有趣的深度学习2——利用pytorch对数据集进行预处理
有趣的深度学习2——利用pytorch对数据集进行预处理
用pytorch对数据集进行预处理
-
- 有趣的深度学习2——利用pytorch对数据集进行预处理
-
- 1.输入数据的表示方法
- 2.使用torchvision工具箱
- 3.使用自定义数据集的方法
1.输入数据的表示方法
随着深度学习的发展,以神经网络为模型的功能越来越强大,这一部分归功于现代设备超强的计算能力,也有很大一部分功劳是属于目前已有的各种丰富数据集,以图像为代表的Mnist、CIFAR-10、CIFAR-100、ImagNet以及COCO数据集等,还有众多丰富的文本数据集和语音数据集等。
一般来说,我们传统的神经网络的神经元之间的信息传递是以浮点数的形式来进行表示的,而如何将我们所能理解的图像、文本和语音转换成神经网络可以理解的浮点数,这个过程即是数据集的预处理过程。而对于不同类型的数据集又有不同的处理方法,这里重点解释一下图像数据的表示方法。
图像数据可以转换成像素点的集合,而每个像素点可以有一通道、三通道等,一通道以mnist数据集为代表的灰度图像,三通道的有常见的CIFAR数据集和ImageNet的RGB图像,我们对于单个像素点的通道取值范围一般是在0~255之间的整数,或者以百分比作为对比度,所以一张图片可以表示为一个三维的张量(hwc,其中h代表图像高度的像素数量,w代表的图像宽度的像素数量,c代表的是图片的一个通道数,灰度图像c=1,RGB图像c=3),而神经网络在训练中一般都是一次训练一个批次的图片,所以输入的图片的长宽是需要等距的,此外还会添加一个批次的维度(nhw*c)。
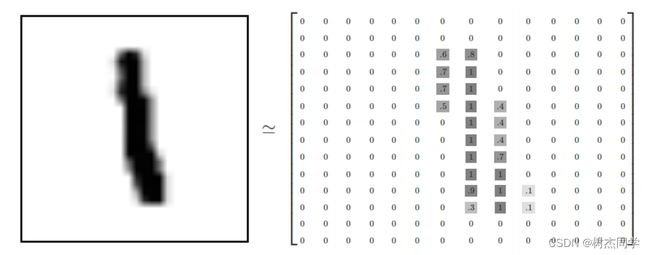
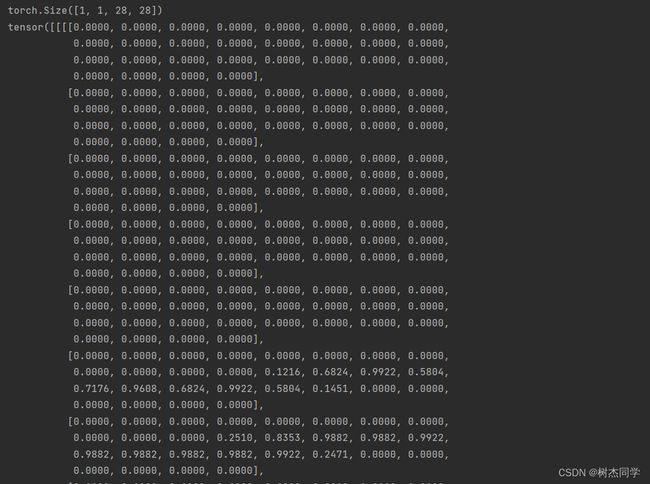
这里以mnist为例展开说明一下:如图所示,这里给出单通道mnist数据集一张图片的矩阵表示形式,同时给定在神经网络模型中mnist数据集的维度和输入形式(nch*w)
2.使用torchvision工具箱
利用好pytorch这个工具,最常见的公开数据集在torchvision工具包里面都给我们做好了数据的预处理工作,我们只要学会简单的调用就可以啦。这里给出MNIST、CIFAR-10、VOC数据集、Coco数据集和ImagNet数据集的torchvision的调用方法示例:
# annotation 调用一些要用到的库
import torch
imoort torchvisoon
batch_size=512
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=False)
# anntation:数据集的调用,一般需要经过加载和装载俩个部分:Dataset实现加载部分的功能,实现了通过索引找寻数据集数据和标签,以及返回数据集大小的功能;Dataloader则实现数据集装载的功能,一种类似于自动迭代的功能,还可定义多线程、多核加载读取、以及随机化读取的功能;
# annotation 调用一些要用到的库
import torch
imoort torchvisoon
train_dataset=torchvision.datasets.CIFAR10('dataset',train=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
]),download=True)
train_dataloader=torch.utils.data.DataLoader(train_dataset,batch_size=512,shuffle=True)
test_dataset=torchvision.datasets.CIFAR10('dataset',train=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor]),
download=True)
test_dataloader=torch.utils.data.DataLoader(test_dataset,batch_size=512,shuffle=False)
# annotation VOC数据集在torchvision里面有用于目标检测和语义分割的数据集,这里给出一种调用方法
import torch
imoort torchvisoon
train_dataset=torchvision.datasets.VOCSegmentation(root='dataset',year='2012',image_set='train',
download=True,transform=torchvision.transforms.Compose(
torchvision.transforms.ToTensor()),
target_transform=None,transforms=None)
train_dataloader=torch.utils.data.DataLoader(train_dataset,batch_size=512,shuffle=True)
test_dataset=torchvision.datasets.VOCSegmentation(root='dataset',image_set='test',
download=True,transform=torchvision.transforms.Compose(
torchvision.transforms.ToTensor()),
target_transform=None,transforms=None)
test_dataloader=torch.utils.data.DataLoader(test_dataset,batch_size=512,shuffle=False)
# annotation 给出COCO和ImageNet的数据集包装类
import torch
imoort torchvisoon
class torchvision.dataset.CocoDetection(root,annFile,transform=None,target_transform=None,
transforms=None)
class torchvison.dataset.ImageNet(root,split='train',download=False,**kwargs)
3.使用自定义数据集的方法
我们在使用自定义的时候,主要需要写一下Dataset和Dataloader俩个类;
Dataset类
Dataset类是Pytorch中图像数据集中最为重要的一个类,也是Pytorch中所有数据集加载类中应该继承的父类。
我们在使用自定义的数据集的时候,其中父类中的两个私有成员函数必须被重载,其中__len__应该返回数据集的大小,而__getitem__应该编写支持数据集索引的函数,例如通过dataset[i]可以得到数据集中的第i+1个数据。首先继承上面的dataset类。然后在__init__()中得到图像的路径,然后将图像路径组成一个数组,这样在__getitim__()中就可以直接读取。这里的__getitem__接收一个index,然后返回图片数据和标签,这个index通常指的是一个list的index,这个list的每个元素就包含了图片数据的路径和标签信息。制作这个list呢,通常的方法是将图片的路径和标签信息存储在一个txt中,然后从该txt中读取。制作这个list:通常的方法是将图片的路径和标签信息存储在一个txt中,然后从该txt中读取。
那么读取自己数据的基本流程就是: 1. 制作存储了图片的路径和标签信息的txt 2. 将这些信息转化为list,该list每一个元素对应一个样本 3. 通过__getitem__函数,读取数据和标签,并返回数据和标签。
# todo 需要继承torch.utils.data.Dataset
class MyDataset(torch.utils.data.Dataset):
def __init__(self):
# 初始化文件路径或文件名列表。
# 初始化该类的一些基本参数。
pass
def __getitem__(self, index):
# TODO
#1。从文件中读取一个数据(例如,plt.imread)。
#2。预处理数据(例如torchvision.Transform)。
#3。返回数据对(例如图像和标签)。
# 这里需要注意的是,第一步:read one data,是一个data
pass
def __len__(self):
# 返回数据集的总大小。
from PIL import Image
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, txt_path, transform = None, target_transform = None):
fh = open(txt_path, 'r')
imgs = []
for line in fh:
line = line.rstrip()
words = line.split()
imgs.append((words[0], int(words[1])))
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
def __getitem__(self, index):
fn, label = self.imgs[index]
img = Image.open(fn).convert('RGB')
if self.transform is not None: #对图片进行处理,这个transform里边可以实现 减均值,
img = self.transform(img) #除标准差,随机裁剪,旋转,翻转,放射变换,等等操作
return img, label
def __len__(self):
return len(self.imgs)
import json
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import Dataset,DataLoader
class CIFAR10_IMG(Dataset):
def __init__(self, root, train=True, transform = None, target_transform=None):
super(CIFAR10_IMG, self).__init__()
self.train = train
self.transform = transform
self.target_transform = target_transform
#如果是训练则加载训练集,如果是测试则加载测试集
if self.train :
file_annotation = root + '/annotations/cifar10_train.json'
img_folder = root + '/train_cifar10/'
else:
file_annotation = root + '/annotations/cifar10_test.json'
img_folder = root + '/test_cifar10/'
fp = open(file_annotation,'r')
data_dict = json.load(fp)
#如果图像数和标签数不匹配说明数据集标注生成有问题,报错提示
assert len(data_dict['images'])==len(data_dict['categories'])
num_data = len(data_dict['images'])
self.filenames = []
self.labels = []
self.img_folder = img_folder
for i in range(num_data):
self.filenames.append(data_dict['images'][i])
self.labels.append(data_dict['categories'][i])
def __getitem__(self, index):
img_name = self.img_folder + self.filenames[index]
label = self.labels[index]
img = plt.imread(img_name)
img = self.transform(img) #可以根据指定的转化形式对数据集进行转换
#return回哪些内容,那么我们在训练时循环读取每个batch时,就能获得哪些内容
return img, label
def __len__(self):
return len(self.filenames)
DataLoader类
上面所说的Dataset类是读入数据集数据并且对读入的数据进行了索引。但是光有这个功能是不够用的,在实际的加载数据集的过程中,我们的数据量往往都很大,对此我们还需要一下几个功能:
batch_size:可以分批次按照不同的batch_size读取,mini-batch可多线程并行处理
shuffle=True:可以对数据进行随机读取,可以对数据进行洗牌操作(shuffling),打乱数据集内数据分布的顺序;
num_workers=2可以并行加载数据(利用多核处理器加快载入数据的效率。
import datasets
from torchvision import transforms
import matplotlib.pyplot as plt
import numpy as np
from torch.utils.data import DataLoader
import torchvision
import torch
train_dataset = datasets.CIFAR10_IMG('./datasets',train=True,transform=transforms.ToTensor())
test_dataset = datasets.CIFAR10_IMG('./datasets',train=False,transform=transforms.ToTensor())
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=6, shuffle=True)
for step ,(b_x,b_y) in enumerate(train_loader):
if step < 3:
imgs = torchvision.utils.make_grid(b_x)
imgs = np.transpose(imgs,(1,2,0))
plt.imshow(imgs)
plt.show()