幸福指数报告 -- 数据可视化+聚类分析
幸福指数报告 – 数据可视化+聚类分析
背景描述
《世界幸福报告》是对全球幸福状况的具有里程碑意义的调查,根据其公民对自己的幸福程度对156个国家进行了排名。
《 2020年报告》首次通过主观幸福感对全球城市进行排名,并更深入地探讨了社会,城市和自然环境如何结合在一起影响我们的幸福。
数据说明
幸福分数和排名使用盖洛普世界民意调查的数据。分数基于对民意调查中提出的主要生活评估问题的答案。
这个问题称为Cantril阶梯,要求被调查者考虑一个阶梯,该阶梯的最长寿命是10,而最糟糕的寿命是0,并以此等级来评价自己当前的寿命。
分数来自2015-2020年全国代表性的样本,并使用盖洛普权重使估算值具有代表性。
幸福评分后面的各栏估算了六个因素(经济生产,社会支持,预期寿命,自由,没有腐败和慷慨)中每个因素在何种程度上有助于使每个国家的生活评价高于反乌托邦,一个假设的国家,其六个因素的价值均等于世界最低的国家平均值。
它们对每个国家/地区的总分数没有影响,但是确实解释了为什么某些国家的排名高于其他国家。
什么是残差?
每个国家的残差或无法解释的成分有所不同,反映出六个变量在2015-2016年平均寿命评估中超出或低于解释的程度。在整个国家中,这些残差的平均值约为零。我们将这些残差与估计的反乌托邦中的生活评估相结合,以便合并后的条形图始终具有正值。
主要内容
1、 对无用的数据进行删除
2、 对数据进行清洗
3、 对数据采用可视化方式显示数据的类别分布
4、 利用2015-2002年数据对国家进行聚类,看哪些国家的幸福程度是类似的
配置及代码核心实现
数据预处理
导入所需要的库及载入数据集
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 读入数据
df_2015 = pd.read_csv('datasets_652031_1153691_2015.csv')
df_2016 = pd.read_csv('datasets_652031_1153691_2016.csv')
df_2017 = pd.read_csv('datasets_652031_1153691_2017.csv')
df_2018 = pd.read_csv('datasets_652031_1153691_2018.csv')
df_2019 = pd.read_csv('datasets_652031_1153691_2019.csv')
df_2020 = pd.read_csv('datasets_652031_1153691_2020.csv')
# 新增列-年份
df_2015["year"] = str(2015)
df_2016["year"] = str(2016)
df_2017["year"] = str(2017)
df_2018["year"] = str(2018)
df_2019["year"] = str(2019)
df_2020["year"] = str(2020)
将每年的幸福指数数据进行数据清洗
2015年数据
df1=df_2015.drop(labels=['Standard Error','Family','Dystopia Residual'],axis=1,inplace=False)
df1.isnull().sum().sort_values(ascending=False)#是否有缺失值
df1.dropna(how = 'all')#删除缺失值
df1.drop_duplicates()#删除重复值
2016年数据
df2=df_2016.drop(labels=['Lower Confidence Interval','Upper Confidence Interval','Family','Dystopia Residual'],axis=1,inplace=False)
df2.isnull().sum().sort_values(ascending=False)#是否有缺失值
df2.dropna(how = 'all')#删除缺失值
df2.drop_duplicates()#删除重复值
2017年数据
colNameDict = {'Happiness.Rank':'Happiness Rank','Happiness.Score':'Happiness Score','Economy..GDP.per.Capita.':'Economy (GDP per Capita)','Health..Life.Expectancy.':'Health (Life Expectancy)','Freedom to make life choices':'Freedom','Trust..Government.Corruption.':'Trust (Government Corruption)','Dystopia.Residual':'Dystopia Residual'}
df_2017.rename(columns = colNameDict,inplace=True)
df3=df_2017.drop(labels=['Whisker.high','Whisker.low','Family','Dystopia Residual'],axis=1,inplace=False)
df3.isnull().sum().sort_values(ascending=False)#是否有缺失值
df3.dropna(how = 'all')#删除缺失值
df3.drop_duplicates()#删除重复值
2018年数据
colNameDict = {'Overall rank':'Happiness Rank','Score':'Happiness Score','GDP per capita':'Economy (GDP per Capita)','Healthy life expectancy':'Health (Life Expectancy)','Freedom to make life choices':'Freedom','Perceptions of corruption':'Trust (Government Corruption)','Country or region':'Country'}
df_2018.rename(columns = colNameDict,inplace=True)
df4=df_2018.drop(labels='Social support',axis=1,inplace=False)
df4.isnull().sum().sort_values(ascending=False)
df4.dropna(how='any')
df4.drop_duplicates()#删除重复值
2019年数据
colNameDict = {'Overall rank':'Happiness Rank','Score':'Happiness Score','GDP per capita':'Economy (GDP per Capita)','Healthy life expectancy':'Health (Life Expectancy)','Freedom to make life choices':'Freedom','Perceptions of corruption':'Trust (Government Corruption)','Country or region':'Country'}
df_2019.rename(columns = colNameDict,inplace=True)
df5=df_2019.drop(labels='Social support',axis=1,inplace=False)
#df5.head()
df5.isnull().sum().sort_values(ascending=False)#是否有缺失值
df5.dropna(how = 'all')#删除缺失值
df5.drop_duplicates()#删除重复值
2020年数据
colNameDict = {'Overall rank':'Happiness Rank','Score':'Happiness Score','Healthy life expectancy':'Health (Life Expectancy)','Freedom to make life choices':'Freedom','Perceptions of corruption':'Trust (Government Corruption)','Explained by: Log GDP per capita':'Economy (GDP per Capita)','Country or region':'Country'}
df_2020.rename(columns = colNameDict,inplace=True)
df6=df_2020.drop(labels=['Social support','Dystopia + residual','Logged GDP per capita','Explained by: Social support','Explained by: Healthy life expectancy','Explained by: Freedom to make life choices','Explained by: Generosity','Explained by: Perceptions of corruption','Regional indicator','Standard error of ladder score','upperwhisker','lowerwhisker','Ladder score in Dystopia'],axis=1,inplace=False)
#df6.head()
df6.isnull().sum().sort_values(ascending=False)#是否有缺失值
df6.dropna(how = 'all')#删除缺失值
df6.drop_duplicates()#删除重复值
数据处理完毕,将15年到20年的数据合并在一起
df_all = df1.append([df2, df3, df4, df5,df6], sort=False)
df_all.head()
最后检查数据是否还有缺失值,没有缺失值、空值则进行数据可视化
df_all.isnull().sum().sort_values(ascending=False)
数据可视化
def data_info():
print(df1.info())
print(df1.describe())
#区域内的平均幸福指数可视化
def country_score_of_every_region():
#设置需要提取的数据的列名
plt_cols = ['Region', 'Happiness Score', 'Country']
plt_data = df1[plt_cols]#提取数据
print(type(plt_da))
regions = set(plt_da['Region'])#获取所有区域名称
for item in regions:#分别获取一个区域内的所有国家信息
plt.figure()#画图
data = plt_da[plt_da['Region'] == item]
print("{}.dataset is :".format(item))
#plt.bar(data['Country'],data['Happiness Score'])
sns.barplot(data['Country'],data['Happiness Score'])
plt.xticks(rotation='vertical')#设置横坐标数据方向
plt.ylabel("Happiness Score")
plt.xlabel("Country")
plt.title('{} is Happiness Score '.format(item))
plt.show()#图片展示
#区域内的人均GDP分部、社会支援信息,预期健康寿命信息,人生抉择自由信息,免于贪腐自由信息,慷慨信息,可视化
#**参数**
#'Economy (GDP per Capita)',
# 'Family',
# 'Health (Life Expectancy)',
# 'Freedom',
# 'Trust (Government Corruption)',
# 'Generosity'
#‘Happiness Rank’
def regions_country_Happiness_infos(table):
plt_cols = ['Region','Country','Economy (GDP per Capita)','Family','Health (Life Expectancy)','Freedom','Trust (Government Corruption)','Generosity','Happiness Rank']
plt_data = df_2015[plt_cols]
# print(plt_data.info())
regions = set(plt_data['Region'])
for item in regions:
plt.figure()
dat = plt_data[plt_data['Region'] == item]
sns.barplot(x='Country', y=table, data=dat)
plt.title('{} in {}'.format(table,item))
plt.xlabel('Country')
plt.ylabel(table)
plt.xticks(rotation='vertical')
plt.show()
#排名前/后5个国家的幸福指数情况
def up_5_country_happiness():
data = df1[:5]
data2 = df1[-5:]
cols = ['Region', 'Happiness Score', 'Country']
info_up = data[cols]
info_down = data2[cols]
# info1 = data[['Region', 'Happiness Score', 'Country']]
plt.figure()
ax = plt.subplot(1,2,1)
sns.barplot(x='Country',y='Happiness Score',data=info_up)
plt.xticks(rotation='vertical')
plt.title('Country Happiness Score')
ax1 = plt.subplot(1,2,2,sharey=ax)
sns.barplot(x='Country', y='Happiness Score', data=info_down)
plt.xticks(rotation='vertical')
plt.title('Country Happiness Score')
plt.show()
#三年内幸福指数变化情况
def happiness_change_in_6_years():
cols = ['Region', 'Happiness Score', 'Country']
da_2015 = df_2015[cols]
print(da_2015)
width = 0.4
da_2016 = df_2016[cols]
#da_2017 = df_2017[cols]
regions = set(da_2015['Region'])
for item in regions:
da_15 = df_2015[da_2015['Region'] == item]#获取15/16年的数据
da_16 = df_2016[da_2016['Region'] == item]
x_15 = len(da_15['Country'])
x1_15 = np.arange(x_15)+1
y_15 = list(da_15['Happiness Score'])
height_15 = np.array(y_15)
x_16 = len(da_16['Country'])
x1_16 = np.arange(x_16) + 1+0.4
y_16 = list(da_16['Happiness Score'])
height_16 = np.array(y_16)
plt.figure()
#画图
a = plt.bar(x=x1_15, height=height_15,width=width,label='2015')
b = plt.bar(x=x1_16, height=height_16,width=width,label='2016',tick_label = da_16['Country'])
plt.xticks(rotation='vertical')
plt.title('{} Happiness Score'.format(item))
plt.legend()
plt.show()
if __name__ == '__main__':
data_info()
#区域
regions_country_Happiness_infos('Economy (GDP per Capita)')
#regions_country_Happiness_infos('Family')
regions_country_Happiness_infos('Health (Life Expectancy)')
regions_country_Happiness_infos('Freedom')
regions_country_Happiness_infos('Trust (Government Corruption)')
regions_country_Happiness_infos('Generosity')
#regions_country_rank()
#regions_country_pie()
up_5_country_happiness()
#国家
# every_regions_country_num()
#幸福指数
happiness_change_in_6_years()
部分可视化图片





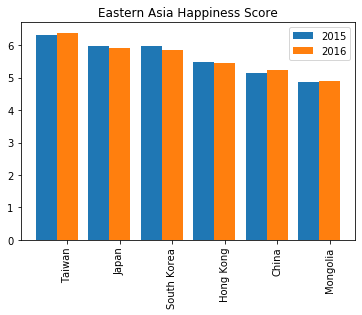
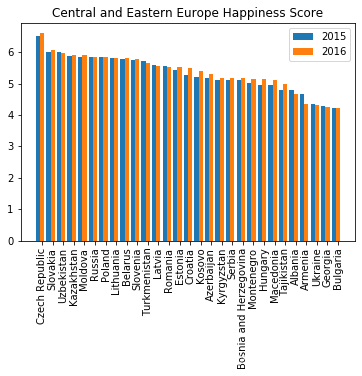
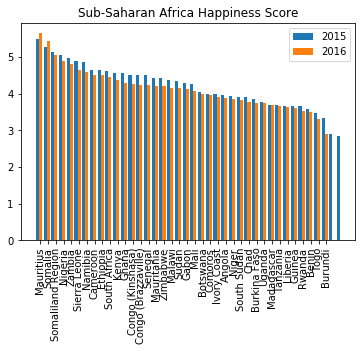
聚类分析
subDataDF1=df1[["Country","Happiness Score"]]
subDataDF1
import numpy as np
import PIL.Image as image
from sklearn.cluster import KMeans
from sklearn import cluster
data =subDataDF1.drop('Country',axis=1)
k_means = cluster.KMeans(n_clusters=2, max_iter=50, random_state=1)
k_means.fit(data)
labels = k_means.labels_
pd.DataFrame(labels, index=subDataDF1.Country, columns=['Country ID'])
centroids = k_means.cluster_centers_
pd.DataFrame(centroids,columns=data.columns)
print('查看聚类中心:\n',k_means.cluster_centers_)
print('查看样本的类别标签:\n',k_means.labels_) #查看样本的类别标签
labels_series=pd.Series(k_means.labels_) #将标签转化为series
s1=labels_series[labels_series.values==0] #幸福得分的分类中心点3
s2=labels_series[labels_series.values==1] #幸福得分类中心点2
DF2=pd.DataFrame(subDataDF1.Country)
print('第一个簇地区为:',set(df2.iloc[s1.index]['Country']))
print('第二个簇地区为:',set(df2.iloc[s2.index]['Country']))
num=pd.Series(k_means.labels_).value_counts()
print('每个幸福得分分类群的数目为:\n',num)
