【论文简述】UCS-Net:Deep Stereo using Adaptive Thin Volume Representation with Uncertainty Awareness(CVPR)
一、论文简述
1. 第一作者:Shuo Cheng、Zexiang Xu
2. 发表年份:2020
3. 发表期刊:CVPR
4. 关键词:MVS、深度学习、自适应深度、由粗到细
5. 探索动机:因为3D CNN内存开销大的缘故,不得不在精度(深度假设数)和完整性(分辨率)间做平衡。之前的很多方法为了深度假设间隔相同且很密,所以只能使用分辨率较低的图像。
At the core of the recent success on MVS is the application of 3D CNNs on plane sweep cost volumes to effectively infer multi-view correspondence. However, such 3D CNNs involve massive memory usage for depth estimation with high accuracy and completeness. In particular, for a large scene, high accuracy requires sampling a large number of sweeping planes and high completeness requires reconstructing high-resolution depth maps. In general, given limited memory, there is an undesired trade-off between accuracy (more planes) and completeness (more pixels) in previous work.
Previous learning-based MVS methods estimate per-view depth using plane sweep volumes (PSVs) with a fixed depth hypothesis at each plane; this requires densely sampled planes for high accuracy, which is impractical for high-resolution depth because of limited memory.
6. 工作目标:是否可以低内存和底计算消耗的同时实现高精度和高完整性的重建?
Our goal is to achieve highly accurate and highly complete reconstruction with low memory and computation consumption at the same time.
7. 核心思想:提出了一种新的感知不确定性的级联网络(UCS-Net),以重建高精度的高分辨率视图深度。
8. 实验结果:在各种具有挑战性的数据集上,与其他基于学习的MVS方法相比,UCS-Net实现了更好的性能。
9. 论文下载:
https://openaccess.thecvf.com/content_CVPR_2020/papers/Cheng_Deep_Stereo_Using_Adaptive_Thin_Volume_Representation_With_Uncertainty_Awareness_CVPR_2020_paper.pdf
二、实现过程
1. UCS-Net概述
给定参考图像I1和N−1个源图像{Ii},UCS-Net逐步回归与参考图像相同分辨率的细粒度的深度图。下图展示了UCS-Net的结构。UCS-Net首先利用2D CNN在三种分辨率下提取多尺度深度图像特征。深度预测通过三个阶段以从粗到细的方式实现,利用多尺度图像特征构建了多尺度代价体,预测多分辨率深度图。第一阶段,构建平面扫描体,后两个阶段为了实现有效的空间划分,利用深度预测的不确定性来构造自适应薄体(ATV),然后,应用3D CNN处理代价体,以预测像素深度概率分布,并根据分布的期望重构深度图。
模型同样是由粗到细的优化深度图,仍然包含特征提取,代价体构建,代价体正则化和深度回归四个组件,不同之处在于使用多尺度特征提取,以及在构建代价体时,深度采样利用上一层概率体输出各像素的置信度方差来选择深度假设样本,并进行迭代优化,论文将整个流程分为3个stage来进行。
为了理解方便,以下按照Stage 1、Stage 2(Stage3与2一致)即训练的流程来介绍该模型。
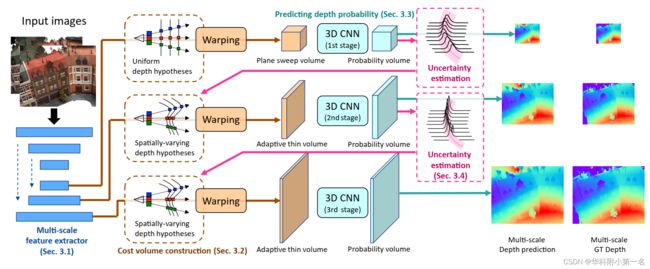
2. 多尺度特征提取器(Multi-scale feature extractor)
使用小型的2D Unet(编码器 + 解码器 + 跳跃连接)在解码层输出在三个不同的尺度特征图用于构建代价体,尺寸分别[W/4, H/4, 32], [W/2, H/2, 16], [W, H, 8],使用分辨率最小的特征图构建第一个代价体。
Our multi-scale feature extractor allows for the high-resolution features to properly incorporate the information at lower resolutions through the learned upsampling process; thus in the multi-stage depth prediction, each stage is aware of the meaningful feature knowledge used in previous stages, which leads to reasonable high-frequency feature extraction.
3. 代价体构建
遵循MVSNet构建代价体的流程,第一阶段建立标准平面扫描体,其深度假设为定值d,深度区间[dmin, dmax]。均匀采样的深度数由256变为64。
第二和第三阶段,构建新的自适应薄体,其深度假设根据之前深度预测的像素不确定性估计设定具有空间变化的深度值,并构建代价体。
4. 深度预测和概率分布
在每个阶段,使用3D UNet(具有多个下采样和上采样的3D卷积层)处理代价体,三个阶段使用相同的网络结构,但没有共享权重,因此每个阶段学习处理不同的尺度的信息。最后使用softmax来预测像素的深度概率,回归得到预测的深度图:
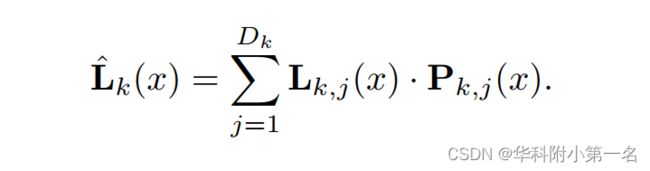
Dk:深度假设数,Pk,j:深度概率图,Lk,j:深度假设,Pk,j(x)表示深度为L时像素x的概率。Lk:第k阶段通过加权和得到的深度。
4. 不确定性估计与ATV
以往的方法只利用了像素分布的期望,回归得到估计的深度图。本文首次利用分布的方差进行不确定性估计,并利用不确定性构造ATV模型。具体来说,在k阶段,沿深度方向上,像素x的概率分布的方差Vk(x)计算为:
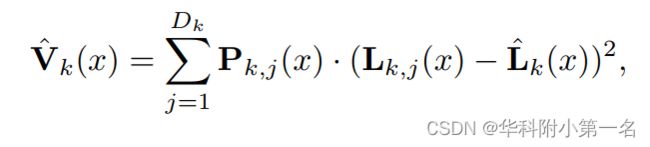
V(x)代表像素x的深度方差,Pj(x)代表x在第j个深度平面上的概率,Lj(x)代表第j个深度平面的深度假设值,L(x)~代表x期望回归后的深度值。对应的标准差为σk(x)=![]() 。给定深度预测Lk(x)及其在像素x处的方差σk(x)2,使用基于方差的置信区间来衡量预测的不确定性:
。给定深度预测Lk(x)及其在像素x处的方差σk(x)2,使用基于方差的置信区间来衡量预测的不确定性:

其中λ是一个标量参数,它决定了置信区间的范围。对于每个像素x,我们从第k阶段的Ck(x)中均匀采样Dk+1深度值,得到阶段(k +1)深度假设平面的深度值Lk+1,1(x), Lk+1,2(x),…,Lk+1,Dk+1(x)。这样,我们构建了Dk+1个空间变化深度假设值Lk+1,j,形成了阶段(k +1)的ATV。
估计的Ck(x)表示预测Lk(x)的不确定区间,它决定了在每个像素处ATV的物理厚度。下图展示了两个实例,两个像素的预测值(红色虚线)及估计的不确定区间Ck(x)。Ck本质上描述了一个围真实表面的概率局部空间,真实的深度位于不确定区间,并且置信度非常高。请注意,我们的基于方差的不确定性估计是可微的,因此UCS-Net能够在端到端训练过程中学习调整每个阶段的概率预测,以实现优化的区间和相应的ATV。因此,ATV的空间变化深度假设很自然适应深度预测的不确定性,从而实现了高效的空间划分。
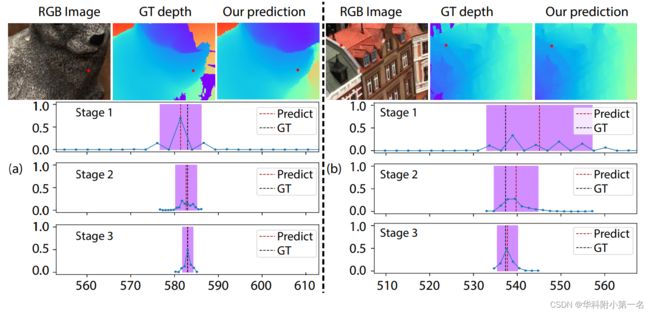
顶部:RGB图像,预测深度和真实深度。底部:三个阶段的细节,两个像素(图像中的红色点),预测的深度概率(连接的蓝点)、深度预测(红色虚线)、真实深度(黑色虚线),不确定性区间(紫色)。可以观察到该区间(也即代价体的物理长度)越来越小,深度预测也越来约逼近真实值。图3B,预测的第一阶段深度分布具有多模态,但相应的,它具有较大的方差和足够大的不确定性区间。
5. 由粗到细预测
UCS-Net利用三个阶段从粗到细构建多个尺度的深度,每个阶段通常有不同的平面数量(Dk),构造一个平面扫描体W/4×H/4×64和两个ATV(W/2×H/2×32和H×W×8)估计相应分辨率下的深度。尽管ATV的深度平面数很少(32和8),但它们划分的局部深度范围的尺度比第一级代价体更细。由于深度平面数很少,因此后两个阶段能够在有限的内存条件下处理更高的像素分辨率,这使得细粒度深度重建成为可能。ATV有效地体现了深度预测的区域性和不确定性,使由粗到细的框架实现了具有较高的准确性和完整性的深度重建结果。
6. 训练细节
数据集:DTU Dataset,W×H = 640×512,点云应用泊松重建,并用三种W/4×H/4、W/2×H/2和W×H分辨率的视图进行表面渲染。
损失函数:UCS-Net 预测三个分辨率下的深度,并使用L1计算每个分辨率下的预测值和真实值的损失,三个损失相加得到最终损失。
训练策略:端到端训练完整的三级网络,60个epoch,使用初始学习率为0.0016的Adam优化器。使用8 NVIDIA GTX1080Ti gpu训练网络,batch size为16。
7. 结果
DTU数据集:在DTU数据集上达到除传统Gipuma之外的精度最高,完整性和overall最高。注意,在相同的输入条件下,MVSNet和R-MVSNet预测的深度图大小仅为W/4 × H/4;本文最终的深度图是在原始图像大小上估计的,它具有更高的分辨率,并具有更好的完整性。Point-MVSNet在预定义的局部深度范围内使低分辨率深度更密,还可以在原始图像分辨率下重建深度,而UCS-Net利用自适应局部深度范围,获得了更好的准确性和完整性。

Tanks and Temple:F-score达到SOTA。
Dense-RMVSNet leverages a well-designed post-processing method and achieves slightly better performance than ours on two of the scenes, whereas our work is focused on high-quality per-view depth reconstruction, and we use a traditional fusion technique for post-processing. Nonetheless, thanks to our high-quality depth, our method still outperforms DenseR-MVSNet on most of the testing scenes and achieves the best overall performance.

不确定性评估
采样区间小,间隔小,效果好,内存小。MVSNet and R-MVSNet sample the same large depth range (508.8mm) in a uniform way with a large number of planes (256 and 512); yet, the uniform sampling merely obtains volumes with sampling distances of 1.99mm and 0.99mm along depth. In contrast, our UCS-Net achieves a higher actual depth-wise sampling rate with a small number of planes; this allows for the focus of the cost volumes to be changed from sampling the depth to sampling the image plane with dense pixels in ATVs given the limited memory, which enables high-resolution depth reconstruction.

UCS-Net通过多个阶段实现了更稠密和精确的重建。请注意,真实点云是通过扫描获得的,它的质量甚至比本例中的重建还要低。
运行时长和内存:该完整模型是唯一一个在原始图像分辨率下重构深度的模型。然而,这并没有带来任何更高的计算或内存消耗,甚至快很多。
This demonstrates the benefits of our coarse-tofine framework with fewer depth planes (104 in total), in terms of system resource usage.
