PSM+DID 效果评估python demo 、线性分类模型+双重差分法
需求背景:
策略不适用随机分流,在某部分人群全量上线,需要同通过构建相似人群的方式,对策略进行评估。
评估方案:
1、使用PSM构建相似人群,确保实验组与对照组在AA期的评估指标趋势能够保持一致
2、通过DID对实验效果进行评估,确认策略对实验组的影响。
一、构建相似人群
1.1环境包导入
import warnings
warnings.filterwarnings('ignore')
# from pymatch.Matcher import Matcher
import pandas as pd
import numpy as np
%matplotlib inline
from scipy import stats
import matplotlib.pyplot as plt
import patsy
from statsmodels.genmod.generalized_linear_model import GLM
import statsmodels.api as sm
import seaborn as sns
import sys
import os
from jinja2 import Template
import prestodb
from pyhive import hive
from scipy import stats
import patsy
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
#指定默认字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
#解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
def presto_read_sql_df(sql):
conn=prestodb.dbapi.connect(
host=os.environ['PRESTO_HOST'],
port=os.environ['PRESTO_PORT'],
user=os.environ['JUPYTER_HADOOP_USER'],
password=os.environ['HADOOP_USER_PASSWORD'],
catalog='hive')
cur = conn.cursor()
cur.execute(sql)
query_result = cur.fetchall()
colnames = [part[0] for part in cur.description]
raw = pd.DataFrame(query_result, columns=colnames,dtype=np.float64)
return raw
def hive_read_sql_df(sql):
conn = hive.connect(
host=os.environ['PYHIVE_HOST'],
port=os.environ['PYHIVE_PORT'],
username=os.environ['JUPYTER_HADOOP_USER'],
password=os.environ['HADOOP_USER_PASSWORD'],
auth='LDAP',
configuration={'mapreduce.job.queuename': os.environ['JUPYTER_HADOOP_QUEUE'],
'hive.resultset.use.unique.column.names':'false'})
raw = pd.read_sql_query(sql,conn)
return raw1.2数据获取
# 1.2.1通过SQL查询数据
# df = hive_read_sql_df("""
# select
# XXXX
# from
# XXXXX
# where
# XXXXX
# """)
# df.to_csv('file_name.csv',encoding='gbk',sep=',',index = False)
#1.2.2通过文件读取获得数据
df = pd.read_csv('file_name.csv',encoding='gbk')
y_date = df
y_date.dtypes #check 数据的数据类型 1.3模型构建
# 设定匹配因子和分组标签
X_field=[
'XXXX' ,'XXXX','XXXX' #分组标签名称
]
Y_field=['is_group']
field=X_field+Y_field
field# 循环字段 :根据需要选择,仅匹配一组,则不需要循环
city_list = {
# 'XXXX','XXXX','XXXX'
}city_psm_dri = None
for x in city_list :
city_name = x
print('='*20+'城市:'+city_name +'='*20)
query_str = "city_name=='"+city_name+"'"
city_info = y_date.query(query_str)
#数据筛选,删除一些非必要的数据
city_info = city_info.drop(columns=["city_name"]) #删除城市名称列
city_info = city_info.query("is_strategy_time=='0'")
city_info = city_info.query("XXX > 0")
#归一化 非必须
city_info.online_days = (city_info.online_days-city_info.online_days.min())/(city_info.online_days.max()-city_info.online_days.min())
data=city_info
data=data.dropna()
# 区分实验/对照组样本
treated=data[(data['is_group']==1)]
control=data[(data['is_group']==0)]
ttest_result_t=pd.DataFrame(stats.ttest_ind(treated,control))
data_p = data
# 构建一个线性模型
print("-"*20+'模型定义'+"-"*20)
y_f,x_f=patsy.dmatrices('{} ~ {}'.format(Y_field[0], '+'.join(X_field)), data=data_p, return_type='dataframe')
formula = '{} ~ {}'.format(Y_field[0], '+'.join(X_field))
print('Formula: '+formula)
i=0
nmodels=100
errors=0
model_accuracy = []
models = []
while i < nmodels and errors < 5:
sys.stdout.write('\r{}: {}\{}'.format("Fitting Models on Balanced Samples", i, nmodels)) #第几个模型
# sample from majority to create balance dataset
df = control.sample(len(treated)).append(treated).dropna() #模型选择相同的对照组和控制组样本
y_samp, X_samp = patsy.dmatrices(formula, data=df, return_type='dataframe') #选出模型的自变量和因变量
glm = GLM(y_samp, X_samp, family=sm.families.Binomial()) #逻辑回归模型
try:
res = glm.fit()
preds = [1.0 if i >= .5 else 0.0 for i in res.predict(X_samp)]
preds=pd.DataFrame(preds)
preds.columns=y_samp.columns
b=y_samp.reset_index(drop=True)
a=preds.reset_index(drop=True)
ab_score=((a.sort_index().sort_index(axis=1) == b.sort_index().sort_index(axis=1)).sum() * 1.0 / len(y_samp)).values[0] # 模型预测准确性得分
# print(' model_accuracy:{}'.format(ab_score))
model_accuracy.append(ab_score)
models.append(res)
i += 1
except Exception as e:
errors += 1 # to avoid infinite loop for misspecified matrix
print('\nError: {}'.format(e))
print("\nAverage Accuracy:", "{}%".
format(round(np.mean(model_accuracy) * 100, 2)))# 所有模型的平均准确性
print('Fitting 1 (Unbalanced) Model...')
if errors >= 5: ##异常城市
print("【异常警告:】"+city_name+'数据出现异常,该城市数据未记录\n')
city_info.to_csv(city_name+'.csv',encoding='gbk',sep=',',index = False)
continue
glm = GLM(y_f, x_f, family=sm.families.Binomial())
res = glm.fit()
# model_accuracy.append(self._scores_to_accuracy(res, x_f, y_f))
preds = [1.0 if i >= .5 else 0.0 for i in res.predict(x_f)]
preds=pd.DataFrame(preds)
preds.columns=y_f.columns
b=y_f.reset_index(drop=True)
a=preds.reset_index(drop=True)
ab_score=((a.sort_index().sort_index(axis=1) == b.sort_index().sort_index(axis=1)).sum() * 1.0 / len(y_f)).values[0]
model_accuracy.append(ab_score)
models.append(res)
print("\nAccuracy", round(np.mean(model_accuracy[0]) * 100, 2))
scores = np.zeros(len(x_f))
for i in range(nmodels):
m = models[i]
scores += m.predict(x_f)
data_p['scores'] = scores/nmodels
# 绘图
plt.figure(figsize=(10,5))
sns.distplot(data_p[data_p[Y_field[0]]==0].scores, label='Control')
sns.distplot(data_p[data_p[Y_field[0]]==1].scores, label='Test')
plt.legend(loc='upper right')
plt.xlim((0, 1))
plt.title("Propensity Scores Before Matching")
plt.ylabel("Percentage (%)")
plt.xlabel("Scores")
threshold=0.00001
method='min' # 使用最近样本匹配方法
nmatches=1
test_scores = data_p[data_p[Y_field[0]]==True][['scores']]
ctrl_scores = data_p[data_p[Y_field[0]]==False][['scores']]
result, match_ids = [], []
for i in range(len(test_scores)):
#print(i)
if i % 10 == 0:
sys.stdout.write('\r{}: {}'.format("Fitting Samples", i ))
# uf.progress(i+1, len(test_scores), 'Matching Control to Test...')
match_id = i
score = test_scores.iloc[i]
if method == 'random':
bool_match = abs(ctrl_scores - score) <= threshold
matches = ctrl_scores.loc[bool_match[bool_match.scores].index]
elif method == 'min':
matches = abs(ctrl_scores - score).sort_values('scores').head(nmatches)
else:
raise(AssertionError, "Invalid method parameter, use ('random', 'min')")
if len(matches) == 0:
continue
# randomly choose nmatches indices, if len(matches) > nmatches
select = nmatches if method != 'random' else np.random.choice(range(1, max_rand+1), 1)
chosen = np.random.choice(matches.index, min(select, nmatches), replace=False)
# print(chosen)
result.extend([test_scores.index[i]] + list(chosen))
match_ids.extend([i] * (len(chosen)+1))
ctrl_scores=ctrl_scores.drop(chosen,axis=0)
matched_data =data_p.loc[result]
matched_data['match_id'] = match_ids
matched_data['record_id'] = matched_data.index
print("\n匹配结果:")
print(len(matched_data[matched_data['is_group']==0]['record_id'].unique()))
print(len(matched_data[matched_data['is_group']==1]['record_id'].unique()))
# m.plot_scores()
plt.figure(figsize=(10,5))
sns.distplot(matched_data[matched_data[Y_field[0]]==0].scores, label='Control')
sns.distplot(matched_data[matched_data[Y_field[0]]==1].scores, label='Test')
plt.legend(loc='upper right')
plt.xlim((0, 1))
plt.title("Propensity Scores After Matching")
plt.ylabel("Percentage (%)")
plt.xlabel("Scores")
matched_data['city_name'] = city_name
file_name = 'result'+city_name+'.csv'
matched_data.to_csv(file_name,encoding='gbk',sep=',',index = False)
if type(city_psm_dri) == type(None) :
city_psm_dri = matched_data
else :
city_psm_dri = pd.concat([city_psm_dri,matched_data])
city_psm_dri.to_csv('result.csv',encoding='gbk',sep=',',index = False)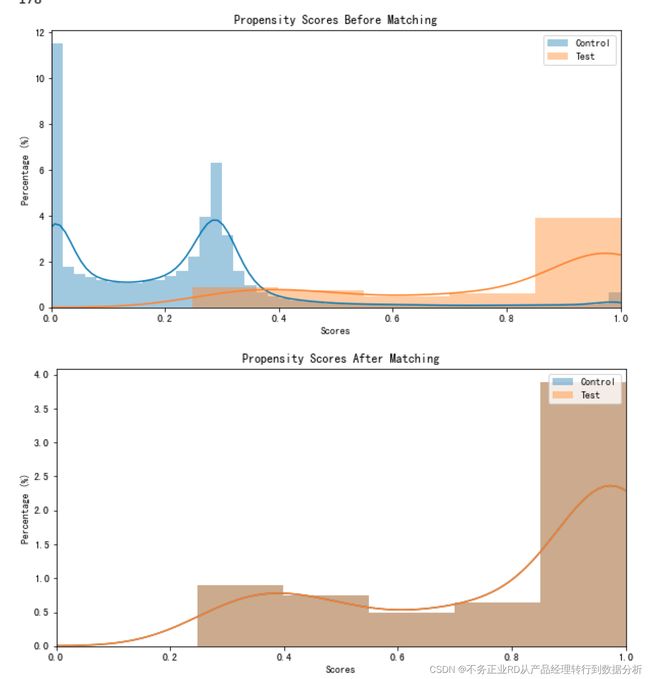
二、DID效果评估
2.1环境包导入
import statsmodels.formula.api as smf
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
#指定默认字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
#解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
import prestodb
import os
from pyhive import hive
def presto_read_sql_df(sql):
conn=prestodb.dbapi.connect(
host=os.environ['PRESTO_HOST'],
port=os.environ['PRESTO_PORT'],
user=os.environ['JUPYTER_HADOOP_USER'],
password=os.environ['HADOOP_USER_PASSWORD'],
catalog='hive')
cur = conn.cursor()
cur.execute(sql)
query_result = cur.fetchall()
colnames = [part[0] for part in cur.description]
raw = pd.DataFrame(query_result, columns=colnames,dtype=np.float64)
return raw
def hive_read_sql_df(sql):
conn = hive.connect(
host=os.environ['PYHIVE_HOST'],
port=os.environ['PYHIVE_PORT'],
username=os.environ['JUPYTER_HADOOP_USER'],
password=os.environ['HADOOP_USER_PASSWORD'],
auth='LDAP',
configuration={'mapreduce.job.queuename': os.environ['JUPYTER_HADOOP_QUEUE'],
'hive.resultset.use.unique.column.names':'false'})
raw = pd.read_sql_query(sql,conn)
return raw2.2数据读取与验证
df = pd.read_csv('20220617171533.csv',encoding='gbk')
print('shape:'+ str(df.shape))
df.dtypes
df.head().T
df.describe()2.3增量评估
city_list = {
'XXXX'
}
data = df
city_num=0
for city_name in city_list :
city_num=city_num+1
"city_name=='"+city_name+"'"
city_info = data.query("city_name=='"+city_name+"'")
print("="*20+str(city_num)+"="*20)
# print(city_info.shape)
value = list([city_info.tsh][0])
group = list([city_info.is_group][0])
strategy = list([city_info.is_strategy_time][0])
tg = list([city_info.tg][0])
aa = pd.DataFrame({'strategy':strategy,'group':group,'tg':tg,'value':value })
X = aa[['strategy', 'group','tg']]
y = aa['value']
# print(X.shape)
# print(y.shape)
est = smf.ols(formula='value ~ strategy + group + tg ', data=aa).fit()
y_pred = est.predict(X)
aa['value_pred'] = y_pred
#策略增量
dat_tsh = est.params.tg / (est.params.strategy + est.params.group + est.params.Intercept )
p_value = est.pvalues.tg
if p_value < 0.05 :
print(city_name+":△TSH = %.2f %%,效果显著 " % (dat_tsh*100))
else :
print(city_name+":△TSH = %.2f %%,效果不显著 " % (dat_tsh*100))
# print(est.params)
# print(est.pvalues)
2.4趋势绘图
def get_trend_plot(matched_long_new,city_name):
yx_trend = matched_long_new.groupby(['is_group','mon']).tsh.mean().reset_index()
fig, axes = plt.subplots(1, 1,figsize=(10,4), sharex = False, subplot_kw=dict(frameon=False))
x = yx_trend.loc[yx_trend.is_group==1,'mon'].astype(str)
y1 = yx_trend.loc[yx_trend.is_group==1,'tsh']
y2 = yx_trend.loc[yx_trend.is_group==0,'tsh']
axes.plot(x, y1,color='coral', linestyle='-', marker='o', label='实验组')
axes.plot(x, y2,color='cornflowerblue', linestyle='--', marker='o', label='对照组')
# 取time变量为0,即匹配期的最大日期,作为分界线
axes.axvline(x=matched_long_new.loc[matched_long_new.is_strategy_time==0].mon.max(), color='red', linestyle='--')
axes.set_xlabel(None)
axes.set_ylabel('TSH',rotation=0,labelpad=20)
# axes.set_xticklabels(labels=[i.replace('2021-','') for i in x],rotation = 40)
axes.legend()
axes.set_title('%s:XXXXX效果by月'%city_name)
plt.show()
city_num=0
for city_name in city_list :
city_num=city_num+1
"city_name=='"+city_name+"'"
city_info = data.query("city_name=='"+city_name+"'")
get_trend_plot(city_info,city_name)
# if city_num == 2 :
# break
若在策略上线前,实验组对照组趋势非常相似,则认为psm匹配效果很好,策略增量置信度高
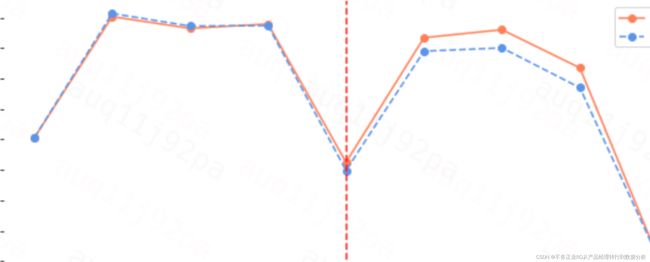
策略上线前,实验组对照组趋势GAP不稳定,则认为PSM人群不够相似,策略的增量置信度低,建议重新进行人群匹配。
结语:
1、psm选择指标时,需要确保指标对AB两组人群是根据样本自身行为有关的,与AB两组样本是无关的。
2、在构建相似人群时,需要注意人群是否本身存在一定的主观意愿的差异,即用户成为A人群和B人群是否是随机事件。如果存在主观的差异,尽管很多行为指标被psm拉齐,但人群仍然是不同质的,潜在的对策略的影响可能不同,从而导致结果虚高或者虚低。
例如A组是全量天猫商家,B组是全量淘宝商家,在全量B中选择A相似人群。
首先,用户成为A或着B,两组样本本身存在主管意愿的差异,已经具备了样本不同质,对策略的敏感度可能不同。
其次,如果相似指标中包含 店铺评分指标,A组和B组虽然都有店铺评分,但A、B的评分体系并不相同,所以这类指标不适宜作为相似指标进行筛选。
(例子不是很合适,我也不能讲我自身的业务,但相信大家可以get到我想说的是什么