[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第1张图片](http://img.e-com-net.com/image/info8/f31075380d534a37bcd3478a9fba77ec.jpg)
前言
系列文章目录
[Python]目录
视频及资料和课件
链接:https://pan.baidu.com/s/1LCv_qyWslwB-MYw56fjbDg?pwd=1234
提取码:1234
文章目录
- 前言
- 数据、文献
- 1. 缺失值处理
- 1.1 缺失值删除
- 1.1.1 适用情况
- 1.1.2 代码实现
- 1.1.2.1 情况一代码
- 1.1.2.2 情况二代码
- 1.2 缺失值填补
- fillna()
- 1.2.1 使用常数填补缺失值
- 1.2.2 使用上一个或下一个非缺失值填补
- 1.2.3 使用平均值填补缺失值
- 1.2.4 使用众数填补缺失值
- 1.2.5 使用中位数填补缺失值
- 1.2.6 使用缺失值前一个与后一个非缺失值的均值填补
- 1.2.7 使用拉格朗日插值法对缺失值进行填补
- 1.2.7.1 拉格朗日插值法
- 1.2.7.2 代码
- 1.2.8 使用预测模型对缺失值进行填补
- 2. 异常值处理
- 2.1 异常值的检测
- 2.1.1 3σ 准则(拉依达准则)
- 相关概念
- 数据分布图绘制
- 2.1.2 箱线图检测
- 相关概念
- 箱线图绘制
- 2.2 异常值的处理
- 2.2.1 对不在指定取值范围内的异常值处理
- 删除异常值
- 异常值置为空值
- 2.2.2 基于 3σ 准则(拉依达准则)的异常值处理
- 2.2.3 基于箱线图检测的异常值处理
- 3. 重复值处理
返回文章目录
数据、文献
数据、文献:
「[Python] 数据预处理(缺失…异常值、重复值)」
返回文章目录
1. 缺失值处理
- 对于缺失值一般有两种处理方式:
- 1.将缺失值直接删除
- 2.对缺失值进行填补
返回文章目录
1.1 缺失值删除
返回文章目录
1.1.1 适用情况
- 对于缺失值采用直接删除的方式进行处理有如下几种情况:
-
1.对于数据表中的一行,如果整行数据缺失,或者是在一行中所需要使用的数据列对应的数据缺失,那么可以将这一行直接进行删除。
如:![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第2张图片](http://img.e-com-net.com/image/info8/42b0a7a108f04bb29a9614bbbe6e2fba.png)
-
2.如果在一行或者一列中存在大量的数据缺失,那么可以对该行或该列直接进行删除。
在一行或一列中,数据的缺失量是否达到需要删除该行或该列,需要视情况而定,这没有十分准确的标准。
如:
表1:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第3张图片](http://img.e-com-net.com/image/info8/3db6f11326af4e8f918dfeddea80755b.png)
表2:![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第4张图片](http://img.e-com-net.com/image/info8/0255829229f74d09958a54a149ec765c.jpg)
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第5张图片](http://img.e-com-net.com/image/info8/12cc43037a494bb1b055063e89180d68.jpg)
-
返回文章目录
1.1.2 代码实现
返回文章目录
1.1.2.1 情况一代码
通过调用 dropna() 方法,删除整行数据缺失的行,或者在一行中所需要使用的数据列对应的数据缺失的行。
- dropna():
- 参数:
- axis:表示轴向,0为删除行,1为删除列,默认为0.
- how:接收 string 类型的数据为参数,表示删除的方式,any 表示只要有缺失值就删除该行或列,all表示全部为缺失值才删除行或列。默认为any。
- subset:接收 array 类型的数据为参数,表示进行缺失值处理的行或列,默认为None,表示所有的行或列。
- inplace:表示是否在原表上进行操作,默认为False。
# 包的导入
import pandas as pd
# 读取数据
data = pd.read_excel('../../监测点C逐日污染物浓度实测数据.xlsx')
# 删除数据缺失的行
# 当 subset 指定的列全部缺失才删除对应的行
data_new = data.dropna(
how='all',
subset=[
'SO2实测日均(μg/m³)',
'NO2实测日均(μg/m³)',
'PM10实测日均(μg/m³)',
'PM2.5实测日均(μg/m³)',
'O3实测八小时滑动平均日最大值(μg/m³)',
'CO实测日均(mg/m³)'
]
)
# print(data_new)
# 导出处理后的数据
data_new.to_excel('./1.xlsx')
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第7张图片](http://img.e-com-net.com/image/info8/89813af5d7f94025b87aeba7b9cfa876.jpg)
返回文章目录
1.1.2.2 情况二代码
-
如果在一行中存在大量的数据缺失,直接删除该行。
数据表表1
中一共有8列数据,除去第一第二列,剩下六列数据,当一行中缺失的数据大于等于4个时,将该行删除。先调用 apply() 方法对数据表的每行进行处理,然后再对数据表中需要删除的行进行删除。
- apply():
- 参数:
- func:接收一个函数作为参数,该函数为对数据表中的每行或每列进行处理的函数,该函数接收有一个参数,用于接收传入的数据表中的行或列。
- axis:轴向,axis=1表示对数据表中的每行进行处理,axis=0表示对数据表中的每列进行处理。
# 包的导入 import pandas as pd import numpy as np # 读取数据 data = pd.read_excel('../../监测点C逐日污染物浓度实测数据.xlsx') # 当一行中的数据,除去第一第二列, # 缺失的数据个数大于等于4(该表中一共8列数据) # 返回空行 # 否则将原来的行返回 def fun(row): sub_row = row[2:] cnt = sub_row.count() if cnt<=2 : # return None return np.nan else : return row # 调用 apply() 方法对每行数据进行处理 re = data.apply(fun, axis=1) # 删除整行数据为空的行,直接修改原表 re.dropna(how='all', inplace=True)![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第9张图片](http://img.e-com-net.com/image/info8/42b84654c0cf47c691d5311217243d1b.jpg)
-
如果在一列中存在大量的数据缺失,直接删除该列。
通过对表2
中,每列非空数据的统计,发现湿度这一列存在大量的数据缺失,所以将这列数据整列进行删除。
- 删除指定列的方法:
- pop():
- pop() 方法一次只能删除一列数据,且是对原数组直接进行列的删除,同时会返回删除的列的数据。
- 参数:
- item:需要删除的列的列名。
- drop():
- drop() 方法支持多列删除,不对原数组直接进行列的删除,会返回一个删除指定列后的新数组。
- 参数:
- labels:接收一个字符串类型数据或一个序列为参数,表示要删除的列。
- axis:轴向,axis=1表示对列进行删除,axis=0表示对行进行删除。
(1)使用 pop() 方法删除指定列:
# 包的导入 import pandas as pd # 读取数据 data = pd.read_excel('../../监测点C逐小时污染物浓度与气象实测数据.xlsx') # 删除指定列 data.pop('湿度(%)') data![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第12张图片](http://img.e-com-net.com/image/info8/bff39c256110405eae2ad58ce689074a.jpg)
(2)使用 drop() 方法删除指定列:
# 包的导入 import pandas as pd # 读取数据 data = pd.read_excel('../../监测点C逐小时污染物浓度与气象实测数据.xlsx') # 删除指定列 re = data.drop('湿度(%)', axis=1) re# 包的导入 import pandas as pd # 读取数据 data = pd.read_excel('../../监测点C逐小时污染物浓度与气象实测数据.xlsx') # 删除指定列 re = data.drop(['湿度(%)'], axis=1) re(3)使用 apply() 方法对每列进行处理,然后使用 dropna() 方法删除数据量缺失过大的列:
- apply():
- 参数:
- func:接收一个函数作为参数,该函数为对数据表中的每行或每列进行处理的函数,该函数接收有一个参数,用于接收传入的数据表中的行或列。
- axis:轴向,axis=1表示对数据表中的每行进行处理,axis=0表示对数据表中的每列进行处理。
- dropna():
- 参数:
- axis:表示轴向,0为删除行,1为删除列,默认为0.
- how:接收 string 类型的数据为参数,表示删除的方式,any 表示只要有缺失值就删除该行或列,all表示全部为缺失值才删除行或列。默认为any。
- subset:接收 array 类型的数据为参数,表示进行缺失值处理的行或列,默认为None,表示所有的行或列。
- inplace:表示是否在原表上进行操作,默认为False。
假设数据的缺失达到0.3为数据缺失过多,需要将该列进行删除。
湿度这列非空的数据个数为13310,表2中的总行数为19491,湿度列的数据缺失已达0.3,所有要将湿度这一列进行删除。# 包的导入 import pandas as pd import numpy as np # 读取数据 data = pd.read_excel('../../监测点C逐小时污染物浓度与气象实测数据.xlsx') # 获取所有列中非空数据个数最多的列的数据个数 max_num = data.count().max() # 处理数据表中的每列 # 数据缺失过多,将整列修改为空 def fun(col): # print(col.count()) # 计算每列的非空数据个数 num = col.count() # 假设数据缺失达到0.3为数据缺失过多 # 需要对该列进行删除 if (num/max_num < 0.7): # 返回空 return np.nan else: return col # re = data.apply(fun) re = data.apply(fun, axis=0) # 删除整列为空的列 re.dropna(how='all', inplace=True, axis=1)![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第14张图片](http://img.e-com-net.com/image/info8/646a4ff678b64371ac459d3de1dd268a.jpg)
- 删除指定列的方法:
返回文章目录
1.2 缺失值填补
- 对缺失值进行填补,有如下几种方法:
- 1.使用一个常数对表中的所有缺失值进行填补。
- 2.使用缺失值所在的行或列的上一个或下一个非缺失值进行填补。
- 3.使用缺失值所在的行或列的平均值进行填补。
- 4.使用缺失值所在的行或列的众数进行填补。
- 5.使用缺失值所在的行或列的中位数进行填补。
- 6.使用缺失值所在的行或列的前一个和后一个非缺失值的均值进行填补。
- 7.使用拉格朗日插值法对缺失值进行填补
- 8.使用预测模型对缺失值进行填补
使用哪种缺失值填补方法对缺失值进行填补,需要根据数据所在的实际场景进行分析与选择,使得缺失值填补后,对最后的结果造成的影响尽可能的小。
一般缺失值的填补是针对存在少量数据缺失的行或列,或者是删除整行数据缺失的行和大量数据缺失的行与列后数据集中仍有部分数据缺失的行或列。
如:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第15张图片](http://img.e-com-net.com/image/info8/a5c6e4d01b624ee883dcd04f5a0ab9f8.jpg)
返回文章目录
fillna()
- 参数:
- value:表示用来替换缺失值的值
- method:接收 string 为参数,backfill或bfill表示使用下一个非缺失值进行替换,pad或ffill表示使用上一个非缺失值进行替换,默认为None
- axis:表示轴向,axis=1表示在一行中如果有缺失值,使用上一列或下一列的数据来填补缺失值;axis=0表示在一列中如果有缺失值,使用上一行或下一行的数据来填补缺失值。
- inplace:表示是否在原表上进行操作,默认为False。
- limit:表示填补缺失值的个数上限,默认为None
- value与method选择其一即可
以下的举例均不考虑实际的应用情况和实际场景。
每个例子使用的都为原始的表格,没有经过预处理。
返回文章目录
1.2.1 使用常数填补缺失值
调用 fillna() 方法,使用一个常数对数据表中所有的缺失值进行填补。
# 包的导入
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_excel('../../监测点C逐小时污染物浓度与气象实测数据.xlsx')
# 使用 999 填补数据表中的所有缺失值
re = data.fillna(value=999)
re
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第16张图片](http://img.e-com-net.com/image/info8/2b5ad90c61a9482d8943b4b37a69d974.jpg)
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第17张图片](http://img.e-com-net.com/image/info8/bc715b4cb83f4773bebc4a1e5804dd32.jpg)
返回文章目录
1.2.2 使用上一个或下一个非缺失值填补
调用 fillna() 方法,使用缺失值的上一个或下一个非缺失值对数据表中所有的缺失值进行填补。
由于湿度这一列第一行的数据为空,所以使用缺失值的下一行非缺失值对缺失的数据进行填补。
# 包的导入
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_excel('../../监测点C逐小时污染物浓度与气象实测数据.xlsx')
# 使用缺失值的下一行非缺失值填补数据表中的所有缺失值
re = data.fillna(method='bfill', axis=0)
re
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第19张图片](http://img.e-com-net.com/image/info8/cef62a21b19941d3a3007e3ac8146829.jpg)
返回文章目录
1.2.3 使用平均值填补缺失值
调用 fillna() 方法,使用每列的平均值对数据表中对应列的缺失值进行填补。
- mean():
- 获取调用该方法的数据集的一行或一列的平均值。
- axis:轴向,默认 axis=0 计算每列的算数平均数,axis=1 计算每行的算数平均数。
经过验证,调用 mean() 方法计算列的均值,空值(缺失值)不会计算在内。
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第20张图片](http://img.e-com-net.com/image/info8/3005480893e5467582ff135c4c4711e2.jpg)
# 包的导入
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_excel('../../监测点C逐小时污染物浓度与气象实测数据.xlsx')
# 由于表格中的部分缺失值使用字符串类型的'—' 'NULL' 'NA' 表示
# 所有先对这些数据进行处理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
# applymap() 方法会遍历并处理表格中每个单元格的数据
# fun 为传入的函数参数,用于处理每个单元格
# fun 函数会接收一个参数,为表格中每个单元格的数据
data = data.applymap(fun)
# 使用每列的均值对每列中的缺失值进行填补
# def fun_mean(col):
# 如果当前列是第二列直接退出函数
# 第二列的数据为字符串类型
# if (col.name == '地点'): return col
# col.fillna(value=col.mean(), inplace=True)
# return col
# re = data.apply(fun_mean)
# 循环处理第三列及往后的每列
# 使用每列的均值对每列中的缺失值进行填补
for col_name in data.columns[2:]:
# 当前要处理的列
col = data[col_name]
# 使用当前列的均值填补缺失值
col.fillna(value=col.mean(), inplace=True)
# 更新原数据表
data[col_name] = col
data
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第21张图片](http://img.e-com-net.com/image/info8/57218dc5c717465f891c74e96b033b52.jpg)
返回文章目录
1.2.4 使用众数填补缺失值
调用 fillna() 方法,使用每列的众数对数据表中对应列的缺失值进行填补。
- mode():
- 获取调用该方法的数据集的一行或一列的众数。如果个数最多的取值存在多个,则返回多个值。
- axis:轴向,默认 axis=0 获取每列的众数,axis=1 获取每行的众数。
湿度这一列的取值情况如下:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第22张图片](http://img.e-com-net.com/image/info8/50a5ddcfd4a54f9b99439120c2ae50da.jpg)
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第23张图片](http://img.e-com-net.com/image/info8/b75b63cd037c40e0a0d516c5a5b64d65.jpg)
# 包的导入
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_excel('../../监测点C逐小时污染物浓度与气象实测数据.xlsx')
# 由于表格中的部分缺失值使用字符串类型的'—' 'NULL' 'NA' 表示
# 所有先对这些数据进行处理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
# applymap() 方法会遍历并处理表格中每个单元格的数据
# fun 为传入的函数参数,用于处理每个单元格
# fun 函数会接收一个参数,为表格中每个单元格的数据
data = data.applymap(fun)
# 使用每列的众数对每列中的缺失值进行填补
def fun_(col):
# 获取第一个众数填补缺失值
col.fillna(value=col.mode()[0], inplace=True)
return col
re = data.apply(fun_)
re
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第24张图片](http://img.e-com-net.com/image/info8/43842bac7c164a988355daccd2bde76e.jpg)
返回文章目录
1.2.5 使用中位数填补缺失值
调用 fillna() 方法,使用每列的中位数对数据表中对应列的缺失值进行填补。
- median():
- 获取调用该方法的数据集的一行或一列的中位数。
- axis:轴向,默认 axis=0 获取每列的中位数,axis=1 获取每行的中位数。
湿度这一列的中位数如下:

# 包的导入
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_excel('../../监测点C逐小时污染物浓度与气象实测数据.xlsx')
# 由于表格中的部分缺失值使用字符串类型的'—' 'NULL' 'NA' 表示
# 所有先对这些数据进行处理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
# applymap() 方法会遍历并处理表格中每个单元格的数据
# fun 为传入的函数参数,用于处理每个单元格
# fun 函数会接收一个参数,为表格中每个单元格的数据
data = data.applymap(fun)
# 使用每列的中位数对每列中的缺失值进行填补
def fun_(col):
# 如果当前列是第二列直接退出函数
# 第二列的数据为字符串类型
if (col.name == '地点'): return col
col.fillna(value=col.median(), inplace=True)
return col
re = data.apply(fun_)
re
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第25张图片](http://img.e-com-net.com/image/info8/cc7519fe690c4190ac449ea74e7596ea.jpg)
返回文章目录
1.2.6 使用缺失值前一个与后一个非缺失值的均值填补
调用 interpolate() 方法,使用每列的缺失值前一个与后一个非缺失值的均值对数据表中对应列的缺失值进行填补。
如果第一行就存在缺失值,则本方法不适用,缺失值不会被填补,仍然为 NaN。
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第26张图片](http://img.e-com-net.com/image/info8/63b1084ba1c94a24831cb7daed78b6f4.jpg)
当前的测试数据如下:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第27张图片](http://img.e-com-net.com/image/info8/4871cce5860e476b8ab4bc5701b0c537.jpg)
# 包的导入
import pandas as pd
import numpy as np
# 读取数据
data = pd.read_excel('../../1.xlsx')
# 由于表格中的部分缺失值使用字符串类型的'—' 'NULL' 'NA' 表示
# 所有先对这些数据进行处理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
# applymap() 方法会遍历并处理表格中每个单元格的数据
# fun 为传入的函数参数,用于处理每个单元格
# fun 函数会接收一个参数,为表格中每个单元格的数据
data = data.applymap(fun)
# 使用每列的缺失值前一个与后一个非缺失值的均值
# 对每列中的缺失值进行填补
def fun_(col):
# 第一列为时间类型直接退出函数
if (col.name == '实测日期'): return col
# 如果当前列是第二列直接退出函数
# 第二列的数据为字符串类型
if (col.name == '地点'): return col
# col = col.interpolate()
# 直接修改原数据
col.interpolate(inplace=True)
return col
re = data.apply(fun_)
re
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第28张图片](http://img.e-com-net.com/image/info8/2ae5631d74774ca0b9f11b8e6b853f94.jpg)
返回文章目录
1.2.7 使用拉格朗日插值法对缺失值进行填补
以下内容来自:
[1]赵莉,孙娜,李丽萍,崔杰.拉格朗日插值法在数据清洗中的应用[J].辽宁工业大学学报(自然科学版),2022,42(02):102-105+117.DOI:10.15916/j.issn1674-3261.2022.02.007.
文献知网连接
返回文章目录
1.2.7.1 拉格朗日插值法
拉格朗日多项式插值法的基本思想是:给出一个恰好穿过二维平面上几个已知点的多项式,利用最小次数的多项式来构建一条光滑曲线,使曲线通
过所有已知点。
对于平面中的n个已知点(一条直线上无两点),可以找到一个n-1次多项式:
y = a 0 + a 1 x 2 + a 2 x + ⋯ + a n − 1 x n − 1 y=a_{0}+a_{1} x^{2}+a_{2} x+\cdots+a_{n-1} x^{n-1} y=a0+a1x2+a2x+⋯+an−1xn−1
使得此多项式对应的曲线通过这n个点。将n个点的坐标 ( x 1 x_1 x1, y 1 y_1 y1), ( x 2 x_2 x2, y 2 y_2 y2), …, ( x n x_n xn, y n y_n yn)代入多项式中得到:
y 1 = a 0 + a 1 x 1 + a 2 x 1 2 + a n − 1 x 1 n − 1 y 2 = a 0 + a 1 x 2 + a 2 x 2 2 + a n − 1 x 2 n − 1 … y n = a 0 + a 1 x n + a 2 x n 2 + a n − 1 x n n − 1 \begin{array}{c} y_{1}=a_{0}+a_{1} x_{1}+a_{2} x_{1}^{2}+a_{n-1} x_{1}^{n-1} \\ y_{2}=a_{0}+a_{1} x_{2}+a_{2} x_{2}^{2}+a_{n-1} x_{2}^{n-1} \\ \ldots \\ y_{n}=a_{0}+a_{1} x_{n}+a_{2} x_{n}^{2}+a_{n-1} x_{n}^{n-1} \end{array} y1=a0+a1x1+a2x12+an−1x1n−1y2=a0+a1x2+a2x22+an−1x2n−1…yn=a0+a1xn+a2xn2+an−1xnn−1
解得拉格朗日插值多项式如下:
L ( x ) = ∑ i = 0 n y i ∏ j = 0 , j ≠ i n x − x j x i − x j L(x)=\sum_{i=0}^{n} y_{i} \prod_{j=0, j \neq i}^{n} \frac{x-x_{j}}{x_{i}-x_{j}} L(x)=i=0∑nyij=0,j=i∏nxi−xjx−xj
例如,平面上有 4 个点,(4, 10)、(5, 5.25)、(6, 1)、(18, ?),根据拉格朗日插值法计算缺失“?”的值:
L ( x ) = 10 ( x − 5 ) ( x − 6 ) ( 4 − 5 ) ( 4 − 6 ) + 5.25 ( x − 4 ) ( x − 6 ) ( 5 − 4 ) ( 5 − 6 ) + ( x − 4 ) ( x − 5 ) ( 6 − 4 ) ( 6 − 5 ) = 1 4 ( x 2 − 28 x + 136 ) \begin{aligned} L(x)=& 10 \frac{(x-5)(x-6)}{(4-5)(4-6)}+5.25 \frac{(x-4)(x-6)}{(5-4)(5-6)}+\\ & \frac{(x-4)(x-5)}{(6-4)(6-5)}=\frac{1}{4}\left(x^{2}-28 x+136\right) \end{aligned} L(x)=10(4−5)(4−6)(x−5)(x−6)+5.25(5−4)(5−6)(x−4)(x−6)+(6−4)(6−5)(x−4)(x−5)=41(x2−28x+136)
将 x=18 代入可以得到 L(18)=-11,因此缺失的值是-11。
返回文章目录
1.2.7.2 代码
当前将要进行缺失值填补的数据:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第29张图片](http://img.e-com-net.com/image/info8/573b54c3808c4baca323d0ae892fea29.jpg)
为了防止取缺失值前后的非缺失值时索引越界,对文献中的代码进行了修改
import numpy as np
import pandas as pd
# 引入拉格朗日插值法所需的方法
from scipy.interpolate import lagrange
# 文件读取
data = pd.read_excel('../../1.xlsx')
# 字符串表示的空值预处理
def fun(x):
if (x=='—' or x=='NULL' or x=='NA'): return np.nan
else: return x
data = data.applymap(fun)
# 生成拉格朗日插值
def interpolate_columns(data_col, missing_val_idx, k=5):
"""
data_col: 需要进行缺失值填补的列
missing_val_idx: 数据缺失的单元格在该列对应的索引
k: 缺失值前后取值的个数, 默认为5个
return: 返回拉格朗日插值
"""
# 防止取缺失值前后的非缺失值时下标越界
# 向缺失值前取值的个数,默认为 k
f_k = k
# 如果缺失值前还有的数值个数小于 k
# 更改取值个数
if(missing_val_idx < k): f_k = missing_val_idx
# 向缺失值后取值的个数,默认为 k
b_k = k
# 如果缺失值后还有的数值个数小于 k
# 更改取值个数
if((data_col.size-missing_val_idx-1) < k): b_k = data_col.size-missing_val_idx-1
# 获取二者的较小值
if(f_k <= b_k): k = f_k
else: k = b_k
# 取出当前缺失值位置前后 k 个值
y = data_col[
list(range(missing_val_idx-k, missing_val_idx)) + list(range(missing_val_idx+1, missing_val_idx+1+k))
]
# 去除空值
y = y[ y.notnull() ]
# 生成拉格朗日插值函数
f = lagrange(y.index, list(y))
# 计算并返回缺失值将要填补的数据值
return f(missing_val_idx)
# 遍历数据表
# 每列
for i in data.columns[2:]:
# 遍历每列中的每个单元格
for j in range(data[i].size):
# 如果单元格为空
# 进行拉格朗日插值
if data[i].isnull()[j]:
data[i][j] = interpolate_columns(data[i], j)
data
此代码无法对数据表第一行与最后一行存在的缺失值进行填补,由于代码修改,当缺失值在第一行或最后一行时,取缺失值前后的非缺失值的个数为0,所以无法使用拉格朗日插值法进行数据的填补。
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第30张图片](http://img.e-com-net.com/image/info8/2b1dec397f6c47e3aed86671f754d67a.jpg)
文献中的代码:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第31张图片](http://img.e-com-net.com/image/info8/34af0e7602884dc3825f8280bb96f182.jpg)
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第32张图片](http://img.e-com-net.com/image/info8/9410e2331f9847e2a5c91fa5206aa6f0.jpg)
返回文章目录
1.2.8 使用预测模型对缺失值进行填补
预测模型较多,后面补上
返回文章目录
2. 异常值处理
返回文章目录
2.1 异常值的检测
- 检查数据集中的异常值,常用的方法有:
- 3σ 准则(拉依达准则)
- 箱线图检测
返回文章目录
2.1.1 3σ 准则(拉依达准则)
相关概念
3σ(西格玛)准则(拉依达准则) 是指先假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有该误差的数据应予以剔除。
这种判别处理原理及方法 仅局限于对正态或近似正态分布 的样本数据处理,它是 以测量次数充分大为前提 的,当测量次数少的情形用准则剔除粗大误差是不够可靠的。因此,在测量次数较少的情况下,最好不要选用该准则。
来源于百度百科 链接
在正态分布中:
| 符号 | 说明 |
|---|---|
| μ \mu μ | 数学期望(均值) |
| σ 2 {\sigma}^{2} σ2 | 方差 |
| σ \sigma σ | 标准差 |
x = μ x=\mu x=μ 为正态分布图像的对称轴。
数值分布在横轴区间 ( μ − σ , μ + σ ) (μ-σ,μ+σ) (μ−σ,μ+σ)内的概率为68.268949%。
数值分布在横轴区间 ( μ − 2 σ , μ + 2 σ ) (μ-2σ,μ+2σ) (μ−2σ,μ+2σ)内的概率为95.449974%。
数值分布在横轴区间 ( μ − 3 σ , μ + 3 σ ) (μ-3σ,μ+3σ) (μ−3σ,μ+3σ)内的概率为99.730020%。
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第33张图片](http://img.e-com-net.com/image/info8/e9b3de71b35445f1bf6f82610a156dc0.png)
“小概率事件”和假设检验的基本思想:“小概率事件” 通常指发生的概率小于5% 的事件,认为在一次试验中该事件是 几乎不可能发生 的。由此可见 X落在(μ-3σ,μ+3σ)以外 的概率小于千分之三,在实际问题中常认为相应的事件 不会发生 ,基本上可以把区间(μ-3σ,μ+3σ)看作是随机变量X实际可能的取值区间,这称之为正态分布的“3σ”原则。
来源于百度百科 链接
设对被测量进行等精度测量,独立得到 x 1 x_{1} x1, x 2 x_{2} x2,…, x n x_{n} xn,算出其算术平均值 x 及剩余误差 v i = x i − x v_{i} = x_{i} - x vi=xi−x (i=1,2,…,n),并按贝塞尔公式算出标准偏差 σ ,若某个测量值 x b x_{b} xb 的剩余误差 v b v_{b} vb (1<=b<=n),满足下式
∣ v b ∣ = ∣ x b − x ∣ > 3 σ |v_{b}|=|x_{b}-x|>3σ ∣vb∣=∣xb−x∣>3σ
则认为 x b x_{b} xb 是含有粗大误差值的坏值,应予剔除。
在整理试验数据时,往往会遇到这样的情况,即在一组试验数据里,发现少数几个偏差特别大的可疑数据,这类数据称为 Outlier 或 Exceptional Data ,他们往往是由于过失误差引起。
来源于百度百科 链接
数据分布图绘制
- seaborn.distplot():
- 参数:
- a:接收一维数组或列表为参数,为绘制图形的数据。
- hist:是否显示直方图,默认值为 True,默认情况下显示直方图。
- kde:是否显示核密度估计,默认值为 True,默认情况下显示核密度估计。
- bins:接收 int 或 list 类型的数据为参数,控制直方图的划分,即直方图有几柱。
- rug:是否绘制变量的分布情况,默认值为 False,默认情况下不显示。
- fit:
- hist_kws:接收字典类型的数据为参数,设置绘制的直方图的显示样式。
- kde_kws:接收字典类型的数据为参数,设置绘制的核密度估计的显示样式。
- rug_kws:接收字典类型的数据为参数,设置绘制的变量分布情况的显示样式。
- color:设置绘制图形的颜色。
- vertical:绘制的图形x轴与y轴是否进行对调,绘制的图形显示在x轴还是y轴,默认值为False,显示在x轴。
- norm_hist:控制直方图的高度(y轴)显示的是密度还是计数。在不含有核密度估计的图形中,默认为 False,显示的为计数。在含有核密度估计的图形中,默认为 True,显示的为密度。
- axlabel:接收字符串类型的数据为参数,用于设置x轴的标签。
- label:接收字符串类型的数据为参数,用于设置直方图的图例。
- ax:seaborn.distplot() 会返回一个坐标轴对象,可以用于设置图形的四个坐标轴。
参考:
【Python可视化 | Seaborn之seaborn.distplot()】鹿港小小镇
【sns.distplot()用法】小小喽啰
数据文件名:
监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_补全数据_去除负数.xlsx
这里只进行简单的测试,更加详细的测试【待写】
绘制 SO2监测浓度 的数据分布图
import pandas as pd
# 画图所需的包
import matplotlib.pyplot as plt
# 绘制数据分布图所需的包
import seaborn as sns
# 提高 matplotlib 在 jupyter 中作图的分辨率
%config InlineBackend.figure_format = 'retina'
# 处理中文与负号的显示问题
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
data = pd.read_excel('./监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_补全数据_去除负数.xlsx')
# 修改列名
data.columns = ['监测时间', '地点', 'SO2监测浓度', 'NO2监测浓度', 'PM10监测浓度',
'PM2.5监测浓度', 'O3监测浓度', 'CO监测浓度', '温度', '湿度',
'气压', '风速', '风向']
# 绘制数据分布图
# ax 接收返回的坐标轴对象
ax = sns.distplot(
# 绘制图形的数据
data['SO2监测浓度'],
# 直方图柱 20个
bins=20,
# 显示变量的分布情况
rug=True,
# 直方图样式设置
hist_kws={
'label': 'SO2监测浓度',
'color': 'red'
},
# 核密度估计曲线样式设置
kde_kws={
'label': 'SO2监测浓度核密度估计',
'color': 'green'
},
# 设置x轴的标签
axlabel= r'$SO_{2}$'
)
# 取消上轴和右轴的显示
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# 显示图例
plt.legend()
plt.show()
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第34张图片](http://img.e-com-net.com/image/info8/0ca37ee85238490aa0406681bb2bacde.jpg)
返回文章目录
2.1.2 箱线图检测
以下内容来自:
[1]孙向东,刘拥军,陈雯雯,贾智宁,黄保续.箱线图法在动物卫生数据异常值检验中的运用[J].中国动物检疫,2010,27(07):66-68.
知网文献链接
相关概念
箱线图(Boxplot)也称箱须图(Box-whisker Plot),是美国著名统计学家 John W. Tukey 于 1977 年发明的。箱线图法利用数据中的五个统计量:最小值、下四分位数(Q1)、中位数(Q2)、上四分位数(Q3)与最大值 来描述数据。
- 箱线图可用于:
- (1)鉴别数据中的异常值,包括离群值和极端值;
- (2) 判断数据的偏态和尾重;
- (3)比较几组数据的形状。
以下内容(本文)仅讨论其在异常值鉴别中的应用。
箱线图根据实际数据绘制,既 不需要事先假定数据服从特定的概率分布 ,也 没有对数据作任何限制性要求 ,能够真实、直观地表现数据形状的本来面貌。
箱线图判断异常值的标准以四分位数和四分位距为基础,较多数据的变化对四分位数影响不大,所以箱线图判断异常值的标准具有较强的鲁棒性(Robust),检测结果比较客观。
箱线图法采用中位数代替平均数检测异常值是统计检测方法上的一大改进。箱线图法能够有效克服数据中存在异常值时,不能测出异常值的这种掩盖效应(masking effect)。
箱线图的结构:
箱线图由参照系(坐标轴)、标志物(箱体、上下四分位线、中位线、异常值截断点)、检测数据(箱体两端的延伸线、异常值)三种成分构成,具体
见图1。
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第35张图片](http://img.e-com-net.com/image/info8/f4232d816e14412296bf1fe10c90296c.jpg)
其中 箱体的两端分别对应下四分位数 Q1 和上四分位数 Q3 , Q1和 Q3之间称作四分位距 (Inter Quartile Range,IQR)。 上四分位点右边 1.5倍 IQR 和下四分位点左边 1.5 倍 IQR位置对应的点是异常值截断点 ,异常值截断点之间是内限。上四分位点右边 3 倍 IQR 和下四分位点左边 3 倍IQR 位置对应的点是极端值截断点,极端值截断点之间是外限。
异常值截断点以外的数据称作异常值 ,其中在内限与外限之间的异常值为温和异常值或离群值(Outlier,mild outliers),在外限以外的为极端异常值或极端值(Extreme,extreme outliers)。
箱线图的结构与标准正态分布函数 N(0, 1) 之间的比较见图2。
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第36张图片](http://img.e-com-net.com/image/info8/dc6917abb52c4b2e97ef97a260da86a5.jpg)
其中 Q3 与 Q1 之间包含了 50%的数据点,异常值截断点之间包含了 99.3%的数据点,非异常值误判为异常值的概率不大于 0.7%。
箱线图的结构图
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第37张图片](http://img.e-com-net.com/image/info8/a6eea92eacfd43518f38f0981eb55609.jpg)
箱线图绘制
以下博客对于绘制箱线图的方法参数介绍的很详细,这里不在进行介绍。
-
matplotlib.pyplot.boxplot()
- 两篇文章中都有详细的方法参数说明
- 【python绘制箱线图boxplot()】小朱小朱绝不服输
- 【Python 箱型图的绘制并提取特征值】流浪猪头拯救地球
将方法的参数及其说明复制在这: x:指定要绘制箱线图的数据,可以是一组数据也可以是多组数据; notch:是否以凹口的形式展现箱线图,默认非凹口; sym:指定异常点的形状,默认为蓝色的+号显示; vert:是否需要将箱线图垂直摆放,默认垂直摆放; whis:指定上下须与上下四分位的距离,默认为1.5倍的四分位差; positions:指定箱线图的位置,默认为range(1, N+1),N为箱线图的数量; widths:指定箱线图的宽度,默认为0.5; patch_artist:是否填充箱体的颜色,默认为False; meanline:是否用线的形式表示均值,默认用点来表示; showmeans:是否显示均值,默认不显示; showcaps:是否显示箱线图顶端和末端的两条线,默认显示; showbox:是否显示箱线图的箱体,默认显示; showfliers:是否显示异常值,默认显示; boxprops:设置箱体的属性,如边框色,填充色等; labels:为箱线图添加标签,类似于图例的作用;即箱线图对应x轴点的名字 flierprops:设置异常值的属性,如异常点的形状、大小、填充色等; medianprops:设置中位数的属性,如线的类型、粗细等; meanprops:设置均值的属性,如点的大小、颜色等; capprops:设置箱线图顶端和末端线条的属性,如颜色、粗细等; whiskerprops:设置须的属性,如颜色、粗细、线的类型等; manage_ticks:是否自适应标签位置,默认为True; autorange:是否自动调整范围,默认为False; -
seaborn.boxplot()
- 第一篇文章有详细的方法参数说明及代码示例,第二篇文章主要是代码示例
- 【超详细Seaborn绘图 ——(二)boxplot & boxenplot】邱之涵0
- 【Python画箱型图之seaborn】随风而逝*
将方法的参数及其说明复制在这: x, y, hue:数据或向量数据中的变量名称 用于绘制长格式数据的输入。 data:DataFrame,数组,数组列表 用于绘图的数据集。 如果x和y都缺失,那么数据将被视为宽格式。 否则数据被视为长格式。 order, hue_order:字符串列表 控制分类变量(对应的条形图)的绘制顺序, 若缺失则从数据中推断分类变量的顺序。 orient:“v”或“h” 控制绘图的方向(垂直或水平)。 这通常是从输入变量的 dtype 推断出来的, 但是当“分类”变量为数值型或绘制宽格式数据时 可用于指定绘图的方向。 color:matplotlib颜色 所有元素的颜色,或渐变调色板的种子颜色。 palette:调色板名称,列表或字典 用于hue变量的不同级别的颜色。 可以从color_palette()得到一些解释, 或者将色调级别映射到matplotlib颜色的字典。 saturation:float 控制用于绘制颜色的原始饱和度的比例。 通常大幅填充在轻微不饱和的颜色下看起来更好, 如果您希望绘图颜色与输入颜色规格完美匹配 可将其设置为1。 width:float 不使用色调嵌套时完整元素的宽度, 或主要分组变量一个级别的所有元素的宽度。 dodge:bool 使用色调嵌套时,元素是否应沿分类轴移动。 fliersize:float 用于表示异常值观察的标记的大小。 linewidth:float 构图元素的灰线宽度。 whis:float 控制在超过高低四分位数时 IQR (四分位间距)的比例, 因此需要延长绘制的触须线段。超出此范围的点将被识别为异常值。 notch:boolean 是否使矩形框“凹陷”以指示中位数的置信区间。 还可以通过plt.boxplot的一些参数来控制 ax:matplotlib轴 绘图时使用的 Axes 轴对象,否则使用当前 Axes 轴对象 kwargs:键值映射 其他在绘图时传给plt.boxplot的参数 设置方法与 plt.boxplot 一样
数据文件名:
监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_补全数据_去除负数.xlsx
绘制 SO2监测浓度 的箱线图
测试一些经常会使用的参数和参数的常用设置
matplotlib.pyplot.boxplot()
import pandas as pd
# 画图所需的包
import matplotlib.pyplot as plt
# 提高 matplotlib 在 jupyter 中作图的分辨率
%config InlineBackend.figure_format = 'retina'
# 处理中文与负号的显示问题
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
data = pd.read_excel('./监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_补全数据_去除负数.xlsx')
# 修改列名
data.columns = ['监测时间', '地点', 'SO2监测浓度', 'NO2监测浓度', 'PM10监测浓度',
'PM2.5监测浓度', 'O3监测浓度', 'CO监测浓度', '温度', '湿度',
'气压', '风速', '风向']
# 绘制箱线图
plt.boxplot(
# 绘图数据
data['SO2监测浓度'],
# 箱子是否内凹
# notch=True,
# 设置异常点的形状
# sym='.',
# 填充箱体颜色
patch_artist=True,
# 显示平均值,默认使用点显示
showmeans=True,
# 设置箱子的宽度
widths=0.1,
# 设置箱子的样式,需要 patch_artist=True
boxprops={
# 箱子的边框为灰色
'color': 'gray',
# 箱子的填充色为橙色
'facecolor': 'orange',
# 设置边框线的宽度
'linewidth': '2'
},
# 设置异常值点的样式
flierprops={
# 设置点的形状
'marker': '.',
# 设置点的填充色
'markerfacecolor': 'blue',
# 设置点的边框色
'markeredgecolor': 'blue',
# 设置点的大小
'markersize': '2'
},
# 添加箱线图在x轴对应位置的名字
# x轴坐标点名
labels=['SO2监测浓度'],
# 设置须的样式
whiskerprops={
# 设置线的颜色
'color': 'green'
},
# 设置箱线图最值线的样式
capprops={
# 设置线的颜色
'color': 'red',
# 设置线的宽度
'linewidth': '3'
}
)
plt.grid(linestyle=':')
# 显示图例
plt.legend()
plt.show()
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第38张图片](http://img.e-com-net.com/image/info8/29e2f4fe8ad64f2786ae7095590d7305.jpg)
绘制 所有列 的箱线图
测试一些经常会使用的参数和参数的常用设置
seaborn.boxplot()
import pandas as pd
# 画图所需的包
import matplotlib.pyplot as plt
# 绘制数据分布图所需的包
import seaborn as sns
# 提高 matplotlib 在 jupyter 中作图的分辨率
%config InlineBackend.figure_format = 'retina'
# 处理中文与负号的显示问题
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
data = pd.read_excel('./监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_补全数据_去除负数.xlsx')
# 修改列名
data.columns = ['监测时间', '地点', 'SO2监测浓度', 'NO2监测浓度', 'PM10监测浓度',
'PM2.5监测浓度', 'O3监测浓度', 'CO监测浓度', '温度', '湿度',
'气压', '风速', '风向']
# 设置画布大小
plt.figure(figsize=(18, 5))
# 绘制箱线图
# 会返回一个坐标轴对象
ax = sns.boxplot(
# x = data['NO2监测浓度'],
# 绘图的数据
# y = data['SO2监测浓度'],
# 传入 DataFrame 类型的数据,会绘制每列的箱线图
data=data,
# 箱子的填充色
# 有多个箱子,多个箱子的颜色都会一致
# color='red',
# 设置调色板,会根据调色板的颜色映射规则对箱子填充颜色
palette='viridis',
# 设置箱子的宽度
width=0.7,
# 异常值点的大小
fliersize=2,
# 箱线图中边框、线的宽度
linewidth=1.2,
# 箱子内凹
notch=True,
# 其他样式设置, 与 matplotlib.pyplot.boxplot() 一样
# 显示均值
showmeans=True,
# 设置异常值点的样式
flierprops={
# 设置点的形状
'marker': '.',
# 设置点的填充色
'markerfacecolor': 'blue',
# 设置点的边框色
'markeredgecolor': 'blue',
# 设置点的大小
'markersize': '2'
}
)
# 取消上轴和右轴的显示
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
ax.spines['left'].set_color('none')
plt.grid(linestyle=':')
# 显示图例
plt.legend()
plt.show()
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第39张图片](http://img.e-com-net.com/image/info8/3a085d15226d4421a488213b8295d9f5.jpg)
返回文章目录
2.2 异常值的处理
- 需要进行异常值处理的情况,主要有如下几种:
- 1.数值的取值范围有明确的要求,对于不在要求的取值范围内的数据可以进行异常值的处理。如,要求取值要为正数,对于取值为负数的数值需要进行处理。
- 2.使用 3σ 准则(拉依达准则)检测异常值,对于落在(μ-3σ,μ+3σ)以外的数据需要进行异常值处理。
- 3.使用箱线图检测异常值,对于落在异常值截断线以外的数据需要进行异常值处理。
- 异常值处理的方式:
- 1.直接将异常值删除。
- 2.将异常值置为空,采用缺失值填补的方法对异常值进行替换。
返回文章目录
2.2.1 对不在指定取值范围内的异常值处理
数据文件名:
监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_数据填补.xlsx
data['SO2监测浓度(μg/m³)'].value_counts()
统计 SO2监测浓度(μg/m³) 的取值情况:
存在16个数据取值为负数,由于浓度大于等于0,所以对取值为负数的异常值进行处理。
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第40张图片](http://img.e-com-net.com/image/info8/90034d4f1c394d34ad322d1af9d9ca51.jpg)
未处理前的数据情况:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第41张图片](http://img.e-com-net.com/image/info8/daf65264e9d64272b5faeaba0c55f450.jpg)
返回文章目录
删除异常值
由于 SO2监测浓度(μg/m³) 取值为负数的数据个数并不多,所以将 SO2监测浓度(μg/m³) 取值为负数的行直接删除。
# 包的引入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取数据
data = pd.read_excel('../22/监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_数据填补.xlsx')
# 删除 SO2监测浓度(μg/m³) 取值为负数的行
# 即取出 SO2监测浓度(μg/m³) 取值大于等于0的行
re = data[data['SO2监测浓度(μg/m³)']>=0]
re.count()
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第42张图片](http://img.e-com-net.com/image/info8/fc1b9b074f2a45b2a014aaf733bb77f1.jpg)
返回文章目录
异常值置为空值
未处理前的数据情况:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第43张图片](http://img.e-com-net.com/image/info8/2ade06a53dd94498b3b69d2f1fe8cb1c.jpg)
# 包的引入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 读取数据
data = pd.read_excel('../22/监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_数据填补.xlsx')
# 深复制一份数据
data1 = data.copy()
# 将 SO2监测浓度(μg/m³) 列中取值为负数的数据置为空值
data1['SO2监测浓度(μg/m³)'][data1['SO2监测浓度(μg/m³)']<0] = pd.NA
data1.count()
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第44张图片](http://img.e-com-net.com/image/info8/8dfec6a038a24f1889d61dd13a4409f0.jpg)
返回文章目录
2.2.2 基于 3σ 准则(拉依达准则)的异常值处理
这里只进行异常值的筛选,不进行处理,若要处理可以采用与 2.2.1 中类似的方法进行处理,删除异常值或者置为空值后填补异常值。
# 包的引入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 提高 matplotlib 在 jupyter 中作图的分辨率
%config InlineBackend.figure_format = 'retina'
# 处理中文与负号的显示问题
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
data = pd.read_excel('../22/监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_数据填补.xlsx')
# 获取 SO2监测浓度(μg/m³) 列
so2 = data['SO2监测浓度(μg/m³)']
# 计算均值与标准差
mean_so2 = so2.mean()
std_so2 = so2.std()
print(mean_so2, std_so2)
# 计算 μ-3σ μ+3σ
left = mean_so2 - 3*std_so2
right = mean_so2 + 3*std_so2
# 绘制数据分布图
# ax 接收返回的坐标轴对象
ax = sns.distplot(
# 绘制图形的数据
data['SO2监测浓度(μg/m³)'],
# 显示变量的分布情况
rug=True,
# 设置x轴的标签
axlabel= r'$SO_{2}$'
)
# 绘制 μ-3σ μ+3σ
plt.axvline(left, linestyle='--', color='orange')
plt.axvline(right, linestyle='--', color='orange')
# 显示图例
plt.legend()
plt.show()
# 复制数据集
data1 = data.copy()
# 筛选出 SO2监测浓度(μg/m³) 列取值不在 (μ-3σ, μ+3σ) 内的行
data1 = data1[np.abs(data1['SO2监测浓度(μg/m³)']-mean_so2) > 3*std_so2]
data1
均值与标准差
基于 3σ 准则(拉依达准则) 筛选出的 SO2监测浓度(μg/m³) 取值异常的行:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第45张图片](http://img.e-com-net.com/image/info8/bae1c75a145e44ae9c84e8ee4cb70c5b.jpg)
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第46张图片](http://img.e-com-net.com/image/info8/f8d7b4c91da44fc998b19fdae16db77e.jpg)
返回文章目录
2.2.3 基于箱线图检测的异常值处理
这里只进行异常值的筛选,不进行处理,若要处理可以采用与 2.2.1 中类似的方法进行处理,删除异常值或者置为空值后填补异常值。
# 包的引入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 提高 matplotlib 在 jupyter 中作图的分辨率
%config InlineBackend.figure_format = 'retina'
# 处理中文与负号的显示问题
plt.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# 读取数据
data = pd.read_excel('../22/监测点A逐小时污染物浓度与气象实测数据_去除整行缺失_数据填补.xlsx')
# 获取 SO2监测浓度(μg/m³) 列
so2 = data['SO2监测浓度(μg/m³)']
# 绘制箱线图
plt.boxplot(
# 绘图数据
so2,
# 填充箱体颜色
patch_artist=True,
# 显示平均值,默认使用点显示
showmeans=True,
# 设置箱子的宽度
widths=0.1,
# 设置箱子的样式,需要 patch_artist=True
boxprops={
# 箱子的边框为黑色
'color': 'k',
# 箱子的填充色为橙色
'facecolor': 'orange',
},
# 设置异常值点的样式
flierprops={
# 设置点的形状
'marker': '.',
# 设置点的填充色
'markerfacecolor': 'blue',
# 设置点的边框色
'markeredgecolor': 'blue',
# 设置点的大小
'markersize': '2'
},
# 添加箱线图在x轴对应位置的名字
# x轴坐标点名
labels=['SO2监测浓度'],
)
plt.grid(linestyle=':')
# 显示图例
plt.legend()
plt.show()
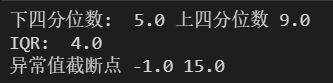
# 获取 SO2监测浓度(μg/m³) 的上下四分位数
bottom, top = so2.quantile([.25, .75])
print('下四分位数: ', bottom, '上四分位数', top)
# 计算 IQR
IQR = top - bottom
print('IQR: ', IQR)
# 计算异常值截断点
top_error = top + 1.5*IQR
bottom_error = bottom - 1.5*IQR
print('异常值截断点', bottom_error, top_error)
# 复制数据集
data1 = data.copy()
data1 = data1[(so2>top_error) | (so2<bottom_error)]
data1
基于箱线图检测筛选出的 SO2监测浓度(μg/m³) 取值异常的行:
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第47张图片](http://img.e-com-net.com/image/info8/b7f49e73a024413f8cb7e66958b86d5e.jpg)
![[Python] 数据预处理(缺失值、异常值、重复值) [相关方法参数说明、代码示例、相关概念]_第48张图片](http://img.e-com-net.com/image/info8/833b1918a1c14071bb01311d8a2fbf21.jpg)
返回文章目录
3. 重复值处理
- 数据集中出现重复值有以下几种情况:
- 1.不同行之间在各列上的取值均相同,即不同行的数据取值完全一致。
- 2.不同行之间存在在某些列上的取值相同
对于重复值可以根据需要,选择对全部列进行去重,也可以选择对某些列进行去重。
可以使用 DataFrame.drop_duplicates() 方法来处理重复值。
- DataFrame.drop_duplicates()
- 参数:
- subset:接收 string 或 序列 为参数,表示要进行去重的列,默认为None,表示全部的列(只有当一行中所有的列一样,才会对该行进行去重)
- keep:接收 string 为参数,表示重复时保留第几个数据。first:保留第一个。last:保留最后一个。false:只要有重复都不保留。默认为first。
- inplace:表示是否在原表上进行修改。默认为False。
默认情况下,对所有的列进行去重,不在原表上进行修改,有重复值时默认保留重复值的第一个。
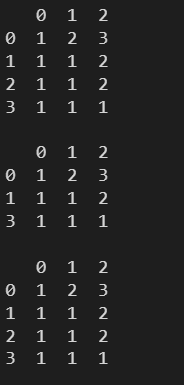
代码示例:
l = [
np.array([1,2,3]),
np.array([1,1,2]),
np.array([1,1,2]),
np.array([1,1,1])
]
df = pd.DataFrame(l)
print(df)
print()
print(df.drop_duplicates())
print()
print(df)
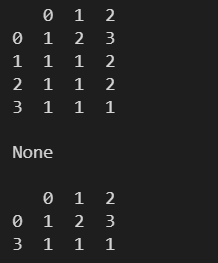
l = [
np.array([1,2,3]),
np.array([1,1,2]),
np.array([1,1,2]),
np.array([1,1,1])
]
df = pd.DataFrame(l)
print(df)
print()
# 在原表上进行修改,无返回值
# 不在原表上进行修改,会返回修改后的新表
# 对第一第二列的数据进行去重,保留重复值的最后一个
print(df.drop_duplicates(subset=[0,1], inplace=True, keep='last'))
print()
print(df)
返回文章目录