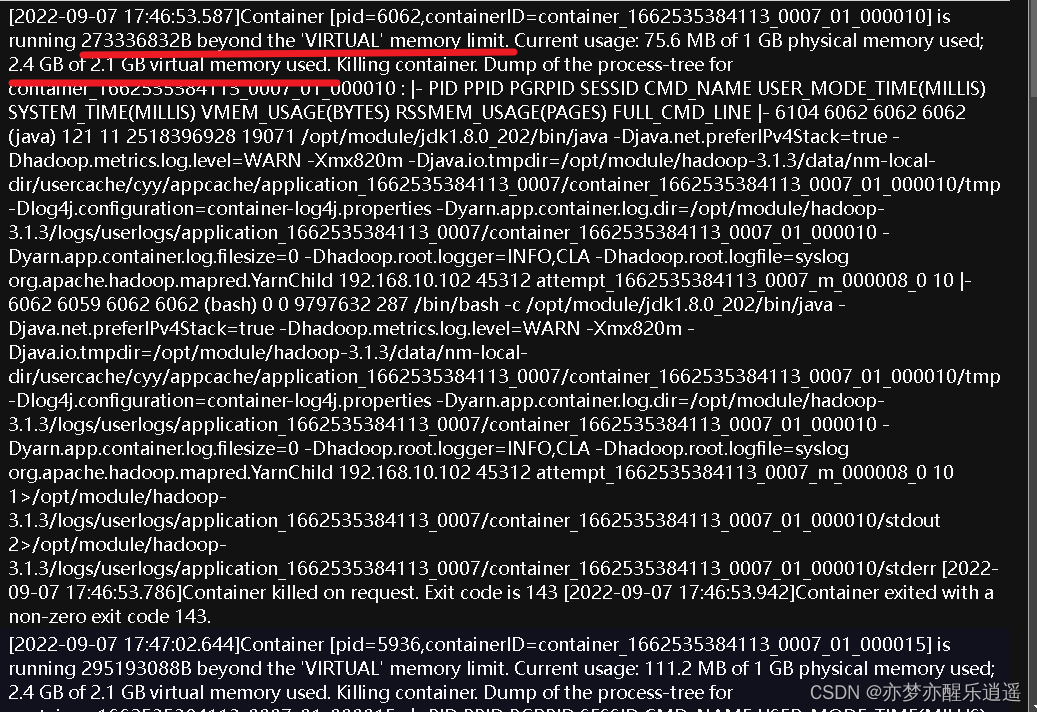
这种情况就是请求的虚拟内存超过了上限。那么我们调高虚拟内存比例,变成4,这样就可以拥有4G的虚拟内存,不会出现虚拟内存超出的错误了。
参考文章
只有在分布式环境下才会有的Bug
好继续运行,map的进度在从1%,2%,一直走,但是到了15%突然回滚成10%,之后就是走走停停,逐渐回滚,最后干脆失败了,于是又到了看日志debug的时候了!
首先看,4次失败都卡在了这里,说明这是个系统错误。

第一行,告诉你是“file920013:1”出了问题。这是最初的源头。我们往下走,第三行是Integer.parseInt()出了问题,再往下看,就是BigIndexCombiner里的17行出问题,就是这里了。
从网上查了一下,大概是value.toString里面有字符出现,导致转换失败。理论上应该是纯正的数字1。
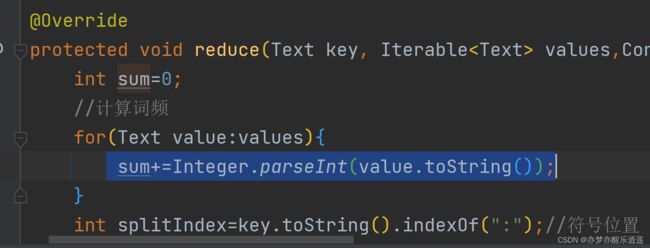
我新建了个测试类,重现一下错误场景:
很好,和我预想的一样,就是把file920013:1作为parseInt的输入出了错。
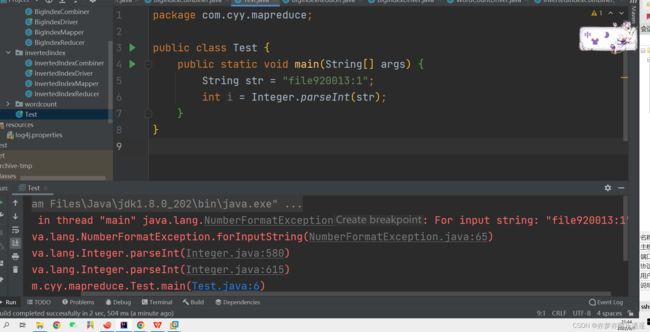
但是问题来了,为什么别的就不出错?
这就需要重新捋一下程序逻辑了,首先Mapper把单词:file数字作为key,把1作为value,在Combiner里,每次parseInt的输入都是“1”,但是这里却输入了一个"file920012:1"
正常情况下是不会错的,再加上920012差不多是第1,2个block的边界,所以我怀疑是block的问题。
于是我通过dfs系统里的block id 找到了block1和block2,至于怎么找,尚硅谷里有教。
之后就是查看信息
linux查看文件
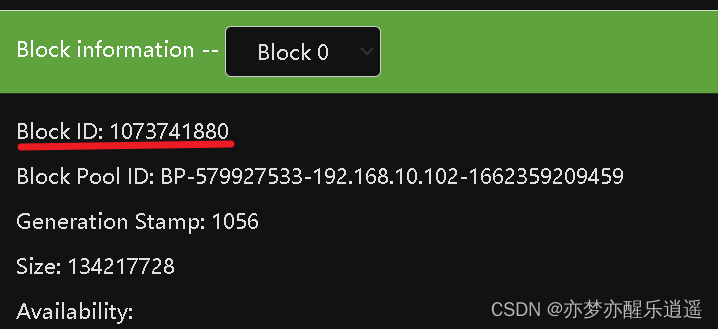
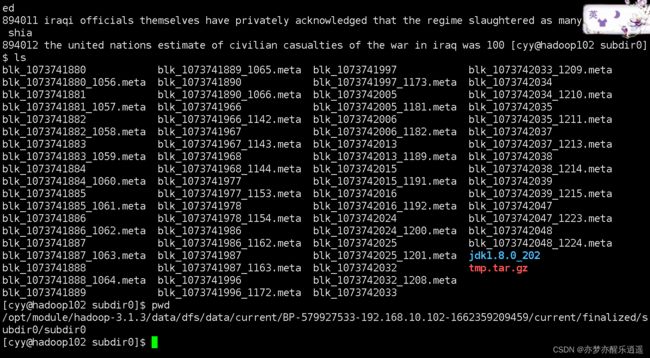
看一下block1的结尾和block2的开头
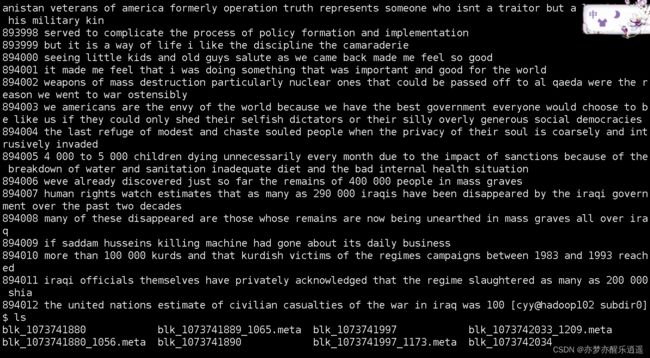
这里可以看出,block2的开头有一句话被截断了,但是这个运气比较好,正好是000,所以不会出问题。
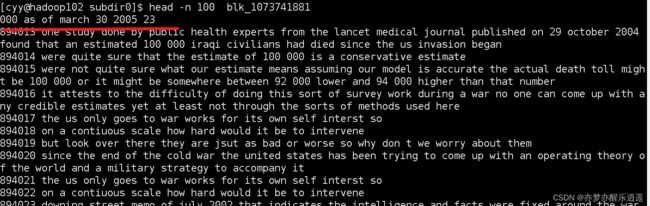
但是找到了920013这一行,我却没有发现上下文有什么问题
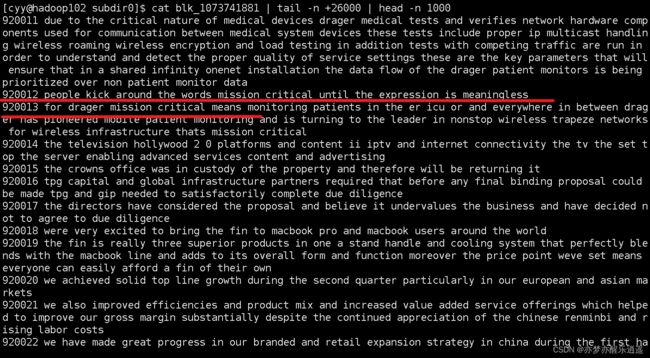
到这里有点一筹莫展了,但是既然32K的没出现问题,那说明问题只有可能出现在交界处,于是我添加了一个try catch块到Mapper里,然后放上去跑.
结果是,改了以后,我又用最后32K数据,就是被截断的数据跑了一下,结果无误,说明截断问题已经被修复。
然而,当我用修复后的代码跑大数据集地时候,还是没用,这说明除了截断以外,还有一个分布式的bug。
这就让我难蚌了,我真的不知道该怎么搞了,只能加try catch了。于是我又到了Combiner里,又在最外面加了try catch,这样终于跑通了。
如果你把这个放到机器上跑,可能还会出问题,这时就是内存不足的问题了,就这个1.4G数据集,要留12G内存才行,否则就没输出,中途崩溃(但是还不报错)
最终代码
Mapper:
package com.cyy.mapreduce.bigindex;
import com.ctc.wstx.util.StringUtil;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.StringUtils;
import java.io.IOException;
public class BigIndexMapper extends Mapper<LongWritable,Text,Text,Text>{
private static Text keyInfo=new Text();
private static final Text valueInfo=new Text("1");
private static String fileName;
@Override
protected void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
/*
key:偏移量(不是行号)
value:0 how to create property binding in a visual webgui silverlight control
words[0]是行号,其他是单词
*/
//切分
String line=value.toString();
String[] words= StringUtils.split(line,' ');
//计算文件名,这里可能出现非数字的word[0]
try{
fileName="file"+Integer.parseInt(words[0])/10;
}
catch (NumberFormatException e){
fileName="file:0";
}
/*
key: word:fileName
value : "1"
*/
for(String word:words){
keyInfo.set(word+":"+fileName);
context.write(keyInfo,valueInfo);
}
}
}
Combiner:
package com.cyy.mapreduce.bigindex;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class BigIndexCombiner extends Reducer<Text,Text,Text,Text> {
private static Text info=new Text();
@Override
protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException,InterruptedException {
//这个是为了应对parseInt的问题
try{
int sum=0;
//计算词频
for(Text value:values){
//System.out.println(key.toString()+"-"+value.toString());
sum+=Integer.parseInt(value.toString());
//sum+=1;
}
int splitIndex=key.toString().indexOf(":");//符号位置
//用URL(文件名)+词频作为value
info.set(key.toString().substring(splitIndex+1)+":"+sum);
//用单词作为key
key.set(key.toString().substring(0,splitIndex));
context.write(key,info);
}
catch (NumberFormatException e){
System.out.println(key.toString());
}
}
}
reducer:
package com.cyy.mapreduce.bigindex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class BigIndexReducer extends Reducer<Text,Text,Text,Text> {
private static Text result=new Text();
@Override
protected void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException {
//生成文档列表
String fileList = new String();
for (Text value : values) {
fileList += value.toString() + ";";
}
result.set(fileList);
context.write(key, result);
}
}
package com.cyy.mapreduce.bigindex;
import com.cyy.mapreduce.bigindex.BigIndexCombiner;
import com.cyy.mapreduce.bigindex.BigIndexDriver;
import com.cyy.mapreduce.bigindex.BigIndexMapper;
import com.cyy.mapreduce.bigindex.BigIndexReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.yarn.webapp.hamlet2.Hamlet;
import org.apache.hadoop.io.Text;
import java.io.FileInputStream;
import java.io.IOException;
public class BigIndexDriver {
public static void main(String[] args)
throws IOException,ClassNotFoundException,InterruptedException{
//获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//设置jar包路径
job.setJarByClass(BigIndexDriver.class);
//关联计算组件
job.setMapperClass(BigIndexMapper.class);
job.setCombinerClass(BigIndexCombiner.class);
job.setReducerClass(BigIndexReducer.class);
//设置最终输出,map和combine没有设置?
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置输入路径与输出路径
//FileInputFormat.setInputPaths(job,new Path("C:\\Programs\\Hadoop\\hadoop-3.1.3\\input"));
//FileOutputFormat.setOutputPath(job,new Path("C:\\Programs\\Hadoop\\hadoop-3.1.3\\output"));
//通过参数确定目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//提交job
System.exit(job.waitForCompletion(true)?0:1);
/*
结果检验:
para file0:5;
silverlight file0:3;
经过ctrl+F的搜索,结果表示正确
文件信息:file0:
0 how to create property binding in a visual webgui silverlight control
1 videoplayer silverlight controls videoplayer videoplayer silverlight controls version 1 0 0 0 culture neutral publickeytoken null
2 our continuing strategic priority is to provide a safe and efficient group of airports while pursuing development opportunities which improve the air transport network serving the region
3 our results for the year demonstrate that we have delivered against these targets and ensured that our airports have continued to play a central role in the economic and social life of the highlands and islands and tayside
4 every time i visit a fishing community in scotland i am asked to take steps to protect fishing rights for future generations
5 est o lan ados os dados para que possamos ser os actores principais do nosso futuro a viagem n o terminou
6 manter a rede energizada enquanto for a pessoa indicada para o fazer
7 foi uma promessa que fiz hoje quinta feira ao presidente da rep blica que esteve presente no encontro
8 independente para que n o haja confus o com interesses privados
9 a inclus o social de outros talentos de outras partes do mundo que portugal seja um local atraente para que todos os que est o l fora queiram vir para aqui
*/
}
}