python自动创建sqlserver表并上传dataframe到创建的表中
现有sqlserver表一张 如下图显示
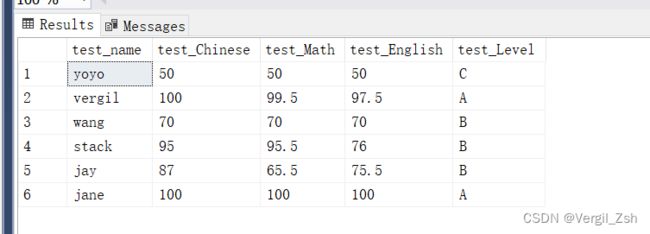
现在要求是 把所有.5的数都加上0.5 然后 将Chinses、Math、English三个数相加除以平均数,根据平均数重新定义等级,并且存到名为test_object的表中
步骤:
1.使用python连接数据库,并从中取该取的数据
2.转换成dataframe并进行处理
3.将处理好的dataframe存入到sqlserver中去
这里需要声明一下,其中会碰到的错误或者做法不妥当的地方 我会直接在文章中写出 并举例出来
提前声明下,取数和最后存入数据库中两个的连接方法是不一样的
一个是pyodc.connect()
一个是create_engine()后续加以说明
直接开始代码 代码中我会尽可能详细的备注 以备你们可以看到 有不理解的地方也可以@我 只要看到会立即回复
# 因为处理的数据并不难,而且使用的方法也比较简单 所以只创建一个类
import pandas
import pandas as pd
import numpy as np
import pyodbc, pymssql, json
from sqlalchemy import types
from sqlalchemy import create_engine
class SqlObj(object):
def __init__(self):
self.server = None
self.database = None
# 从数据库中取数
def get_data_from_sql(self):
# 连接数据库Server={服务器名称} Database={数据库名称}
conn = pyodbc.connect(r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connection=yes;')
# 创建游标
cursor = conn.cursor()
# 写下数据库语言 取数
sqlStr = 'select test_name, test_Chinese, test_Math, test_English from [数据库名].[表名]'
# 加try:except 会返回哪里错误以便后续查找
try:
a = cursor.execute(sqlStr)
data = a.fetchall()
print(data)
print(type(data))
except Exception as e:
print('出错内容:', e)
# 设置回滚(如果出错的话)
conn.rollback()
finally:
# 成功的话 关闭连接
conn.close()
return data
if __name__ == '__main__':
cc = SqlObj()
cc.get_data_from_sql()
![]()
接下来是第一步处理数据,可以将tuple返回为list,然后使用pd.DataFrame()直接处理为dataframe类型
class SqlObj(object):
def __init__(self):
self.server = None
self.database = None
# 从数据库中取数
def get_data_from_sql(self):
# 连接数据库Server={服务器名称} Database={数据库名称}
conn = pyodbc.connect(r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connection=yes;')
# 创建游标
cursor = conn.cursor()
# 写下数据库语言 取数
sqlStr = 'select test_name, test_Chinese, test_Math, test_English from [数据库名].[表名]'
# 加try:except 会返回哪里错误以便后续查找
try:
a = cursor.execute(sqlStr)
data = a.fetchall()
except Exception as e:
print('出错内容:', e)
# 设置回滚(如果出错的话)
conn.rollback()
finally:
# 成功的话 关闭连接
conn.close()
return data
# 处理数据
def handle_sql_data(self):
column_name = ['test_name', 'test_Chinese', 'test_Math', 'test_English']
# 因为上面return data 所以下面我们可以直接调用SqlObj().get_data_from_sql()进行上一个方法的返回值 也就是tuple的那个
data = SqlObj().get_data_from_sql()
print('调用get_data_from_sql:', data)
# 列表推导式 将tuple()全部转换为list
data = [list(i) for i in data]
print('列表推导式之后:', data)
df = pd.DataFrame(data, columns=column_name)
print('转换为dataframe:', df)
print(df)
print('----------')
print('输出类型:', type(df))
return df
if __name__ == '__main__':
cc = SqlObj()
cc.handle_sql_data()

第二步处理数据 按照要求所有为.5的数据加上0.5 并去三个平均数 重新划分等级
import pandas
import pandas as pd
import pyodbc, pymssql, json
from sqlalchemy import types
from sqlalchemy import create_engine
class SqlObj(object):
def __init__(self):
self.server = None
self.database = None
# 从数据库中取数
def get_data_from_sql(self):
# 连接数据库Server={服务器名称} Database={数据库名称}
conn = pyodbc.connect(r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connection=yes;')
# 创建游标
cursor = conn.cursor()
# 写下数据库语言 取数
sqlStr = 'select test_name, test_Chinese, test_Math, test_English from [数据库名].[表名]'
# 加try:except 会返回哪里错误以便后续查找
try:
a = cursor.execute(sqlStr)
data = a.fetchall()
except Exception as e:
print('出错内容:', e)
# 设置回滚(如果出错的话)
conn.rollback()
finally:
# 成功的话 关闭连接
conn.close()
return data
# 处理数据
def handle_sql_data(self):
column_name = ['test_name', 'test_Chinese', 'test_Math', 'test_English']
data = SqlObj().get_data_from_sql()
data = [list(i) for i in data]
df = pd.DataFrame(data, columns=column_name)
return df
def handle_df(self):
# 直接从handle_sql_data返回dataframe
df = SqlObj().handle_sql_data()
print('未修改之前的数据:\n',df)
# 所有数据为0.5的数据+0.5
def plus_(i):
if '.5' in str(i):
return i+0.5
else:
return i
for i in df.columns.tolist()[1:]:
df[i] = df[i].apply(plus_)
print('+0.5之后:\n',df)
#划分等级
def changle_level(x,y,z):
if (x+y+z) / 3 < 60:
return 'D'
elif (x+y+z) / 3 < 70:
return 'C'
elif (x+y+z) / 3 < 80:
return 'B'
else:
return 'A'
# 使用的是apply函数
# 如果有不太懂得可以问我 也可以查看我的博客有一节是专门将pandas apply函数的
df['test_level'] = df.apply(lambda row: changle_level(row['test_Chinese'], row['test_Math'], row['test_English']), axis=1)
print('划分等级后:\n', df)
return df
if __name__ == '__main__':
cc = SqlObj()
cc.handle_df()
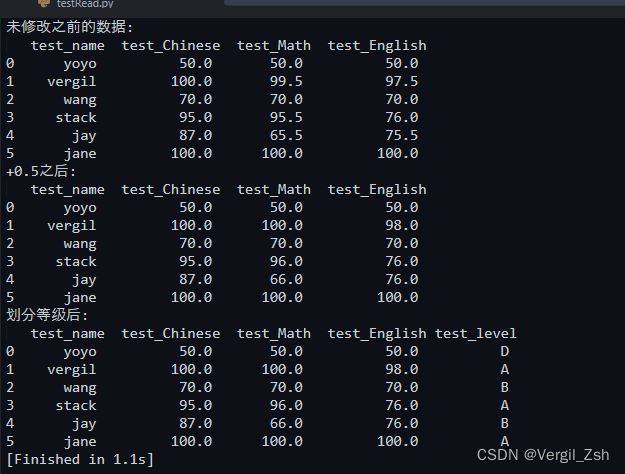
接下来就是最后一步上传到数据库中
切记一点这个方法是可以不用提前创建数据表,可以直接上传的时候创建数据表,需要注意的是提前要设置好上传类型,
网上有一部分是需要提前创建数据表,但是会产生一个比较难缠的东西就是创建表的时候 会以本地电脑名的前缀作为表的db
如下图显示

下面的就是本地电脑名,而本应该是dbo.开始,所以不建议先创建表
一 使用的函数是
df.to_sql(name='表名', if_exists='append', schema='dbo', con=conn, index=False, dtype=dict)
to_sql为pandas自带的函数,这里不多讲述,可以在官网上进行查看或者查看其他作者的博客,因为没来的更新(尴尬),请原谅
讲下dtype这个参数,可以看到dtype=dict是用来说名后面需是一个字典类型的值,并且是要使用type.()完成创建,下面会有演示
最重要的就是schema这个参数,设置这个参数的值为’dbo’可以解决上述截图的那个问题,不然会直接上传到电脑本地名的那个表中
import pandas
import pandas as pd
import pyodbc, pymssql, json
from sqlalchemy import types
from sqlalchemy import create_engine
class SqlObj(object):
def __init__(self):
self.server = None
self.database = None
# 从数据库中取数
def get_data_from_sql(self):
# 连接数据库Server={服务器名称} Database={数据库名称}
conn = pyodbc.connect(r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connection=yes;')
# 创建游标
cursor = conn.cursor()
# 写下数据库语言 取数
sqlStr = 'select test_name, test_Chinese, test_Math, test_English from [数据库名].[表名]'
# 加try:except 会返回哪里错误以便后续查找
try:
a = cursor.execute(sqlStr)
data = a.fetchall()
except Exception as e:
print('出错内容:', e)
# 设置回滚(如果出错的话)
conn.rollback()
finally:
# 成功的话 关闭连接
conn.close()
return data
# 处理数据
def handle_sql_data(self):
column_name = ['test_name', 'test_Chinese', 'test_Math', 'test_English']
data = SqlObj().get_data_from_sql()
data = [list(i) for i in data]
df = pd.DataFrame(data, columns=column_name)
return df
def handle_df(self):
# 直接从handle_sql_data返回dataframe
df = SqlObj().handle_sql_data()
# 所有数据为0.5的数据+0.5
def plus_(i):
if '.5' in str(i):
return i+0.5
else:
return i
for i in df.columns.tolist()[1:]:
df[i] = df[i].apply(plus_)
#划分等级
def changle_level(x,y,z):
if (x+y+z) / 3 < 60:
return 'D'
elif (x+y+z) / 3 < 70:
return 'C'
elif (x+y+z) / 3 < 80:
return 'B'
else:
return 'A'
df['test_level'] = df.apply(lambda row: changle_level(row['test_Chinese'], row['test_Math'], row['test_English']), axis=1)
return df
def return_dtypes(self):
# 从SqlObj().handle_df()返回df 并命名为data
data = SqlObj().handle_df()
# 取第一行的值
list_data = data.iloc[0,0:]
print('第一行的值为Series:\n', list_data)
print('--------------------------------')
# 因为是Series 所以我们可以取出index和values
# 这个是灵活运用的 实际情况看实际情况而定
index_ = list_data.index.tolist()
print('index的值:\n', index_)
print('--------------------------')
values_ = list_data.values.tolist()
print('values_的值:\n', values_)
# 因为函数to_sql,dtype参数是需要字典类型,所以我们创建好dict_,并进行写入
dict_ = {}
for i in range(len(index_)):
if type(values_[i]) == str:
dict_[index_[i]] = types.NVARCHAR(length=255)
else:
dict_[index_[i]] = types.Float()
print('返回的dtype参数字典数据:\n',dict_)
return dict_
if __name__ == '__main__':
cc = SqlObj()
cc.return_dtypes()
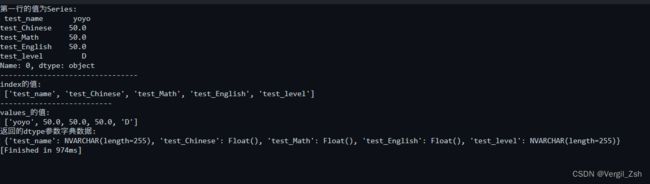
特别需要注意下最后一行输出的,就是我们的列名: 需要上传到数据库的类型
还有datetime、bigint、nvarchar(‘MAX’)等等 视情况而定,主要用到的库是from sqlalchemy import types
网上如果要查看其他类型可以搜索这个就可以看到其他类型
最后一步上传到数据库
import pandas
import pandas as pd
import pyodbc, pymssql, json
from sqlalchemy import types
from sqlalchemy import create_engine
class SqlObj(object):
def __init__(self):
self.server = None
self.database = None
# 从数据库中取数
def get_data_from_sql(self):
# 连接数据库Server={服务器名称} Database={数据库名称}
conn = pyodbc.connect(r'Driver={SQL Server};Server=服务器名;Database=数据库名;Trusted_Connection=yes;')
# 创建游标
cursor = conn.cursor()
# 写下数据库语言 取数
sqlStr = 'select test_name, test_Chinese, test_Math, test_English from [数据库名].[表名]'
# 加try:except 会返回哪里错误以便后续查找
try:
a = cursor.execute(sqlStr)
data = a.fetchall()
except Exception as e:
print('出错内容:', e)
# 设置回滚(如果出错的话)
conn.rollback()
finally:
# 成功的话 关闭连接
conn.close()
return data
# 处理数据
def handle_sql_data(self):
column_name = ['test_name', 'test_Chinese', 'test_Math', 'test_English']
data = SqlObj().get_data_from_sql()
data = [list(i) for i in data]
df = pd.DataFrame(data, columns=column_name)
return df
def handle_df(self):
# 直接从handle_sql_data返回dataframe
df = SqlObj().handle_sql_data()
# 所有数据为0.5的数据+0.5
def plus_(i):
if '.5' in str(i):
return i+0.5
else:
return i
for i in df.columns.tolist()[1:]:
df[i] = df[i].apply(plus_)
#划分等级
def changle_level(x,y,z):
if (x+y+z) / 3 < 60:
return 'D'
elif (x+y+z) / 3 < 70:
return 'C'
elif (x+y+z) / 3 < 80:
return 'B'
else:
return 'A'
df['test_level'] = df.apply(lambda row: changle_level(row['test_Chinese'], row['test_Math'], row['test_English']), axis=1)
return df
def return_dtypes(self):
# 从SqlObj().handle_df()返回df 并命名为data
data = SqlObj().handle_df()
# 取第一行的值
list_data = data.iloc[0,0:]
# 因为是Series 所以我们可以取出index和values
# 这个是灵活运用的 实际情况看实际情况而定
index_ = list_data.index.tolist()
values_ = list_data.values.tolist()
# 因为函数to_sql,dtype参数是需要字典类型,所以我们创建好dict_,并进行写入
dict_ = {}
for i in range(len(index_)):
if type(values_[i]) == str:
dict_[index_[i]] = types.NVARCHAR(length=255)
else:
dict_[index_[i]] = types.Float()
return dict_
def concat_tables(self):
# 调用SqlObj().handle_df()返回最终的df
data = SqlObj().handle_df()
print('最终数据:\n', data)
print('-------------------------------------')
# 返回提前设置好的字典类型
dict1 = SqlObj().return_dtypes()
print('最终需要上传到数据库的数据类型指定:\n', dict1)
conn = create_engine('mssql+pymssql://服务器名/数据库名')
# cursor = conn.cursor()
data.to_sql(name='test_object', if_exists='append', schema='dbo', con=conn, index=False, dtype=dict1)
# 关闭数据库
conn.dispose()
if __name__ == '__main__':
cc = SqlObj()
cc.return_dtypes()
啰嗦几句 if_exists有三个值分别是’fail’,'append’还有一个忘了 具体用法请查看官网
conn.dispose()因为连接方法不同所有关闭也不同,不同与上面的conn.close(),所以需要特别注意下
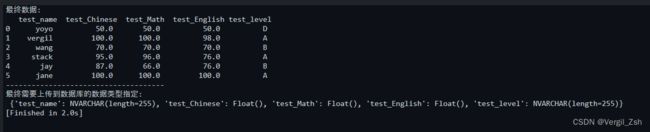
![]()
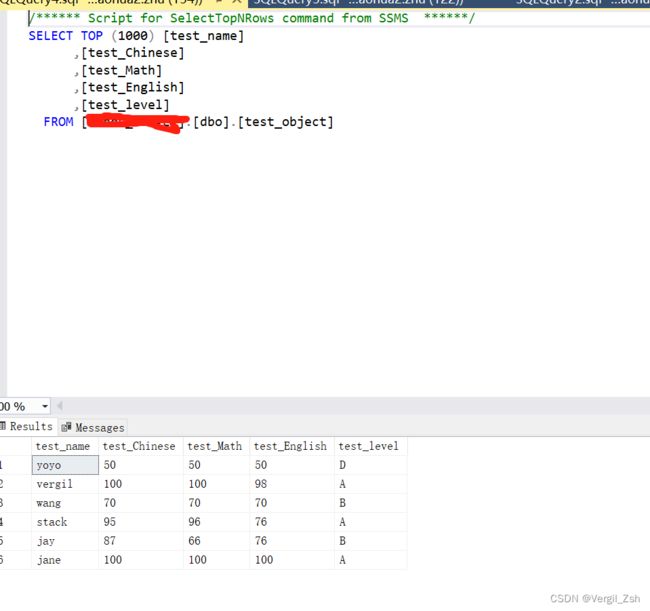
这个就是上传成功后的
如果有哪里不太清楚 或者方法不简便的 可以随时和我沟通 谢谢!!!