图神经网络学习(三)-常见的图神经网络库
1.Pytorch Geometric
PyTorch Geometric Library (简称 PyG) 是一个基于 PyTorch 的图神经网络库。它包含了很多 GNN 相关论文中的方法实现和常用数据集,并且提供了简单易用的接口来生成图。
1.1 数据集

1.1.1 使用PyG自带的数据集
# %%
# 数据加载
dataset = Planetoid(root="data/Cora", name="Cora")
print(dataset)
print(dataset[0])
print(dataset.data)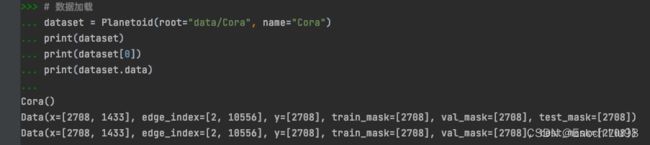
1.1.2 自己diy数据集
#%%
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)1.2 模型定义
大部分
图神经网络层的输入(两项):节点数据,边数据
图神经网络层的定义:节点的维度,输出的维度
1.2.1 GCN
# %%
# 构建一个网络模型类
class GCNnet(torch.nn.Module):
def __init__(self, input_feature, num_classes):
super(GCNnet, self).__init__()
self.input_feature = input_feature # 输入数据中,每个节点的特征数量
self.num_classes = num_classes
self.conv1 = GCNConv(input_feature, 32)
self.conv2 = GCNConv(32, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.conv2(x, edge_index)
return F.softmax(x, dim=1)1.2.2 GraphSage
# %%
# 构建一个网络模型类
class SAGEnet(torch.nn.Module):
def __init__(self, input_feature, num_classes):
super(SAGEnet, self).__init__()
self.input_feature = input_feature # 输入数据中,每个节点的特征数量
self.num_classes = num_classes
self.conv1 = SAGEConv(input_feature, 32)
self.conv2 = SAGEConv(32, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.conv2(x, edge_index)
return F.softmax(x, dim=1)1.2.3 GAT
# %%
# 构建一个网络模型类
class GATnet(torch.nn.Module):
def __init__(self, input_feature, num_classes):
super(GATnet, self).__init__()
self.input_feature = input_feature # 输入数据中,每个节点的特征数量
self.num_classes = num_classes
self.conv1 = GATConv(input_feature, 32, heads=2)
self.conv2 = GATConv(2 * 32, num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = self.conv2(x, edge_index)
return F.softmax(x, dim=1)1.3 模型训练
1.3.1 不使用dataloader
# %%
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GATnet(dataset.num_node_features, dataset.num_classes).to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
model.eval()
_, pred = model(data).max(dim=1)
correct = pred[data.test_mask].eq(data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print('GAT:', acc)对于这种只有一个图的情况,不需要dataloader,也就没有batch的概念
1.3.2 使用dataloader
from torch_scatter import scatter_mean
from torch_geometric.datasets import TUDataset
from torch_geometric.data import DataLoader
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for data in loader:
data
#data: Batch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])
x = scatter_mean(data.x, data.batch, dim=0)
# x.size(): torch.Size([32, 21])
1.4 常用API
| 模块 | 类或者函数 | 功能 |
| torch_geometric.nn | GCNConv() | GCN层 |
| ChebConv() | Chebyshev谱图卷积层 | |
| SAGEConv() | GraphSAGE算子层 | |
| GATConv | 图注意力算子层 | |
| BatchNorm() | 对一个batch的节点特征进行标准化操作 |
|
| InstanceNorm() | 对节点特征进行标准化操作 | |
| torch_geometric.data | Data() | 图神经网络的数据类 |
| Dataset() | 用于创建数据集的类 | |
| DataLoader() | 数据加载器 | |
| torch_geometirc.datasets | Planetoid() | 文献引用网络数据集,包含Cora,CiteSeer等 |
| torch_geometric.transforms | Compose() | 把多种操作组合在一起 |
| Constant() | 为每个节点的特征加一个常数 | |
| Distance() | 将节点的欧几里得距离保存在其边属性中 | |
| OneHotDegree() | 将节点度使用onehot添加到节点特征中 | |
| KNNGraph() | 基于节点的位置创建一个KNN图 |
2. TensorFlow Geometric
TensorFlow版本的图神经网络库,同时提供面向对象接口(OOP API)和函数接口(functional API).
2.1 数据集
2.1.1 使用自带的dataset
graph, (train_index, valid_index, test_index) = CoraDataset().load_data()自带很多常见数据集,具体见2.4的常见API部分
2.1.2 自己diy数据集
graph = tfg.Graph(
x=np.random.randn(5, 20), # 5个节点, 20维特征
edge_index=[[0, 0, 1, 3],
[1, 2, 2, 1]] # 4个无向边
)
print("Graph Desc: \n", graph)
graph.convert_edge_to_directed() # 预处理边数据,将无向边表示转换为有向边表示
print("Processed Graph Desc: \n", graph)
print("Processed Edge Index:\n", graph.edge_index)
# 多头图注意力网络(Multi-head GAT)
gat_layer = tfg.layers.GAT(units=4, num_heads=4, activation=tf.nn.relu)
output = gat_layer([graph.x, graph.edge_index])
print("Output of GAT: \n", output)2.2 模型定义
具体定义方式与tf的定义方式一致,所以很好上手
num_classes = graph.y.max() + 1
drop_rate = 0.5
learning_rate = 1e-2
# Multi-layer GCN Model
class GCNModel(tf.keras.Model):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.gcn0 = tfg.layers.GCN(16, activation=tf.nn.relu)
self.gcn1 = tfg.layers.GCN(num_classes)
self.dropout = tf.keras.layers.Dropout(drop_rate)
def call(self, inputs, training=None, mask=None, cache=None):
x, edge_index, edge_weight = inputs
h = self.dropout(x, training=training)
h = self.gcn0([h, edge_index, edge_weight], cache=cache)
h = self.dropout(h, training=training)
h = self.gcn1([h, edge_index, edge_weight], cache=cache)
return h2.3 模型训练
model = GCNModel()
# @tf_utils.function can speed up functions for TensorFlow 2.x.
# @tf_utils.function is not compatible with TensorFlow 1.x and dynamic graph.cache.
@tf_utils.function
def forward(graph, training=False):
return model([graph.x, graph.edge_index, graph.edge_weight], training=training, cache=graph.cache)
# The following line is only necessary for using GCN with @tf_utils.function
# For usage without @tf_utils.function, you can commont the following line and GCN layers can automatically manager the cache
model.gcn0.build_cache_for_graph(graph)
@tf_utils.function
def compute_loss(logits, mask_index, vars):
masked_logits = tf.gather(logits, mask_index)
masked_labels = tf.gather(graph.y, mask_index)
losses = tf.nn.sparse_softmax_cross_entropy_with_logits(
logits=masked_logits,
labels=masked_labels
)
kernel_vars = [var for var in vars if "kernel" in var.name]
l2_losses = [tf.nn.l2_loss(kernel_var) for kernel_var in kernel_vars]
return tf.reduce_mean(losses) + tf.add_n(l2_losses) * 5e-4
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate)
@tf_utils.function
def train_step():
with tf.GradientTape() as tape:
logits = forward(graph, training=True)
loss = compute_loss(logits, train_index, tape.watched_variables())
vars = tape.watched_variables()
grads = tape.gradient(loss, vars)
optimizer.apply_gradients(zip(grads, vars))
return loss2.4 常用API
| tf_geometric.datasets | Planetoid |
| Cora | |
| Citeseer | |
| Pubmed | |
| TU | |
| 其他的数据集 | |
| tf_geometric.layers | GCN |
| GAT | |
| GraphSAGE | |
| 其他的层 | |
| tf.geometric.nn | gcn |
| gat | |
| graph_sage | |
| 其他函数 |