深度强化学习:入门(Deep Reinforcement Learning: Scratching the surface)
原文链接:https://blog.csdn.net/qq_32690999/article/details/78594220
本博客是对学习李宏毅教授在youtube上传的课程视频《Deep Reinforcement Learning: Scratching the surface》所做的笔记,供大家学习参考。
需要:课程视频链接
- 热度起源
- RL的方案
- 学习Go监督学习与增强学习
- 更多应用
- RL的难点
- 后面内容的大纲
- Policy-based Approach Learning an Actor
- Critic
热度起源
- 15年2月:Google在nature上的文章,用RL玩atari游戏,可以超越人类玩家表现。
- 16年春天:基于RL的Alphago横扫人类棋手。
RL的方案
两个主要对象:Agent和Environment
Agent观察Environment,做出Action,这个Action会对Environment造成一定影响和改变,继而Agent会从新的环境中获得Reward。循环上述步骤。
举例:
机器人把水杯打翻了,人类说“不能这么做”,机器人获得人类的这个负向反馈,然后机器人观察到水杯打翻的状态,采取了拖地的行为,获得了人类的“谢谢”的正向反馈。

Agent学习的目标就是使得期望的回报(reward)最大化。
注意:State(observation说法更贴切)指的是Agent观察到的Environment的状态,不是指machine本身的状态。
以Alphago为例子:
对Alphago来说,Observation就是19×19的一个棋盘,于是它落下一黑子:
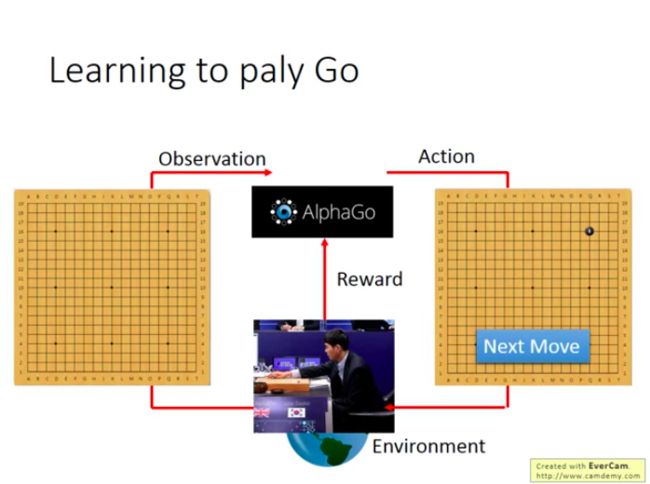
然后对手下了一个白子,Alphago观察到一个新Observation(有两颗棋子的),再下一颗黑子:

不过RL比较困难的一个地方是:Reward是比较难获得的,而Agent就是依靠Reward来进行学习,进行自身策略的调整。
学习Go:监督学习与增强学习
- 监督学习的行动方案(跟着老师学):
看到一个局式,机器就从经验中找寻和这个局式相同的那个做法,并采取经验中的应对方法,因为通过经验了解到这种应对方法是最好的(只是经验中的最好,并不代表对于Go的局势来说真的最好)。然而问题也就在于,人类也不知道哪一种应对方法时最优的,所以让机器从人类棋谱中学习,可能可以下的不错,但不一定是最厉害的。
- RL的行动方案(从经验中学习)
机器自己去和别人下围棋,赢了就是正反馈,输了就是负反馈。不过机器不知道自己下的那么多步里面哪些好,哪些不好,需要自己去搞清楚。
不管是哪种方法,都需要有大量的训练例子,比如监督学习要看上千万的棋谱,RL要下上千万盘的棋。不过对于RL来说,很难有人类和它下几千万盘棋,所以策略是先用监督学习训练处两个下得还可以的机器,再让它们用RL互相对着下。

RL也可以用在聊天机器人的训练上:

同样有监督学习和RL的学习差别:
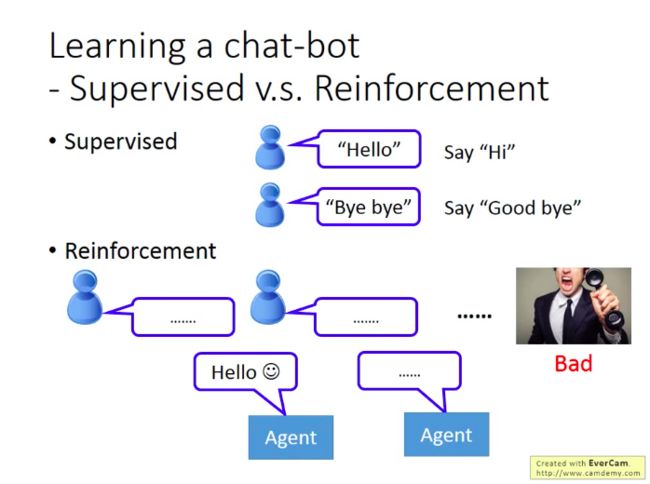
- 监督学习
如果对方说”hello”,机器应该回复”Hi”;如果对方说”Bye bye”,机器应该回复”Good bye”。
- 增强学习
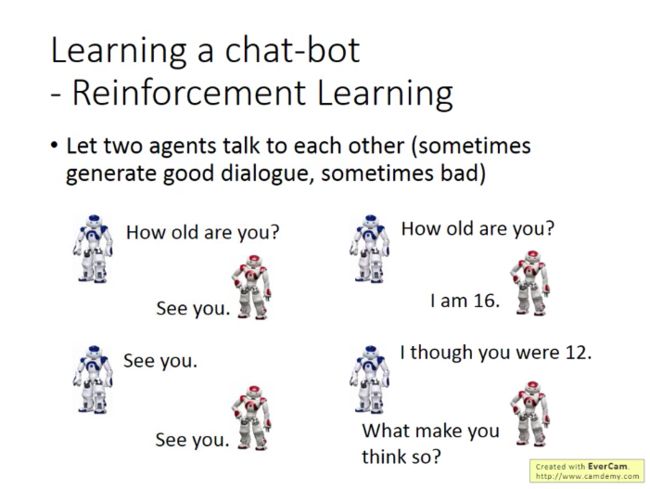
机器和对方瞎说,最后获得人类怒挂电话的负反馈(滑稽)。但机器仍不知道是自己哪句话没讲对,要靠自己去弄清楚。
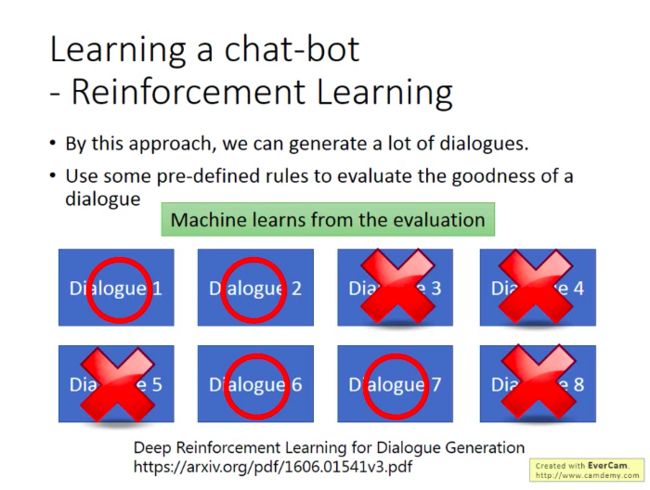
同样,由于需要大量训练,现实的训练方法是先用监督学习训练两个机器人,再让两个机器人通过RL互相讲话。不过还是需要有人来判断机器的对话是好还是不好,这是用程序很难判断的。(目前尚需克服的一个问题,有文献尝试给出一些简单规则来判断好不好,好就给机器人正反馈,不好就给负反馈)。
同样,很可能接下来会有人用GAN来做训练,即训练一个discriminator,去学习人类之间和机器之间的对话,然后判断一段新对话是来自人类,还是机器。而Agent的对话会尽量”骗过“discriminator,想办法生成尽可能像人类的对话。
更多应用
交互式检索:
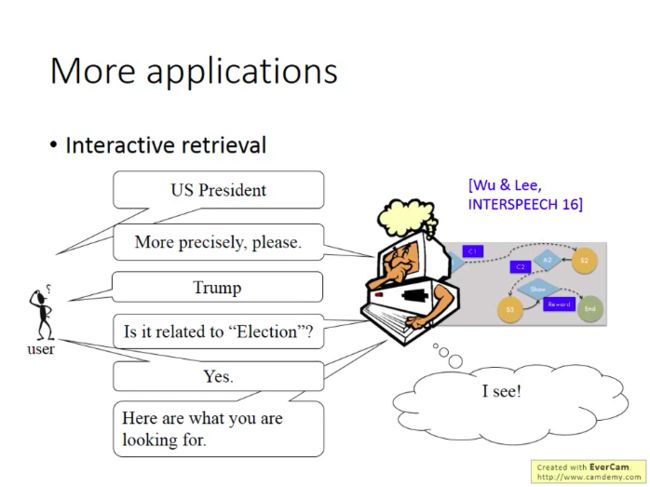
开直升机、无人驾驶、智能节电、文本生成:

玩电脑游戏:
机器用RL学习玩游戏和人类是一样的输入:电脑屏幕(像素输入),而不是像传统的游戏内置AI,是通过从程序里面直接获得某些数据来进行行动。RL的机器通过自主学习以采取合适的行为。

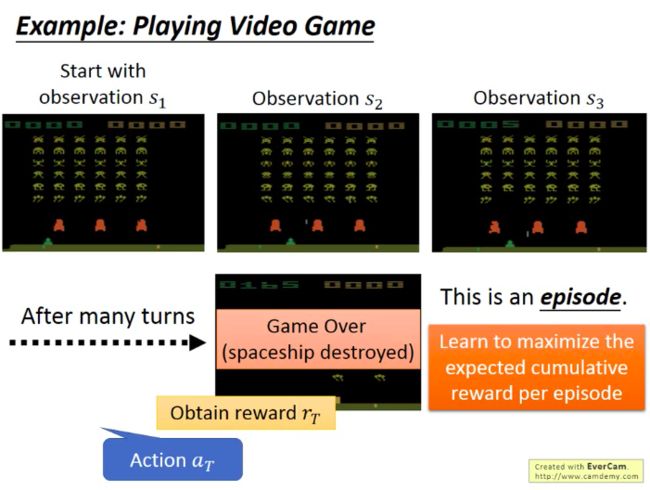
比如经典的太空入侵者游戏:飞机有三种行动选择,开火,左移,右移。Reward是游戏界面上的分数(不是看像素)。
如下图,飞机观察到第一种情况s1,决定右移,结果返现反馈为0,这时它观察完当前情况s2,选择开火,杀死一个外星人,发现获得了5的reward。观察到新的情况s3(少了一个外星人),继续行动…… 游戏从一次开始到结束称为一个episode,而机器的学习目标就是最大化每个episode的累积分数。

RL的难点
- Reward Delay
- Agent’s actions affect the subsequent data it receives

后面内容的大纲
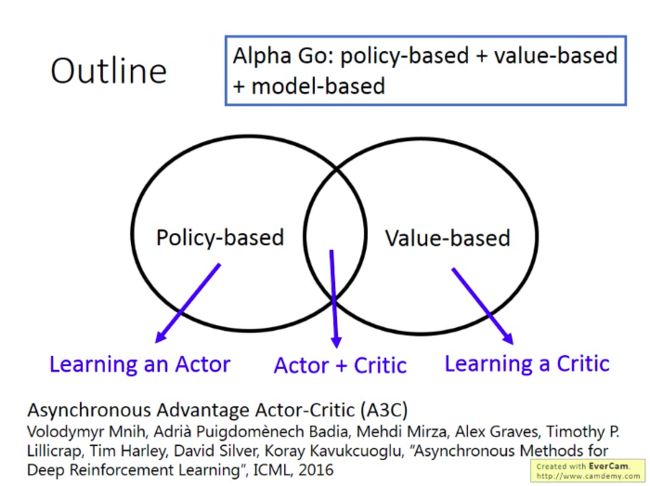
RL的方法分成两部分:
- Policy-based:学习到一个Actor
- Value-based:学习到一个Critic
将Actor与Critic结合起来是目前最有效果的做法。

Policy-based Approach: Learning an Actor
机器学习的本质就是找一个“函数”,而RL是机器学习的一种,而RL要找到的这个函数就是Actor/Policy=π(Observation)π(Observation),这个函数的输入就是Observation,输出就是Action。Reward是用来帮助我们找到这个最优的函数的。

而找到这个函数有三个步骤,如下图(当我们的Actor是一个Neural Network构成的时候,我们做的就是Deep Reinforcement Learning):

- 第一步:确定函数集合(选择一个充当Actor的模型)
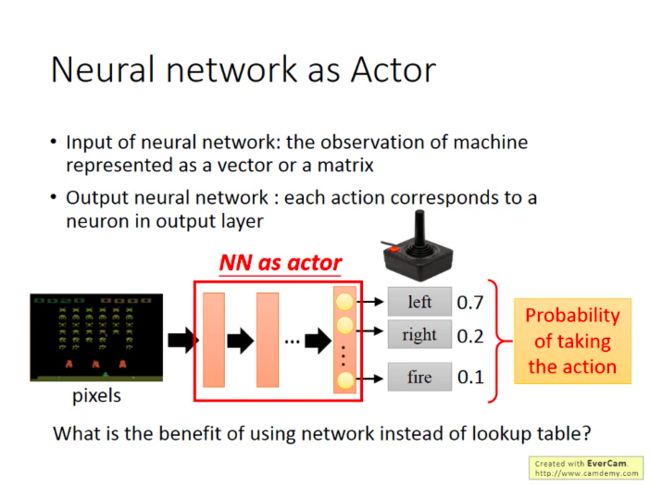
假设还是在之前的游戏里面,那么作为Actor的输入就是游戏画面,因此我们作为Actor的NN一定不是简答的前馈神经网络,应该还会有一些卷积层。而Actor的输出就是玩家可以进行的操作(action):左移,右移,开火。即作为Actor的NN的书输出层只要三个神经元即可,每个神经元代表一种玩家操作的选择,而神经元的输出是对于该操作所对应的分数。而我们就可以选择分数最高的action。
不过如果是在做policy-based的时候,我们通常假设Actor是随机的(stochastic),即Actor的输出是各个操作对应的概率值,而不是得分。后面的lecture里面也假设Actor都是随机的。
- NN相对搜索表(lookup table)的优点
搜索表的做法是:穷举每种游戏状况的可能,并给出对应状况下的最优操作。所以可以得到搜索表,就只需要一一对应地去找对应状况地给出的最优操作去执行就可以了。
不过在Actor玩电脑游戏的时候,搜索表的做法就不可行了,因为我们的输入时游戏画面(像素),不太可能穷尽所有像素的组合情况,所以只能用神经网络来替代搜索表的做法。而且NN是有举一反三的能力的,即就算有些情况它之前没见过,它也可能给出一个比较合理的结果。
- 第二步:确定函数的性能
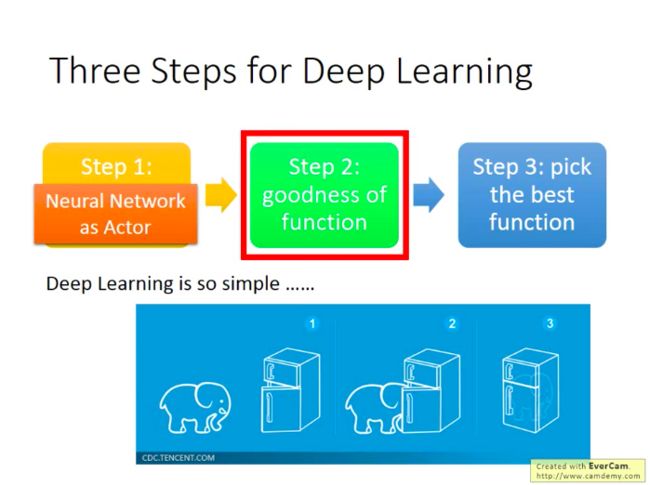
在监督学习里面,我们的做法通常是:给定训练样本,然后训练得到模型的参数,再讲测试样本输入到训练好的模型中,看模型的输出结果与真实值“像”不“像”,越“像”就说明模型(函数)训练得越好。而为了获得最好的模型,我们定义了一个衡量模型输出与真实值之间“差距”的变量叫损失函数(Loss),所有训练样本的损失加总就得到了成本函数/总损失,我们就会去尝试寻找能够让总损失总小的模型参数,而这个模型参数找到后,也就确定了最优的模型/函数。
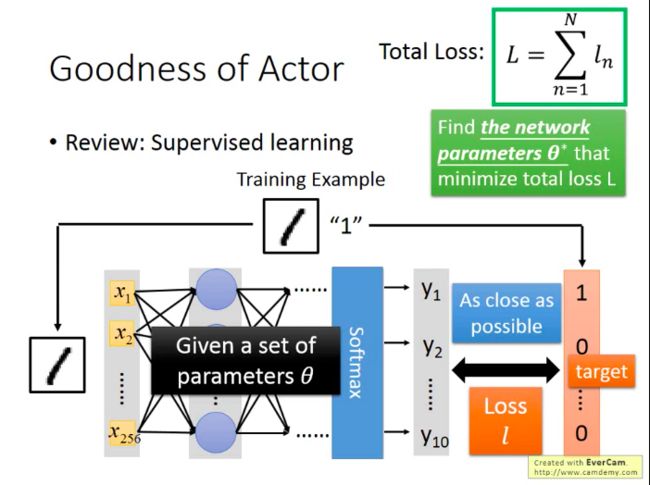
在RL中,对于函数的“好坏”的定义其实与监督学习中的也是非常相似的:比如我们直接让训练过的Actor去玩游戏,并获得一轮游戏(episode)结束最后的总Reward(Rθ=ΣTt=1rtRθ=Σt=1Trt,对游戏过程中的所有reward的加总)。
不过有个问题是:就算我们用相同的Actor去玩同一款游戏,也可能获得不同的Reward,两个原因:
- Actor本身是随机的,相同情况下(Observation)可能采取不同的操作(Action)。
- 游戏本身有随机性。即使Actor采取相同的操作(Action),游戏可能给出不同的反馈(Observation)。
因此,我们应该最大化的目标值不是某一轮游戏的Reward,而是Reward的期望值R¯θR¯θ。于是,R¯θR¯θ就是衡量Actor(πθ(s)πθ(s))好坏的指标。

那么R¯θR¯θ的期望值如何计算呢?
首先,我们将一轮游戏(episode)视作一个过程(trajectory):
而总Reward为:
每个 ττ 都是有一定概率被采样到的,这个采样概率取决于Actor的参数 θ:P(τ|θ)。θ:P(τ|θ)。
那么总回报的期望值就为:
不过,因为ττ的取值可能也太多了,而我们只能玩有限次(N)的游戏,并获得N个ττ值。而这个玩N次游戏的行为其实本质上和从P(τ|θ)P(τ|θ)里面作N次取样是一样的。
因此,我们计算总回报期望值的公式也可以写成:
这样,期望总回报就具备可计算性了。

- 第三步:选择最优的函数
那么,接下来,我们就用梯度上升(Gradient Ascent)的方法去找到可以最大化R¯θR¯θ的θ∗θ∗。

具体如何计算期望总回报的梯度呢?
因为R(τ)R(τ)与R¯θR¯θ无关,所以在做微分时不需要计算R(τ)R(τ)的微分(可以看做常量),对P(τ|θ)P(τ|θ)做微分就行。所以我们甚至都不需要知道R(τ)R(τ)这个函数的具体形式,只要知道给定一个ττ,它的输出值就可以,即把它当做一个黑盒。
接下来,针对P(τ|θ)P(τ|θ)的微分做一些变形:

最后,我们的计算难点落脚在计算∇logP(τ|θ)∇logP(τ|θ),而其实也就是算P(τ|θ)P(τ|θ)上:

然后取log,相乘变相加,并且和θθ无关的项可以直接删掉(微分时直接被当成常量略去):

最后,我们得到总期望回报的梯度可以表示成如下形式:

从直觉上来看,总期望回报的梯度表达式也是非常合理的。因为它就暗示了:当Actor在τnτn这一次游戏过程中,碰到状况sntstn并采取antatn后,根据它最后获得的该轮游戏的总回报,以调整θθ使得相应状况下的行为的概率被调整以使得期望的总回报能够更大。
再看∇log(p(ant|snt,θ))∇log(p(atn|stn,θ))这一项的合理性:它原来的形式是∇f(x)f(x)∇f(x)f(x),而此处除以分母的的一个好处则是,使得总Reward虽然为正但较小的那些更频繁的action对参数的更新效果变小。(不这么做,参数更新会偏好出现几率更大的action,而不是总Reward更高的action)
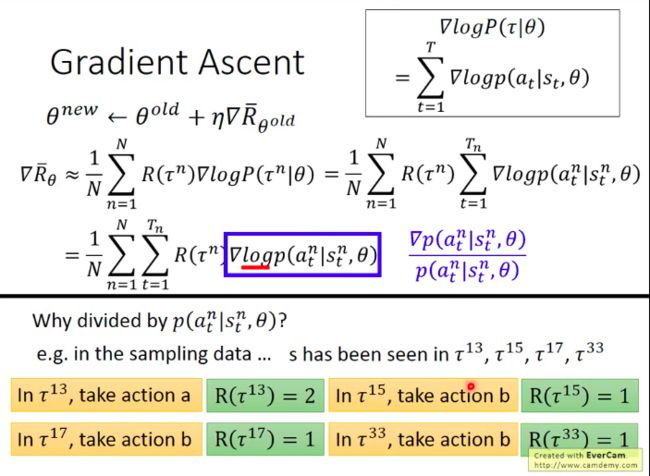
不过R(τn)R(τn)的分数如果一直为正数,那么理想情况下,在某个observation对应的可选的所有action中,参数更新依然会使得那些总Reward较低的action的采取概率下降(因为总Reward为正,参数更新本身偏向使其概率提升,但是由于其它两种行为也为正的且更大的总Reward,故相应的概率也会提升,则导致总Reward较低的那个action概率反而还是会下降)。
但实际情况中,由于我们采取的是sampling,可能会在过程中从未sampling过某个可选的action,导致对应action的概率降低。
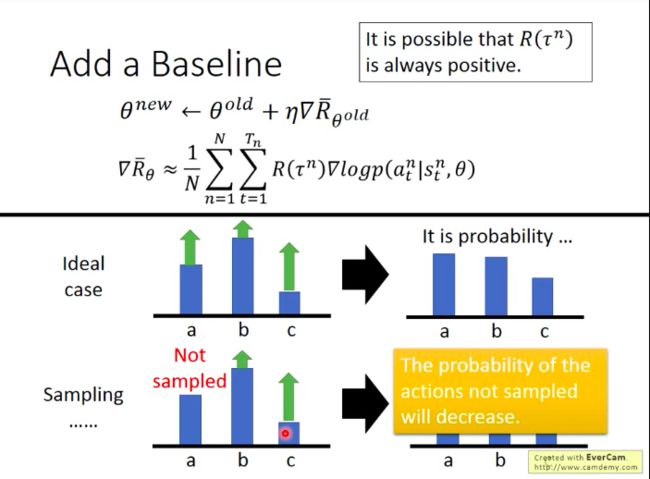
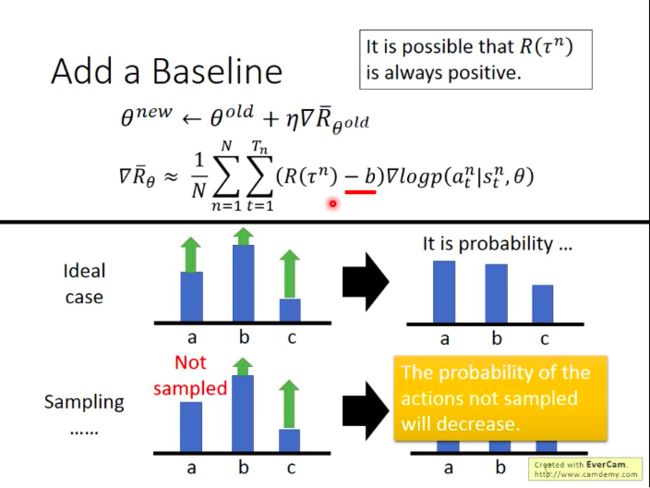
一个简单地解决上述sampling问题的方法是:令总Reward有负有正。即,当所有ττ对应的总Reward都为正时,我们让它们统一减去某个正值(baseline),使这些Reward有正有负。这样就能防止某个action没被sample到,就会导致其概率减少。
Critic
Critic也是训练出的一个NN,但是它不会对Actor的行为进行决策,它只负责评估Actor表现如何。