datax-osswriter代码解析
osswriter解析
首先我们先查看一下osswriter插件的目录,有个具体的印象

目录下面的doc文件就是osswriter的markdown文档,可以先阅读一下。
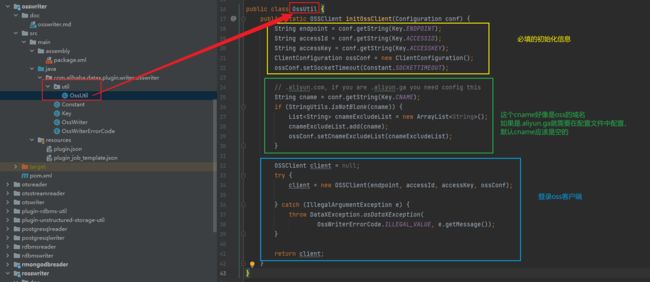
然后在src/main目录下面有assembly文件夹和java文件夹,assembly里面是打包的xml可以不用管,主要看java文件夹里面的代码里面有个util文件下面的ossutil主要用于初始化oss的客户端
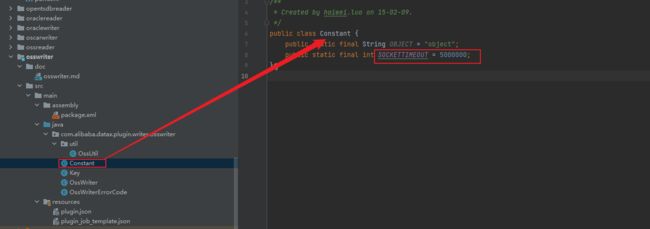
constant文件主要用于记录一些固定的常量,比如刚刚上面初始化oss客户端的超时时间
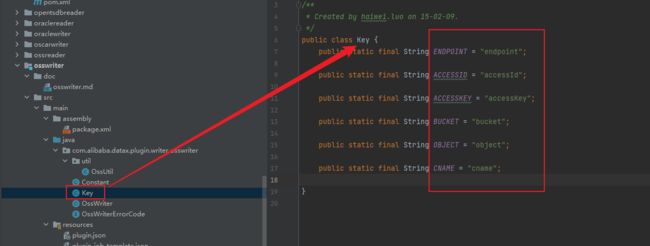
key文件主要用于记录一些oss重要的关键字
OssWriterErrorCode文件主要用于存放报错日志信息函数返回

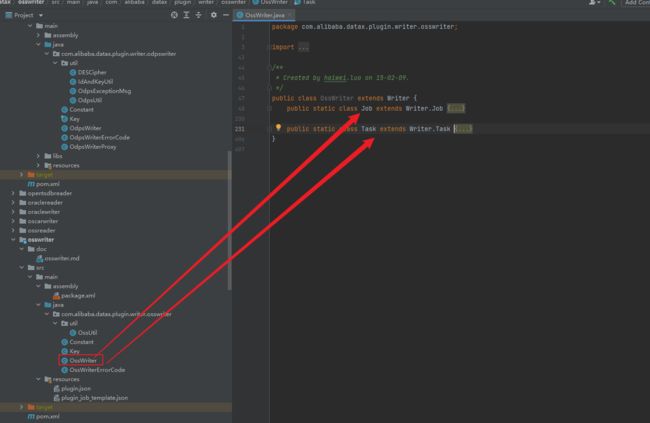
ossWriter
osswriter文件主要有job和task两个类,其中job主要任务是验证配置文件数据,根据配置文件准备数据,然后进行分割数据等等,task主要任务是初始化客户端以及配置什么的,然后写入oss
Job接口功能如下:
init: Job对象初始化工作,此时可以通过super.getPluginJobConf()获取与本插件相关的配置。读插件获得配置中reader部分,写插件获得writer部分。prepare: 全局准备工作,比如odpswriter清空目标表。split: 拆分Task。参数adviceNumber框架建议的拆分数,一般是运行时所配置的并发度。值返回的是Task的配置列表。post: 全局的后置工作,比如mysqlwriter同步完影子表后的rename操作。destroy: Job对象自身的销毁工作。
Task接口功能如下:
init:Task对象的初始化。此时可以通过super.getPluginJobConf()获取与本Task相关的配置。这里的配置是Job的split方法返回的配置列表中的其中一个。prepare:局部的准备工作。startRead: 从数据源读数据,写入到RecordSender中。RecordSender会把数据写入连接Reader和Writer的缓存队列。startWrite:从RecordReceiver中读取数据,写入目标数据源。RecordReceiver中的数据来自Reader和Writer之间的缓存队列。post: 局部的后置工作。destroy: Task象自身的销毁工作。
需要注意的是:
Job和Task之间一定不能有共享变量,因为分布式运行时不能保证共享变量会被正确初始化。两者之间只能通过配置文件进行依赖。prepare和post在Job和Task中都存在,插件需要根据实际情况确定在什么地方执行操作。
框架按照如下的顺序执行Job和Task的接口:

上图中,黄色表示Job部分的执行阶段,蓝色表示Task部分的执行阶段,绿色表示框架执行阶段。
相关类关系如下:

job中的split函数将需要传输的数据分组
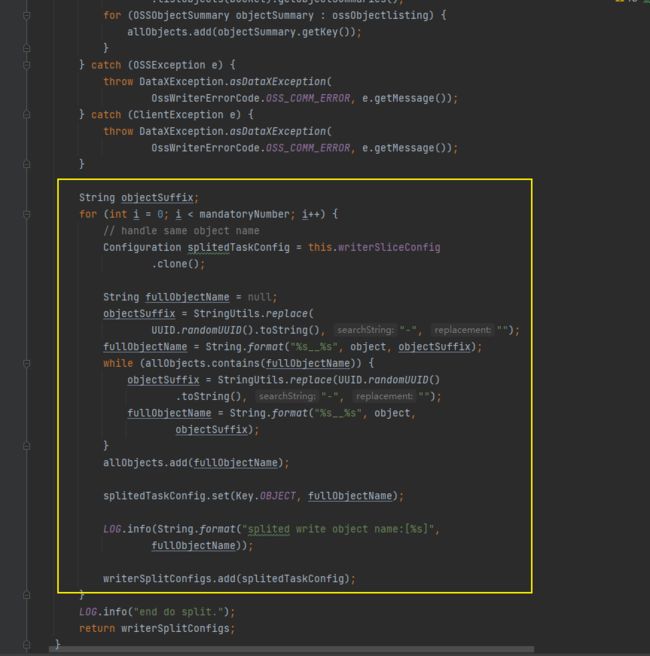
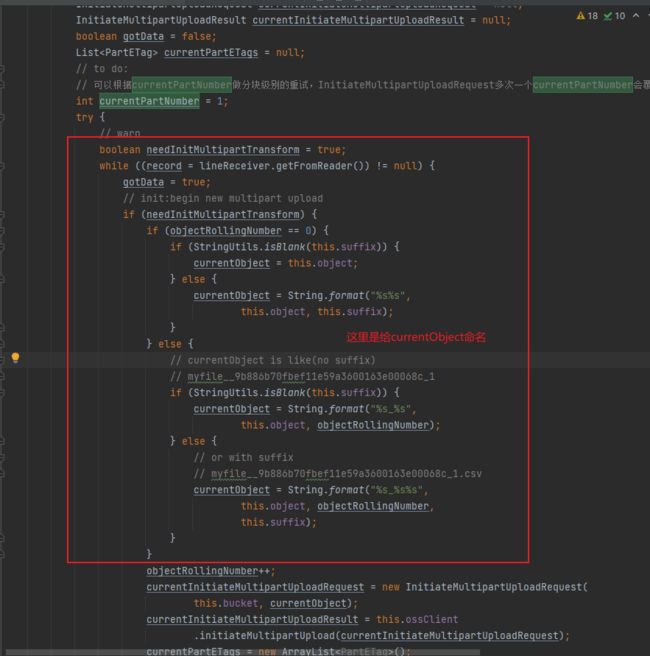
task中的startWrite函数解析:
// 设置每块字符串长度
final long partSize = 1024 * 1024 * 10L;
// 就是文件大小除十
long numberCacul = (this.maxFileSize * 1024 * 1024L) / partSize;
// 看这个是否大于1,若大于1就是其本身,否则就是1
final long maxPartNumber = numberCacul >= 1 ? numberCacul : 1;
// todo 后面再看
int objectRollingNumber = 0;
// 写入
StringWriter sw = new StringWriter();
// 写入缓存
StringBuffer sb = sw.getBuffer();
// 无结构写入
UnstructuredWriter unstructuredWriter = TextCsvWriterManager
.produceUnstructuredWriter(this.fileFormat,
this.fieldDelimiter, sw);
// todo 后面再看
Record record = null;
// 进度日志
LOG.info(String.format(
"begin do write, each object maxFileSize: [%s]MB...",
maxPartNumber * 10));
// 当前的对象
String currentObject = this.object;
// 多部分上传请求
InitiateMultipartUploadRequest currentInitiateMultipartUploadRequest = null;
// 多部分上传结果
InitiateMultipartUploadResult currentInitiateMultipartUploadResult = null;
// 判断当前是否获取了数据
boolean gotData = false;
// 当前分组的名称
List<PartETag> currentPartETags = null;
// 当前分组数
int currentPartNumber = 1;
// 下面就是写入的逻辑了




uploadOnePart函数解析
/**
* 对于同一个UploadID,该号码不但唯一标识这一块数据,也标识了这块数据在整个文件内的相对位置。
* 如果你用同一个part号码,上传了新的数据,那么OSS上已有的这个号码的Part数据将被覆盖。
*
* @throws Exception
* */
private void uploadOnePart(
final StringWriter sw,
final int partNumber,
final InitiateMultipartUploadResult initiateMultipartUploadResult,
final List<PartETag> partETags, final String currentObject)
throws Exception {
final String encoding = this.encoding;
final String bucket = this.bucket;
final OSSClient ossClient = this.ossClient;
RetryUtil.executeWithRetry(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
byte[] byteArray = sw.toString().getBytes(encoding);
InputStream inputStream = new ByteArrayInputStream(
byteArray);
// 创建UploadPartRequest,上传分块
UploadPartRequest uploadPartRequest = new UploadPartRequest();
uploadPartRequest.setBucketName(bucket);
uploadPartRequest.setKey(currentObject);
uploadPartRequest.setUploadId(initiateMultipartUploadResult
.getUploadId());
uploadPartRequest.setInputStream(inputStream);
uploadPartRequest.setPartSize(byteArray.length);
uploadPartRequest.setPartNumber(partNumber);
UploadPartResult uploadPartResult = ossClient
.uploadPart(uploadPartRequest);
partETags.add(uploadPartResult.getPartETag());
LOG.info(String
.format("upload part [%s] size [%s] Byte has been completed.",
partNumber, byteArray.length));
IOUtils.closeQuietly(inputStream);
return true;
}
}, 3, 1000L, false);
ossWriter魔改版
ossWriter魔改版——解决了按字段自动分区的问题
在job阶段不拆分数据
到task阶段把数据按照字段和配置分区上传
这样就解决了
源码:
package com.alibaba.datax.plugin.writer.rosswriter;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringWriter;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.*;
import java.util.concurrent.atomic.AtomicLong;
import com.alibaba.datax.common.element.Column;
import com.alibaba.datax.common.util.StrUtil;
import com.alibaba.datax.common.util.XDateUtils;
import com.alibaba.datax.plugin.unstructuredstorage.writer.Constant;
import com.aliyun.oss.model.*;
import org.apache.commons.io.IOUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.DateFormatUtils;
import org.apache.commons.lang3.time.DateUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.alibaba.datax.common.element.Record;
import com.alibaba.datax.common.exception.DataXException;
import com.alibaba.datax.common.plugin.RecordReceiver;
import com.alibaba.datax.common.spi.Writer;
import com.alibaba.datax.common.util.Configuration;
import com.alibaba.datax.common.util.RetryUtil;
import com.alibaba.datax.plugin.unstructuredstorage.writer.TextCsvWriterManager;
import com.alibaba.datax.plugin.unstructuredstorage.writer.UnstructuredStorageWriterUtil;
import com.alibaba.datax.plugin.unstructuredstorage.writer.UnstructuredWriter;
import com.alibaba.datax.plugin.writer.rosswriter.util.OssUtil;
import com.aliyun.oss.ClientException;
import com.aliyun.oss.OSSClient;
import com.aliyun.oss.OSSException;
import static com.alibaba.datax.plugin.unstructuredstorage.writer.Constant.*;
/**
ossWriter魔改版——解决了按字段自动分区的问题
在job阶段不拆分数据
到task阶段把数据按照字段和配置分区上传
这样就解决了
*/
public class OssWriter extends Writer {
public static class Job extends Writer.Job {
private static final Logger LOG = LoggerFactory.getLogger(Job.class);
private Configuration writerSliceConfig = null;
private OSSClient ossClient = null;
@Override
public void init() {
this.writerSliceConfig = this.getPluginJobConf();
this.validateParameter();
this.ossClient = OssUtil.initOssClient(this.writerSliceConfig);
}
private void validateParameter() {
this.writerSliceConfig.getNecessaryValue(Key.ENDPOINT, OssWriterErrorCode.REQUIRED_VALUE);
this.writerSliceConfig.getNecessaryValue(Key.ACCESSID, OssWriterErrorCode.REQUIRED_VALUE);
this.writerSliceConfig.getNecessaryValue(Key.ACCESSKEY, OssWriterErrorCode.REQUIRED_VALUE);
this.writerSliceConfig.getNecessaryValue(Key.BUCKET, OssWriterErrorCode.REQUIRED_VALUE);
this.writerSliceConfig.getNecessaryValue(Key.OBJECT, OssWriterErrorCode.REQUIRED_VALUE);
// warn: do not support compress!!
String compress = this.writerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.COMPRESS);
if (StringUtils.isNotBlank(compress)) {
String errorMessage = String.format("OSS写暂时不支持压缩, 该压缩配置项[%s]不起效用", compress);
LOG.error(errorMessage);
throw DataXException.asDataXException(OssWriterErrorCode.ILLEGAL_VALUE, errorMessage);
}
UnstructuredStorageWriterUtil.validateParameter(this.writerSliceConfig);
}
@Override
public void prepare() {
LOG.info("begin do prepare...");
String bucket = this.writerSliceConfig.getString(Key.BUCKET);
String object = this.writerSliceConfig.getString(Key.OBJECT);
String writeMode = this.writerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.WRITE_MODE);
// warn: bucket is not exists, create it
try {
// warn: do not create bucket for user
if (!this.ossClient.doesBucketExist(bucket)) {
// this.ossClient.createBucket(bucket);
String errorMessage = String.format("您配置的bucket [%s] 不存在, 请您确认您的配置项.", bucket);
LOG.error(errorMessage);
throw DataXException.asDataXException(OssWriterErrorCode.ILLEGAL_VALUE, errorMessage);
}
LOG.info(String.format("access control details [%s].", this.ossClient.getBucketAcl(bucket).toString()));
// truncate option handler
if ("truncate".equals(writeMode)) {
LOG.info(String.format("由于您配置了writeMode truncate, 开始清理 [%s] 下面以 [%s] 开头的Object", bucket, object));
// warn: 默认情况下,如果Bucket中的Object数量大于100,则只会返回100个Object
while (true) {
ObjectListing listing = null;
LOG.info("list objects with listObject(bucket, object)");
listing = this.ossClient.listObjects(bucket, object);
List<OSSObjectSummary> objectSummarys = listing.getObjectSummaries();
for (OSSObjectSummary objectSummary : objectSummarys) {
LOG.info(String.format("delete oss object [%s].", objectSummary.getKey()));
this.ossClient.deleteObject(bucket, objectSummary.getKey());
}
if (objectSummarys.isEmpty()) {
break;
}
}
} else if ("append".equals(writeMode)) {
LOG.info(String.format("由于您配置了writeMode append, 写入前不做清理工作, 数据写入Bucket [%s] 下, 写入相应Object的前缀为 [%s]", bucket, object));
} else if ("nonConflict".equals(writeMode)) {
LOG.info(String.format("由于您配置了writeMode nonConflict, 开始检查Bucket [%s] 下面以 [%s] 命名开头的Object", bucket, object));
ObjectListing listing = this.ossClient.listObjects(bucket, object);
if (0 < listing.getObjectSummaries().size()) {
StringBuilder objectKeys = new StringBuilder();
objectKeys.append("[ ");
for (OSSObjectSummary ossObjectSummary : listing.getObjectSummaries()) {
objectKeys.append(ossObjectSummary.getKey() + " ,");
}
objectKeys.append(" ]");
LOG.info(String.format("object with prefix [%s] details: %s", object, objectKeys.toString()));
throw DataXException.asDataXException(OssWriterErrorCode.ILLEGAL_VALUE, String.format("您配置的Bucket: [%s] 下面存在其Object有前缀 [%s].", bucket, object));
}
}
} catch (OSSException e) {
throw DataXException.asDataXException(OssWriterErrorCode.OSS_COMM_ERROR, e.getMessage());
} catch (ClientException e) {
throw DataXException.asDataXException(OssWriterErrorCode.OSS_COMM_ERROR, e.getMessage());
}
}
@Override
public void post() {
}
@Override
public void destroy() {
}
@Override
public List<Configuration> split(int mandatoryNumber) {
LOG.info("begin do split...only need one task.");
return Arrays.asList(this.writerSliceConfig.clone());
}
}
public static class Task extends Writer.Task {
private static final Logger LOG = LoggerFactory.getLogger(Task.class);
private OSSClient ossClient;
private Configuration writerSliceConfig;
private String bucket;
private String object;
private String nullFormat;
private String encoding;
private char fieldDelimiter;
private String dateFormat;
private DateFormat dateParse;
private String fileFormat;
private List<String> header;
private Long maxFileSize;// MB
private String suffix;
public String partitionType;
public String partitionBy;
private int partitionIdx;
@Override
public void init() {
this.writerSliceConfig = this.getPluginJobConf();
this.ossClient = OssUtil.initOssClient(this.writerSliceConfig);
this.bucket = this.writerSliceConfig.getString(Key.BUCKET);
this.object = this.writerSliceConfig.getString(Key.OBJECT);
this.nullFormat = this.writerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.NULL_FORMAT);
this.dateFormat = this.writerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.DATE_FORMAT, null);
if (StringUtils.isNotBlank(this.dateFormat)) this.dateParse = new SimpleDateFormat(dateFormat);
this.encoding = this.writerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.ENCODING, com.alibaba.datax.plugin.unstructuredstorage.writer.Constant.DEFAULT_ENCODING);
this.fieldDelimiter = this.writerSliceConfig.getChar(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.FIELD_DELIMITER, com.alibaba.datax.plugin.unstructuredstorage.writer.Constant.DEFAULT_FIELD_DELIMITER);
this.fileFormat = this.writerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.FILE_FORMAT, com.alibaba.datax.plugin.unstructuredstorage.writer.Constant.FILE_FORMAT_TEXT);
this.header = this.writerSliceConfig.getList(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.HEADER, null, String.class);
this.maxFileSize = this.writerSliceConfig.getLong(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.MAX_FILE_SIZE, com.alibaba.datax.plugin.unstructuredstorage.writer.Constant.MAX_FILE_SIZE);
this.suffix = this.writerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.SUFFIX, com.alibaba.datax.plugin.unstructuredstorage.writer.Constant.DEFAULT_SUFFIX);
this.suffix = this.suffix.trim();// warn: need trim
this.partitionType = this.writerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.PARTITION_TYPE, PARTITION_TYPE_NONE);
this.partitionBy = this.writerSliceConfig.getString(com.alibaba.datax.plugin.unstructuredstorage.writer.Key.PARTITION_BY, Constant.DEFAULT_PARTITION_BY);
/*
todo revivew
这里做了字段定位分区,一般情况是用"_1"这种形式,但是如果有写header的话也可以直接写列名
header描述:Oss写出时的表头,示例['id', 'name', 'age']。
*/
if (this.partitionType != PARTITION_TYPE_NONE) {
if (StringUtils.startsWith(this.partitionBy, "_")) {
this.partitionIdx = Integer.valueOf(this.partitionBy.split("_")[1]);
} else {
if (null != this.header && !this.header.isEmpty()) {
for (int idx = 0; idx < header.size(); idx++) {
String head = header.get(idx);
if (head.equals(partitionBy)) {
partitionIdx = idx;
}
}
}
}
}
}
@Override
public void startWrite(RecordReceiver lineReceiver) {
// 设置每块字符串长度
final long partSize = 1024 * 1024 * 10L;
//warn: may be StringBuffer->StringBuilder
StringWriter sw = new StringWriter();
StringBuffer sb = sw.getBuffer();
UnstructuredWriter unstructuredWriter = TextCsvWriterManager.produceUnstructuredWriter(this.fileFormat, this.fieldDelimiter, sw);
Record record = null;
LOG.info(String.format("begin do write, each object partSize: [%s]MB...", partSize/1024/1024));
String currentObject = this.object;
boolean gotData = false; // 数据源是否有数据过来
AtomicLong position = new AtomicLong();
try {
long partitionFlag = 0L; // 分区标志
while ((record = lineReceiver.getFromReader()) != null) {
long curPartitionFlag = calPartitionFlag(record);
if (curPartitionFlag < 0) { // 异常数据
this.getTaskPluginCollector().collectDirtyRecord(record, new Exception(String.format("分区失败,记录:[%s]", record)));
continue;
}
if (partitionFlag != curPartitionFlag) {
if (gotData) {
//如果取到过数据了,那么先把buffer里的数据先传完
appendUpload(sw, currentObject, position);
sb.delete(0,sb.length());
}
gotData = true;
partitionFlag = curPartitionFlag;
// myfile/20210902/h9
currentObject = buildFileName(curPartitionFlag);
position.set(getRemoteFileLength(currentObject));
LOG.info(String.format("write to bucket: [%s] object: [%s] with oss position: [%s] curPartitionFlag is [%s]", this.bucket, currentObject, position.get(), curPartitionFlag));
// each object's header
if (null != this.header && !this.header.isEmpty()) {
unstructuredWriter.writeOneRecord(this.header);
}
// warn
}
// write: upload data to current object
UnstructuredStorageWriterUtil.transportOneRecord(record, this.nullFormat, this.dateParse, this.getTaskPluginCollector(), unstructuredWriter);
if (sb.length() >= partSize) {
appendUpload(sw, currentObject, position);
sb.setLength(0);
}
}
if (!gotData) { // 如果没有从 Receiver 里面取到数据,这时候只需要设置一下csv头就可以了
LOG.info("Receive no data from the source.");
if (null != this.header && !this.header.isEmpty()) {
unstructuredWriter.writeOneRecord(this.header);
}
}
appendUpload(sw, currentObject, position);
sb.delete(0,sb.length());
LOG.info(String.format("final object postion is:[%s]", position.get()));
} catch (IOException e) {
// 脏数据UnstructuredStorageWriterUtil.transportOneRecord已经记录,header
// 都是字符串不认为有脏数据
throw DataXException.asDataXException(OssWriterErrorCode.Write_OBJECT_ERROR, e.getMessage());
} catch (Exception e) {
throw DataXException.asDataXException(OssWriterErrorCode.Write_OBJECT_ERROR, e.getMessage());
}
LOG.info("end do write");
}
private void appendUpload(StringWriter sw, String currentObject, AtomicLong position) throws Exception {
final String curObject = currentObject;
final long positio = position.get();
RetryUtil.executeWithRetry(() -> {
byte[] byteArray = sw.toString().getBytes(encoding);
if (byteArray.length == 0) {
return true;
}
InputStream inputStream = new ByteArrayInputStream(byteArray);
AppendObjectRequest appendObjectRequest = new AppendObjectRequest(this.bucket, curObject, inputStream);
appendObjectRequest.setPosition(positio);
AppendObjectResult appendObjectResult = ossClient.appendObject(appendObjectRequest);
position.set(appendObjectResult.getNextPosition());
LOG.info(String.format("upload part [%s] size [%s] Byte has been completed.", appendObjectResult.getNextPosition(), byteArray.length));
IOUtils.closeQuietly(inputStream);
return true;
}, 3, 1000L, false);
}
private long getRemoteFileLength(String currentObject) {
long position = 0;
try {
if (this.ossClient.doesObjectExist(this.bucket, currentObject)) {
ObjectMetadata objectMetadata = this.ossClient.getObjectMetadata(this.bucket, currentObject);
position = objectMetadata.getContentLength();
}
} catch (Exception e) {
position = 0;
}
return position;
}
private String buildFileName(long curPartitionFlag) {
String objName = this.object;
switch (this.partitionType) {
case PARTITION_TYPE_NONE:
objName = this.object;
break;
case PARTITION_TYPE_DAY:
String dt = DateFormatUtils.format(new Date(curPartitionFlag), "yyyyMMdd");
objName = String.format("%s/dt=%s/d%s", this.object, dt, dt);
break;
case PARTITION_TYPE_HOUR:
Date hour = new Date(curPartitionFlag);
String dt_day = DateFormatUtils.format(hour, "yyyyMMdd");
int hours = XDateUtils.getHour(hour);
objName = String.format("%s/dt=%s%02d/h%02d", this.object, dt_day, hours, hours);
break;
}
String currentObject;
if (StringUtils.isBlank(this.suffix)) {
currentObject = objName;
} else {
currentObject = String.format("%s%s", objName, this.suffix);
}
return currentObject;
}
public long calPartitionFlag(Record record) {
switch (this.partitionType) {
case PARTITION_TYPE_NONE:
return 1;
case PARTITION_TYPE_DAY:
long partionVar = getPartionVar(record.getColumn(partitionIdx));
if (partionVar <= 0) {
return partionVar;
}
return XDateUtils.getDayBegin(new Date(partionVar)).getTime();
case PARTITION_TYPE_HOUR:
long partionVarHour = getPartionVar(record.getColumn(partitionIdx));
if (partionVarHour <= 0) {
return partionVarHour;
}
return XDateUtils.getHourBegin(new Date(partionVarHour)).getTime();
default:
return 1;
}
}
// 获取分区值
private long getPartionVar(Column column) {
try {
switch (column.getType()) {
case LONG:
case DOUBLE:
Long time = column.asLong();
int stringSize = stringSize(time);
if (stringSize == 13) { // 13为毫秒
return time;
} else if (stringSize == 10) { // 10为秒
return time * 1000;
}
return -1;
case DATE:
return column.asDate().getTime();
case STRING:
return DateUtils.parseDate(column.asString(), XDateUtils.PARSE_PATTERNS).getTime();
default:
return -1;
}
} catch (Exception e) {
LOG.info(String.format("get PartionVar err is:[%s],col:[%s]", e, column));
return -1;
}
}
public int stringSize(long x) {
long p = 10;
for (int i=1; i<19; i++) {
if (x < p)
return i;
p = 10*p;
}
return 19;
}
@Override
public void prepare() {
}
@Override
public void post() {
}
@Override
public void destroy() {
}
}
}
时间工具类
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package com.alibaba.datax.common.util;
import java.util.Calendar;
import java.util.Date;
public class XDateUtils {
public static String[] PARSE_PATTERNS = new String[]{"yyyy-MM-dd", "yyyy-MM-dd HH:mm:ss", "yyyy-MM-dd HH:mm", "yyyy-MM", "yyyy/MM/dd", "yyyy/MM/dd HH:mm:ss", "yyyy/MM/dd HH:mm", "yyyy/MM", "yyyy.MM.dd", "yyyy.MM.dd HH:mm:ss", "yyyy.MM.dd HH:mm", "yyyy.MM", "yyyyMMdd", "yyyyMMddHHmmss", "yyyyMMddHHmm", "yyyyMMddHH"};
public XDateUtils() {
}
public static Date getDayBegin(Date date) {
Calendar c = Calendar.getInstance();
c.setTime(date);
c.set(11, 0);
c.set(12, 0);
c.set(13, 0);
c.set(14, 0);
return c.getTime();
}
public static int getHour(Date date) {
Calendar c = Calendar.getInstance();
c.setTime(date);
return c.get(11);
}
public static Date getHourBegin(Date date) {
Calendar c = Calendar.getInstance();
c.setTime(date);
c.set(12, 0);
c.set(13, 0);
c.set(14, 0);
return c.getTime();
}
}
XDateUtils() {
}
public static Date getDayBegin(Date date) {
Calendar c = Calendar.getInstance();
c.setTime(date);
c.set(11, 0);
c.set(12, 0);
c.set(13, 0);
c.set(14, 0);
return c.getTime();
}
public static int getHour(Date date) {
Calendar c = Calendar.getInstance();
c.setTime(date);
return c.get(11);
}
public static Date getHourBegin(Date date) {
Calendar c = Calendar.getInstance();
c.setTime(date);
c.set(12, 0);
c.set(13, 0);
c.set(14, 0);
return c.getTime();
}
}