多视图立体视觉:从几何到学习 (PAMI2022, IJCV2022)
关注公众号,发现CV技术之美
本篇分享 PAMI 2022 论文『Multi-Scale Geometric Consistency Guided and Planar Prior Assisted Multi-View Stereo』和 IJCV 2022 论文『Learning Inverse Depth Regression for Pixelwise Visibility-Aware Multi-View Stereo Networks』,针对多视图重建中两个大的研究方向对传统的基于几何的多视图重建方法和基于深度学习的多视图重建方法进行讨论。
详细信息如下:
PAMI2022作者:徐青山,孔维航,陶文兵*,Marc Pollefeys
IJCV2022作者:徐青山,苏婉娟,齐雨航,陶文兵*,Marc Pollefeys
第一作者和通讯作者单位:华中科技大学

论文作者:Qingshan Xu, Weihang Kong, Wenbing Tao*, Marc Pollefeys.
论文名称:Multi-Scale Geometric Consistency Guided and Planar Prior Assisted Multi-View Stereo
论文链接:https://ieeexplore.ieee.org/document/9863705

论文作者:Qingshan Xu, Wanjuan Su, Yuhang Qi, Wenbing Tao*, Marc Pollefeys.
论文名称:Learning Inverse Depth Regression for Pixelwise Visibility-Aware Multi-View Stereo Networks.
论文链接:https://link.springer.com/article/10.1007/s11263-022-01628-2
01
引言
多视图立体视觉(MVS)一直是计算机视觉研究的一个热点。它的目的是从多个已知相机姿态的图像中建立密集的对应关系,从而产生稠密的三维点云重建结果。
在过去的几年里,人们在提高稠密三维重建的质量上付出了很大的努力,一些传统的几何算法如PMVS、GIPUMA以及COLMAP等取得了令人印象深刻的效果。而近年来深度学习也在多视图重建中取得了非凡的性能,如MVSNet、CasMVSNet等。然而,在三维重建任务中,由于数据量大、弱纹理、遮挡、反射等问题,如何高效准确地实现多视图立体视觉仍然是一个具有挑战性的任务。
这篇推文主要介绍发表在PAMI2022上的基于几何的多视图重建算法ACMH、ACMM、ACMP及ACMMP等,以及发表在IJCV2022上的基于深度学习的多视图重建算法CIDER和PVSNet等,以利于读者能够比较完整地把握在多视图重建中传统的几何算法与最近兴起的深度学习算法各自的特点及优劣。
从在DTU、ETH3D及Intel tanks and temples等公开数据集的评测结果来看,基于深度学习的多视图重建算法具有越来越大的潜力,其性能也逐步提升,而基于几何的多视图重建算法的研究最近两年逐渐陷入停滞。然而,在实际的商业应用中,基于深度学习的方法是否能够克服其训练样本不足,泛化能力有限的缺陷,仍是一个未知的问题。
对比DTU训练集及BlendedMVS训练集就能够发现一些端倪。将一个深度学习算法不做任何修改,在较大的BlendedMVS上进行训练得到的模型就比在DTU上训练得到的模型性能会有大幅提升,这一点在IJCV2022提出的PVSNet算法中就有明显的体现。
随之而来需要回答的问题是:在基于深度学习的多视图重建算法中,究竟需要多少训练样本才能挖掘算法所有的潜能?研究者在网络架构、损失函数以及训练策略上所做的工作是否在样本足够时都无关紧要?或许一个给予充足的样本训练的普通网络架构就能达到我们精心设计但训练样本没那么多的网络架构的效果?这些问题也许不单单存在于多视图重建领域,其它领域也会存在,只是在多视图重建领域中数据集的构造不那么容易而显得尤为突出。
如果从另一个角度来对上述问题进行描述,那就是:传统的几何方法是否还有进步的空间?是否还能够找到更好的数学模型和优化算法独立于样本学习的策略来推动多视图重建性能的提高?这个问题在短期内同样也很难找到答案。
02
多尺度几何一致性引导及平面先验辅助的多视图重建
2.1 主要贡献
基于几何的多视图重建算法一般是基于PatchMatch的迭代优化方式来估计深度图,通常包含四个步骤:随机初始化(Initialization)、采样传播(Sampling and Propagation)、视图选择(View Selection)和细化(refinement)。

图1 PatchMatch多视图立体视觉框架
然而,目前的PatchMatch方法在采样传播的效率和视图选择的准确性上很难同时兼顾,而且无法很好地处理弱纹理区域的深度估计问题。论文中提出的ACMH算法不仅在性能上优于经典的COLMAP算法,并且计算效率是COLMAP的8-10倍。进而为解决MVS中弱纹理区域的深度估计问题,提出多尺度几何一致性引导的ACMM算法以及基于概率图模型的平面先验引导的ACMP算法。
这些工作的主要贡献有以下几点:
提出了自适应棋盘网格采样策略,以捕获更好的候选假设空间。进而提出了启发式的视图选择策略(ACMH)以及基于概率图模型的视图选择策略(ACMH+),能够鲁棒的完成逐像素的视图选择。算法不仅继承棋盘网格传播的高效性,在效率方面是传统的COLMAP算法的8-10倍,也由于逐像素视图选择推断的准确性使得算法具有比COLMAP算法更好的性能。
基于ACMH算法框架,提出了多尺度几何一致性引导的MVS算法框架ACMM。通过构造图像金字塔,在不同尺度上捕获歧义性区域的显著性信息,并通过多视图的几何一致性来优化传递该信息。此外,还提出尺度间的细节恢复器来保证场景的细节不在多尺度传递中被湮灭。ACMM由于引入了多尺度信息,在弱纹理区域的深度估计方面具有突出的性能,性能相比ACMH有了大幅提升。
提出基于概率图模型的平面先验辅助的ACMP算法框架。为了自适应地为弱纹理区域捕获更合适的显著性信息,通过三角化图像中深度可靠的稀疏像素点来构造平面先验模型,然后通过构造概率图模型来推导平面先验辅助的多视图匹配代价函数。这样不仅能保证PatchMatch的高效性,而且自适应地感知弱纹理区域的显著性信息以辅助其深度估计。论文进而将ACMM和ACMP融合构建了多尺度几何一致性引导及平面先验辅助的多视图重建框架。
2.2 ACMH和ACMH+

图2 传播方式

图3多假设联合视图选择
由于邻域内像素点深度值具有相关性,在一个的邻域内,其中一个像素点得到了较优的估计,在之后的迭代更新过程中,则它的估计值会向它的上下左右相邻像素点进行传播,从而实现稠密深度图的迭代优化。
Colmap采用的是从上到下从左到右的传播方法(如图2左边所示),这种传播方式使得算法的并行规模与图像的行数或列数成正比,对GPU的利用效率不高。
Gipuma采用一种红黑棋盘网格的传播方式,将二维图像像素点以红黑棋盘的方式进行分组,并以扩散的方式采样邻域像素点(如图2中间所示)。
这种方式可以充分利用GPU实现大规模的并行操作,从而提高算法的效率。实际中Gipuma算法的计算效率也是大大优于Colmap算法。然而COLMAP算法采用了较为复杂的基于马尔科夫链模型的视图选择策略,而Gipuma算法则缺乏视图选择,在迭代过程中简单的选取前k个最小匹配代价求平均来计算每个候选假设的匹配代价,因而在性能上不如Colmap算法。
原始的Gipuma算法在ETH3D数据集上评测2cm精度结果只有28.5,远低于Colmap的65.0,而经过优化后的Gipuma+效果可以达到64.7,效果与Colmap相当,这说明棋盘网格的传播方式在性能方面并非没有优势。
论文首先红黑棋盘格的传播方式进行了优化。采取图2右边的V形和长条形来自适应地选取像素点进行传播。其中,每个V形区域包含7个可采样点,每个长条区域包含11个可采样点。
根据之前迭代计算的多视图匹配代价,从各自的区域中选取出最优的假设,构成8个候选假设解,以此进一步提高了传播的合理性和高效性。进而设计了一种多假设联合视图选择策略来进行视图选择(图3),最终得到的ACMH算法在ETH3D数据集上评测2cm精度结果为68.5。不仅性能优于Colmap算法,效率也达到了Colmap的8-10倍。
为了使得视图选择策略更加稳健,提出了一种基于概率图模型的视图选择策略(图4),似然概率为前面的光度一致性假设,另外增加了先验概率,为相邻像素的可见性一致性概率,当该像素与其邻域像素的可见性一致时,则先验概率大,否则就小,从而保证视图选择的平滑性。这种方案使得视图选择对参数的依赖相比图3的多假设联合视图选择策略更小,性能更加稳健,实际效果也有所提升。

图4 基于概率图模型的视图选择
2.3 ACMM
观察图5中的图像,可以发现纹理信息在不同尺度上的显著性是不同的。尽管高分辨率图像有利于重建得到更多的细节,然而这使得在同样的patch大小情况下,高分辨率图像的patch缺乏纹理,从而使得NCC匹配代价计算失效,在弱纹理区域深度估计失败,这一点从图5的(b)和(d)就能明显的看出。
事实上,较低尺度的图像能够较好的反应图像的结构信息,如图5中(c)。因此,为了更好地为歧义性的区域感知其显著性信息,论文提出了一种多尺度几何一致性引导框架,不仅在不同的尺度上感知显著信息,并且通过多视图的几何一致性来更好地传递该信息。如图(e)为融合多个尺度图像所得到的深度估计,在弱纹理区域具有明显的提升。
 图5 不同尺度图像的纹理描述
图5 不同尺度图像的纹理描述
具体来说,对输入的图像集合构造图像金字塔,然后由粗到细地恢复每个尺度的深度图信息。在得到较粗尺度的估计后,对其上采样,首先使用细节恢复器来修正细节上的误差。
具体操作为:在当前尺度上,计算上采样的估计值对应的光度一致性代价以及该尺度RGB图像计算新的光度一致性代价,比较两个代价值,对于差值大于阈值的像素点,使用新的代价对应的估计值更新原来的估计。细节恢复器的使用,防止了在弱纹理区域由上一尺度上采样得到的可靠估计丢失。
这样,为了进一步保证多视图间的深度一致性,采用几何一致性来优化当前尺度的估计。多尺度几何一致性框架如图6所示。

图6 多尺度几何一致性引导框架
2.4 ACMP和ACMMP
基于概率图模型的平面先验约束的多视图深度估计整体框架如图5所示。在图的上方是基本流程,首先采用ACMH算法得到参考图的深度图,然后采用严格的几何一致性进行校验,保留一些可靠像素的深度值,以这些可靠的像素点为基础,采用德劳内方法在图像平面构建三角网格,将每一个三角形看做一个小的平面,每个三角平面的深度和方法根据其三个顶点进行计算。
ACMP算法以这样构造得到的三角网格来作为深度估计的平面先验约束。为了让平面先验辅助深度图估计,构建了如图7的概率图模型,似然概率为光度一致性描述,先验概率为每个像素相对于其所处的三角网格平面的深度和法向一致性,如果一致性好,则先验概率大,反之则小。进一步在ACMP框架中融入多尺度信息就可得到多尺度的算法ACMMP。

图7 基于概率图模型的平面先验约束的MVS
2.5 实验结果
表1:ETH3D高分辨率训练集上量化对比试验

图8 深度图对比实验
表2:ETH3D高分辨率测试集上的量化对比试验

表3:Intel Tanks and Temples数据集量化评价对比试验

03
基于像素可见性感知及逆向深度回归的多视图立体视觉网络
3.1 主要贡献
从传统的几何多视图重建算法中可以看出,视图选择对重建性能具有至关重要的作用,无关视图的干扰会使得NCC得分的校验变得无效甚至带来负面的影响,从而导致深度估计的错误。然而在CasMVSNet以及之前的网络中,视图的选择是不加考虑的。
网络在训练时,选择可见性最好的两幅源视图与参考视图一起构建代价体参与训练。在测试时,一般选取4幅重叠较好的源视图与参考视图一起通过训练好的网络来推断参考视图的深度。
这种方式对采集数据为视频的数据集,如DTU和Tanks and Temples影响不大,因为在这类数据集中,任何一个参考视图总能找到相邻具有较高重叠度的源视图来参与深度估计,从而保证参考视图中绝大部分像素具有较好的可见性。然而对于视点变化比较大的数据集,如ETH3D,则有较大的影响。
因为如果仅考虑相邻的重叠度较高的源视图,无法保证参考视图中像素的可见性。对于重建视点变化较大的数据,只有更多的源视图参与校验,参考视图像素的可见性才能得以保证。
图8中实验结果表明,没有视图选择策略,即便是如CasMVSNet这样表现突出的网络模型,在ETH3D上其性能仅有51.18,远不及早期的Colmap算法,而考虑了视图选择策略的Vis-MVSNet和PVSNet方法其性能则有大幅的提升。缺乏视图选择策略,这多少也是之前的基于深度学习的多视图重建算法在ETH3D上很少进行评测的原因。

图9 当前基于学习的MVS存在的问题
事实上,即便是如DTU和Tanks and Temples这样从连续视频中采集的数据集,视图选择策略也是有益的,越多的源视图参与参考视图的深度估计,其校验的可靠性越高,越有利于准确的深度估计。
在Colmap和ACMH等传统几何方法中,通常会选多达20幅左右的源视图参与NCC校验,这至少从实验的角度验证了这一点。因此,在网络中融入视图选择的策略是非常必要的。IJCV22中的核心工作基于视图选择的网络PVSNet最早是2020年7月在Arxiv上公开,另一个有代表性的融入视图选择策略的网络Vis-MVSNet2020年8月份也在Arxiv上发布。
两者解决可见性预测的思路不同,但都在一定程度上缓解了基于深度学习的多视图重建方法中视图选择的问题。IJCV22论文的另一个贡献是在多视图重建网络中考虑了逆向深度采样的问题,并采用组相关的策略降低了特征的维度,使得显存消耗只有原来的四分之一,而性能有明显提升。
3.2 轻量级组相关代价体及逆向深度回归网络CIDER
在基本的深度学习MVS网络框架中,图像分辨率过高和采样过密都会使得显存消耗过大。早期的MVSNet需要将DTU中1920x1280的图像数据压缩到640x480进行训练,测试也是采用同样大小的图像进行。
其根本原因在于过大的图像会导致代价体太大显存不足以支撑训练和测试。深度采样过密也同样会导致这个问题。但采样密度过小自然会影响最终深度估计的精度。这里提出一种轻量级的组相关策略来降低特征的维度从而减小显存的开销并且不影响性能。
此外,在相同的采样密度情况下,如果是等间隔采样,那么对近处的深度和远处的深度其量化误差都是一样的。但在实际视觉观察中,同样大小的量化误差在近处视觉上会表现的更为明显。因此,可以在近处采用较小的采样间隔,提高深度估计的精度,随着距离的增大逐渐提高采样间隔。与等间隔采样方式相比,这种不等间隔的采样方式可以在提高性能的情况下不增加显存的开销。
另一方面,如图10右边所示,在参考视图上的等间隔采样映射到源视图后会变成不等间隔,并且随着深度越大,其间隔越来越小,这使得特征的区分度越来越低。因此,为了保证映射到源视图上的位置基本是等间隔的,也要求参考视图的采样间隔是逐渐增大的不等间隔采样。进一步采用序数回归的方式可提高深度估计的精度,减少阶梯效应,使得深度估计结果更为平滑。

图10 逆向深度回归模型
3.3 像素相关的可见性网络PVSNet
像素相关的可见性网络如图11所示,网络对每一个源视图学习了一个权值,这个权值等价于ACMH方法中的权值。将PVSNet与CIDER结合起来,并采用类似CasMVSNet和UCSnet的级联架构,降低显存的开销,并使得网络可以对1920x1280大小的图像进行训练和测试,网络的整体架构如图12所示。关于网络结构的细节可参考论文。

图11 视图选择的深度学习网络架构

图12 网络整体架构
3.4 对抗噪声视图训练策略
通常,MVS网络训练是对一幅参考图像选择两幅可见性最好的图像作为源视图进行训练。在这种训练方式中,即便在网络架构中融入了如图11的视图选择模块,但在实际效果提升十分有限。
其主要原因在于参与训练的视图均是可见性较好的视图,因而对可见性较差的视图辨识度不高。为了提高网络的视图可见性辨识能力,这里在训练时除了采用两幅可见性较好的图像参与训练外,还引入两幅可见性较差的图像参与训练。从结果来看,这样训练出来的网络对视图具有更好的可见性辨识能力。

图13 噪声视图训练策略
3.5 视图可见性选择分析
图14对PVSNet网络的视图可见性辨识能力进行了可视化分析,从结果来看,其视图像素可见性的判别与视觉观察基本吻合。对比原始的CIDER和在此基础上引入可见性模块的PVSNet,深度估计效果有了明显的提升。

图14 视图选择结果示意图
图15进一步对视图选择模型进行了量化分析。通常训练好的MVS网络在测试时,一般是选择可见性最好的4幅图像作为源视图集合来推断参考图像的深度。
也许会有这样的疑惑,为什么不像Colmap和ACMH等几何方法那样选择20幅图像作为源视图集合呢?图15左边的曲线图很好的分析了原因,在没有视图可见性模块的CIDER网络中,当源视图个数为4时其性能最佳,而随着视图增多时,其性能急剧退化。
这是由于当网络缺乏视图选择能力时,可见性不佳的噪声视图的引入会增加代价体的误差,这样的视图越多则误差越大,从而性能退化也越严重。而在引入视图选择模块后,随着视图个数的增加,性能逐渐提高最后趋于稳定。具体细节分析可参考论文。

图15 视图选择网络与常规网络对比分析
3.6 实验结果
表4:DTU量化对比试验

表5:Intel Tanks and Temples量化对比试验
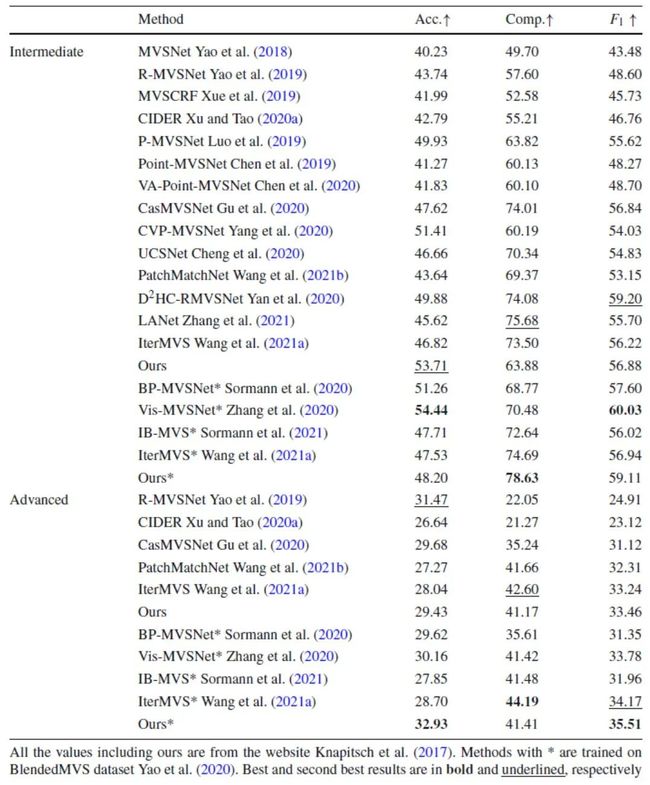
表6:ETH3D量化对比试验

说明:PatchMatchNet和IterMVS在网络框架中参考2020年的PVSNet的Arxiv版本融入了PVSNet的视图选择策略,因而在ETH3D上性能有明显优势。Vis-MVSNet在BlenderMVS上训练的模型在ETH3D训练集的评测结果略低于PVSNet,在测试集上略优于PVSNet,在Tanks and Temples的Intermediate上评测略优于PVSNet,在advanced上略低于PVSNet。
Vis-MVSNet没有提供DTU训练模型在ETH3D和Tanks and Temples的评测结果。表格中“-”表示该方法未在ETH3D上提交评测结果,其在测试集上结果为PVSNet作者根据这些论文提供的开源代码补充的实验。

图16 ETH3D点云对比试验
04
总结
这篇推文主要对发表在PAMI22和IJCV22的论文进行了概述,这两篇论文恰好代表着多视图重建中两个大的研究方向:传统的基于几何的多视图重建方法和基于深度学习的多视图重建方法。
未来基于深度学习的多视图重建方法是否能够在实际应用中大放异彩,还是仍然停留在数据评测刷榜的阶段?而传统的几何方法是否又能找到好的突破口重新焕发活力?这一切都需要时间来检验。
至少在目前看来,与其它的很多计算机视觉任务如目标检测等不同,在多视图重建中,深度学习方法的性能还远未达到碾压传统几何方法的地步,在一些代表性的数据集上二者评测性能仍在伯仲之间。而就多视图重建整个大的范畴而言,深度图估计和稠密点云生成,仍然还有很多需要完善的地方。
尽管不少商业软件宣称能够如何如何,恨不得智慧城市、数字地球、数字孪生、元宇宙等等下一刻就会降临人间,但是这一领域研究的客观局限性仍在那里,弱纹理甚至无纹理物体或区域,遍布城市的玻璃结构,草丛树木的精细表达,以及其他外在因素如低照度、光照不均衡、反射及天气状况等引起的成像问题,这些特殊情况的重建仍是需要克服的障碍,如果不能有所突破,终究只是沦为口号而已。任重而道远,与诸君共勉!
这篇简单的推文对论文的内容没有做详尽的叙述,文中的图片来自于几次学术报告的内容,最早是2020年天元数学中心举办的暑期系列讲座内容,相比论文中的图片有所概括,便于读者理解,可以看作是这两篇论文的导读和补充。
这两篇论文的内容也是第一作者徐青山的博士论文内容,他在攻读博士期间思维的敏锐与对科研的执着仍然令我印象深刻。由于他刚进入博士后阶段工作繁忙,这篇推文就由我操刀整理而成,文中的观点均代表我个人的观点,有不妥之处,望读者予以宽容。
参考文献
S. Galliani, K. Lasinger, and K. Schindler. Massively parallel multiview stereopsis by surface normal diffusion. ICCV 2015.
J. L. Schonberger, E. Zheng, J.-M. Frahm, and M. Pollefeys. Pixelwise view selection for unstructured multi-view stereo. ECCV 2016.
Q. Xu and W. Tao, Multi-scale geometric consistency guided multi-view stereo. CVPR 2019.
Q. Xu and W. Tao, Planar prior assisted patchmatch multi-view stereo. AAAI 2020.
Q. Xu and W. Tao. Learning inverse depth regression for multiview stereo with correlation cost volume. AAAI 2020.
Y. Yao, Z. Luo, S. Li, T. Fang and L. Quan. Mvsnet: Depth inference for unstructured multi-view stereo. ECCV2018.
X. Gu, Z. Fan, S. Zhu, Z. Dai, F. Tan and P. Tan. Cascade cost volume for high-resolution multi-view stereo and stereo matching. CVPR2020.
Q. Xu and W. Tao. Pvsnet: Pixelwise visibility-aware multi-view stereo network. arXiv: 2007. 07714. 2020.
J. Zhang, Y. Yao, S. Li, Z. Luo and T. Fang. Visibility-aware multi-view stereo network. arXiv: 2008.07928. 2020.
S. Cheng, Z. Xu, S. Zhu, Z. Li, L. E. Li, R. Ramamoorthi and H. Su. Deep stereo using adaptive thin volume representation with uncertainty awareness. CVPR2020.

END
欢迎加入「三维重建」交流群备注:3D
