python采集世界大学排名并作数据可视化, 来看看你的母校上榜没~
前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐
本篇文章目录(可自由点击你想看的地方)
-
- 前言
- 知识点:
- 准备工作
-
-
- 如果安装python第三方模块:
- 如何配置pycharm里面的python解释器?
- pycharm如何安装插件?
-
- 代码
-
- 采集排名数据
- 数据分析代码
- 可视化效果(部分)
- 尾语
代码提供者:青灯教育-巳月
知识点:
- 动态数据抓包
- requests发送请求
- 结构化+非结构化数据解析
准备工作
下面的尽量跟我保持一致哦~不然有可能会发生报错
开发环境:
- python 3.8
运行代码 - pycharm 2021.2
辅助敲代码 - requests
第三方模块 pip install 模块名
如果安装python第三方模块:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
如何配置pycharm里面的python解释器?
-
选择file(文件) >>> setting(设置) >>> Project(项目) >>> python interpreter(python解释器)
-
点击齿轮, 选择add
-
添加python安装路径
pycharm如何安装插件?
-
选择file(文件) >>> setting(设置) >>> Plugins(插件)
-
点击 Marketplace 输入想要安装的插件名字 比如:翻译插件 输入 translation / 汉化插件 输入 Chinese
-
选择相应的插件点击 install(安装) 即可
-
安装成功之后 是会弹出 重启pycharm的选项 点击确定, 重启即可生效
软件、解答、源码、教程可以私信博主免费获取~
代码
采集排名数据
import requests
import re
import csv
def replace(str_):
str_ = re.findall('(.*?)', str_)[0]
return str_
with open('rank.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(['country', 'rank', 'region', 'score_1', 'score_2', 'score_3', 'score_4', 'score_5', 'score_6', 'stars', 'total_score', 'university', 'year'])
url = 'https://www.qschina.cn/sites/default/files/qs-rankings-data/cn/2057712_indicators.txt'
response = requests.get(url=url)
json_data = response.json()
data = json_data['data']
for i in data:
country = i['location'] # 国家/地区
rank = i['overall_rank'] # 排名
region = i['region'] # 大洲
score_1 = replace(i['ind_76']) # 学术声誉
score_2 = replace(i['ind_77']) # 雇主声誉
score_3 = replace(i['ind_36']) # 师生比
score_4 = replace(i['ind_73']) # 教员引用率
score_5 = replace(i['ind_18']) # 国际教室
score_6 = replace(i['ind_14']) # 国际学生
stars = i['stars'] # 星级
total_score = replace(i['overall']) # 总分
university = i['uni'] # 大学
university = re.findall('(.*?)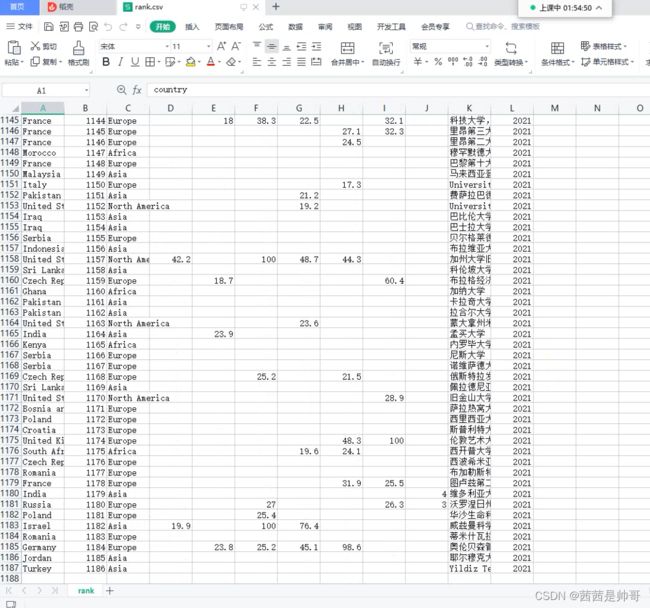
数据分析代码
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
from pyecharts.components import Table
import re
import pandas as pd
df = pd.read_csv('rank.csv')
# 香港,澳门与中国大陆地区等在榜单中是分开的记录的,这边都归为china
df['loc'] = df['country']
df['country'].replace(['China (Mainland)', 'Hong Kong SAR', 'Taiwan', 'Macau SAR'],'China',inplace=True)
tool_js = """
<div style="border-bottom: 1px solid rgba(255,255,255,.3); font-size: 18px;padding-bottom: 7px;margin-bottom: 7px">
{}
</div>
排名:{} <br>
国家地区:{} <br>
加权总分:{} <br>
国际学生:{} <br>
国际教师:{} <br>
师生比例:{} <br>
学术声誉:{} <br>
雇主声誉:{} <br>
教员引用率:{} <br>
"""
t_data = df[(df.year==2021) & (df['rank']<=100)]
t_data = t_data.sort_values(by="total_score" , ascending=True)
university, score = [], []
for idx, row in t_data.iterrows():
tjs = tool_js.format(row['university'], row['rank'], row['country'],row['total_score'],
row['score_6'],row['score_5'], row['score_3'],row['score_1'],row['score_2'], row['score_4'])
if row['country'] == 'China':
university.append(' {}'.format(re.sub('(.*?)', '',row['university'])))
else:
university.append(re.sub('(.*?)', '',row['university']))
score.append(opts.BarItem(name='', value=row['total_score'], tooltip_opts=opts.TooltipOpts(formatter=tjs)))
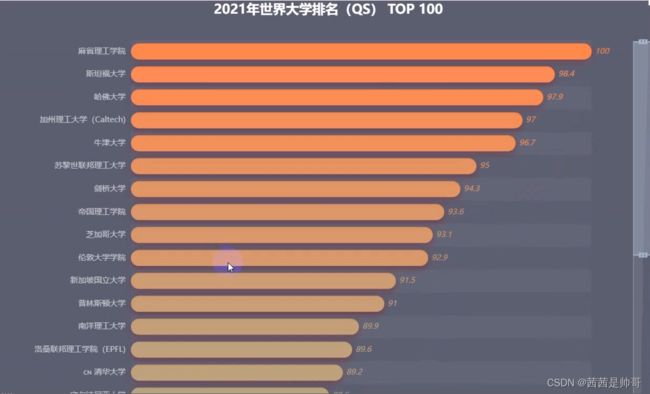
### TOP 100高校
篇幅有限,这边只展示TOP100的高校,完整的榜单可以通过附件下载查看~
* 排名第一的大学是麻省理工,在单项上除了**国际学生**和**教员引用率**其余都是100分;
* TOP4大学全部来自美国,除此之外是排名第五的牛津大学;
* **国内排名最高的大学是清华大学,排名15**,其次是香港大学&北京大学;
bar = (Bar()
.add_xaxis(university)
.add_yaxis('', score, category_gap='30%')
.set_global_opts(title_opts=opts.TitleOpts(title="2021年世界大学排名(QS) TOP 100",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(font_size=20)),
datazoom_opts=opts.DataZoomOpts(range_start=70, range_end=100, orient='vertical'),
visualmap_opts=opts.VisualMapOpts(is_show=False, max_=100, min_=60, dimension=0,
range_color=['#00FFFF', '#FF7F50']),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(is_show=False, is_scale=True),
yaxis_opts=opts.AxisOpts(axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(is_show=False),
axislabel_opts=opts.LabelOpts(font_size=12)))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='right',
font_style='italic'),
itemstyle_opts={"normal": {
"barBorderRadius": [30, 30, 30, 30],
'shadowBlur': 10,
'shadowColor': 'rgba(120, 36, 50, 0.5)',
'shadowOffsetY': 5,
}
}
).reversal_axis())
grid = (
Grid(init_opts=opts.InitOpts(theme='purple-passion', width='1000px', height='1200px'))
.add(bar, grid_opts=opts.GridOpts(pos_right='10%', pos_left='20%'))
)
grid.render_notebook()
tool_js = """
<div style="border-bottom: 1px solid rgba(255,255,255,.3); font-size: 18px;padding-bottom: 7px;margin-bottom: 7px">
{}
</div>
世界排名:{} <br>
国家地区:{} <br>
加权总分:{} <br>
国际学生:{} <br>
国际教师:{} <br>
师生比例:{} <br>
学术声誉:{} <br>
雇主声誉:{} <br>
教员引用率:{} <br>
"""
t_data = df[(df.country=='China') & (df['rank']<=500)]
t_data = t_data.sort_values(by="total_score" , ascending=True)
university, score = [], []
for idx, row in t_data.iterrows():
tjs = tool_js.format(row['university'], row['rank'], row['country'],row['total_score'],
row['score_6'],row['score_5'], row['score_3'],row['score_1'],row['score_2'], row['score_4'])
if row['country'] == 'China':
university.append(' {}'.format(re.sub('(.*?)', '',row['university'])))
else:
university.append(re.sub('(.*?)', '',row['university']))
score.append(opts.BarItem(name='', value=row['total_score'], tooltip_opts=opts.TooltipOpts(formatter=tjs)))
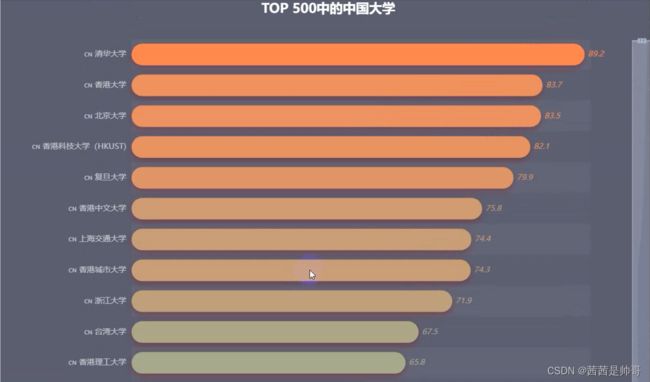
### 中国大学排名
因为在500名之后没有具体的分值,所以这里只筛选了榜单TOP 500中的国内高校;
* 在第一梯队中,香港的高校占比很高,**TOP10中有4所来自香港**;
* 刨除香港的高校,**TOP5高校分别是清华,北大,复旦,上交,浙大**;
bar = (Bar()
.add_xaxis(university)
.add_yaxis('', score, category_gap='30%')
.set_global_opts(title_opts=opts.TitleOpts(title="TOP 500中的中国大学",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(font_size=20)),
datazoom_opts=opts.DataZoomOpts(range_start=50, range_end=100, orient='vertical'),
visualmap_opts=opts.VisualMapOpts(is_show=False, max_=90, min_=20, dimension=0,
range_color=['#00FFFF', '#FF7F50']),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(is_show=False, is_scale=True),
yaxis_opts=opts.AxisOpts(axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(is_show=False),
axislabel_opts=opts.LabelOpts(font_size=12)))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='right',
font_style='italic'),
itemstyle_opts={"normal": {
"barBorderRadius": [30, 30, 30, 30],
'shadowBlur': 10,
'shadowColor': 'rgba(120, 36, 50, 0.5)',
'shadowOffsetY': 5,
}
}
).reversal_axis())
grid = (
Grid(init_opts=opts.InitOpts(theme='purple-passion', width='1000px', height='1200px'))
.add(bar, grid_opts=opts.GridOpts(pos_right='10%', pos_left='20%'))
)
grid.render_notebook()
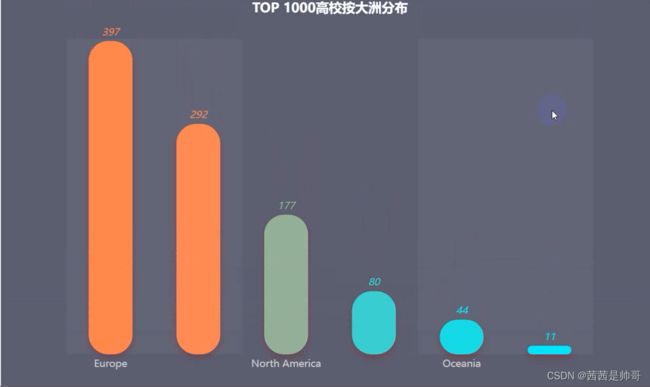
### 按大洲分布
* TOP 1000高校中有**近40%是来自于欧洲**;
* 非洲仅有11所高校上榜;
t_data = df[(df.year==2021) & (df['rank']<=1000)]
t_data = t_data.groupby(['region'])['university'].count().reset_index()
t_data.columns = ['region', 'num']
t_data = t_data.sort_values(by="num" , ascending=False)
bar = (Bar(init_opts=opts.InitOpts(theme='purple-passion', width='1000px', height='600px'))
.add_xaxis(t_data['region'].tolist())
.add_yaxis('出现次数', t_data['num'].tolist(), category_gap='50%')
.set_global_opts(title_opts=opts.TitleOpts(title="TOP 1000高校按大洲分布",
pos_left="center",
title_textstyle_opts=opts.TextStyleOpts(font_size=20)),
visualmap_opts=opts.VisualMapOpts(is_show=False, max_=300, min_=0, dimension=1,
range_color=['#00FFFF', '#FF7F50']),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(axistick_opts=opts.AxisTickOpts(is_show=False),
axisline_opts=opts.AxisLineOpts(is_show=False),
axislabel_opts=opts.LabelOpts(font_size=15)),
yaxis_opts=opts.AxisOpts(is_show=False))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,
position='top',
font_size=15,
font_style='italic'),
itemstyle_opts={"normal": {
"barBorderRadius": [30, 30, 30, 30],
'shadowBlur': 10,
'shadowColor': 'rgba(120, 36, 50, 0.5)',
'shadowOffsetY': 5,
}
}
))
bar.render_notebook()
更多数据分析代码可以私信博主免费获取~
可视化效果(部分)
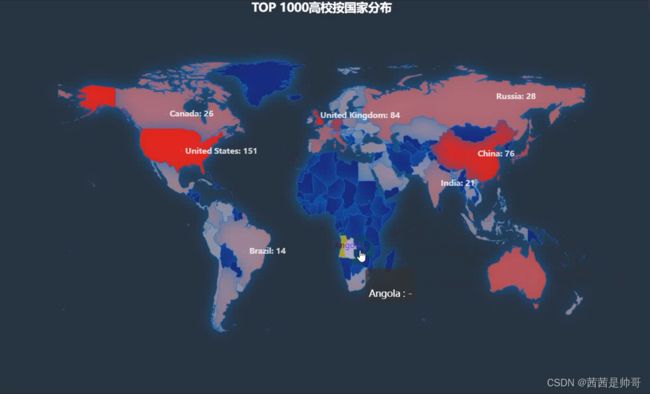

尾语
感谢你观看我的文章呐~本次航班到这里就结束啦
希望本篇文章有对你带来帮助 ,有学习到一点知识~
躲起来的星星也在努力发光,你也要努力加油(让我们一起努力叭)。
最后,博主要一下你们的三连呀(点赞、评论、收藏),不要钱的还是可以搞一搞的嘛~
不知道评论啥的,即使扣个6666也是对博主的鼓舞吖 感谢