【开集识别论文解读】C2AE: Class Conditioned Auto-Encoder for Open-set Recognition——CVPR2019
原文链接:https://arxiv.org/abs/1904.01198
开集识别的一般场景设定如图1所示, 我们已知四类图片,但是在测试过程中,可能会出现不属于任何一类的样本,而开集识别的目标就是识别出未知类,并且对已知类正确分类。

本文将开集识别任务分成了两个子任务:闭集分类和开集识别。训练过程如图2中的1)和2)所示。
1. Closed-set Training (Stage 1)
给定一个batch![]() 的图像,以及相应的标签
的图像,以及相应的标签![]() 。编码器(
。编码器( )和分类器(
)和分类器( )分别具有参数
)分别具有参数![]() 和
和![]() ,使用以下交叉熵损失进行训练,
,使用以下交叉熵损失进行训练,
![L_c(\{\Theta_f,\Theta_c\})=-\frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{k}\mathbb{I}_{y_i}(j)log[p_{y_i}(j)]](http://img.e-com-net.com/image/info8/424b0a508fc0431186b57befb138bf92.gif)
其中,![]() 是标签
是标签 的指示函数(即,一个热编码向量),
的指示函数(即,一个热编码向量),![]() 是预测概率得分向量。
是预测概率得分向量。![]() 是第i个样本来自第j类的概率。
是第i个样本来自第j类的概率。
2. Open-set Training (Stage 2)
在开集训练中有两个主要部分,条件解码器训练,然后是重建误差的EVT建模。在此阶段,编码器和分类器权重是固定的,在优化过程中不会改变。
2.1 Conditional Decoder Training
这里使用了视觉推断的一种方法:FiLM,FiLM层在神经网络的中间层特征上进行一个简单的feature-wise仿射变换(仿射变换:简单理解就是线性变化+平移,再通俗点就是![]() )。
)。
对于输入特征 和包含条件信息的向量
和包含条件信息的向量 ,可给出如下:,
,可给出如下:,
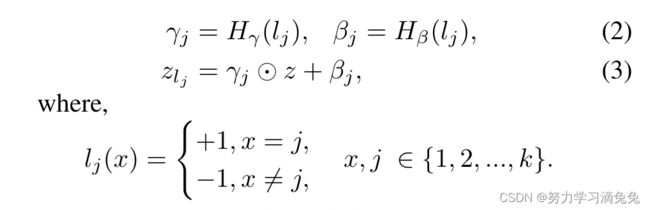
这里,![]() 和
和![]() 是具有参数
是具有参数![]() 和
和![]() 的神经网络。张量
的神经网络。张量![]() 、
、![]() 、
、 具有相同的形状。用于条件处理,在本文中称为标签条件向量。此外,符号
具有相同的形状。用于条件处理,在本文中称为标签条件向量。此外,符号![]() 用于描述以标签条件向量为条件的潜在向量,即
用于描述以标签条件向量为条件的潜在向量,即![]() 。
。
当以与输入的类标识相匹配的标签条件向量(这里称为匹配条件向量(![]() ))为条件时,期望解码器(带有参数
))为条件时,期望解码器(带有参数![]() 的
的 )能够完美地重构原始输入,可以被视为传统的自动编码器。然而,在这里,当以标签条件向量为条件时,被额外训练以不好地重构原始输入,标签条件向量与输入的类标识不匹配,这里称为非匹配条件向量(
)能够完美地重构原始输入,可以被视为传统的自动编码器。然而,在这里,当以标签条件向量为条件时,被额外训练以不好地重构原始输入,标签条件向量与输入的类标识不匹配,这里称为非匹配条件向量(![]() )。
)。
现在,对于来自一个batch的给定输入 和
和![]() 和
和![]() ,对于从
,对于从![]() 中采样的任何随机
中采样的任何随机![]() ,作为其相应的匹配和非匹配条件向量,第二阶段的前馈路径可以通过以下等式总结,
,作为其相应的匹配和非匹配条件向量,第二阶段的前馈路径可以通过以下等式总结,

按照上述前馈路径,第二阶段训练解码器(参数为![]() 的)和调节层(参数为
的)和调节层(参数为![]() 和
和![]() )的损失函数如下所示,
)的损失函数如下所示,

这里,损失函数![]() 对应于使用匹配条件向量
对应于使用匹配条件向量![]() 生成的输出应该是的完美重构的约束。损失函数
生成的输出应该是的完美重构的约束。损失函数![]() 对应于使用非匹配条件向量
对应于使用非匹配条件向量![]() 生成的输出应具有差重构的约束。为了强制执行后一个条件,从训练数据中对另一个批次
生成的输出应具有差重构的约束。为了强制执行后一个条件,从训练数据中对另一个批次![]() 进行采样,使得新批次没有与匹配条件向量一致的类标识。这种调节策略在某种程度上模拟了openset行为。这里,网络经过专门训练,当输入图像的类标识与条件向量不匹配时,会产生较差的重建。因此,当遇到未知的类测试样本时,理想情况下,任何条件向量都不会与输入图像类标识匹配。这将导致所有条件向量的重建效果不佳。然而,当遇到已知的测试样本时,由于其中一个条件向量将匹配输入图像类标识,它将为该特定条件向量生成完美的重建。因此,非匹配损失训练有助于网络更好地适应开放集设置。
进行采样,使得新批次没有与匹配条件向量一致的类标识。这种调节策略在某种程度上模拟了openset行为。这里,网络经过专门训练,当输入图像的类标识与条件向量不匹配时,会产生较差的重建。因此,当遇到未知的类测试样本时,理想情况下,任何条件向量都不会与输入图像类标识匹配。这将导致所有条件向量的重建效果不佳。然而,当遇到已知的测试样本时,由于其中一个条件向量将匹配输入图像类标识,它将为该特定条件向量生成完美的重建。因此,非匹配损失训练有助于网络更好地适应开放集设置。
2.1 EVT Modeling
极值理论。极值理论常用于许多视觉识别系统,是建模训练后分数的有效工具。它已被用于许多应用,如金融、铁路轨道检测等,以及开集识别。本文遵循极值定理的Picklands-Balkema-deHaan公式。它考虑了以超过高阈值的随机变量为条件的建模概率。对于具有累积分布函数(CDF)![]() 的给定随机变量
的给定随机变量 ,任何超过阈值
,任何超过阈值 的条件CDF定义为:
的条件CDF定义为:
![]()
现在,给定I.I.D.样本,![]() ,极值定理指出,对于大类基础分布,并且给定足够大的,
,极值定理指出,对于大类基础分布,并且给定足够大的,![]() 可以很好地近似于广义帕累托分布(GPD),
可以很好地近似于广义帕累托分布(GPD),

参数估计。当将任何分布的尾部建模为GPD时,主要的挑战是找到尾部参数u以获得条件CDF。可以使用平均超额函数(MEF)来找到u的估计值,即![]() 。研究表明,对于GPD,MEF与u呈线性关系。许多研究人员利用GPD的这一特性来估计u的值。这里,采用了文献[29]中针对GPD介绍的查找u的算法,但做了一些小的修改。在得到u的估计值后,从极值定理,我们知道集合
。研究表明,对于GPD,MEF与u呈线性关系。许多研究人员利用GPD的这一特性来估计u的值。这里,采用了文献[29]中针对GPD介绍的查找u的算法,但做了一些小的修改。在得到u的估计值后,从极值定理,我们知道集合![]() 遵循GPD分布,GPD的其余参数,即ζ和μ可以使用最大似然估计技术轻松估计。
遵循GPD分布,GPD的其余参数,即ζ和μ可以使用最大似然估计技术轻松估计。
2.3 Threshold Calculation
在前几节所述的训练过程之后,匹配和非匹配重建错误集从训练集![]() 以及它们相应的匹配和非匹配标签,
以及它们相应的匹配和非匹配标签,![]() 和
和![]() 创建。设
创建。设![]() 为输入的匹配重建误差,
为输入的匹配重建误差,![]() 为非匹配重建误差,则匹配和非匹配误差集可计算为,
为非匹配重建误差,则匹配和非匹配误差集可计算为,

![]() (匹配重建误差集)和
(匹配重建误差集)和![]() (非匹配重建误差集)的典型直方图如图3a所示。请注意,这些集合中的元素仅根据训练期间观察到的内容进行计算(即,不使用任何未知样本)。图3b显示出了在从已知类集(K)和未知类集(U)的测试样本进行推断期间观察到的重建误差的归一化直方图。比较图3中的这些图,可以观察到,对于来自已知集(K)和未知集(U)的测试样本,在训练期间计算的
(非匹配重建误差集)的典型直方图如图3a所示。请注意,这些集合中的元素仅根据训练期间观察到的内容进行计算(即,不使用任何未知样本)。图3b显示出了在从已知类集(K)和未知类集(U)的测试样本进行推断期间观察到的重建误差的归一化直方图。比较图3中的这些图,可以观察到,对于来自已知集(K)和未知集(U)的测试样本,在训练期间计算的![]() 和
和![]() 的分布为推断期间观察到的误差分布提供了良好的近似。这一观察结果还验证了非匹配训练模拟了一个开放集测试场景,其中输入与任何类标签都不匹配。这就需要使用
的分布为推断期间观察到的误差分布提供了良好的近似。这一观察结果还验证了非匹配训练模拟了一个开放集测试场景,其中输入与任何类标签都不匹配。这就需要使用![]() 和
和![]() 来找到开放集识别的操作阈值,从而对任何已知/未知的测试样本做出决策。
来找到开放集识别的操作阈值,从而对任何已知/未知的测试样本做出决策。

现在,可以假设最佳操作阈值(![]() ) 位于
) 位于![]() 区域。在这里,
区域。在这里,![]() 和
和![]() 的潜在分布尚不清楚。但是,可以使用GDP来建模
的潜在分布尚不清楚。但是,可以使用GDP来建模![]() (右尾)和
(右尾)和![]() (左尾)的尾部,分别用
(左尾)的尾部,分别用![]() 和
和![]() 表示。GPD仅定义用于建模最大值,但可以在拟合
表示。GPD仅定义用于建模最大值,但可以在拟合![]() 的
的![]() 左尾之前,执行
左尾之前,执行![]() 。假设观测未知样本的先验概率为pu,则误差概率可表示为阈值τ的函数,
。假设观测未知样本的先验概率为pu,则误差概率可表示为阈值τ的函数,

3. Open-set Testing by k-inference (Stage 3)
这部分介绍了该方法的开集测试算法,测试程序在下面的算法1中描述。该测试策略涉及使用所有可能的条件向量调节解码器k次,以获得k个重建误差。因此,它被称为k-推理算法。
