CNN卷积神经网络简单示例(PyTorch)
CNN卷积神经网络示例PyTorch
- 导入Python库和相关模块
- 转换为图像格式
- 将数据格式numpy转换为tensor,并打包成batch
- 构建CNN网络
- 定义损失函数
- 训练网络
- 显示学习曲线
- 进行预测
- 显示重建其中一个标记
注:
- 记录使用CNN网络的始末,该部分为CNN网络搭建过程
- 同时感谢在这项工作中提供帮助的各位师兄师姐
- 欢迎交流,有误请留言
- 如有侵权请联系删除
查看安装pytorch,点击链接
导入Python库和相关模块
包含了深度学习的库和基本计算相关库
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torch.utils.data import TensorDataset,DataLoader
from torch.utils.data.dataset import random_split
import matplotlib.pyplot as plt
%matplotlib inline
import time
from scipy.optimize import curve_fit
转换为图像格式
# 这里输入8×8×1的图像大小
RawInputImage = RawInput.reshape(-1,1,8,8)
将数据格式numpy转换为tensor,并打包成batch
# pytorch操作,数据格式转化为tensor张量
InputNorm_tensor = torch.from_numpy(RawInputImage).float()
Labelxyz_tensor = torch.from_numpy(RawLabelImage).float()
# 对tensor打包
DataToNN = TensorDataset(InputNorm_tensor,Labelxyz_tensor)
# 0.8作为训练数据 0.2 作为验证集
trainRatio = 0.8
train_size = int(trainRatio*len(DataToNN))
val_size = len(DataToNN) - train_size
batch_size = 32
# 随机将一个数据集分割成给定长度的不重叠的新数据集
train_dataset, val_dataset = random_split(DataToNN,[train_size,val_size])
#DataLoader返回的是所有的数据,只是分成了每批次为参数batch_size的数据
train_dataloader = DataLoader(dataset=train_dataset,batch_size=batch_size,shuffle=True)
# 作为验证集, batchsize就是整个验证集
val_dataloader = DataLoader(dataset=val_dataset,batch_size=len(val_dataset),shuffle=True)
Batch Size目的:在小样本数的数据库中,不使用Batch Size是可行的,而且效果也很好。但是一旦是大型的数据库,一次性把所有数据输进网络,肯定会引起内存的爆炸。
上限主要受到硬件资源限制,如GPU显存,一般设为32,64,128,256 Batch Size合适的优点:
1、通过并行化提高内存的利用率。就是尽量让你的GPU满载运行,提高训练速度。
2、单个epoch的迭代次数减少了,参数的调整也慢了,假如要达到相同的识别精度,需要更多的epoch。
3、适当Batch Size使得梯度下降方向更加准确。
构建CNN网络
网络结构根据规则任意调整
包含一个输入层,两个卷积层,一个全连接层,一个输出层,可以根据个人爱好增加复杂度
卷积层的计算:输出图像空间尺寸=(输入图像尺寸-卷积核尺寸+2*零填充个数)/步长+1;输出数据体深度=使用卷积核个数
# 定义一个卷积神经网络
outputSize = 1
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
#输入8×8×1图像,1个零填充,经过4个3×3×1的卷积核,输出8×8×4的图像
self.conv1 = nn.Conv2d(in_channels=1,out_channels=4,kernel_size=3,padding=1)
#输入8×8×4图像,经过8个5×5×4卷积核,输出4×4×8的图像
self.conv2 = nn.Conv2d(in_channels=4,out_channels=8,kernel_size=5)
#输入4×4×8图像,输出1×32全连接层
self.fc1 = nn.Linear(4*4*8,32)
#接着输出1个参数
self.fc2 = nn.Linear(32,outputSize)
def forward(self,x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = x.view(-1,4*4*8)
x = torch.tanh(self.fc1(x))
x = self.fc2(x)
return x
定义损失函数
# 定义损失函数
learning_rate = 1e-3
#损失函数度量的是预测值与真实值之间的差异,线性回归最常用均方误差,逻辑回归最常用交叉熵
#损失函数为均方误差
loss_fn = nn.MSELoss()
#使用Adam优化器
optimizer = torch.optim.Adam(net.parameters(),lr=learning_rate)
训练网络
%%time
net = net.cuda()
train_loss = []
train_loss_all = []
val_loss = []
n_epoches = 10
for epoch in range(n_epoches):
for x_batch, y_batch in train_dataloader:
x_batch = x_batch.cuda()
y_batch = y_batch.cuda()
outputs = net(x_batch)
loss = loss_fn(outputs,y_batch)
# 梯度初始化
optimizer.zero_grad()
# 反向传播
loss.backward()
# step
optimizer.step()
# loss列表
train_loss.append(loss.item())
train_loss_batchmean = np.mean(train_loss)
train_loss_all.append(train_loss_batchmean)
with torch.no_grad():
for x_val,y_val in val_dataloader:
x_val = x_val.cuda()
y_val = y_val.cuda()
# make prediction
net.eval()
outputs = net(x_val)
# compute val loss
val_loss_batch = loss_fn(outputs,y_val)
val_loss.append(val_loss_batch.cpu())
print(epoch)
显示学习曲线
# plot learning curve
ax = plt.subplot()
ax.plot(train_loss_all,'.',label='train_loss')
ax.plot(val_loss,'r.',label='val_loss')
ax.legend()
ax.set_xlabel('epochs')
ax.set_ylabel('loss')
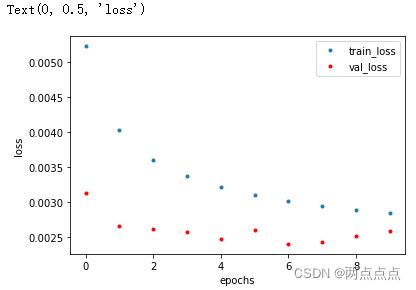
学习曲线
train loss 不断下降,test loss不断下降,说明网络仍在学习;(最好的)
train loss 不断下降,test loss趋于不变,说明网络过拟合;(max pool或者正则化)
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;(检查dataset)
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;(减少学习率)
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。(最不好的情况)
可以通过不断修改网络结构调整
进行预测
#预测
val_tensor = val_dataset[:][0]
val_label = val_dataset[:][1]
net.eval()
net.cpu()
with torch.no_grad():
ypred = net(val_tensor)
diff = ypred - val_label
显示重建其中一个标记
Coordinates = -9
trueCoor = vallabel_test*LabelGap+minLabel
conditions = abs(trueCoor - Coordinates)<0.1
indices = np.nonzero(conditions)[0]
selectedEvents = vallabel_test[indices]
predEvents = predlabel_test[indices]
# plot
plt.subplot(211)
h1 = plt.hist(selectedEvents*LabelGap+minLabel,bins=10)
plt.title('original')
plt.xlim([-17,17])
plt.subplot(212)
h2 = plt.hist(predEvents*(LabelGap)+minLabel,bins=100)
plt.title('predicted')
plt.xlim([-17,17])
plt.tight_layout()
#
difftest = (selectedEvents - predEvents)*(LabelGap)
plt.figure()

参考及推荐资料
CS231n的课程
翻译(推荐)