【文献阅读】SLAKE——医学图像的VQA双语数据集(Bo Liu等人,ArXiv,2021)
一、背景
文章题目:《SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering》
文章下载地址:https://arxiv.org/pdf/2102.09542.pdf
文章引用格式:Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, Xiao-Ming Wu. "SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Question Answering". arXiv preprint, arXiv: 2102.09542, 2021.
项目地址:http://www.med-vqa.com/slake
二、文章摘要
Medical visual question answering (Med-VQA) has tremendous potential in healthcare. However, the development of this technology is hindered by the lacking of publicly-available and high-quality labeled datasets for training and evaluation. In this paper, we present a large bilingual dataset, SLAKE, with comprehensive semantic labels annotated by experienced physicians and a new structural medical knowledge base for Med-VQA. Besides, SLAKE includes richer modalities and covers more human body parts than the currently available dataset. We show that SLAKE can be used to facilitate the development and evaluation of Med-VQA systems. The dataset can be downloaded from http://www.med-vqa.com/slake
Med-VQA在医疗保健领域具有非常大的潜力。然而,由于缺乏高质量的公开数据集,这项技术一直发展受限。在本文中,我们提出了一个双语的数据集,SLAKE,该数据集包含的语义标签由经验丰富的医生进行标注,且包含新的结构化的医学知识。此外,SLKAE包含有丰富的模态,与其他数据集相比,有着更多的人体部分。我们表明SLAKE能够用于发展和评估Med-VQA系统。
三、文章介绍
Med-VQA在医疗健康领域有着巨大的应用前景,然而关于Med-VQA的研究仍处于起步阶段,不同于传统领域的VQA,它们都有大规模高质量的数据集可用,Med-VQA的数据集仍旧非常缺乏,目前仅有VQA-RAD做了这项工作。但是VQA-RAD却没有提供图像的语义标签,并且并没有涉及到外部知识。
为了填补这项空白,本文提出了新的数据集,即semantically-labeled knowledge-enhanced (SLAKE) dataset。这项工作耗费了作者多半年的时间,包括构建标注系统,医学知识图,选择标注图像,生成问题,分析数据集。如下图所示:

对于每一张放射图,我们都提供两种标注,一种是语义分割图,另一种是bounding box的目标标注图。除了最基本的医学问题,我们还提供了需要多步推理和外部知识的问题。除了这些设计之外,SLAKE还是一个双语的数据集,包含英语和汉语。SLAKE与VQA-RAD数据集相比的结果如下所示:

本文的主要贡献有两个方面:
• We create SLAKE, a large-scale, semantically annotated, and knowledge-enhanced bilingual dataset for training and testing Med-VQA systems. 创建了SLAKE数据集。
• We experiment with representative Med-VQA methods to show that SLAKE can be used as a benchmark to train systems to solve practical and complex tasks. 验证了SLAKE可以用做benchmark
1. SLAKE数据集
SLAKE包含了多个模态的数据,比如CT, MRI, and X-Ray,且有人体的多个部位,比如head, neck, and chest。
(1)图像获取和标注(Image Acquisition and Annotation)
图像是从三个开源的数据集中收集来的,都是放射图,包含有健康的和不健康的样本。总计642张图像,涉及12种疾病和39种器官,图像类型的分布如下图:

(2)知识图的构建(Knowledge Graph Construction)
为了设置需要外部知识回答的问题,作者构建了知识图。作者基于维基百科构建
之后作者根据如下规则对指示图进行了精校正:1)关于器官的元组,必须描述其功能或者是身体系统,2)关于疾病的元组,必须描述其症状,位置,原因,治疗和预防,一些示例如下表所示:

最终,大约有2603个英语元组和2629个汉语元组。
(3)问题生成(Question Generation)
问题是由有经验的医生提出的,为了提高效率,作者制作了一个标注系统,在这个系统中,首先作者为身体的每一个部分定义一个问题模板;然后再定义了10种问题类型,比如颜色,模态,位置,这10种类型具体如下表所示:

此外,作者为每一个问题提供了语义标签,形式采用
另外,根据一些研究,数据集中问题分布可能会产生答案的偏见,为了减小SLAKE的内在偏见,我们会尽量使得答案的数量保持平衡。
(4)数据划分(Dataset Splitting)
training:validation:test=70%:15%:15%。其中还需要注意的一点就是,验证数据中出现的答案必须是训练集中出现过的。
2. 实验
(1)实验设置(Experiment Setup)
pipeline的示意图如下:
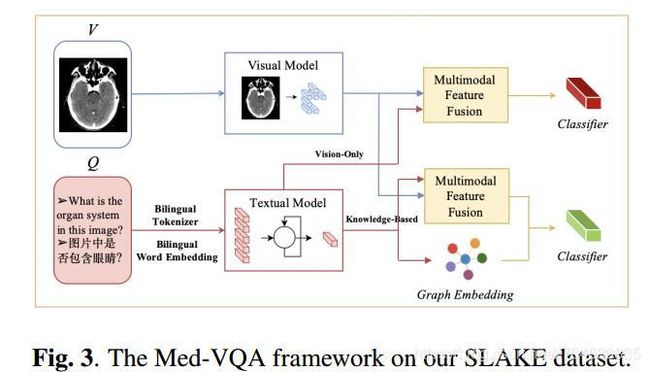
在SLAKE数据上,作者使用的是SAN框架。用VGG16来提取视觉特征;对于双语问题。作者设置了一个双语分词器,用于建立双语的词嵌入。然后用1024维的LSTM来提取问题的语义特征;如上图所示,它有两个分支,一个是vision-only,就是用SAN的框架,来融合两个模态的特征。在另一个需要外部知识的模型中,还会额外将问题嵌入拿出来,来提取相应的知识图信息。
(2)数据分析(Dataset Analysis)
vision-only的实验结果如下表所示:

knowledge-based的实验结果如下表所示:
