Week5:线性学习率热身——warm up
2021SC@SDUSC
1.什么是学习率?
(1)理解学习率
将输出误差反向传播给网络参数,以此来拟合样本的输出。本质上是最优化的一个过程,逐步趋向于最优解。但是每一次更新参数利用多少误差,就需要通过一个参数来控制,这个参数就是学习率(Learning rate),也称为步长。从bp算法的公式可以更好理解:

(2)学习率对模型的影响
从公式就可以看出,学习率越大,输出误差对参数的影响就越大,参数更新的就越快,但同时受到异常数据的影响也就越大,很容易发散。

2.什么是warmup?
warmup是一种学习率优化方法(最早出现在ResNet论文中)。在模型训练之初选用较小的学习率,训练一段时间之后(如:10epoches或10000steps)使用预设的学习率进行训练。
3.为什么使用warmup?
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
4.paddlepaddle/paddleocr中的warmup
ppocr/optimizer/learning_rate.py中
def __call__(self):
learning_rate = lr.PolynomialDecay(
learning_rate=self.learning_rate,
decay_steps=self.epochs,
end_lr=self.end_lr,
power=self.power,
last_epoch=self.last_epoch)
if self.warmup_epoch > 0:
learning_rate = lr.LinearWarmup(
learning_rate=learning_rate,
warmup_steps=self.warmup_epoch,
start_lr=0.0,
end_lr=self.learning_rate,
last_epoch=self.last_epoch)
return learning_rate
调用class paddle.optimizer.lr.LinearWarmup(learing_rate, warmup_steps, start_lr, end_lr, last_epoch=- 1, verbose=False)接口。该接口源代码如下:
class LinearWarmup(LRScheduler):
def __init__(self,
learning_rate,
warmup_steps,
start_lr,
end_lr,
last_epoch=-1,
verbose=False):
type_check = isinstance(learning_rate, float) or isinstance(
learning_rate, int) or isinstance(learning_rate, LRScheduler)
if not type_check:
raise TypeError(
"the type of learning_rate should be [int, float or LRScheduler], the current type is {}".
format(learning_rate))
self.learning_rate = learning_rate
assert warmup_steps > 0 and isinstance(
warmup_steps, int), " 'warmup_steps' must be a positive integer."
self.warmup_steps = warmup_steps
self.start_lr = start_lr
self.end_lr = end_lr
assert end_lr > start_lr, "end_lr {} must be greater than start_lr {}".format(
end_lr, start_lr)
super(LinearWarmup, self).__init__(start_lr, last_epoch, verbose)
def state_dict(self):
"""
Returns the state of the LinearWarmup scheduler as a :class:`dict`.
It is a subset of ``self.__dict__`` .
"""
state_dict = super(LinearWarmup, self).state_dict()
if isinstance(self.learning_rate, LRScheduler):
state_dict["LinearWarmup_LR"] = self.learning_rate.state_dict()
return state_dict
def set_state_dict(self, state_dict):
"""
Loads state_dict for LinearWarmup scheduler.
"""
super(LinearWarmup, self).set_state_dict(state_dict)
if isinstance(self.learning_rate, LRScheduler):
self.learning_rate.set_state_dict(state_dict["LinearWarmup_LR"])
def get_lr(self):
if self.last_epoch < self.warmup_steps:
return (self.end_lr - self.start_lr) * float(
self.last_epoch) / float(self.warmup_steps) + self.start_lr
else:
if isinstance(self.learning_rate, LRScheduler):
self.learning_rate.step(self.last_epoch - self.warmup_steps)
return self.learning_rate()
return self.learning_rate
该接口提供一种学习率优化策略-线性学习率热身(warm up)对学习率进行初步调整。在正常调整学习率之前,先逐步增大学习率。
当训练步数小于热身步数(warmup_steps)时,学习率lr按如下方式更新: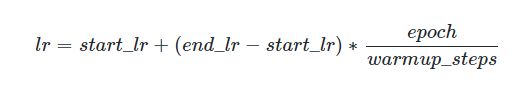
当训练步数大于等于热身步数(warmup_steps)时,学习率lr为:
![]()
其中learning_rate为热身之后的学习率,可以是python的float类型或者 _LRScheduler 的任意子类。
参数:
learning rate (float|_LRScheduler) - 热启训练之后的学习率,可以是python的float类型或者 _LRScheduler 的任意子类。
-
warmup_steps (int) - 进行warm up过程的步数。
-
start_lr (float) - warm up的起始学习率。
-
end_lr (float) - warm up的最终学习率。
-
last_epoch (int,可选) - 上一轮的轮数,重启训练时设置为上一轮的epoch数。默认值为 -1,则为初始学习率 。
-
verbose (bool,可选) - 如果是 True ,则在每一轮更新时在标准输出 stdout 输出一条信息。默认值为 False。
-
返回:用于调整学习率的
LinearWarmup实例对象。
代码实例:
import paddle
import numpy as np
# train on default dynamic graph mode
linear = paddle.nn.Linear(10, 10)
scheduler = paddle.optimizer.lr.LinearWarmup(
learning_rate=0.5, warmup_steps=20, start_lr=0, end_lr=0.5, verbose=True)
sgd = paddle.optimizer.SGD(learning_rate=scheduler, parameters=linear.parameters())
for epoch in range(20):
for batch_id in range(2):
x = paddle.uniform([10, 10])
out = linear(x)
loss = paddle.mean(out)
loss.backward()
sgd.step()
sgd.clear_gradients()
scheduler.step() # If you update learning rate each step
# scheduler.step() # If you update learning rate each epoch
# train on static graph mode
paddle.enable_static()
main_prog = paddle.static.Program()
start_prog = paddle.static.Program()
with paddle.static.program_guard(main_prog, start_prog):
x = paddle.static.data(name='x', shape=[None, 4, 5])
y = paddle.static.data(name='y', shape=[None, 4, 5])
z = paddle.static.nn.fc(x, 100)
loss = paddle.mean(z)
scheduler = paddle.optimizer.lr.LinearWarmup(
learning_rate=0.5, warmup_steps=20, start_lr=0, end_lr=0.5, verbose=True)
sgd = paddle.optimizer.SGD(learning_rate=scheduler)
sgd.minimize(loss)
exe = paddle.static.Executor()
exe.run(start_prog)
for epoch in range(20):
for batch_id in range(2):
out = exe.run(
main_prog,
feed={
'x': np.random.randn(3, 4, 5).astype('float32'),
'y': np.random.randn(3, 4, 5).astype('float32')
},
fetch_list=loss.name)
scheduler.step() # If you update learning rate each step
# scheduler.step() # If you update learning rate each epoch