NNDL 作业7:第五章课后题

目录
习题5-2 证明宽卷积具有交换性,即公式:
习题5-3 分析卷积神经网络中用1×1的卷积核的作用
参考
习题5-4 对于一个输入为100×100×256的特征映射组,使用3×3的卷积核,输出为100×100×256的特征映射组的卷积层,求其时间和空间复杂度。如果引入一个1×1的卷积核,先得到100×100×64的特征映射,再进行3×3的卷积,得到100×100×256的特征映射组,求其时间和空间复杂度
习题5-7 忽略激活函数,分析卷积网络中卷积层的前向计算和反向传播是一种转置关系
推导CNN反向传播算法(选做)
1、已知池化层的误差,反向推导上一隐藏层的误差
2、已知卷积层的误差,反向推导上一隐藏层的误差
3、已知卷积层的误差,推导该层的W,b的梯度
设计简易CNN模型,分别用Numpy、Pytorch实现卷积层和池化层的反向传播算子,并代入数值测试.(选做)
总结
习题5-2 证明宽卷积具有交换性,即公式:
![]()
证明:
现有
根据宽卷积定义

为了让x的下标形式和w的进行对换,进行变量替换
令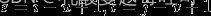
故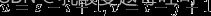
则
已知
![i \in [1,M]J,J \in [1,N]](http://img.e-com-net.com/image/info8/e36826124105446eb032ab6dae12e9cd.jpg)
因此对于
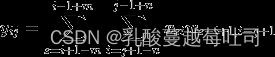
由于宽卷积的条件,s和t的变动范围是可行的。
习题5-3 分析卷积神经网络中用1×1的卷积核的作用
降维(缩减网络通道数,减少参数,减少计算量)
升维(用最少的参数拓宽网络channal)
跨通道信息交互(channal的变换)
添加非线性特性(可以增加网络深度)
1、增加网络的深度,添加非线性
其一:
这个就比较好理解了,1x1 的卷积核虽小,但也是卷积核,加 1 层卷积,网络深度自然会增加。
其实问题往下挖掘,应该是增加网络深度有什么好处?为什么非要用 1x1 来增加深度呢?其它的不可以吗?
其实,这涉及到感受野的问题,我们知道卷积核越大,它生成的 featuremap 上单个节点的感受野就越大,随着网络深度的增加,越靠后的 featuremap 上的节点感受野也越大。因此特征也越来越形象,也就是更能看清这个特征是个什么东西。层数越浅,就越不知道这个提取的特征到底是个什么东西。

解释:
好比以上这个图,当层数越浅时,我们只能看到low level parts 也就是一些细节的纹理,并不知道这个纹理是来自于车轮,车身,还是其他哪里。但是随着网络层数的加深,感受野增大,到了mid level parts时,就可以看到车的一部分零件了,比如看到了车轮,车窗,但是看不完。到了层数很深后,就是high level parts了,可以看到这个物品是个完整的车子,或者是其他一个什么东西。
其二:
但有的时候,我们想在不增加感受野的情况下,让网络加深,为的就是引入更多的非线性。而 1x1 卷积核,恰巧可以办到。
我们知道,卷积后生成图片的尺寸受卷积核的大小和卷积核个数影响,但如果卷积核是 1x1 ,个数也是 1,那么生成后的图像长宽不变,厚度为1。
但通常一个卷积层是包含激活和池化的。也就是多了激活函数,比如 Sigmoid 和 Relu。
所以,在输入不发生尺寸的变化下,加入卷积层的同时引入了更多的非线性,这将增强神经网络的表达能力。
2、升维或者降维
在这里插入图片描述

我们可以直观地感受到卷积过程中:卷积后的的 featuremap 通道数是与卷积核的个数相同的
所以,如果输入图片通道是 3,卷积核的数量是 6 ,那么生成的 feature map 通道就是 6,这就是升维,如果卷积核的数量是 1,那么生成的 feature map 只有 1 个通道,这就是降维度。
值得注意的是,所有尺寸的卷积核都可以达到这样的目的。
3、跨通道信息交互(channal 的变换)
例子:使用1*1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3*3,64channels的卷积核后面添加一个1*1,28channels的卷积核,就变成了3*3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互。
注意:只是在channel维度上做线性组合,W和H上是共享权值的sliding window
参考
卷积神经网络中1*1卷积的作用_m0_61899108的博客-CSDN博客
(1条消息) 卷积神经网络CNN中1×1卷积作用理解_青衫憶笙的博客-CSDN博客_在cnn中使用1*1卷积时
习题5-4 对于一个输入为100×100×256的特征映射组,使用3×3的卷积核,输出为100×100×256的特征映射组的卷积层,求其时间和空间复杂度。如果引入一个1×1的卷积核,先得到100×100×64的特征映射,再进行3×3的卷积,得到100×100×256的特征映射组,求其时间和空间复杂度
时间复杂度一:![]()
空间复杂度一:![]()
时间复杂度二:![]()
空间复杂度二:![]()
习题5-7 忽略激活函数,分析卷积网络中卷积层的前向计算和反向传播是一种转置关系
以一个3×3的卷积核为例,输入为X输出为Y


将4×4的输入特征展开为16×1的矩阵,y展开为4×1的矩阵,将卷积计算转化为矩阵相乘
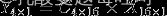



由
而
即
所以
忽略激活函数时卷积网络中卷积层的前向计算和反向传播是一种转置关系。
推导CNN反向传播算法(选做)
1、已知池化层的误差,反向推导上一隐藏层的误差
在前向传播算法时,池化层一般我们会用MAX或者Average对输入进行池化,池化的区域大小已知。现在我们反过来,要从缩小后的误差,还原前一次较大区域对应的误差。
在反向传播时,我们首先会把的所有子矩阵矩阵大小还原成池化之前的大小,然后如果是MAX,则把的所有子矩阵的各个池化局域的值放在之前做前向传播算法得到最大值的位置。如果是Average,则把的所有子矩阵的各个池化局域的值取平均后放在还原后的子矩阵位置。这个过程一般叫做upsample。
用一个例子可以很方便的表示:假设我们的池化区域大小是2x2。的第k个子矩阵为:

如果池化区域表示为a*a大小,那么我们把上述矩阵上下左右各扩展a-1行和列进行还原:

如果是MAX,假设我们之前在前向传播时记录的最大值位置分别是左上,右下,右上,左下,则转换后的矩阵为:

如果是Average,则进行平均,转换后的矩阵为:

上边这个矩阵就是误差矩阵经过upsample之后的矩阵,那么,由后一层误差推导出前一层误差的公式为:

2、已知卷积层的误差,反向推导上一隐藏层的误差
公式如下:
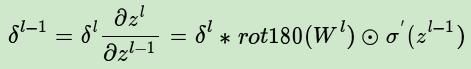
这里的式子其实和DNN的类似,普通网络的反向推导误差的公式:

区别在于对于含有卷积的式子求导时,卷积核被旋转了180度。即式子中的rot180(),翻转180度的意思是上下翻转一次,接着左右翻转一次。在DNN中这里只是矩阵的转置。
3、已知卷积层的误差,推导该层的W,b的梯度
经过以上各步骤,我们已经算出每一层的误差了,那么:
- 对于全连接层,可以按照普通网络的反向传播算法求该层W,b的梯度。
- 对于池化层,它并没有W,b,也不用求W,b的梯度。
- 只有卷积层的W,b需要求出,先看w:

再对比一下普通网络的求w梯度的公式,发现区别在于,对前一层的输出做翻转180度的操作:
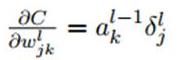
而对于b,则稍微有些特殊,因为在CNN中,误差δ是三维张量,而b只是一个向量,不能像普通网络中那样直接和误差δ相等。通常的做法是将误差δ的各个子矩阵的项分别求和,得到一个误差向量,即为b的梯度:
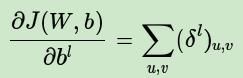
设计简易CNN模型,分别用Numpy、Pytorch实现卷积层和池化层的反向传播算子,并代入数值测试.(选做)
卷积层的反向传播:
import numpy as np
import torch.nn as nn
class Conv2D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(Conv2D, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.ksize = kernel_size
self.stride = stride
self.padding = padding
self.weights = np.random.standard_normal((out_channels, in_channels, kernel_size, kernel_size))
self.bias = np.zeros(out_channels)
self.grad_w = np.zeros(self.weights.shape)
self.grad_b = np.zeros(self.bias.shape)
def forward(self, x):
self.x = x
weights = self.weights.reshape(self.out_channels, -1) # o,ckk
x = np.pad(x, ((0, 0), (0, 0), (self.padding, self.padding), (self.padding, self.padding)), 'constant',
constant_values=0)
b, c, h, w = x.shape
self.out = np.zeros(
(b, self.out_channels, (h - self.ksize) // self.stride + 1, (w - self.ksize) // self.stride + 1))
self.col_img = self.im2col(x, self.ksize, self.stride) # bhw * ckk
out = np.dot(weights, self.col_img.T).reshape(self.out_channels, b, -1).transpose(1, 0, 2)
self.out = np.reshape(out, self.out.shape)
return self.out
def backward(self, grad_out):
b, c, h, w = self.out.shape #
grad_out_ = grad_out.transpose(1, 0, 2, 3) # b,oc,h,w * (bhw , ckk)
grad_out_flat = np.reshape(grad_out_, [self.out_channels, -1])
self.grad_w = np.dot(grad_out_flat, self.col_img).reshape(self.grad_w.shape)
self.grad_b = np.sum(grad_out_flat, axis=1)
tmp = self.ksize - self.padding - 1
grad_out_pad = np.pad(grad_out, ((0, 0), (0, 0), (tmp, tmp), (tmp, tmp)), 'constant', constant_values=0)
flip_weights = np.flip(self.weights, (2, 3))
# flip_weights = np.flipud(np.fliplr(self.weights)) # rot(180)
flip_weights = flip_weights.swapaxes(0, 1) # in oc
col_flip_weights = flip_weights.reshape([self.in_channels, -1])
weights = self.weights.transpose(1, 0, 2, 3).reshape(self.in_channels, -1)
col_grad = self.im2col(grad_out_pad, self.ksize, 1) # bhw,ckk
# (in,ckk) * (bhw,ckk).T
next_eta = np.dot(weights, col_grad.T).reshape(self.in_channels, b, -1).transpose(1, 0, 2)
next_eta = np.reshape(next_eta, self.x.shape)
return next_eta
def zero_grad(self):
self.grad_w = np.zeros_like(self.grad_w)
self.grad_b = np.zeros_like(self.grad_b)
def update(self, lr=1e-3):
self.weights -= lr * self.grad_w
self.bias -= lr * self.grad_b
def im2col(self, x, k_size, stride):
b, c, h, w = x.shape
image_col = []
for n in range(b):
for i in range(0, h - k_size + 1, stride):
for j in range(0, w - k_size + 1, stride):
col = x[n, :, i:i + k_size, j:j + k_size].reshape(-1)
image_col.append(col)
return np.array(image_col)
class Layers():
def __init__(self, name):
self.name = name
# 前向
def forward(self, x):
pass
# 梯度置零
def zero_grad(self):
pass
# 后向
def backward(self, grad_out):
pass
# 参数更新
def update(self, lr=1e-3):
pass
class Module():
def __init__(self):
self.layers = [] # 所有的Layer
def forward(self, x):
for layer in self.layers:
x = layer.forward(x)
return x
def backward(self, grad):
for layer in reversed(self.layers):
layer.zero_grad()
grad = layer.backward(grad)
def step(self, lr=1e-3):
for layer in reversed(self.layers):
layer.update(lr)
# test_conv
if __name__ == '__main__':
x = np.array([[[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]]])
conv = Conv2D(2, 3, 2, 1, 0)
y = conv.forward(x)
print(y.shape)
loss = y - (y + 1)
grad = conv.backward(loss)
print(grad.shape)池化层的反向传播:
import numpy as np
import torch.nn as nn
class MaxPooling(nn.Module):
def __init__(self, ksize=2, stride=2):
super(MaxPooling,self).__init__()
self.ksize = ksize
self.stride = stride
def forward(self, x):
n,c,h,w = x.shape
out = np.zeros([n, c, h//self.stride,w//self.stride])
self.index = np.zeros_like(x)
for b in range(n):
for d in range(c):
for i in range(h//self.stride):
for j in range(w//self.stride):
_x = i*self.stride
_y = j*self.stride
out[b, d ,i , j] = np.max(
x[b, d ,_x:_x+self.ksize, _y:_y+self.ksize])
index = np.argmax(x[b, d ,_x:_x+self.ksize, _y:_y+self.ksize])
self.index[b,d,_x+index//self.ksize, _y+index%self.ksize] = 1
return out
def backward(self, grad_out):
return np.repeat(np.repeat(grad_out, self.stride, axis=2), self.stride, axis=3) * self.index总结
本次作业推导了宽卷积的交换性和CNN的反向传播算法,通过推导理解反向传播的公式和含义,加深了印象,同时对于1*1的卷积核的作用有了清晰了解。