通过混淆矩阵计算指标的过程梳理
本文提到三点,第一是output和target怎么样形成一个混淆矩阵。第二是tensor中特定行和列的删除问题,第三是怎么通过混淆矩阵计算acc和miou的问题。
在计算miou时,老是会出现零值,导致代码运行不下去,遂记录解决问题的方案。
用来transformers代码跑了自己的六分类的数据集。有个疑问一直还没解决:语义分割时背景一定要算到类别里面去吗,这个类别该怎么处理?我的数据集并没说明这一点,我正是在这一点上出了问题。我设置num_cls为6时,总会报错:有一类超出了。设置为7就可以正常跑了,但是在混淆矩阵可以看到0这一类预测值和真实值会出现全是0的情况,导致混淆矩阵没法计算iou,global_acc,acc等指标,错误的混淆矩阵如下所示(真心求大神指点交流这个疑问)
在计算时我发现label中的出现的类别数是0-6,但是我的模型中的output类别只有1-6。反正体现在混淆矩阵上0这一类的预测和真实值是空值。我猜想0这一类应该是背景吧,然我就想了曲线救国的方式,将原始混淆矩阵中的第一行和第一列去掉,这样不会影响代码运行,当然如果我的猜想0类是背景正确的话这样计算就是ok的。(反正0值在计算中不存在意义) 我们假设这样是对的吧不然代码跑不下去,组会没法报告了 /捂脸。
我从说按照逻辑顺序记录三个阶段。第一个阶段output和target变换到合适的形式并传入到混淆矩阵部分;第二个是混淆矩阵中去掉某些行和列(这个问题困扰到了我,记录下来);第三个问题是混淆矩阵怎么计算精度。
1、output和target的变换
image, target = temp[0], temp[1] #读取target和image
image, target = image.to(device), target.to(device)
output = model(image)
confmat.update(target.flatten(), output.argmax(1).flatten())
这个地方需要注意的是最后一句。flatten很好理解,比如target.shape()=[1,32,32],经过flatten之后得到target.shape()=[1024],即32*32=1024。
output的shape=[batchsize,num_cls,32,32],首先经过argmax(1)之后shape为[batchsize,32,32].具体为什么会这样,下面说明。
1)torch.max()
两个关键词:类别和概率值
神经网络的输出是每个类别对应的概率值,要返回类别的话就需要用到将概率值与类别对应。比如经典的vgg最后一层经过softmax之后输出的每一类的概率值,比如说dog类别对应的概率值是0.3,cat类别对应的概率值是0.7.
torch.max()返回tensor数据最大值(概率值)和索引(类别),输出的值有两个参数,第一个参数是最大值(概率最大的一个),第二个参数是最大值的索引(也就是对应的类别),主要用于神经网络输出与label的匹配。
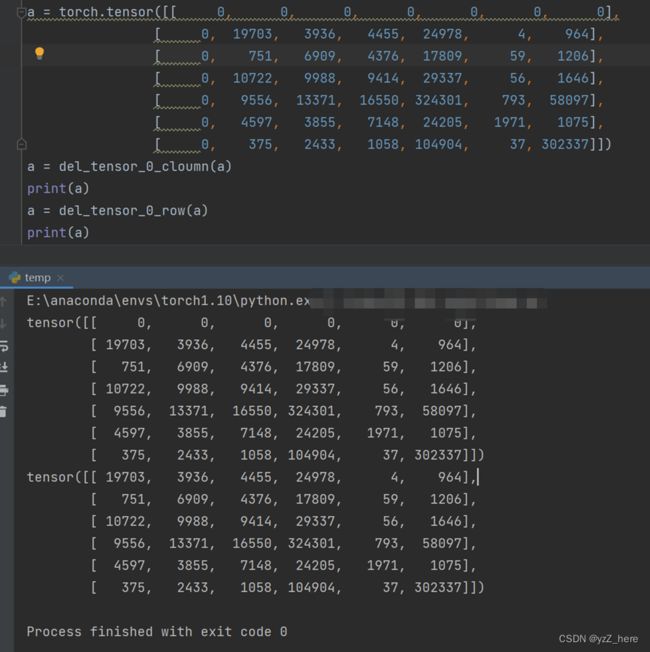
如下代码:
a = torch.tensor([[ 0, 0, 0, 0, 0, 0, 0],
[ 0, 19703, 3936, 4455, 24978, 4, 964],
[ 0, 751, 6909, 4376, 17809, 59, 1206],
[ 0, 10722, 9988, 9414, 29337, 56, 1646],
[ 0, 9556, 13371, 16550, 324301, 793, 58097],
[ 0, 4597, 3855, 7148, 24205, 1971, 1075],
[ 0, 375, 2433, 1058, 104904, 37, 302337]])
a = torch.max(a,1)
print(a)
运行结果如下图
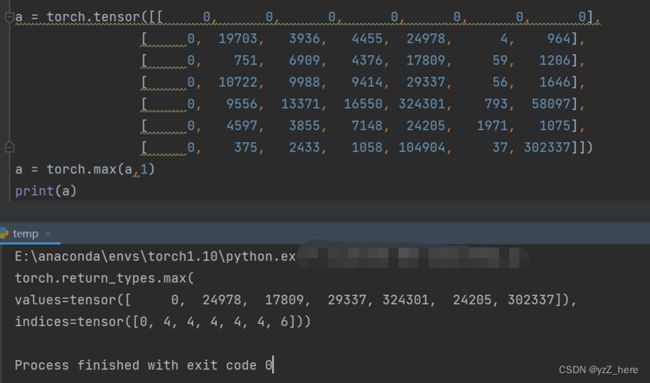
可以看到这段代码返回了两个值,一个是tensor的值,也就是概率,另一个是对应的索引值也就是类别
2)argmax()
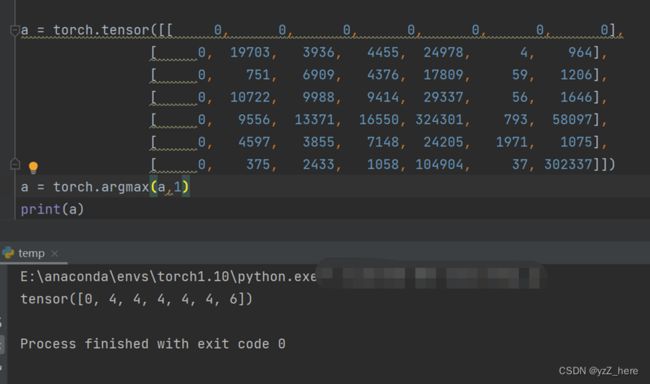
torch.argmax()的作用与前面类似,我们只想要神经网络最终的标签(类别),它输出的概率值并不关心,那么就可以直接用torch.argmax()返回tensor数据最大值的索引,运行结果如下
2、tensor(混淆矩阵)中去掉特定行和列
因为我得到的混淆矩阵中含有0值,计算指标时会出错,最开始我观察发现这个0值永远是出现在第一行和第一列,然后我就想办法怎么删除tensor中的所有全为0值的行和列,代码如下
##删除tensor中全为0的行和列
def del_tensor_0_row(Cs):
idx = torch.all(Cs[..., :] == 0, axis=1)
index=[]
for i in range(idx.shape[0]):
if not idx[i].item():
index.append(i)
index=torch.tensor(index)
Cs = torch.index_select(Cs, 0, index)
return Cs
def del_tensor_0_cloumn(Cs):
idx = torch.where(torch.all(Cs[..., :] == 0, axis=0))[0]
all = torch.arange(Cs.shape[1])
for i in range(len(idx)):
all = all[torch.arange(all.size(0))!=idx[i]-i]
Cs = torch.index_select(Cs, 1, all)
return Cs
运行结果如下
但是最重要的是我只有运行到第三个epoch的时候,第一行和第一列才会完全为零,所以上面的方法不行,我得按照索引来删除tensor中指定的行和列。所以有了下面代码删除特定行和列
代码如下
a = torch.tensor([[ 0, 0, 123, 0, 0, 0, 0],
[ 0, 19703, 3936, 4455, 24978, 4, 964],
[ 0, 751, 6909, 4376, 17809, 59, 1206],
[ 12, 10722, 9988, 9414, 29337, 56, 1646],
[ 0, 9556, 13371, 16550, 324301, 793, 58097],
[ 0, 4597, 3855, 7148, 24205, 1971, 1075],
[ 0, 375, 2433, 1058, 104904, 37, 302337]])
# print(a)
###删除特定行和列
indices = torch.tensor([1,2,3,4,5,6])
#torch.index_select中的第二个参数0或1分别表示行或列
a = torch.index_select(a, 0, indices)
a = torch.index_select(a, 1, indices)
print(a)运行结果如下
torch.index_select(a, 0, indices)中的第一个参数是原始的tensor,第二个参数是0或者1表示按照行或列索引,第三个参数表示需要留下的目标行或者目标列。

3、混淆矩阵怎么计算精度指标
语义分割中常见的指标有global_acc,acc,iou等
首先知道混淆矩阵的基本知识和上述指标计算的公式,可参考该文章语义分割之MIoU原理与实现 - 简书 (jianshu.com)。
代码如下
def update(self, a, b):
n = self.num_classes
if self.mat is None:
# 创建混淆矩阵
self.mat = torch.zeros((n, n), dtype=torch.int64, device=a.device)
with torch.no_grad():
# 寻找GT中为目标的像素索引
k = (a >= 0) & (a < n)
# 统计像素真实类别a[k]被预测成类别b[k]的个数(这里的做法很巧妙)
inds = n * a[k].to(torch.int64) + b[k]
self.mat += torch.bincount(inds, minlength=n**2).reshape(n, n)
# print(self.mat)
def reset(self):
if self.mat is not None:
self.mat.zero_()
def compute(self):
h = self.mat.float()
h = h.cpu()
indices = torch.tensor([1, 2, 3, 4, 5, 6])
h = torch.index_select(h, 0, indices)
h = torch.index_select(h, 1, indices)
# print(h.cpu())
# 计算全局预测准确率(混淆矩阵的对角线为预测正确的个数)
acc_global = torch.diag(h).sum() / h.sum() #torch.diag(h)取张量h对角线上的元素,sum()求和函数
# print("acc_global is \n",acc_global)
# 计算每个类别的准确率
acc = torch.diag(h) / h.sum(1) #h.sum(1) 求h中每一行的和
# print("acc is \n",acc)
# 计算每个类别预测与真实目标的iou
iu = torch.diag(h) / (h.sum(1) + h.sum(0) - torch.diag(h))
# print("iou is\n",iu)
return acc_global, acc, iu首先将output和target作为参数,输入到update函数中,这个时候输入进来的a和b已经是每个概率对应到类别了(可参考第二节的argmax()函数)。Output作为预测的类别,target作为真实的类别,两组参数形成一个混淆矩阵,计算各项指标。
此文作为踩坑记录在此,防止日后忘记。欢迎交流。
参考文章:
http://t.csdn.cn/7YKZb
http://t.csdn.cn/49iGH
https://www.jianshu.com/p/42939bf83b8a