家乐福618保卫战二-零售O2O场景中的万级并发交易情况下的极限性能调优
本系列简介
- 这个系列可以帮助普通程序员们深刻的意识到平时工作中到底还有什么不足以及如何进一步进化成真正意义上的架构师、CTO以及后面的道路是如何走的;
- 这个系列可以帮助企业IT管理者深刻意识到,性能安全不是单一技术、纯技术这么简单的一件事,它是一套系统化的打法是IT团队文化建设的最高成果;
在上一篇家乐福618安全与性能保卫战(一)-安全高地保卫战中我们画出过这样的一幅图。
我们可以看到其实零售全渠道O2O平台在上线后,会面临两个“战略高地”。
- 其一、为安全高地。
- 其二、就是应用性能高地。
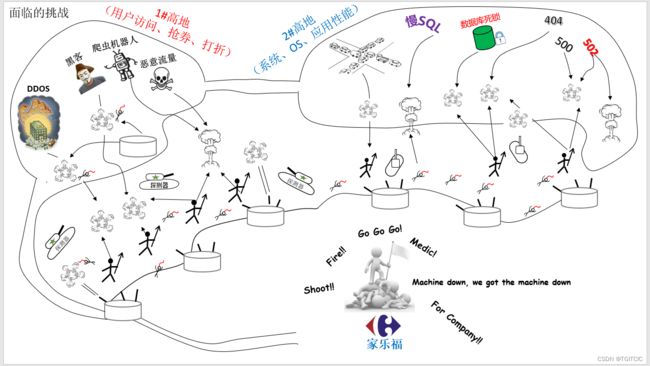
本篇不光只是讲单一case中的系统性能调优。本人经历过先后3个大规模级别的零售全渠道中台从0到1的建设。碰上过无数个案例,而这些案例都具有一定的通性和规则。
系统性能安全的高地绝不是一个、两个技术场景所可以讲得清的。它是一件体系化建设的任务,这就好比打一场胜仗和打赢整体战役,这二者是有着本质的区别的。
恰恰本人经过了若干次这种高并发、大流量场景,并且是在没有任何外援、手上也没有大厂那种预算,算得上是独自决策、指挥、落地并且成功的个例。
这里面有幸运的成份也有我的上级领导对我的极大支持同时也有本身一直注重体系化知识建设综合而取得的成果。
如我在上篇安全高地中所说的,系统的安全和性能这两条“战壕”是必须打通的而不是孤立、隔裂的去考虑。这对整个IT团队也是一项很巨大的考验。
我们知道大厂有大厂的好处,当你的流量达到每秒钟持续超过万级QPS、交易量超过5,000TPS并且是持续的对于你的公司的全系统这样“压”过来时,大厂可以通过紧急调拨上百、上千台服务集群去做临时支撑。而对于那些没有成百上千的硬件资源可以被调拨时,此时我们连系统重启都是解决不了的,除非你当天挂“停业”-这相当于就是举白旗了。
因此对于我们来说不是靠的外挂“黄金甲”去解决这个问题,而真的是要靠自身内功的打造去“空手夺白刃”的。可能我用“中途岛战役”来形容我们所面临的态势和最终的结果会更贴切。
要夺得这样的以少胜多、以弱胜强战役的胜利,关键靠的还是平时的体系化、综合化IT团队的建设,完全超脱了纯技术领域。
因此,我才要把IT系统性能优化知识分享出来并作为一个系列而不只是孤立的一个战场而去论。
那么本篇的作用就是一个导论,先从理论上来说IT由其是零售电商平台的系统性能调优必须是怎么样的。它不是一个一蹴而就的事而是一件长期化的事并且是做足提前量的一件事。好比:4周后你要面临高考了此时你再开始拿起书本、练习册开始准备你觉得还来得及吗?有人提前了3年、4年应已经开始准备这场“高考”了这样的一种比较是一个道理的。
因此我们先从技术角度来说系统性能调优的体系化布局。
系统性能体系化知识
说一个15年前的故事。
某企业面临业务快速发展,需要把原有的线下系统做成线上,因此委托了一家乙方来进行系统的开发。系统上线之初一切运行良好一切满足了乙方的功能要求,而且开发异常的快速,该企业领导人相当满意。
第二年,系统线上用户翻了近百倍,该系统开始发生有规律性的性能问题,每天的晚上20:00左右在系统做日结盘点时就会经常宕机,一开始宕机4-5次,再往后开始每隔30分钟宕机一次。
来来回回让负责开发和维护的乙方来过10几次现场,无果。整个性能问题会让日結从20:00做到零晨2点都做不完导致了那个班次的所有女员工要么辞职,要么就不做那个班次的工作了,因此那真的是要死人的节奏。
最后,我,当时的一个小工程师,来到了现场。
当时我记得是夏天,7月的晚上大概在21:45分,到了现场看了状态后,开始查看JVM进程、日志,最终发觉他们用的还是小型机,中间件为WAS,最后通过日志、设计文档和代码证实其根本原因在于:
EOD(日结)时经常业务人员会查看一些报表和产生报表数据,而这一切竟然都是用的是web session来暂存数据的,数据库倒也不大,日结时会把全schema做一个备份,即把1.2GB左右的oracle整个schema存入内存进行备份,然后同时有20多个业务人员在前端查看一些日报,日报是带翻页的,每点一次翻写,数据都会从session中取。
当时的数据量为18万条一天左右,全部放入user session然后用数组索引下标去做翻页。
笔者同时结合了另外一些点给己方的项目经理和VP提出了改进意见,可能耗时在1个半月左右,但是为了响应业务,还是设置了一个紧急方案,内容为:
- 日结时先禁用报表功能,以多线程把数据导成EXCEL并放置于share folder的形式为需要查看报表的业务人员提供报表,即一个excel多个sheet,供所有业务人员查看,但是数据会有一定的延迟,同时把该功能独立成一个新的模块
- EOD中把整个SCHEMA先LOAD进内存的方式改成外部exp命令驱动式的数据库备份
- 同时,安排3-4个人员开始重构性能有关的service层代码
但是,己方的项目经理却选择了如下的方案:
- 给小型机加了一根8GB内存,哇,08年啊,客户有钱真好骗,加完内存后,嘿嘿,原来30分钟OUT OF MEMORY一次,现在变成了42分钟OOM一次,不错,还是有效果的哦(干咳)
- 做WAS集群,2台小型机。。。吼吼。。。不错,搞了半天最后连服务都起不来了,再还原回单机状
最后,由VP和项目经理拍板,一个月2000多RMB雇了一个人,坐在机房里,只要出现OOM了就用手点一下这个机器上的重启按钮。。。。。。最终这个团队的甲方项目经理走人、相应的供应商团队也被解散。
做一个系统,不难,可能只要几个月甚至短的2个月,3个月的时间。
而让一个系统能够服务于业务运行个3-5年,嘿嘿,这真的是本事。
技术为了先满足业务,肯定是要做一定的妥协的,我们不提倡“大技术”论,但是却需要在后期有步骤有计划递进和切合实际的去解决系统的性能问题。
要知道,当真的性能问题爆发时,你们的业务和母体公司会面临2种境地:
1. 业务部门或者是你的客户还没完全关注到这个点上,此时你还有时间可以投入成本去做优化;
2. 业务此时己经收不住了,而客户的抱怨开始直线上升,此时,你面临的很可能就是“走人”的结局;
性能问题举例及影响范围

还有小程序白屏、卡、前方拥堵、最后就是“暂停营业”。
我们来看看一些关键行业的性能指标
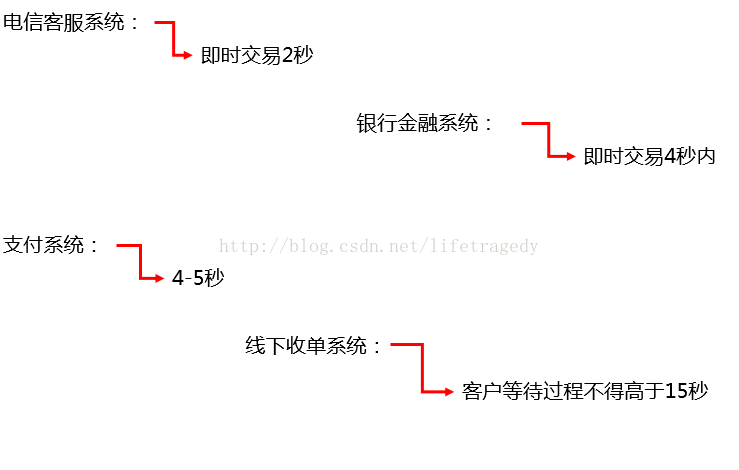
说一下零售电商行业特别是时下最火的小程序、APP上的一些指标是多少
| no | 模块级别 | 打开/加载时间 | 备注 |
| 1 | 首页 | <4秒 | |
| 2 | 搜索 | <2秒 | |
| 3 | 分类页(含内部任何子类) | <2秒 | |
| 4 | 会员 | <2秒 | |
| 5 | 结算按钮(含结算时整个页面的展示) | <3秒 | |
| 6 | 提交订单 | <6秒 | 受制于调外部支付拉起支付的窗口因此普遍慢于结算页 |
| 7 | 个人中心 | <2秒 | |
| 8 | 我的订单(含下部所有按钮的展示) | <4秒 | |
| 9 | 收货地址增删改减任何动作 | <2秒 | |
| 10 | 点“加车按钮" | <2秒 | |
| 11 | 礼品卡所有相关动作 | <2秒 | |
| 12 | 附近门店 | <2秒 | |
| 13 | 取消订单 | <2秒 | |
| 14 | 退单中任何有交互的操作 | <2秒 | |
| 15 | 结算或者活动中有任何的“可用优惠券”包含(优惠券关联可用商品查询) | <2秒 | |
| 注: | |||
| 1 | 以上指标基于10,000每秒的查询(QPS), 3,000每秒的下单(TPS) | ||
| 2 | 以上指标基于<=100家门店 | ||
请注意最后浅褐色部分的两个点,这两个点意味着:
你的系统必须在满足日进千万级别数据、万级并发、3,000每秒钟强交易(TPS)下各个APP、小程序板面的响应速度。
为什么有这样的响应指标?这完全就是源自于我们国内大量人群使用电商时在某个电商APP、小程序上或者是WEB页上的“体验/感受”。
顾客体验在零售业内被称为可以造成:留存、转化率上升的三大核心指标之一。试想,你在线下POS结帐,收银员如果告你你从扫码到显示价格要15秒、出小票要1分钟,差不多一单收银如果需要:3分钟,你直接东西都不要买了,你会把手推车往柜台旁边一推:我不要了,走人了。
同样,线上购物也是这种体验的感觉。这个指标是取自于各大厂的APP在这些类别内的各指标的一个平均值。而。。。有个别大厂都已经做到了1秒内的体验了,因此这不是神话而变成了“必须”。
系统性能调优的理论知识
纯技术角色的系统性能调优
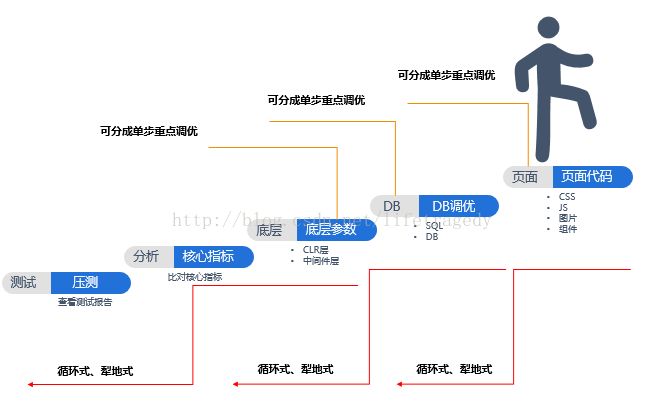
这是一个:从下到上、反复式、犁地式的调优,直到最优结果。
和很多决招、密藉一样,有什么“三板斧”、有什么“4大点”。从理论上讲系统性能调优从大的方面来讲就是这五大步。
看似简单,实际又不是这么简单。因为这个理论是不适用于真正零售电商高并发、大数据情况下的系统性能调优。
看似简单实际又不简单的悖论
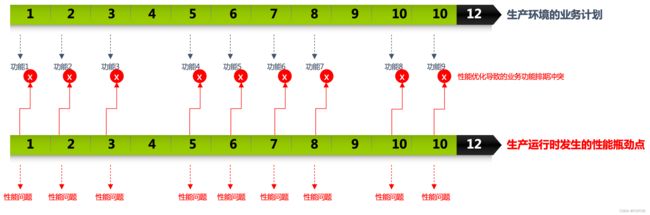 我们是有一个生产环境的,生产环境为“业务的延续可持续”发展。每个节点都有业务功能、业务需求的排期。
我们是有一个生产环境的,生产环境为“业务的延续可持续”发展。每个节点都有业务功能、业务需求的排期。
什么是业务需求?我随例举几个零售电商场景下的业务需求:
- 20天后必须接入饿了吗平台,这样饿了吗可以给到相关接入方一笔100万的促销折扣?
- 30天后必须和XXX视频打通会员积分,这样在当下最红剧集中可以出现自家电商的微信二维码,否则平时自己做这个广告要花400万?
在面对这样的业务需求时,你现在告诉你们的CIO或者是CEO:因为这个地方有个死锁、那个地方没有走缓存,啊呀因为我这边需要9天、那边需要重构。。。
业务只问你一句话:我需要的这个业务功能上线时间点能满足吗?
你的回答:需要延后5天。
或许,你理由充足。这一次业务答应了。再有下一次?第三次?我用我近20年的零售行业IT经验告诉你,骚年。就拿上面这样的需求来说,你只要敢delay三次,you are finished了。你的部门也会被finished了。
当你收到被finish的通知时你去争辩:我这是为了系统好呀!
老板只会告诉你一句话:一次业务功能的上线就会给公司省去几百万同时每天多带来几百万的额外订单交易额,你这么延误我们的公司业务计划三次,你觉得你合格吗?
哦!!!
很多,经过我的观察甚至包括我在20年前我自己,都没有考虑到这些点。
真金白银的来钱。。。才真的有这个话语权啊。他们才不来听你的bla bla bla呢,他们只需要知道:
- 你能否及时上线?
- 上线后性能很差会在原来的卡的基础上更加卡,那么系统优化需要时间。。。哦,你是IT、你是搞技术的,这不是你该解决的?这难道不是你的本质工作?你来和我们说什么说呢?
看,业务结果为导向。联想我之前文章说过的:一切以业务结果为导向你才能成为一个专业的IT。想要玩技术,you can go home。
确实是这样的。
这就是悖论、难的地方。
又要把事做了、还要把事做好。这是非常难的。
因此我们才引出了“互联网模式下、如何应对零售电商万级并发时系统出现的问题时去调优”的话题。
上文所述:离高考只剩四周了,你开始抓紧复习了。你来得及吗?有人三年前、四年前就已经在准备这一次考试了。人家在临考前一个月竟然外还外出旅游,还玩得很开发。而你呢?自己把自己累得苦哈哈的,还考不好。
嘿,下面给出真正的一个高性能IT系统性到底需要怎么做的完整理论模型
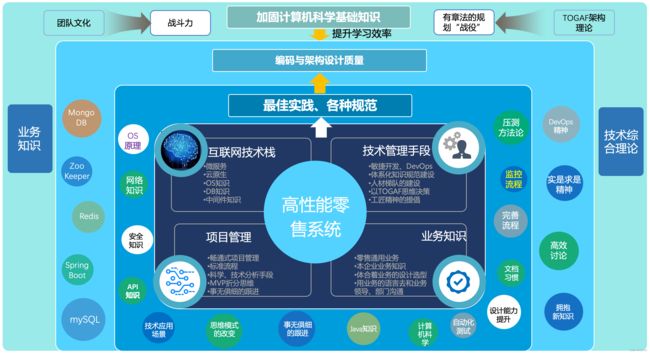
你说他是不是管理呢?但看看还有这么多细节的技术点。
你说他是不是纯技术呢?还说了不少软实力、管理、流程、甚至所谓的PUA。
各位,我后面就会用每一个实际场景把这些点全部带到时,你再返回来看看这些点,你真的会有一种“多么痛的领悟”的感觉。
这就是为什么我需要静下心来,把这些点结合实际例子一个个写出来的原因。假设有1万个人看到了这个系列,其中有两个人、三个人看到了、看进去了、领悟了,他们就能避免一些我碰到的事的再次发生。
从技术的大方面上说系统的调优
首先,我们会让我们的系统开发人员有着根深蒂固的系统性能意识。
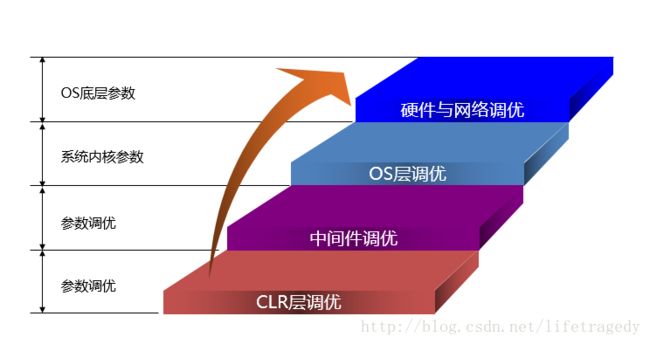
一个系统开发人员,从硬实力上说需要在大的方面具备这些层面的“基础知识”。这些叫基础,所谓基础就是如果不会饭也没得吃了。
说明:
CLR层,即common language runtime层。我们一般企业级开发用的是java或者是.net,它都有一个jvm或者是.net framework,这一层我们称之为:CLR层
我们先不说如何培训,我们从大方向上在选择招人或者是内部提升程序员至高级程序员或者Tech Leader时会关注一个很重要的能力,即:自己把开发好了的东西自己用压力测试工具去跑一跑的能力。
而通过结果为导向来推论,做的好的自我性能、压力测试的技术人员通常会去对以下5个点也会形成自我加固、学习、挖掘能力的培养。
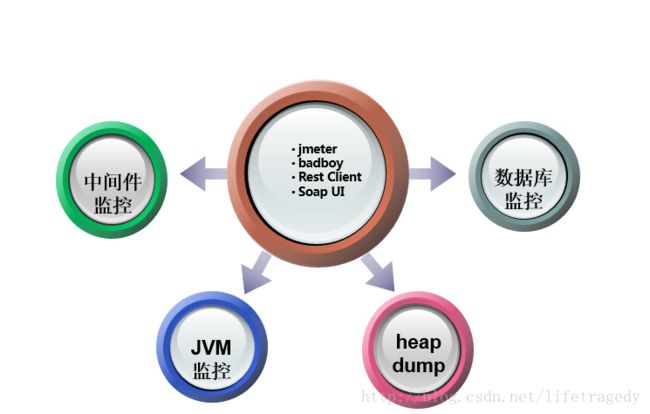
JAVA的Heap Dump工具
其中 ibm heap dump是经常用的,由其对于一些跨省、跨国的远程生产环境调试,服务器轻易是不会给你进入生产或者是宕机查看问题的,因此在很多时候我们依赖于jvm的heap dump和jmap, jstack这些小工具、小命令行来分析JVM里到底干了些什么事。
由于本章不是讲这种小工具怎么用的而是关注于一个全局的方法论的问题,因此至于这些小工具怎么使用,请自行GOOGLE和百度一下即可,到处都有讲解。关键在于你是不是经常去用。
现在知道为什么有些好点的互联网企业面试时会问你什么JAVA的类的结构、HASHMAP的原码、什么JVM核心机制这些问题了的真正原因了吧?
下面介绍几个植入式的可视化的适合于开发的性能开发与监视工具
Glowroot
这款工具很好玩,它可以把它的jar包伴随着你的容器一起启动起来,你只要在启动命令行里多加一个参数。
它是一个开源的小工具,唯一不好的地方在于它对于多节点不支持集群,但是通过它可以看到单个JVM内的任何状况且可以通过某个方法一直跟踪到你里面执行的具体的一个SQL。
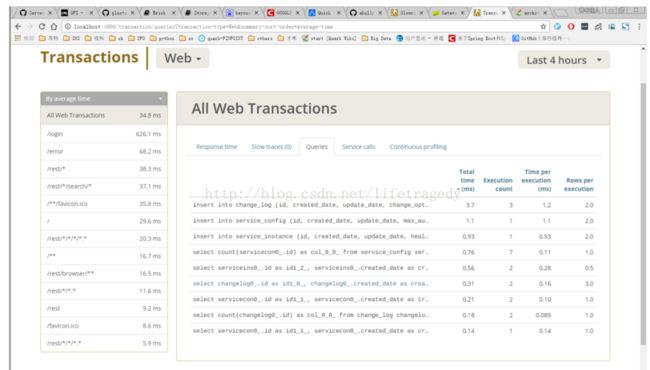
jmeter
这个就不用多介绍了吧。提示:使用BADBOY或者是Charles一类抓网页点击动作然后export成jmeter的计划文件。
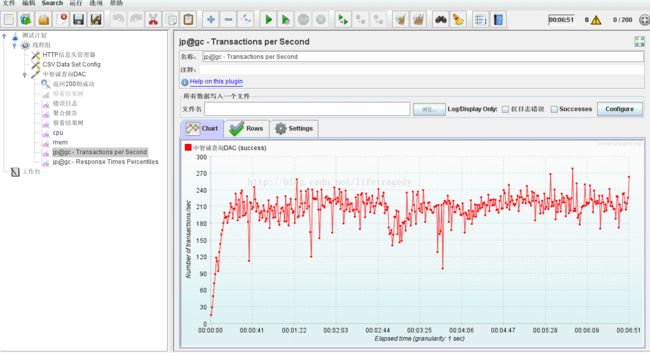
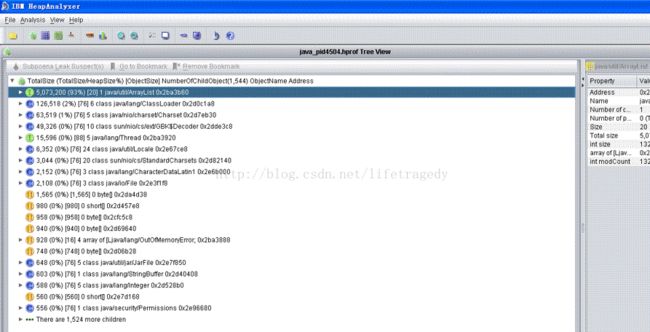
IBM Heap Analyzer
一般java应用在发生OOM时会产生一个dump文件
启动示例:
/usr/java6/bin/java – Xmx4000m – jar ha36.jar heapdump.20120602.134015.430370.phd
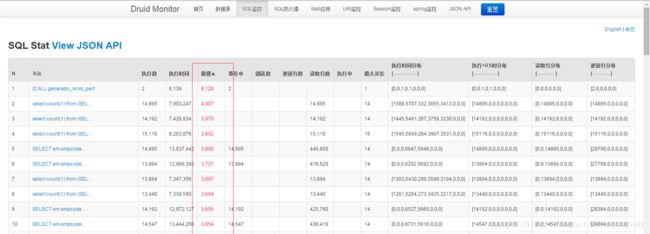
DRUID后台监控报表
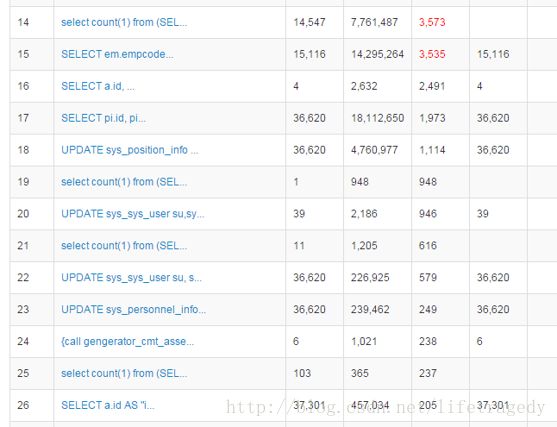
阿里的开源Datasource Connection Pool组件,它的好处就在于可以伴随着JVM启动起一个SQL监控后台,远程可以通过这个控台查看到TOP30,40,50效率最差的是哪些SQL以及它们是怎么写的。
我们一般的优化就是扫这个DRUID后台,把所有高于1秒的(控台中会标红那些个超过1秒以上的SQL)全部优化到1秒之内。
大家想,一个SQL从100秒优化到了1秒,有人觉得不得了了,可是我告诉你,在许多互联网企业内生产上的SQL执行时间1S都算慢的,为什么?假设我有1万个并发(互联网企业动不动就是上万的),你觉得这个功能或者是点击得要花多久?
因此我们一般力争把所有的SQL调优到0.5秒内,有时看看能否达到0.1秒甚至为0.0X秒,这就是一个程序员为什么会对着一个SQL调优花上2天,3天的原因了,这是真正的技术而不再是一个码农了。
集群的监控能力的要求
我们在平时发现具有这些能力的工作的人员时,我们可以看到他们已经在技术上具备了成体系化系统知识的概念,但实际工作中,上述这些小工具只是沧海一粟。可以用的工具太多了,而工具太多了也影响你的工作效率,因此我们会引导和鼓励这些人员去自搭建一些“实时监控工具”。如:
Grafna
Grafna有很多成熟的可用插件,它直接可以长入各个应用平台或者是服务器内,给到你核心关键且是“聚合”化的各服务CPU、内存、网络吞吐等指标化能力。
Zabbix
这块已经基本上淘汰了,不过自自己开发自己搭建会比较方便,都已经有成熟的套件了。
其实这些还远远不够,我告诉大家,真正的上了生产环境,这些开源监控你当然需要但当你的系统一旦面向了真正的上了千位数并发并且涉及不同legacy系统超过10个、API几千条交互时你需要另一种法宝,叫APM,这些我都会在后续的章节中特别是作为监控章节中详细来擅述。
我们用结果为导向迫使整体团队对于慢SQL引起重视
60-80% of database performance issues are related to poorly performing SQL,60-80%的数据库性能问题要归结于生产中糟糕的SQL语句!
在我的团队,我对普通开发在写SQL时提出了这么五个点。
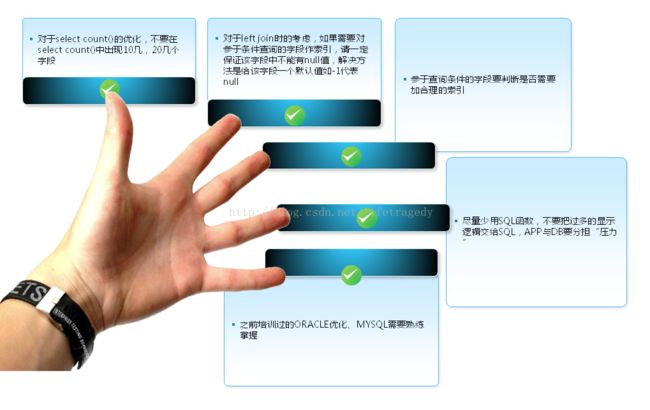
普通开发必须掌握DB的一些底层知识。这和你是否是不是在做DBA一点关系没有,而在于:DB的那些通用知识,这个点我会在后面的实际生产例子中作为DB章节去详细展开。同时我们从一个合格程序员的标准来说,程序员除了写代码、写SQL也必须要懂DB、懂OS原理,读过大学的同学们都知道大学中我拿:清华和浙大的计算机本科授课课程来说DB有两门是必须学的:一门叫数据库概论、一门叫数据库原理。这里面就讲到了索引、范式。
是不是觉得很无聊、是不是觉得很枯燥呢?嘿嘿嘿,看过了当学过、及格了就可以了。
来几次生产问题。。。你真的会涨记性的,那么这些东西都不只能靠几十、上百人的团队依赖架构师一个人,因此就必须全员普及、加强。这里面因此还涉及到了一个“如何以事件为触发条件引导着全团队加强这方面的知识”的技巧。
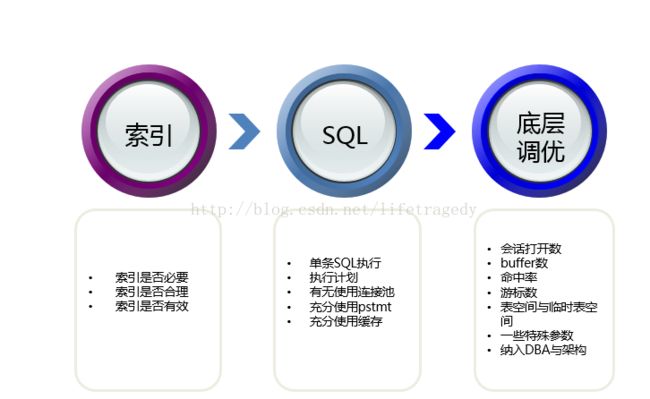
我前面有好几篇博文大量长篇幅的阐述了一些DB的调优手段、索引、甚至底层参数和OS级调优,相关的详细手段与步骤都可以参考我之前的博文。
而在管理手段上我要求每一个微服务模块有一个druid的监控后台。然后在开发环境全部开启这些druid的监控后台。然后按照“慢SQL”最长时间倒排序。
然后告诉他:把所有即时类交易凡是超过1秒的sql压入1秒内。
然后开发来告诉我:所有SQL已经调优到1秒内了。
我会再次要求他在我面前打开druid的监控后台,然后按照“慢SQL”最长时间倒排序然后再告诉他:把所有即时类交易凡是超过500毫秒的sql压入500毫秒内。
在万级并发的场景,我们的要求只有一条:一切即时类交易在千万级笛卡尔积的情况下运行的sql不得超过300毫秒。
有了这个结果,逼着团队去做SQL的极限调优。
传授普通开发人员在自我压测时需要观察的一些关键指标的知识
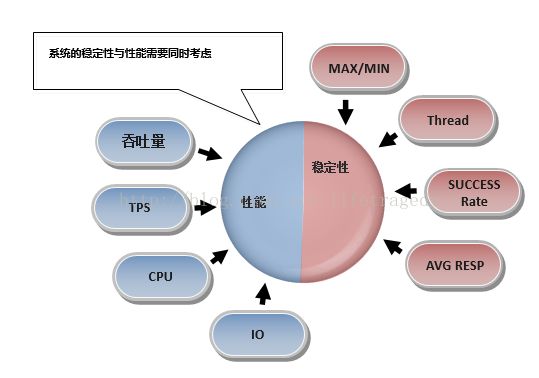
这些具体指标干什么的,在我的架构师之路头四篇里已经做了详细的说明,这篇因为是后续系列的导论,因此只做方法论的解释。
看几个极端调优实例报告吧
报告一、
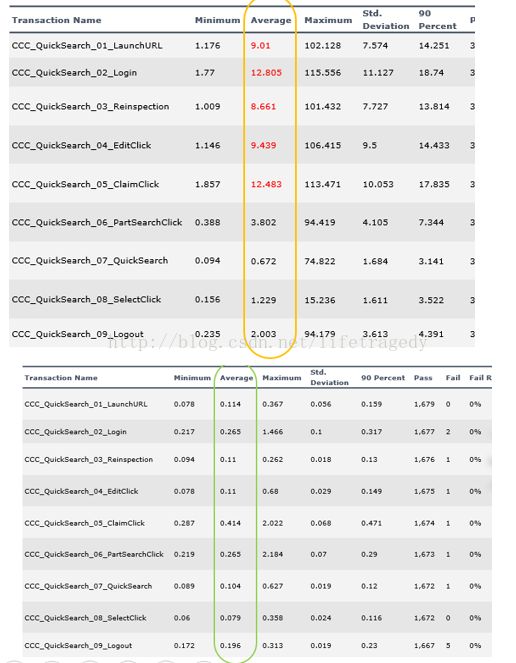
从12.483秒到0.414提高了多少倍?2000%以上的效率吧,是吧?
报告二、
再来看一个
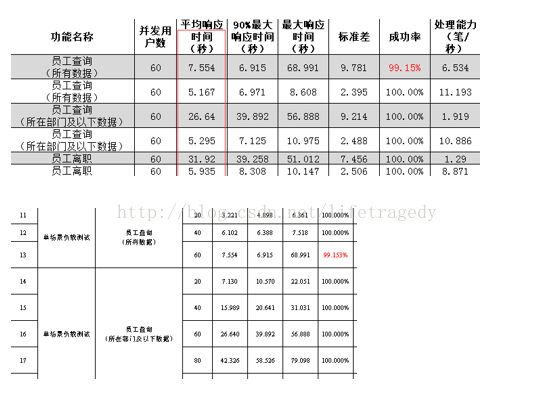
灰的和白的是调优前和调优后,对比一下看看31.92秒到5.935秒的单功能调优提高了多少?
香不香?
不断加集群有时不一定好过单机
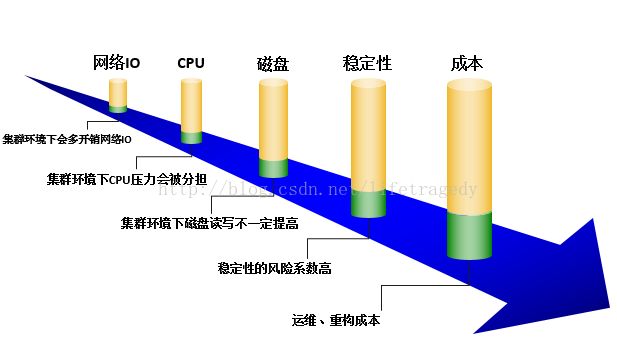
上文所述:我们不是大厂,我们没有这么巨大的资金去投入到硬件上。因此在后续很多很多生产实际问题出现时,其实可以通过堆硬件解决的我们做不了。
我们是极限调优,因此我们的技术能力不比大厂差!我甚至连JVM的BUG、NETTY的BUG、JAVA的限制都碰到了。因此竟然自己动手改底层、或者想其它办法去做规避、或者集中打攻坚战解决这种这么层底的问题。
我们的技术人员,千万不要动不动就是用集群、加集群,要知道集群后网络间的来回心跳同步、磁盘的开销是高于单机的,包括运维与监控的复杂度与成本,请考虑一下ROI的问题。
因此,在你没有极端调优到最优的情况下先请不要把加集群、加机器作为你的首选优化方案。
Redis Mongo会用用得好就够了吗
网上一堆Redis精通、彻底搞懂Redis、唯快不破一类的文章。
全读会了,用好了。。。真的就够了吗?
有人这边要说了:我都用得好了,还不够?
差远了,真的。我说过了,很多问题你不碰到这些场景,你根本想像不到原来还有这样那样、这些那些的种种注意点。后面会按照实际发生的案例来展开。
MQ的使用场景你确认你真的懂了吗
MQ被大量用在解耦上,我告诉你如果瞬时有一千万条数据冲入MQ,你猜猜看会发生什么。
知道ELK用在搜索场景可是你真的用好了吗
在这个案例里我会讲一个实际零售案例,在这种实际案例中你可以感受到需要知道和补充的点太多太多。
600万行代码的系统,如何像犁地一样层层调优
我经历的每一个系统都超过了600万行代码(仅仅是后端还没算前端),不影响生产、不影响业务日常功能你还要不断的去调优以满足一会一个大促、一会一个领券、一会一个什么第三方渠道引过来的流的这些功能开发呢?这里面既有项目又有技术管理还有方法论。
上千万的请求涌过来时你的流量要还是不要
不要,可能这里面真的是业务流量呢?
要,你的系统得要多少千个服务实例?
体系化建设你的技术生态,而忌用折东墙补西墙、眉毛胡子一把抓的方法
我们经历过的案例虽构不上拍案惊奇,也称不上波澜壮阔。但是团队打得很顽强、打得很坚苦。从没有动用过超过7位数的硬件投入的情况下我们还能达到一线团队该有的技术和性能性能、案全应对能力。甚至调优过程中我们还竟然在不断的缩硬件,这个在很多人看来是不可能和想像不到的一件事。
因为之前经历过家乐福的相关安全、性能保卫战,因此在我制作第三个零售全渠道中台时,我把技术团队的整体素质模型归纳成了这么一个“技术人员能力素质模型”,这只是从纯技术角度去考虑人材梯队的建设的。
在后面我也会着重讲述这样的能力素质模型我们是如何一步步去迈进和做到的。
结束语同时也是新篇章的开启
高性能系统并非一蹴而就,它是一个体系化工程,非单个单个的技术累加就能解决。所以我以此篇开章引出另一个系列即:高性能高并发系统调优的话题。后面我会结合实际发生场景进行详细介绍。