基于出行住宿评论数据的情感分析研究(酒店篇,含python代码)
携程酒店评论数据:
链接:https://pan.baidu.com/s/1zUtfc6Ku6W2sx99XdqeWcA
提取码:vkzs
停用词汇总:
链接:百度网盘 请输入提取码
提取码:02eb
情感分析用词:
链接:https://pan.baidu.com/s/1TKR8xBFMhUH7AZPePqBGJQ
提取码:7wwz
文章目录
前言
一、数据集介绍
二、数据预处理
1.引入库
2.剔除无价值数据
三、情感信息提取及可视化
四、使用线性支持向量分类模型进行情感预测
优化处理操作——向下采样:
五、使用LDA主题分类模型进行数据分析
1. 积极评论:
2. 消极评论:
六、结果分析及结论
前言
在上一篇文章中,我进行了爱彼迎民宿评论数据的分析,而本篇是携程酒店评论数据的分析,我希望能通过数据分析,从用户体验感出发,找出民宿与酒店的不同点,发觉它们各自的优劣。
一、数据集介绍
携程酒店评论数据:
链接:https://pan.baidu.com/s/1fIhjn1DrPV8wxqnJ0DdumA
提取码:lpy3
数据集中共有7766条评论,其中5322条正向评论,2444条负向评论,已经带有评论标签,label值为1是正向评论,0为负向评论。
二、数据预处理
1.引入库
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import jieba
import re
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
import warnings
warnings.filterwarnings("ignore")2.剔除无价值数据
因为数据中包含部分其他类型的数据,所以要注意将评论数据通过.astype('str')统一转化为字符型。共剔除以下几类数据:
1)英文数据,由于北京、上海、重庆等城市都是国际化都市,所以数据集中包含了部分英文数据,我在预处理时首先就将数据中的英文评论和评论文本中的空白行去除,具体方法就是将空白行标记为缺失值,再将包含英文字母的评论换为缺失值,然后进行再删去文本中所有缺失值。
2)重复词,例如:携程、酒店、年月日、北京、上海、重庆、广州、杭州、南京、成都、东路、西路等,这些词虽然频繁出现,但对于分析评论特点没有帮助。
3)数字,0-9。
data["review"] = data["review"].astype('str')
import re
# 去除数字、携程等词语
strinfo = re.compile('[0-9]|酒店|携程|年月日|北京|上海|重庆|广州|杭州|南京|成都|苏州|西安|东莞|长沙|济南|深圳|西路|东路')
data["review"] = data["review"].apply(lambda x: strinfo.sub('',x))
import re
# 由于有的时候jupyternotebook会出bug,去除一次并不能去除掉年月日,所以保险起见,再去除一次
strinfo = re.compile('[0-9]|酒店|携程|年月日')
data["review"] = data["review"].apply(lambda x: strinfo.sub('',x))
#第一步 将空字符的行替换为nan,方便进行删除
data.replace(to_replace=r'^\s*$', value=np.nan, regex=True, inplace=True)
data.replace(to_replace=r'[a-zA-Z]', value=np.nan, regex=True, inplace=True)
print(data)
#第二步 删除所有值为nan的行
data.dropna(axis=0, how='any', inplace=True)三、情感信息提取及可视化
由于携程酒店评论数据数据自带情感标签,所以不需要对酒店评论数据进行情感倾向修正了。直接绘制出正向和负向评论词云图并提取对应的关键词。提取出正负面评论信息:
# 提取正负面评论信息
posdata = data[data['label'] == 1]['review']
negdata = data[data['label'] == 0]['review']
绘制正面评论信息词云图:
from wordcloud import WordCloud
import jieba
import matplotlib.pyplot as plt
import PIL
text = ''
for s in posdata:
text += s
data_cut = ' '.join(jieba.lcut(text))
path = '停用词汇总.txt'
f = open(path,"r",encoding='utf-8').read() #设置文件对象
word_cloud = WordCloud(font_path="simsun.ttc",
background_color="white",
stopwords=f
)
word_cloud.generate(data_cut)
plt.subplots(figsize=(12,8))
plt.imshow(word_cloud)
plt.axis("off")
plt.show()
提取负面评论关键词:
from jieba import analyse
key_words = jieba.analyse.extract_tags(sentence=text, topK=20, withWeight=True, allowPOS=())
key_words
绘制负面评论信息词云图:
from wordcloud import WordCloud
import jieba
import matplotlib.pyplot as plt
import PIL
text1 = ''
for s in negdata:
text1 += s
data_cut = ' '.join(jieba.lcut(text1))
path = '停用词汇总.txt'
f = open(path,"r",encoding='utf-8').read() #设置文件对象
word_cloud = WordCloud(font_path="simsun.ttc",
background_color="white",
stopwords=f
)
word_cloud.generate(data_cut)
plt.subplots(figsize=(12,8))
plt.imshow(word_cloud)
plt.axis("off")
plt.show()
提取负面评论关键词:
from jieba import analyse
key_words = jieba.analyse.extract_tags(sentence=text1, topK=20, withWeight=True, allowPOS=())
key_words 
四、使用线性支持向量分类模型进行情感预测
我将总数据集随机划分为训练集和验证集,训练集占70%的数据量,验证集占30%的数据量最终使用默认参数的LinearSVC模型,利用模型的fit函数来对数据集做训练,最终打印模型在验证集数据上的准确率。模型准确率为0.7290953545232274。
第一步:划分训练集和验证集;
from sklearn.feature_extraction.text import TfidfVectorizer as TFIDF # 原始文本转化为tf-idf的特征矩阵
from sklearn.svm import LinearSVC
from sklearn.calibration import CalibratedClassifierCV
from sklearn.model_selection import train_test_split
# 将有标签的数据集划分成训练集和测试集
train_X,valid_X,train_y,valid_y = train_test_split(data['review'],data['label'],test_size=0.3,random_state=42)
train_X.shape,train_y.shape,valid_X.shape,valid_y.shape![]()
第二步:模型的构建和训练;
# 模型构建
model_tfidf = TFIDF(min_df=5, max_features=5000, ngram_range=(1,3), use_idf=1, smooth_idf=1)
# 学习idf vector
model_tfidf.fit(train_X)
# 把文档转换成 X矩阵(该文档中该特征词出现的频次),行是文档个数,列是特征词的个数
train_vec = model_tfidf.transform(train_X)
# 模型训练
model_SVC = LinearSVC()
clf = CalibratedClassifierCV(model_SVC)
clf.fit(train_vec,train_y)第三步:验证模型效果,查看准确率;
# 把文档转换成矩阵
valid_vec = model_tfidf.transform(valid_X)
# 验证
pre_valid = clf.predict_proba(valid_vec)
pre_valid = clf.predict(valid_vec)
print('正例:',sum(pre_valid == 1))
print('负例:',sum(pre_valid == 0)) ![]()
from sklearn.metrics import accuracy_score
score = accuracy_score(pre_valid,valid_y)
print("准确率:",score)![]()
优化处理操作——向下采样:
我注意到该模型负向评论为2444条,正向评论为5322条,存在着数据不平衡的情况,这里用向下采样的方法,分别采取2444条的正向评论和2444条的负向评论,这里我是参考网络上的自定义函数get_balanced_words进行的向下采样,该函数可以实现采集相同数量的不同类别数据,同时也可以通过改变采集数据总量做到欠采样和过采样。
在进行了向下采样后,模型的准确率为0.7027948193592365,仍需继续优化。
def get_balanced_words(size,
positive_comment=data[data['label'] == 1],
negtive_comment=data[data['label'] == 0]):
word_size = size // 2
#获取正负评论数
num_pos = positive_comment.shape[0]
num_neg = negtive_comment.shape[0]
# 当 正(负)品论数中<采样数量/2 时,进行上采样,否则都是下采样;
# 其中pandas的sample方法里的repalce参数代表是否进行上采样,默认不进行
balanced_words = pd.concat([
positive_comment.sample(word_size,
replace=num_pos < word_size,
random_state=0),
negtive_comment.sample(word_size,
replace=num_neg < word_size,
random_state=0)
])
# 打印样本个数
print('样本总数:', balanced_words.shape[0])
print('正样本数:', balanced_words[data['label'] == 1].shape[0])
print('负样本数:', balanced_words[data['label'] == 0].shape[0])
print('')
return balanced_words
data_4888 = get_balanced_words(4888) 
第一步:划分训练集和验证集;
from sklearn.feature_extraction.text import TfidfVectorizer as TFIDF # 原始文本转化为tf-idf的特征矩阵
from sklearn.svm import LinearSVC
from sklearn.calibration import CalibratedClassifierCV
from sklearn.model_selection import train_test_split
# 将有标签的数据集划分成训练集和测试集
train_X,valid_X,train_y,valid_y = train_test_split(data_4888['review'],data_4888['label'],test_size=0.3,random_state=23)
train_X.shape,train_y.shape,valid_X.shape,valid_y.shape![]()
第二步:验证模型效果,查看准确率;
# 模型构建
model_tfidf = TFIDF(min_df=2, max_features=5000, ngram_range=(1,3), use_idf=1, smooth_idf=1)
# 学习idf vector
model_tfidf.fit(train_X)
# 把文档转换成 X矩阵(该文档中该特征词出现的频次),行是文档个数,列是特征词的个数
train_vec = model_tfidf.transform(train_X)
# 模型训练
model_SVC = LinearSVC()
clf = CalibratedClassifierCV(model_SVC)
clf.fit(train_vec,train_y)第三步:验证模型效果,查看准确率;
# 把文档转换成矩阵
valid_vec = model_tfidf.transform(valid_X)
# 验证
pre_valid = clf.predict_proba(valid_vec)
pre_valid = clf.predict(valid_vec)
print('正例:',sum(pre_valid == 1))
print('负例:',sum(pre_valid == 0)) 
from sklearn.metrics import accuracy_score
score = accuracy_score(pre_valid,valid_y)
print("准确率:",score)![]()
五、使用LDA主题分类模型进行数据分析
使用LDA主题分类模型分别对正向评论(label=1)中的词汇和负向评论(label=0)中的词汇进行主题分析,在进行了多次参数调优之后,我发现正向评论中LDA设为3个主题的效果较好,负向评论中LDA设为2个主题的效果较好,如果选择分为更多主题就会出现部分主题之间的大范围重叠。
第一步:先分别删除正负面评论中是空值的行;
posdata=pd.DataFrame(posdata).dropna(axis=0)
posdata.columns=['comment']
negdata=pd.DataFrame(negdata).dropna(axis=0)
negdata.columns=['comment']第二步:进行分词操作;
#利用jieba中文分词
import jieba
import jieba.posseg as psg
#格式转换 否则会报错 'float' object has no attribute 'decode'
df1 = pd.DataFrame(posdata.astype(str))
def chinese_word_cut(mytext):
return ' '.join(jieba.cut(mytext))
#增加一列数据
df1['content_cutted'] = df1['comment'].apply(chinese_word_cut)
#格对负面评论进行操作
df2 = pd.DataFrame(negdata.astype(str))
def chinese_word_cut(mytext):
return ' '.join(jieba.cut(mytext))
#增加一列数据
df2['content_cutted'] = df2['comment'].apply(chinese_word_cut)1. 积极评论:
第三步:去除停用词,计算tf值;
path = '停用词汇总.txt'
f = open(path,"r",encoding='utf-8').read()
stopwords=list(f)
#计算TF-IDF值
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
#设置特征数
n_features = 2000
tf_vectorizer = TfidfVectorizer(strip_accents = 'unicode',
max_features=n_features,
stop_words=stopwords,
max_df = 0.99,
min_df = 0.002) #去除文档内出现几率过大或过小的词汇
tf = tf_vectorizer.fit_transform(df1.content_cutted)
print(tf.shape)
print(tf)第四步:进行LDA主题分析;
#LDA分析
from sklearn.decomposition import LatentDirichletAllocation
#设置主题数
n_topics = 3
lda = LatentDirichletAllocation(n_components=n_topics,
max_iter=100,
learning_method='online',
learning_offset=50,
random_state=0)
lda.fit(tf)
#显示主题数 model.topic_word_
print(lda.components_)
#几个主题就是几行 多少个关键词就是几列
print(lda.components_.shape)
#主题-关键词分布
def print_top_words(model, tf_feature_names, n_top_words):
for topic_idx,topic in enumerate(model.components_): # lda.component相当于model.topic_word_
print('Topic #%d:' % topic_idx)
print(' '.join([tf_feature_names[i] for i in topic.argsort()[:-n_top_words-1:-1]]))
print("")
#定义好函数之后 暂定每个主题输出前20个关键词
n_top_words = 20
tf_feature_names = tf_vectorizer.get_feature_names()
#调用函数
print_top_words(lda, tf_feature_names, n_top_words) 
第五步:LDA分类结果可视化;
import pyLDAvis
import pyLDAvis.gensim_models
red_vis_data = pyLDAvis.sklearn.prepare(lda,tf,tf_vectorizer)
pyLDAvis.display(red_vis_data) 
2. 消极评论:
第三步:去除停用词,计算tf值;
#计算TF-IDF值
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
n_features = 2000
tf_vectorizer = TfidfVectorizer(strip_accents = 'unicode',
max_features=n_features,
stop_words=stopwords,
max_df = 0.99,
min_df = 0.002)
tf = tf_vectorizer.fit_transform(df2.content_cutted)
print(tf.shape)
print(tf)第四步:进行LDA主题分析;
#LDA分析
from sklearn.decomposition import LatentDirichletAllocation
#设置主题数
n_topics = 2
lda = LatentDirichletAllocation(n_components=n_topics,
max_iter=100,
learning_method='online',
learning_offset=50,
random_state=0)
lda.fit(tf)
#显示主题数 model.topic_word_
print(lda.components_)
#几个主题就是几行 多少个关键词就是几列
print(lda.components_.shape)
#主题-关键词分布
def print_top_words(model, tf_feature_names, n_top_words):
for topic_idx,topic in enumerate(model.components_): # lda.component相当于model.topic_word_
print('Topic #%d:' % topic_idx)
print(' '.join([tf_feature_names[i] for i in topic.argsort()[:-n_top_words-1:-1]]))
print("")
#定义好函数之后 暂定每个主题输出前20个关键词
n_top_words = 20
tf_feature_names = tf_vectorizer.get_feature_names()
#调用函数
print_top_words(lda, tf_feature_names, n_top_words) 
第五步:LDA分类结果可视化;
import pyLDAvis
import pyLDAvis.gensim_models
red_vis_data = pyLDAvis.sklearn.prepare(lda,tf,tf_vectorizer)
pyLDAvis.display(red_vis_data)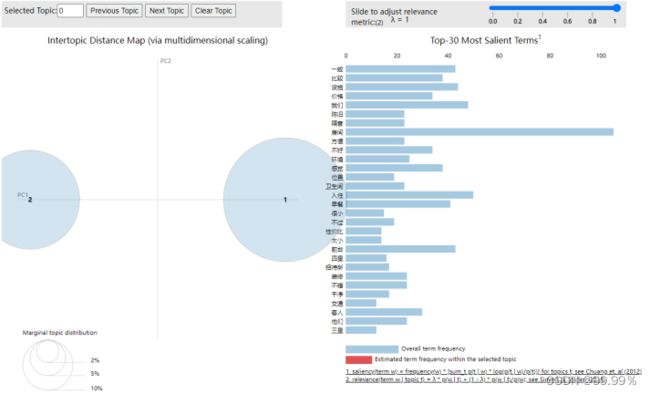
六、结果分析及结论
通过携程酒店评论数据的分析结果可以看出,用户们喜欢酒店的主要原因有以下几点:
一、酒店服务周到,早上提供早餐,入住方便且舒适;
二、酒店的网络好,配套设施齐全,干净整洁;
三、酒店的周围环境优美,空气清新,这也主要是度假酒店拥有的优点。
而使住户留下差评的原因主要有以下几点:
一、酒店设施陈旧,装修不符合住户审美;
二、酒店服务人员服务不到位,让客人不满意。
综合民宿篇(详见我的上一篇文章)和酒店篇,通过对数据分析结果的解读,我找出了民宿和酒店各自的优势和劣势。
民宿作为近些年新兴的住宿方式,优势主要依靠民间房屋独有的装修风格和民宿周边的便民设施,然而民宿由于地处社区内部,具体位置往往没有酒店好找,并且在疫情期间,很多社区的管控较严,使得原本的劣势进一步放大,并且考虑到民宿的卫生条件往往不如酒店,因此在疫情背景下,更多用户选择了更干净卫生的酒店。
此外酒店的价格标准往往是统一的,统一档次的酒店往往价格都相差不多,而民宿缺少统一标准的严格监管,民宿的具体状况完全依靠房屋所有者的自觉程度和第三方平台的监管,造成民宿配套设施、卫生条件和隔音效果参差不齐,并且由于是房屋所有者和平台第三方共同定价,民宿所有人为了得到更多利益,所以就会出现性价比差的情况。
爱彼迎作为中国大陆地区民宿预订平台的龙头企业之一,选择在此时推出大陆市场应该也是考虑到疫情环境下,国家防疫政策不可能在短时间内放松,民宿的很多缺点被进一步放大,近年来由于疫情,国内的出行住宿市场的利润就处于低位,民宿行业在这种情况下短时间很难扭转颓势,并且民宿行业自身一直以来都存在着良莠不齐的问题,所以只能依靠出行住宿市场的的整体回暖和民宿行业内部的严格监管,民宿行业才会逐步走出当前困境。
而酒店行业在当前环境下,虽然收益相对于疫情前有所下降,但依靠较为统一的价格标准和相对于民宿更齐全的服务模式,仍可以保持一定的客户量,但由于收入较少,酒店就需要降低用人成本,这就导致了服务人员素质有所下降,并且收益减少也使得酒店的设施出现翻新不及时的情况,这些因素给用户带来了不好的消费体验。