CVPR2022 | 简单高效的语义分割体系结构
前言 本文提出了一种简单的编码-解码器体系结构,具有类似ResNet的主干和一个小的多尺度头,其性能与复杂的语义分割体系结构(如HRNet、FANet和DDRNets)相当或更好。另外,本文还为桌面和移动目标提供了一系列这样的简单架构。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:http://arxiv.org/pdf/2206.08236
代码:https://github.com/Qualcomm-AI-research/FFNet
背景
尽管语义分割架构(如HRNet)的状态显示出令人印象深刻的准确性,但其显著的设计选择所产生的复杂性阻碍了一系列模型加速工具,而且它们还利用了在当前硬件上效率低下的操作。
本文开始研究这些复杂设计相对于概念上更简单的架构的有效性程度。使用的基线架构与FPN最为密切相关,FPN最初是为目标检测而提出的。具体地说,作者研究了当将更复杂的体系结构的相关非体系结构改进应用于这个简单的基线体系结构时,它们的精度增益是否有效。可以看到,在类似FPN的设计中使用由瓶颈块组成的ResNet50/101骨干网时,网络确实比更复杂的设计要差得多。推测这种性能下降主要是由于使用瓶颈块导致感受野下降。
结果表明,对于由基本块组成的类似深ResNet主干,具有更大的感受野,简单的体系结构确实比更复杂的设计更有利。名为FFNet的简单体系结构不仅减少了推理时间和计算成本,而且完全由各种硬件上支持的操作组成,进一步简化了设备部署。
方法

图1. FFNet体系结构包括一个主干(编码器),类似于ResNet,馈送到一个紧凑的多分支up-head(解码器),该解码器随后将多尺度特征馈送到任务特定的头部。”s’表示步长。主干块的干、宽度和深度、up-head中卷积的宽度、上采样算子的选择(双线性vs最近邻)以及任务头的设计取决于目标平台和任务。
图1描述了Fuss-Free网络(FFNet)的模式:受FPN架构启发的简单架构。它具有编码器-解码器结构。编码器由一个不带分类头的ResNet主干网组成。不只是使用主干网最后一层的特征,而是从所有中间残差阶段提取不同空间分辨率的特征。这些特征被传递到一个轻型卷积解码头,该解码头对低分辨率分支到高分辨率分支的特征进行上采样和合并。这个解码器头,称为“up-head”,以不同的空间分辨率输出特征。
这些多尺度特征随后被用作特定于任务的小型头部的输入,例如用于分割或分类。

图2. 在本文中考虑的stem、up-head和segmentation head的各种选择。这些连接到不同宽度和深度的骨干网络,如表1所示。对于GPU,使用双线性上采样。对于移动模型,使用最近邻上采样。所描述的选择并不全面,仅表示潜在NAS搜索空间中的几个不同点。本文将stem、up-head和segmentation head选项组合称为A-B-B、C-B-C等。
FFNet的一般设置具有很大的灵活性,可以自由更改主干构建块的宽度、深度和类型、特征比例的数量、头部类型和头部宽度。图2描述了在本文中研究的各种stem、up-head和segmentation head,标记为A/B/C。这些选择与表1中描述的各种主干宽度和深度配置相结合,具体取决于目标平台。主干中的第一个残差块可以具有1或2的步长,这会改变输出的空间分辨率。
本文展示了桌面GPU和移动目标的模型。**桌面模型在Up-head中使用双线性上采样,而移动模型使用最近邻上采样。**这是一种简单的设计,对主干中的阶段数量或输出的特征量表数量、主干和主干中步长的选择没有特别的限制。因此,该体系结构可以很容易地适应其他任务。
实验
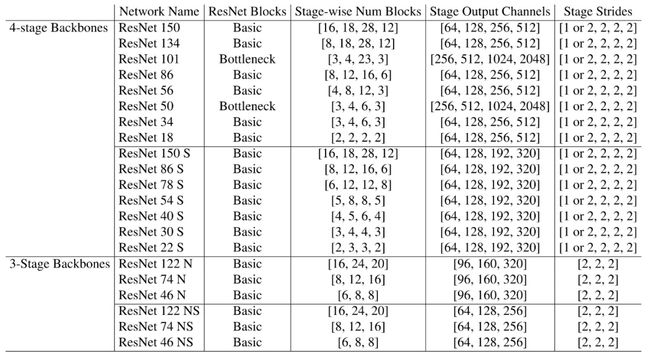
表1. 本文研究的主干结构。遵循resnet的命名约定,尽管它们与图2所示的不同stem和head配对,这改变了层的总体数量。
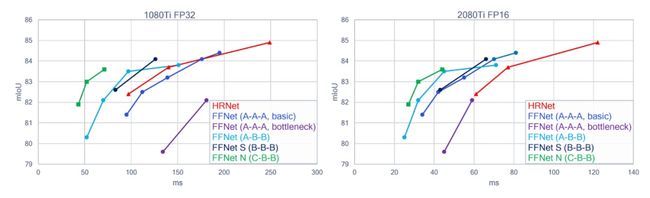
图3. FFNet GPU大型模型的推理延迟与在CityScape上的精度:使用基本块的简单FFNet(蓝色)与HRNET(红色)相当,而使用瓶颈块的FFNet(紫色)明显更差。探索up-head宽度(青色)和主干宽度(黑色)的各种组合,可以创建更好的模型。具有3级主干(绿色)的FFNET可能比4级FFNET提供更好的帕累托性能。输入分辨率1024×2048,输出分割图分辨率256×512。见表2。
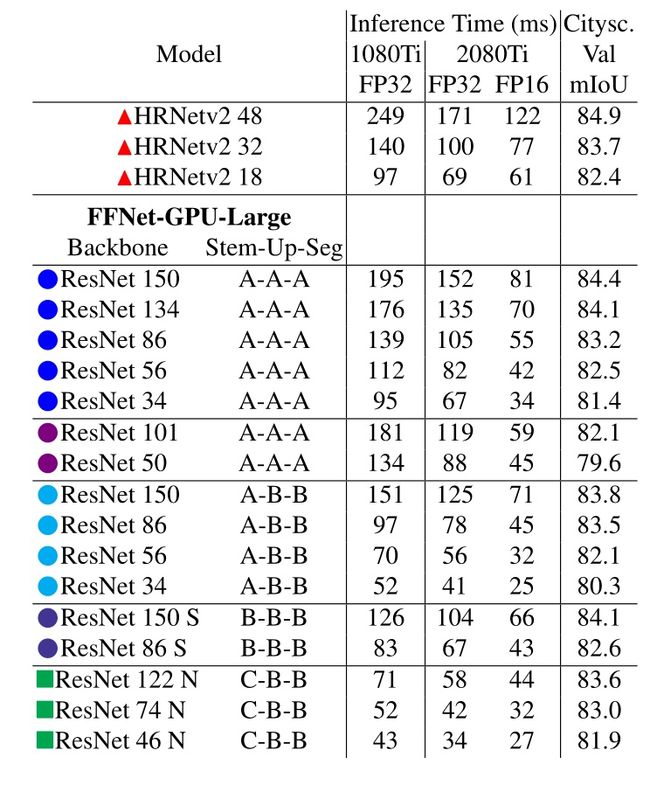
*表2. 模型的输出分割图分辨率为256×512,输入图像分辨率为1024×2048。在ResNet主干的第一个块中,FFNET的步长为1。

*表3. 模型的输出分割图分辨率为128×256,输入图像分辨率为1024×2048。此处报告的计时没有批次标准折叠,批次大小为1。†这些模型在ResNet主干的第一阶段使用步长=2。
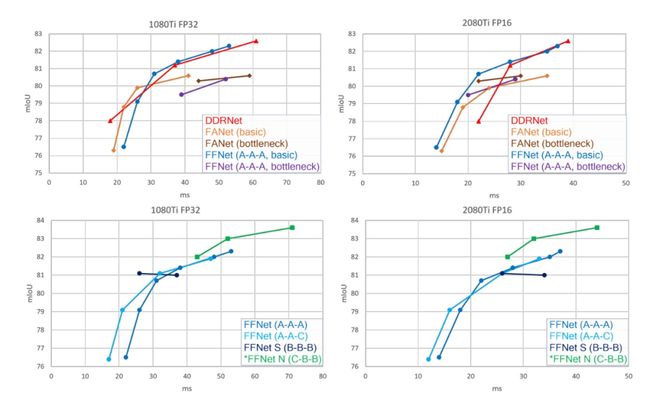
图5. FFNet GPU小型模型的推理延迟与在Cityscapes上的精度:(顶部)FFNet(蓝色)的性能与DDRNet(红色)和FANet(橙色和棕色)等复杂模型相当。对于FFNET,基本块(蓝色)总是优于瓶颈块(紫色)。(底部)模型空间可以通过基本块主干和不同宽度(青色和黑色)的顶部组合来探索,以创建更好的模型。输入分辨率1024×2048,输出分割图分辨率128×256。见表3。

表4. FFNet移动模型的推断时间与Cityscapes验证精度:验证精度适用于FP16模型,而推断时间适用于三星S21 DSP上的8位量化模型。推断时间是针对批量大小为1的情况进行测量的。†这些模型在ResNet主干的第一个块中使用步长=2。

图6. 三星S21上FFNet移动模型的推断延迟与在Cityscapes上的精度:模型在移动DSP上实时运行。无论输入分辨率如何,所有模型都以相同的分辨率输出分割图。
结论
本文表明,简单的基于FPN的语义图像分割基线是高效的,并且在各种设备上与SoTA体系结构不相上下。另外,为ImageNet设计的特定体系结构实例不一定是其他任务的最佳实例,并且在相同的设计空间中存在更好的特定于任务的体系结构。在决定从另一个任务移植网络之前,考虑任务的具体要求是很有帮助的。
CV技术指南创建了一个计算机视觉技术交流群和免费版的知识星球,目前星球内人数已经700+,主题数量达到200+。
知识星球内将会每天发布一些作业,用于引导大家去学一些东西,大家可根据作业来持续打卡学习。
CV技术群内每天都会发最近几天出来的顶会论文,大家可以选择感兴趣的论文去阅读,持续follow最新技术,若是看完后写个解读给我们投稿,还可以收到稿费。 另外,技术群内和本人朋友圈内也将发布各个期刊、会议的征稿通知,若有需要的请扫描加好友,并及时关注。
加群加星球方式:关注公众号CV技术指南,获取编辑微信,邀请加入。
公众号其它文章
计算机视觉入门路线
计算机视觉中的论文常见单词总结
YOLO系列梳理(四)关于YOLO的部署
YOLO系列梳理(三)YOLOv5
YOLO系列梳理(二)YOLOv4
YOLO系列梳理(一)YOLOv1-YOLOv3
CVPR2022 | 可精简域适应
CVPR2022 | 基于自我中心数据的OCR评估
CVPR 2022 | 使用对比正则化方法应对噪声标签
CVPR2022 | 弱监督多标签分类中的损失问题
CVPR2022 | iFS-RCNN:一种增量小样本实例分割器
CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
CVPR2022 | PanopticDepth:深度感知全景分割的统一框架
CVPR2022 | 重新审视池化:你的感受野不是最理想的
CVPR2022 | 未知目标检测模块STUD:学习视频中的未知目标
CVPR2022 | 基于排名的siamese视觉跟踪
从零搭建Pytorch模型教程(六)编写训练过程和推理过程
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建Pytorch模型教程(四)编写训练过程--参数解析
从零搭建Pytorch模型教程(三)搭建Transformer网络
从零搭建Pytorch模型教程(二)搭建网络
从零搭建Pytorch模型教程(一)数据读取
关于快速学习一项新技术或新领域的一些个人思维习惯与思想总结