春节在家不再无聊,这份2019 AI研究进展回顾陪伴你
2020-01-28 13:24:06
2019 年可以说是「预训练模型」流行起来的一年。自 BERT 引发潮流以来,相关方法的研究不仅获得了 EMNLP 大会最佳论文等奖项,更是在 NLP、甚至图像领域里引领了风潮。
去年也有很多游戏 AI 取得了超越人类的水平。人工智能不仅已经玩转德州扑克、星际争霸和 Dota2 这样复杂的游戏,还获得了 Nature、Science 等顶级期刊的肯定。
机器之心整理了去年全年在人工智能、量子计算等领域里最为热门的七项研究。让我们以时间的顺序来看:
OpenAI 发布 15 亿参数量的通用语言模型 GPT-2
第一个重磅研究出现在 2 月,继发布刷新 11 项 NLP 任务记录的 3 亿参数量语言模型 BERT 之后,谷歌 OpenAI 于 2019 年 2 月再次推出了一种更为强大的模型,而这次的模型参数量达到了 15 亿。这是一种大型无监督语言模型,能够生产连贯的文本段落,在许多语言建模基准上取得了 SOTA 表现。此外,在没有任务特定训练的情况下,该模型能够做到初步的阅读理解、机器翻译、问答和自动摘要。
该模型名为 GPT-2,它是基于 Transformer 的大型语言模型,包含 15 亿参数、在一个 800 万网页数据集上训练而成。训练 GPT-2 有一个简单的目标:给定一个文本中前面的所有单词,预测下一个单词。GPT-2 是对 GPT 模型的直接扩展,在超出 10 倍的数据量上进行训练,参数量也多出了 10 倍。
- GitHub 项目地址:https://github.com/openai/gpt-2
- 论文链接:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
GPT-2 展示了一系列普适而强大的能力,包括生成当前最佳质量的条件合成文本,其中我们可以将输入馈送到模型并生成非常长的连贯文本。此外,GPT-2 优于在特定领域(如维基百科、新闻或书籍)上训练的其它语言模型,而且还不需要使用这些特定领域的训练数据。在知识问答、阅读理解、自动摘要和翻译等任务上,GPT-2 可以从原始文本开始学习,无需特定任务的训练数据。虽然目前这些下游任务还远不能达到当前最优水平,但 GPT-2 表明如果有足够的(未标注)数据和计算力,各种下游任务都可以从无监督技术中获益。
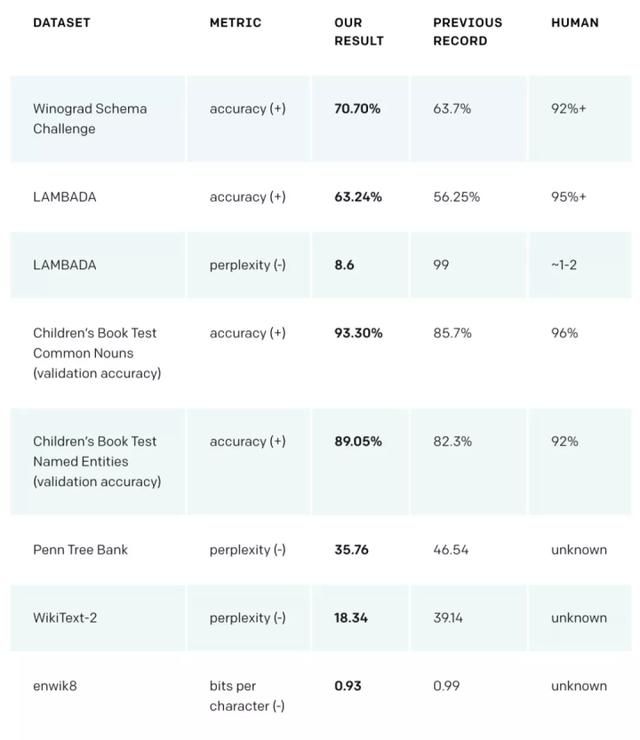
GPT-2 在 Winograd Schema、LAMBADA 和其他语言建模任务中达到了当前最佳性能。
最后,基于大型通用语言模型可能会产生巨大的社会影响,也考虑到模型可能会被用于恶意目的,在发布 GPT-2 时,OpenAI 采取了以下策略:仅发布 GPT-2 的较小版本和示例代码,不发布数据集、训练代码和 GPT-2 模型权重。
ICML 2019 最佳论文:拥有解耦表征的无监督学习是不可能的
机器学习顶会的最佳论文,总会引起人们的广泛讨论。在今年 6 月于美国加州举办的 ICML 2019(国际机器学习大会)上,由苏黎世联邦理工学院(ETH)、德国马普所、谷歌大脑共同完成的《Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations》获得了其中一篇最佳论文。研究者在论文中提出了一个与此前学界普遍预测相反的观点:对于任意数据,拥有相互独立表征(解耦表征)的无监督学习是不可能的。

论文链接:https://arxiv.org/abs/1811.12359
在这篇论文中,研究者冷静地审视了该领域的最新进展,并对一些常见的假设提出了质疑。
首先,研究者表示从理论上来看,如果不对模型和数据进行归纳偏置,无监督学习解耦表征基本是不可能的;然后他们在七个不同数据集进行了可复现的大规模实验,并训练了 12000 多个模型,包括一些主流方法和评估指标;最后,实验结果表明,虽然不同的方法强制执行了相应损失「鼓励」的属性,但如果没有监督,似乎无法识别完全解耦的模型。此外,增加的解耦似乎不会导致下游任务学习的样本复杂度的下降。
研究者认为,基于这些理论,机器学习从业者对于超参数的选择是没有经验法则可循的,而在已有大量已训练模型的情况下,无监督的模型选择仍然是一个很大的挑战。
神经网络架构搜索新方法无需显式权重训练即可执行各种任务
去年 6 月,来自德国波恩-莱茵-锡格应用技术大学和谷歌大脑的研究者发表了一篇名为《Weight Agnostic Neural Networks》的论文,进而引爆了机器学习圈。在该论文中,他们提出了一种神经网络架构搜索方法,这些网络可以在不进行显式权重训练的情况下执行各种任务。

论文链接:https://arxiv.org/pdf/1906.04358.pdf
通常情况下,权重被认为会被训练成 MNIST 中边角、圆弧这类直观特征,而如果论文中的算法可以处理 MNIST,那么它们就不是特征,而是函数序列/组合。对于 AI 可解释性来说,这可能是一个打击。很容易理解,神经网络架构并非「生而平等」,对于特定任务一些网络架构的性能显著优于其他模型。但是相比架构而言,神经网络权重参数的重要性到底有多少?
来自德国波恩-莱茵-锡格应用技术大学和谷歌大脑的一项新研究提出了一种神经网络架构搜索方法,这些网络可以在不进行显式权重训练的情况下执行各种任务。
为了评估这些网络,研究者使用从统一随机分布中采样的单个共享权重参数来连接网络层,并评估期望性能。结果显示,该方法可以找到少量神经网络架构,这些架构可以在没有权重训练的情况下执行多个强化学习任务,或 MNIST 等监督学习任务。
CMU 预训练模型 XLNet
BERT 带来的影响还未平复,CMU 与谷歌大脑 6 月份提出的 XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果。

来自卡耐基梅隆大学与谷歌大脑的研究者提出新型预训练语言模型 XLNet,在 SQuAD、GLUE、RACE 等 20 个任务上全面超越 BERT。
作者表示,BERT 这样基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于自回归语言模型的预训练方法。然而,由于需要 mask 一部分输入,BERT 忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)。
基于这些优缺点,该研究提出了一种泛化的自回归预训练模型 XLNet。XLNet 可以:1)通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息;2)用自回归本身的特点克服 BERT 的缺点。此外,XLNet 还融合了当前最优自回归模型 Transformer-XL 的思路。
延伸阅读:
- 20 项任务全面碾压 BERT,CMU 全新 XLNet 预训练模型屠榜(已开源)
- XLNet 团队:只要公平对比,BERT 毫无还手之力
- 他们创造了横扫 NLP 的 XLNet:专访 CMU 博士杨植麟
AI 攻陷多人德州扑克登上 Science
2019 年 7 月,在无限制德州扑克六人对决的比赛中,德扑 AI Pluribus 成功战胜了五名专家级人类玩家。Pluribus 由 Facebook 与卡耐基梅隆大学(CMU)共同开发,实现了前辈 Libratus(冷扑大师)未能完成的任务,该研究已经登上了当期《科学》杂志。
据介绍,Facebook 和卡内基梅隆大学设计的比赛分为两种模式:1 个 AI+5 个人类玩家和 5 个 AI+1 个人类玩家,Pluribus 在这两种模式中都取得了胜利。如果一个筹码值 1 美元,Pluribus 平均每局能赢 5 美元,与 5 个人类玩家对战一小时就能赢 1000 美元。职业扑克玩家认为这些结果是决定性的胜利优势。这是 AI 首次在玩家人数(或队伍)大于 2 的大型基准游戏中击败顶级职业玩家。
在论文中,Pluribus 整合了一种新的在线搜索算法,可以通过搜索前面的几步而不是只搜索到游戏结束来有效地评估其决策。此外,Pluribus 还利用了速度更快的新型 Self-Play 非完美信息游戏算法。综上所述,这些改进使得使用极少的处理能力和内存来训练 Pluribus 成为可能。训练所用的云计算资源总价值还不到 150 美元。这种高效与最近其他人工智能里程碑项目形成了鲜明对比,后者的训练往往要花费数百万美元的计算资源。
Pluribus 的自我博弈结果被称为蓝图策略。在实际游戏中,Pluribus 使用搜索算法提升这一蓝图策略。但是 Pluribus 不会根据从对手身上观察到的倾向调整其策略。
实验中 Pluribus 与人类玩家对抗时的界面
Pluribus 在 10000 手实验中对职业扑克玩家的平均胜率。直线表示实际结果,虚线表示一个标准差

Pluribus 在与顶尖玩家对战时的筹码数量变化
谷歌宣布实现量子优越性
在人工智能之外的量子计算领域,去年也有重要的研究突破。2019 年 9 月,谷歌提交了一篇名为《Quantum supremacy using a programmable superconducting processor》的论文自 NASA 网站传出,研究人员首次在实验中证明了量子计算机对于传统架构计算机的优越性:在世界第一超算 Summit 需要计算 1 万年的实验中,谷歌的量子计算机只用了 3 分 20 秒。因此,谷歌宣称实现「量子优越性」。之后,该论文登上了《自然》杂志 150 周年版的封面。

谷歌的「量子优越性」论文登上《自然》杂志 150 周年版封面
这一成果源自科学家们不懈的努力。谷歌在量子计算方向上的研究已经过去了 13 年。2006 年,谷歌科学家 Hartmut Neven 就开始探索有关量子计算加速机器学习的方法。这项工作推动了 Google AI Quantum 团队的成立。2014 年,John Martinis 和他在加利福尼亚大学圣巴巴拉分校(UCSB)的团队加入了谷歌的工作,开始构建量子计算机。两年后,Sergio Boixo 等人的论文发表,谷歌开始将工作重点放在实现量子计算优越性任务上。
如今,该团队已经构建起世界上第一个超越传统架构超级计算机能力的量子系统,可以进行特定任务的计算。

谷歌 CEO 桑达尔·皮查伊和圣芭芭拉实验室中谷歌的量子计算机
量子优越性实验是在一个名为 Sycamore 的 54 量子比特的完全可编程处理器上运行的。该处理器包含一个二维网格,网格中的每个量子比特与其他四个相连。量子优越性实验的成功归功于谷歌改进了具有增强并行性的双量子比特门,即使同时操作多个门,也能可靠地实现记录性能。谷歌使用一种新型的控制旋钮来实现这一性能,该旋钮能够关闭相邻量子比特之间的交互。此举大大减少了这种多连通量子比特系统中的误差。此外,通过优化芯片设计来降低串扰,以及开发避免量子比特缺陷的新控制校准,谷歌进一步提升了性能。
DeepMind 星际争霸 AI 登上 Nature
虽然 AI 没有打败最强人类玩家 Serral,但其研究的论文仍然登上了 Nature。2019 年 10 月底,DeepMind 有关 AlphaStar 的论文发表在了当期《Nature》杂志上,这是人工智能算法 AlphaStar 的最新研究进展,展示了 AI 在「没有任何游戏限制的情况下」已经达到星际争霸Ⅱ人类对战天梯的顶级水平,在 Battle.net 上的排名已超越 99.8%的活跃玩家。

DeepMind 发推称已达到 Grandmaster 水平
回顾 AlphaStar 的发展历程,DeepMind 于 2017 年宣布开始研究能进行即时战略游戏星际争霸Ⅱ的人工智能——AlphaStar。2018 年 12 月 10 日,AlphaStar 击败 DeepMind 公司里的最强玩家 Dani Yogatama;12 月 12 日,AlphaStar 已经可以 5:0 击败职业玩家 TLO 了(TLO 是虫族玩家,据游戏解说们认为,其在游戏中的表现大概能有 5000 分水平);又过了一个星期,12 月 19 日,AlphaStar 同样以 5:0 的比分击败了职业玩家 MaNa。至此,AlphaStar 又往前走了一步,达到了主流电子竞技游戏顶级水准。
根据《Nature》论文描述,DeepMind 使用通用机器学习技术(包括神经网络、借助于强化学习的自我博弈、多智能体学习和模仿学习)直接从游戏数据中学习。AlphaStar 的游戏方式令人印象深刻——这个系统非常擅长评估自身的战略地位,并且准确地知道什么时候接近对手、什么时候远离。此外,论文的中心思想是将游戏环境中虚构的自我博弈扩展到一组智能体,即「联盟」。
联盟这一概念的核心思想是:仅仅只是为了赢是不够的。相反,实验需要主要的智能体能够打赢所有玩家,而「压榨(exploiter)」智能体的主要目的是帮助核心智能体暴露问题,从而变得更加强大。这不需要这些智能体去提高它们的胜率。通过使用这样的训练方法,整个智能体联盟在一个端到端的、完全自动化的体系中学到了星际争霸Ⅱ中所有的复杂策略。
2019 年在 AI 领域的各个方向上都出现了很多技术突破。新的一年,我们期待更多进展。
此外,机器之心于 2019 年 9 月底推出了自己的新产品 SOTA 模型,读者可以根据自己的需要寻找机器学习对应领域和任务下的 SOTA 论文,平台会提供论文、模型、数据集和 benchmark 的相关信息。