PyTorch 入门与实践(四)多分类问题(Softmax)
来自 B 站刘二大人的《PyTorch深度学习实践》P8 的学习笔记
上一篇 PyTorch 加载数据集 中,我们实战了 MNIST 手写数据集的识别网络,那其实就是一个多分类问题(识别出 10 个类),这时候就要用 softmax,而不是 sigmoid 了。
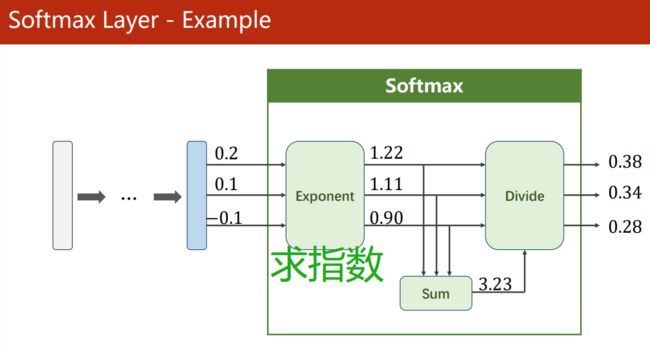
Softmax
Softmax 函数:
P ( y = i ) = e z i ∑ j = 0 K − 1 e z i , i ∈ { 0 , . . . , K − 1 } P(y = i) = \frac{e^{z_i}}{\sum^{K-1}_{j=0} e^{z_i}}, i \in \{ 0, ..., K - 1 \} P(y=i)=∑j=0K−1eziezi,i∈{0,...,K−1}
Cross Entropy
Cross Entropy:

Negative Log Likelihood Loss:

Cross Entropy in PyTorch:
读文档:CrossEntropyLoss <==> LogSoftmax + NLLLoss
要注意:
- PyTorch 中的交叉熵损失
torch.nn.CrossEntropyLoss(pred, label)已经包含了 Softmax 层,所以神经网络最后输出的时候不需要再套上 Softmax 激活函数。 y即 label,必须是torch.LongTensor()类型。- 将
y = torch.LongTensor([2, 0, 1])作为标签输入torch.nn.CrossEntropyLoss()后,会被转换成 one-hot:torch.LongTensor([[0, 0, 1], [1, 0, 0], [0, 1, 0]]),即,y的值表示 one-hot 数组的 1 的位置。
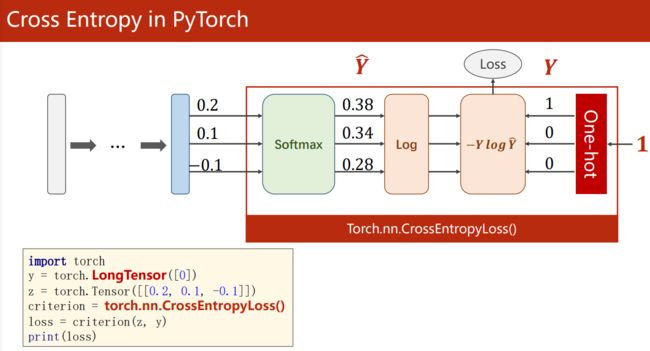
例如:Y_pred矩阵跟Y的 one-hot 矩阵的大数能对应上的(更相似),torch.nn.CrossEntropyLoss(pred, label)的 loss 值就更小:

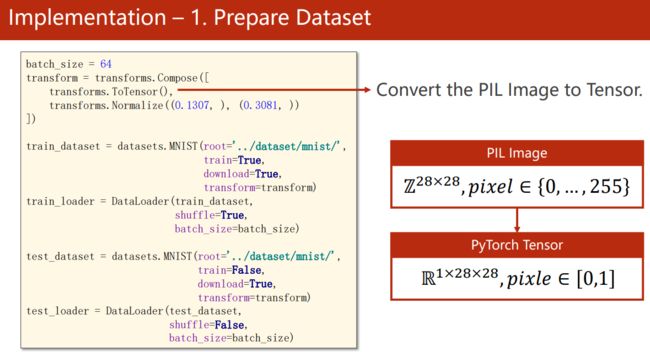
MNIST数据预处理
使用 from torchvision import transforms 库,可以轻松选择转换组件:
- PIL 转 Tensor:
transforms.ToTensor(),将[0, 255]范围内的形状为 (H x W x C) 的 PIL Image 或 numpy.ndarray 转换为[0.0, 1.0]范围内形状为 (C x H x W) 的 torch.FloatTensor。
- N ( 0 , 1 ) N(0, 1) N(0,1) 归一化:
transforms.Normalize(mean, std),mean、std 是经过计算的总样本的均值和方差。经过归一化后,值呈 N ( 0 , 1 ) \mathcal {N} (0, 1) N(0,1) 的标准正态分布。

完整代码
import os
import copy
import numpy as np
import torch
from torch import nn, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_set = datasets.MNIST(root="../datasets/mnist",
train=True,
transform=trans, # 原始是 PIL Image 格式
download=True)
test_set = datasets.MNIST(root="../datasets/mnist",
train=False,
transform=trans,
download=True)
train_loader = DataLoader(train_set, batch_size=64, shuffle=True)
test_loader = DataLoader(test_set, batch_size=64, shuffle=True)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(784, 512) # MNIST 每个图像大小为 28*28=784
self.linear2 = nn.Linear(512, 256)
self.linear3 = nn.Linear(256, 128)
self.linear4 = nn.Linear(128, 64)
self.linear5 = nn.Linear(64, 10)
self.activate = nn.ReLU()
def forward(self, x):
x = x.view(-1, 784)
x = self.activate(self.linear1(x))
x = self.activate(self.linear2(x))
x = self.activate(self.linear3(x))
x = self.activate(self.linear4(x))
x = self.linear5(x)
return x
model = Model()
def train(model, train_loader, save_dst="./models"):
global acc
criterion = nn.CrossEntropyLoss() # 包含了 softmax 层
optimizer = optim.Adam(model.parameters()) # SGD 对 batch-size 很敏感,64 是最好的;lr=0.01, momentum=0.5
optim_name = optimizer.__str__().split('(')[0].strip()
print("optimizer name:", optim_name)
for epoch in range(5):
TP = 0
loss_lst = []
for i, (imgs, labels) in enumerate(train_loader):
y_pred = model(imgs)
# print("x:", x.shape, "y:", labels.shape, "y_pred:", y_pred.shape)
loss = criterion(y_pred, labels)
loss_lst.append(loss.item())
y_hat = copy.copy(y_pred)
TP += torch.sum(labels.flatten() == torch.argmax(y_hat, dim=1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
acc = TP.data.numpy() / len(train_set)
print("epoch:", epoch, "loss:", np.mean(loss_lst), "acc:", round(acc, 3), f"TP: {TP} / {len(train_set)}")
# 保存模型
torch.save(model.state_dict(), os.path.join(save_dst, f"{optim_name}_acc_{round(acc, 2)}.pth"))
print(f"model saved in {save_dst}")
def test(model, test_loader, load_dst="./models/SGD_acc_0.99.pth"):
TP = 0
model.load_state_dict(torch.load(load_dst))
for i, (imgs, labels) in enumerate(test_loader):
with torch.no_grad():
# 测试的时候不需要再计算梯度
y_pred = model(imgs)
# print("x:", x.shape, "y:", labels.shape, "y_pred:", y_pred.shape)
y_hat = copy.copy(y_pred)
TP += torch.sum(labels.flatten() == torch.argmax(y_hat, dim=1)) # .sum().item()
acc = TP.data.numpy() / len(test_set)
print("acc:", round(acc, 4), f"TP: {TP} / {len(test_set)}")
def draw(model, test_loader, load_dst="./models/SGD_acc_0.99.pth"):
model.load_state_dict(torch.load(load_dst))
examples = enumerate(test_loader)
_, (imgs, labels) = next(examples)
with torch.no_grad():
y_pred = model(imgs)
for i in range(30):
plt.subplot(5, 6, i + 1)
plt.tight_layout()
plt.imshow(imgs[i][0], cmap='gray', interpolation='none')
plt.title("p: {}".format(
y_pred.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
if __name__ == '__main__':
train(model, train_loader)
# test(model, test_loader, load_dst="./models/SGD_acc_0.99.pth")
# draw(model, test_loader, load_dst="./models/SGD_acc_0.99.pth")
课后练习
- 参加 Kaggle 挑战赛:Otto Group Product Classification Challenge
- 处理数据集:https://www.kaggle.com/c/otto-group-product-classification-challenge/data