Python的数据类型str、set、list、dict、tuple、Array、DataFrame等整理
目录
- 杂记
- 特殊正则
- 排序问题:
-
- sorted(agrs1,key=)
- 堆排序:headpq模块
- str
- Set:
- Zip
- List
- Tuple
- dict
- Array:
- Dataframe
- collections模块
-
- 双边队列:deque()
- 文件操作
-
- PDF文件:pdfplumber模块
杂记
1)iterable类型在切片时,没有越界问题(但是按索引取值时有)。
2)判断数据类型使用:
isinstance(code, float) #判断code是否为float类型
3)浮点数问题:保留小数点后两位:
format(loadedAvg_sheet1, '.2f') #对loadedAvg_sheet1保留小数点后两位
4)字符串格式化print:
① .format():
{}通过位置填充

{}通过字典key填充

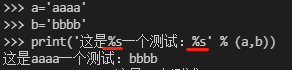
②%:
特殊正则
注:
(1). 只匹配除换行符(\n, \r)外的任意字符;
(2)匹配包括\n等换行符在内的任意字符:([\s\S]) ,也可以用 “([\d\D])”、“([\w\W]*)” 来表示;
(3){}:限制匹配长度(个数)
{m,n}:最少匹配n次且最多匹配m次
{m,}:最少匹配m次
(4)^:开头或字符的否定
”[]”代表的是一个字符集,”^”只有在字符集[]中才是反向字符集的意思。
部分示例代码:
import re
re.compile(['\u4E00-\u9FFF]*', re.S) # 匹配任意中文,包括简/繁体;'[\u4e00-\u9fa5]'简体?
# 查找、匹配
re.findall(pattern,str) # 以list形式返回所有的匹配结果。
re.mach(pattern,str) # pattern匹配str开头,成功返回匹配结果,否则none
re.search(pattern,str) # 匹配str中内容,成功返回第一个成功的匹配,否则none
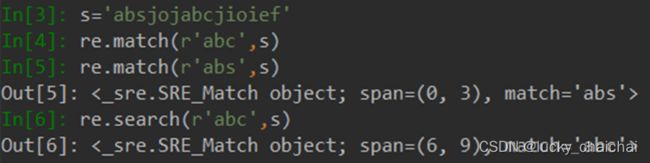
.group()的获取分组情况:s2=‘:我喜欢你’
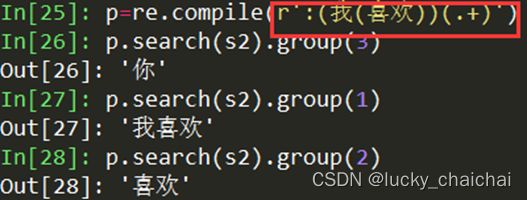
compile的flag参数:
re.I (re.IGNORECASE) :使匹配对大小写不敏感
re.S (re.DOTALL) :使 . 匹配包括换行在内的所有字符
re.L (re.LOCAL) :做本地化识别(locale-aware)匹配
re.M (re.MULTILINE) :多行匹配,影响 ^ 和 $
re.U (re.UNICODE):根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
排序问题:
sorted(agrs1,key=)
1)key指定排序规则:
①实现通过lis的第三个元素进行升序排序

②
>>> lis_1=['最高被引文献', '最早年度文献', '综述文献']
>>> dic={'综述文献':1, '最高被引文献':2, '最新年度文献':3, '最早年度文献':4 }
>>> sorted(lis_1, key=lambda x:dic[x])
['综述文献', '最高被引文献', '最早年度文献']
【对于list还可以:
①倒序切片

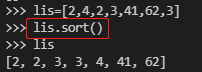
②.sort():会改变lis本身
】
2)对于字典:按照dict的key排序

按照字典的values排序,并且只要keys:
>>> dic={'name':1,'age':2}
>>> s=sorted(dic.keys(), key = lambda x:dic[x])
>>> s
['name', 'age']
3)对list去重但不改变元素顺序
nums=[-1,0,1,2,-1,-4]
nums_new=list(set(nums))
nums_new.sort(key=nums.index) #nums_new结果:[-1, 0, 1, 2, -4]
4)按照多个key排序
lis=['1','2','5','2','aa','t','b']
lis_sorted=(sorted(lis, key=lambda x:(len(x), x))) # 结果:['1', '2', '2', '5', 'b', 't', 'aa']
堆排序:headpq模块
大顶堆:完全二叉树结构,满足任一个节点都比其孩子节点大(但是不保证左枝比右枝大)。
大顶堆动图示例:(来源:https://www.runoob.com/w3cnote/heap-sort.html)
模块的常用方法:
heapq.heappop(lis):弹出堆中的最小值(堆顶元素),保持堆不变
import heapq
lis=[1,562,4,2,51,5,4]
# 两种初始化堆的方法
# 方法1、直接将lis转化为堆
heapq.heapify(lis) # 直接将lis转化为堆,lis变为 [1, 2, 4, 562, 51, 5, 4],小顶堆
# 方法2、将lis中的元素逐个push到堆中
lis_hp=[]
for num in lis:
heapq.heappush(lis_hp,num)
heap=[heapq.heappop(lis) for _ in range(len(lis))] # 获取堆排序结果,结果:[1, 2, 4, 4, 5, 51, 562]
heapq.heappush(heap,12) # 将元素加入到堆中,不改变堆结构。结果:[1, 2, 4, 4, 5, 51, 562, 12]
heapq.heapreplace(heap,13) # 返回并删除堆中最小元素,同时加入一个新元素,不改变堆结构,结果:[4, 4, 13, 12, 5, 51, 562]
str
string的一些自带函数:
s='%s%s' % (s1, s2) #类似于s1+s2
s1=s.find (sub_s1) #返回sub_s1在s1中第一次出现的位置,若不存在则返回-1
s_new = s.replace(old, new) #替换后,s不变
s1 = re.sub('(\[\])|(\(\))|(\{\})','',s) #替换所有的()、[]、{}。替换后,s不变。参数:(pattern: AnyStr@sub, repl: AnyStr@sub, string: AnyStr@sub)
s.startswith(sub_s) # 判断s是否以sub_s作为开头
s.lower(), s.upper() #字符大小写转换
'buabjabh'.index('ab') # 返回子串‘ab’第一次出现的开始位置
strip():
【str2.lstrip()删除开头的;str2.rstrip()删除结尾的】

字符类型判断:

【
str.isalnum() #所有字符都是数字或者字母
str.isalpha() #所有字符都是字母
str.isdigit() #所有字符都是数字
str.islower() #所有字符都是小写
str.isupper() #所有字符都是大写
str.istitle() #所有单词都是首字母大写,像标题
str.isspace() #所有字符都是空白字符、\t、\n、\r
】
Set:
set不能按索引取值。
1)A-B:A有B没有
2)A&B:交集 (可用于计算共现)
3)A.add(hashable_object):元素添加:当要添加的元素已经存在时,不会重复添加
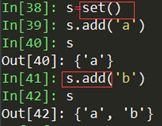
4)A.update():作用类似于list的extend方法
>>> st = set(['1','b','4'])
>>> st.add(('1','g','4','5'))
>>> st
{'1', ('1', 'g', '4', '5'), '4', 'b'}
>>> st.update(('1','g','4','5'))
>>> st
{'b', ('1', 'g', '4', '5'), 'g', '1', '4', '5'}
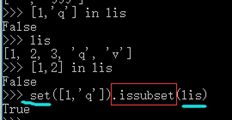
4)判断子集,issubset()
Zip
List
1)list(s)与[s]区别:前者不会改变s的长度,后者是将s整体作为列表的一个元素

2)list的一些自带操作函数
lis.index(value) #获取lis列表中元素value在其中第一次出现的下标。
s.jion(lis) #在lis各个元素之间插入s,结果是字符串
Lis.pop(index) # 从lis中删除对应元素的同时,返回pop出的元素
del lis[index] #仅仅删除对应的元素。
lis.sort() #list排序,直接在lis本身进行改变
lis.insert(0,3) # 在0下标处插入元素3
lis1=lis.copy() #lis1、lis改变时,互不影响;lis1=lis操作,改变任一方都会影响另一方;
lis1 + lis2 #类似于lis1.extend(lis2),但是‘+’操作不改变lis1、lis2,extend在lis1上直接变化
3)list与多变量赋值:

4)list和array内存占用比较:list内存占用小于array

5)list和dict内存占用比较:list内存占用远小于dict,但索引速度也远小于dict。

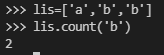
6)list元素统计:
①lis.count(元素值)
②from collections import Counter


7)反转列表:lis[::-1] / list.reversed(lis) 后者会在lis上直接变化
8)列表生成式:
嵌套for 循环
![]()
列表生成式中的if……else

9)将list转换为str如何再转为list:eval()
>>> lis=['a','b','c']
>>> s=str(lis)
>>> lis
['a', 'b', 'c']
>>> s
"['a', 'b', 'c']"
>>> s_l=eval(s)
>>> s_l
['a', 'b', 'c']
Tuple
namedtuple( ):

dict
dict的索引速度远大于list,但是占用的空间也远大于list。Dict相当于用空间换时间。
1)dict的一些自带常用方法:
dic.update( dic1 ) #当dic1中的键不存在于dic中时,则将dic1添加到dic中,若是存在dic中,则更新该键对应的值,可以实现两个字典的合并
len(dic) #获取dict长度
dic.pop('key') #返回key对应的value,同时从dic中删除该键值对
dic.get('b', []) # 获取dic中键'b'对应的值,没有则返回默认值[]
del dic['key'] #直接删除key对应的键值对
注意:用一个字典dic为另一个字典dic1赋值,改变dic1时,dic也会改变(list一样)
2)Dict的key——value相关:

dic.keys dic.values不能通过for循环遍历,区别于keys()、values()可以用于list转换和for循环


3)multidict:使用键时忽略大小写

4)筛选:使用列表生成式的方式进行筛选:

5).get(k, default_v)获取指定键k对应的值,不存在则返回default_v
dic={'name':'a','age':12}
print(dic.get('ag','不存在')) # 结果:不存在
Array:
1)numpy一些常用的自带方法
np.concatenate((a,b,c),axis=0) #axis:0指在第一维(维度指的是参数a/b/c的维度)度拼接;-n指在倒数第n维拼接;
#Concatenate的相关:
tf.concat((a,b,c),axis=0,name='concat')
numpy.unique(list/array) # 去除其中重复的元素,并按元素由小到大返回一个新的无元素重复的元组或者列表
>>> a
array([1, 2, 3])
>>> np.expand_dims(a, axis = 1) # 在axis指定的维度上扩充一维
array([[1],
[2],
[3]])
2)打乱原序列的顺序(DataFrame对应的是sample()方法)
注:np.random.shuffle(lis)与permutation的区别:permutation不直接在原来的数组上进行操作,而是返回一个新的打乱顺序的数组

以相同的索引打乱多组数据集:
# 方法1、使用种子生成指定随机数(array、list均可,tensor不行)
>>> a = np.array([[1,1,1],[2,2,2],[3,3,3],[4,4,4],[5,5,5]])
>>> np.random.seed(4) # 对于多组数据集,只在调用的时候seed()一下并不能使生成的随机数相同,需要每次调用都seed()一下,表示种子相同,从而生成的随机数相同
>>> np.random.shuffle(a)
>>> a
array([[1, 1, 1],
[4, 4, 4],
[2, 2, 2],
[5, 5, 5],
[3, 3, 3]])
# 方法2、使用打乱的索引,实现数据集打乱(针对array)
>>> a
array([[1, 1, 1],
[4, 4, 4],
[2, 2, 2],
[5, 5, 5],
[3, 3, 3]])
>>> index = [0,1,2,3]
>>> np.random.shuffle(index) # 将索引打乱
>>> a[index] # a使用打乱的索引得到打乱的a_new
array([[5, 5, 5],
[1, 1, 1],
[2, 2, 2],
[4, 4, 4]])
3)取值、切片
获取a的第2行第3个元素方式:a[2,3] / a[2][3]

遍历:

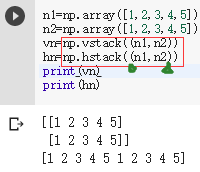
4) 堆叠:np.vstack()垂直方向,np.hstack()水平方向,作用有时效果与concatenate相同
5)array.flatten():将array转化为1维向量

6)特殊矩阵生成
(1)sp.eye(m,n) :生成m*n的单位矩阵

(2)生成对角矩阵
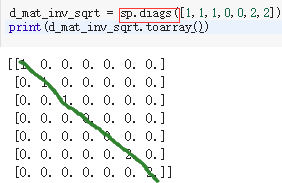
7)array条件赋值、更新

8)使用numpy做多项式计算
z1 = np.polyfit(num_lis,cosine, n) #z1为多(n)项式各个系数
p1 = np.poly1d(z1) #p1为多项式公式
p1_1=np.polyder(p1,1) # 求p1的一阶导数
p1_1_1=np.polyder(p1,2) # 求p1的二阶导数
xs = np.roots(z1) # 求p1的根
9)常见异常:
(1)ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
当直接将array对象作为判断条件时,会报改错:
>>> a = np.array([1,2,3])
>>> if a: # 正确的可以使用any(a),a不为空则返回TRUE
... print(a)
...
Traceback (most recent call last):
File "" , line 1, in <module>
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
Dataframe
1) 新建赋值
① df.loc[i] (这种方式比dic的方式还慢,贼慢)
![]()
![]()
② 参数可以是元素为字典的list

PS :读取mongodb然后list形式导出到DataFrame速度要快很多:
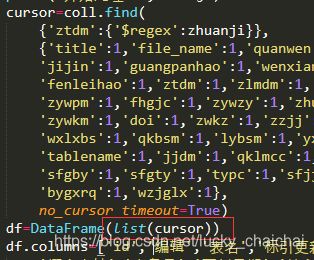
③ 参数可以是字典dict,但是dict的values需要是list,否则报错:ValueError: If using all scalar values, you must pass an index
【写入的时候可以指定列名顺序,最后文件中即为该顺序,也可以为索引命名:
![]()
写入文件时也可以选择不写index:
![]() 】
】
2)基本操作
df['sex'] = ['女', '男', '男', '男', '女'] #增加列
df['add_newcol']=0 # 为列赋值(不存在则新建),若有多列,则多有列都是这个值
df['num']=df['age'] # 使用某一列为自己另一列赋值
df.columns=['name_new','age_new','sex_new'] #更改列名
df.rename(columns={'旧列名’:’新列名’},inplace=True) #更改列名
df.index = ['A','B','C','D','E'] #更改索引名
df.index.tolist() # 获取索引并list形式返回
df.set_index(['id'],inplace=True) #使用其中一列作为索引
df.index.name='id' #为df的索引命名,print出来索引名会在列名下单独一行,但是写入Excel后是正常的。
name_col = df['name_new'] #使用列名获取指定列,可以取多个列df[['name_new', 'age_new']]
name_2 = df['name_new'][1] #使用列名获取name_new列**索引(标签或位置)**为1的值(不一步到位,不推荐使用)
index_row_slite = df[3:] #使用行索引切片
name_row_slite = df['C':] #使用行名切片
# 直接用loc获取的是df对象,加.values获取的是array([['v'],['d']], dtype=object)对象
name_row = df.loc['A'] #使用行名获取指定行
name_cell=df.loc['A','name'] #使用行列名进行索引,获取‘A’行‘name’列的数据
cols_rows=df.loc[['A','C'],['name','age']] # 使用多个行列名进行索引,获取‘A、C’行‘name、age’列的数据
cols_rows=df.loc['A':'C','name':'age'] # 使用行/列名切片进行索引,获取‘A’到‘C’行‘name’到‘age’列的数据
cols_rows_bool=df.loc[df['age']>10,['name','sex']] # 支持逻辑索引,获取‘age’>10的‘name’、‘sex’列
for filename, title in self.df_cited_f.loc[(self.df_cited_f['年']==year) & (self.df_cited_f['被引频次']==year_maxcited),['文件名','篇名']].values: #多个逻辑判断是需要分别括号括起来
print(filename, title)
index_row0 = df.iloc[0] #(同df.loc,只不过使用的是索引位置,不支持逻辑索引)使用行索引获取指定行,返回DataFrame,索引为列名
index_row1 = df.ix[0] #使用行索引获取指定行
#根据条件获取DataFrame内容
df=pd.read_excel('data/result_cluster_km_老年慢性.xlsx')
df_choose = df[df['cluster']==4]
df_f.loc[df['文件名']=='ZGXF201001007']
# 根据多条件取值:或|,且&
xifen_code_chinese=str(df_info[(df_info['细分学科']==xifenxueke)|(df_info['细分学科']==int(xifenxueke))]['细分学科命名'].values[0])
# 判断DataFrame是否为空,是则返回True
df.empty
# 判断DataFrame中一个单元格是否为空,nan
pd.insnull(df_f.loc[i,'ref_参考文献年统计'])
pd.isna(df_f.loc[i,'ref_参考文献年统计'])
#获取DataFrame的shape,返回值为tuple
df.shape
【也可以for循环遍历列:单个列时series,可以直接遍历,也可以使用.to_list()转化为list;多个列时使用values属性,结果为array,一行为array的一行。
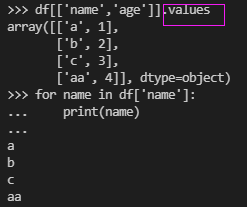

】
DataFrame的in条件筛选:

注:1)上述取值结果都是DataFrame格式,使用.values获取值,结果数据类型为numpy.ndarray。
2)上述获取的行列可以通过for循环获取值,并且可以使用.tolist()转换为list
获取指定列去重后的值

注:numpy.unique(list/array)
按照指定列去重,并保存第一条:
>>> df
name age num new_c
0 c 1 1 new
1 f 2 2 new
>>> df = df.drop_duplicates(['new_c'],keep='first') # inplace=True
>>> df
name age num new_c
0 c 1 1 new
3)循环遍历行,获取各行指定列的值
df=pd.read_excel(normalize_path)
for row in df.itertuples():
normalize_code=getattr(row,'包名称') # int
4)打乱DataFrame的行顺序

5)排序:按某一列值排序:
res = df.sort_values(by='数量', ascending=False)
# 也可以按照多列(数量降序,年升序):
df.sort_values(by=['数量','年'],axis=0,ascending=[False,True], inplace=True) # 在原来的df基础上替换,不返回新对象
6)写入Excel的不同sheet,并且先后写入内容不被覆盖
使用pd. ExcelWriter(file_t),并且最后一定要进行save()
#下述结果是在file_t中创建两个sheet,分别存储df1,df2(如果再次打开并写入save的话还是会覆盖)
df1=DataFrame({'name':[],'age':[]})
df2=DataFrame({'name':['nn','mm']})
writer = pd.ExcelWriter('data/test.xlsx')
df1.to_excel(writer,sheet_name='2010',engine='xlsxwriter')
df2.to_excel(writer,sheet_name='2011',engine='xlsxwriter')
writer.save()
#在同一个sheet中进行追加写入:
df_exist=pd.read_excel(file_name_exist_need_complete)
writer=pd.ExcelWriter(file_t_name,mode='w')
df_exist.to_excel(writer,index=False,sheet_name='Sheet1',engine='xlsxwriter')
df_need=df_records[df_records.年.isin(year_need_lis)]
df_need.to_excel(writer, startrow=df_exist.shape[0]+1,index=False,header=False,sheet_name='Sheet1',engine='xlsxwriter')
writer.save()
7)DataFrame中的空值:NaN 判断空值使用pd.isnull(ele)、pd.isna(ele) 、math.isnan(ele)
df=pd.read_excel(code_fromFile)
for code in df['code']:
if math.isnan(code): #math只能针对数值类型,str类型会报错
code=""
# 适用于所有类型
pd.isnull(df['ref_二级参考文献年统计'][i])
8)删除操作
# 删除指定列存在空值的行,删除列需要axis=1,inplace表示在原来对象上处理,不返回新对象
df.dropna(subset= ['ref_被引频次'], inplace=True)
# df在删除行后,索引并不会改变,因此获取新df索引时需要先重置索引,使用索引获取值(df['age'][1])时尤其要注意重置索引
df.reset_index(drop=True, inplace=True)
# 删除指定索引的行
df.drop(index_num,inplace=True)
9)dataframe对某一列的数据类型进行转换
pd.to_numeric(records['年']) # 将“年”这一列类型转换为数值型,在原来对象上直接变化
records['年'] = records['年'].astype(str) # 将“年”这一列转换为字符串,并重新赋给原来对象
10)dataFrame拼接:
① df.append(df1)
>>> df
name age num new_c
0 c 1 1 new
>>> df1=DataFrame({'name':['bb','ff'],'num':[3,2],'age':[12,32]})
>>> df1
name num age
0 bb 3 12
1 ff 2 32
>>> df=df.append(df1)
>>> df
name age num new_c
0 c 1 1 new
0 bb 12 3 NaN
1 ff 32 2 NaN
② pandas.concat(llis_df)
>>> df1=DataFrame({'name':['a','b'],'age':[1,2],'table':['df1','df1']})
>>> df1
name age table
0 a 1 df1
1 b 2 df1
>>> df2=DataFrame({'name':['a'],'age':[12],'table':['df2']})
>>> df2
name age table
0 a 12 df2
>>> df3=DataFrame({'name':['aa','bb'],'age':[2,4],'table':['df3','df3']})
>>> df3
name age table
0 aa 2 df3
1 bb 4 df3
>>> df=pd.concat([df1,df2,df3])
>>> df
name age table
0 a 1 df1
1 b 2 df1
0 a 12 df2
0 aa 2 df3
1 bb 4 df3
11)DataFrame的计算:
(1)对某一列进行求平均、求和等:

(2)获取a列最大值对应的b列:

(3)使用DataFrame进行统计
①读取mysql结果到DataFrame
(连接读取mysql推荐使用sqlalchemy:Python中的ORM工具,即将关系型数据库表转换为Python类,其中数据列作为属性,数据库操作作为方法,而不是直接针对SQL操作。
使用示例参考_廖雪峰)
使用说明_略详细
from sqlalchemy import create_engine
cnn=create_engine('mysql+pymysql://%(user)s:%(password)s@%(host)s/%(database)s?charset=utf-8'%...,
encoding='utf-8')
df_sql_data=pd.read_sql(sql_str,cnn)
#保存到mysql
df_sql_data.to_sql('table_name',cnn,index=False, if_exists='append')
②df.describe().round(num).T
对所有的列进行求平均、计数等基本统计。(round(num)表示返回值保留num位小数)
当各个列包含数值型和非数值型时,则默认统计数值型。
③df.concat([df1, df2], axis=0):对多个表进行拼接
④df[‘age_d’]=[df[‘age’]-df[‘age_new’] :数值类型的列可以进行计算
⑤one_hot_feature=pd.get_dummies(df[‘sex’]):独热编码(对某一列(非数值型)的不同取值进行编码(one-hot))
⑥df[‘age’].apply(func): 对某一列进行func函数操作
⑦df.agg({‘age’:np.mean, ‘name’:‘mode’}):对不同的列进行不同的操作
collections模块
其中包括Counter()方法(使用见“list元素统计”部分),还有:
双边队列:deque()
deque与list操作基本类似,都有append、enxtend、insert、pop等方法,此外还可以在左边操作:
import collections
dq=collections.deque()
for i in range(6):
dq.append(i)
dq.appendleft('left') # 结果:deque(['left', 0, 1, 2, 3, 4, 5])
dq.extendleft(['e_left1','e_left2']) # 结果:deque(['e_left2', 'e_left1', 'left', 0, 1, 2, 3, 4, 5])
r=dq.popleft() # 结果:deque(['e_left1', 'left', 0, 1, 2, 3, 4, 5])
文件操作
PDF文件:pdfplumber模块
使用示例:(抽取PDF中的表格另存入Excel)
import pdfplumber
lis_row_all=[]
columns=[]
with pdfplumber.open('data/xxxx目录.pdf') as pdf:
for i in range(0, 22):
page = pdf.pages[i]
table = page.extract_table() # 返回list[list[str]],shape=(页数,行数,列数)
# print(table)
if i==0:
columns=table[0]
for row in table[1:]:
lis_row_all.append(row)
df_t=DataFrame(lis_row_all)
df_t.columns=columns
df_t.to_excel('data/xxxx目录.xlsx',index=False,engine='xlsxwriter')
pdf文件:

代码中table结果:
