CVPR2020|无需3D运动数据训练,最新SOTA人体姿势估计方法
点击我爱计算机视觉标星,更快获取CVML新技术
作者 | Muhammed Kocabas
译者 | 刘畅
出品 | AI科技大本营(ID:rgznai100)
人体的运动对于理解人的行为是非常重要的。尽管目前已经在单图像3D姿势和动作估计方面取得了进展,但由于缺少用于训练的真实的3D运动数据,因此现有的基于视频的SOTA方法无法产生准确且自然的运动序列。为了解决这个问题,本文提出了“用于人体姿势和形状估计的视频推理”(VIBE)方法,它利用了现有的大规模运动捕捉数据集(AMASS)以及未配对的2D关键点标注数据。
本文最关键的创新在于它是一种对抗性学习框架,该框架利用AMASS数据集来区分真实的人类动作与本文利用时序姿态和动作回归网络产生的动作。本文定义了一个时序网络体系结构,并展示了在没有真实3D标签的情况下,能够产生序列级别的合理的运动序列。本文进行了大量实验,分析了运动性的重要性,并演示了VIBE在非常有挑战性的3D姿态估计数据集上的有效性,达到了SOTA性能。
代码和预训练模型已经开源:
https://github.com/mkocabas/VIBE

引言
从单幅图像估计3D人体姿势和动作方面已经取得了巨大的进展。这对于许多应用程序是十分有用的,通过身体的运动来获取人的行为。正如约翰逊所指出的那样,即使人体仅移动了一丁点也可以得出有关行为的信息。在这里,本文介绍如何利用时间信息来更准确地从单视频中去估算人体的3D运动。尽管这个问题已经研究了30多年,但我们可能会问,为什么仍然没有可靠的方法。本文的见解是,由于训练数据不足,之前的人类运动的时间模型不能够捕获到人类实际运动的复杂性和可变性。作者在这里用一种新的方法解决了这个问题,并且表明我们可以从单视频中显著改善3D人体姿势估计的生成和判别方法。

如图1(上图)所示,现有的视频姿势和动作估计方法无法产生逼真的且运动学上合理的预测结果。造成这种情况的主要原因是缺乏数据的3D标注,对于单个图像都比较难以获得,更不用说对视频而言。之前的一些研究工作,它们将室内3D数据集与具有2D标注或关键点伪标注的视频结合在一起。但是,这有几个限制:(1)室内3D数据集在拍摄对象的数量,运动范围和图像复杂度方面受到限制;(2)带有2D姿势标注的视频数量仍然不足以训练深层的神经网络;(3)伪2D标签对于3D人体运动的建模不可靠。
为了解决这个问题,本文利用了称为AMASS的最新的大规模3D运动捕捉数据集,该数据集足够丰富,可以训练模型学习人们如何移动。本文的方法是从未标注的视频中使用2D关键点去估计3D姿势序列,是为了判别器无法分辨估计运动与AMASS数据集中运动之间的差异。与之前的一些研究工作相同,本文也会使用3D关键点。本文方法的输出是SMPL人体模型格式的一系列姿势和动作参数。
具体来说,本文通过训练基于序列的生成对抗网络来利用两个未配对的信息来源。在这里,给定一个人的视频,作者训练了一个时间模型来预测每帧SMPL人体模型的参数,而运动判别器则试图区分真实序列和回归序列。通过这样做,可以激励回归器通过最小化对抗训练损失来输出表示合理运动的姿势。作者称该方法为VIBE,它表示“用于人体姿态和动作估计的视频推理”。
在训练过程中,“ VIBE”将未标注的图像作为输入,并使用在单个图像的人体姿态估计任务上预训练的卷积神经网络去预测SMPL人体模型参数。然后,运动判别器使用预测的姿态以及从AMASS数据集采样的姿态,为每个序列输出真实/伪造的标签。整个模型由对抗性损失以及回归损失进行监督,以最大程度地减少预测的和标注的关键点,姿态和动作参数之间的误差。本文使用了改进的SPIN方法,该方法使用基于模型的拟合器来训练深度回归器。但是,SPIN是一种单帧方法。为了处理视频序列,作者通过将SMPLify扩展到视频,使得SPIN方法可以融入时序信息。
在测试时,给定一段视频,作者使用预训练的HMR和时间模块来预测每帧的姿势和动作参数。并在多个数据集上进行了大量的实验,超过了所有最新技术;有关VIBE输出的示例,请参见图1(底部)。重要的是,作者证明了基于视频的方法在具有挑战性的3D姿态估计基准数据集3DPW和MPI-INF-3DHP上总是比单帧方法好得多。这清楚地证明了在3D姿势估计中使用视频的好处。
综上,本文的主要贡献如下:首先,作者扩展了Kolotouros等人的基于模型的fitting-in-the-loop训练过程,对视频进行了更准确的监督。其次,作者利用了AMASS运动数据集,以进行VIBE的对抗训练。第三,作者定量比较了不同时间架构的3D人体运动估计。第四,作者使用大型的运动捕捉数据集来训练鉴别器,从而获得了SOTA的结果。

方法
整个VIBE方法的结构如下图2所示,输入是一段单人的视频。对每一帧使用一个预训练的模型去提取特征,接下来使用双GRU组成的编码器去训练。然后特征会被用于回归SMPL人体模型的参数。最后会从AMASS数据集中采样样本,进入动作判别器,去区分真假样本,完成整个流程。

时序编码器(Temporal Encoder)
作者在训练该编码器的时候,使用了4个损失函数,如下,包括2D损失、3D损失、姿态损失和动作损失。

每一项的具体计算方法如下:
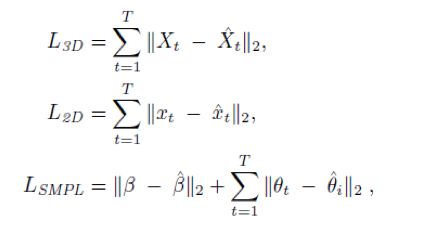
其中L_adv是动作判别器的损失。
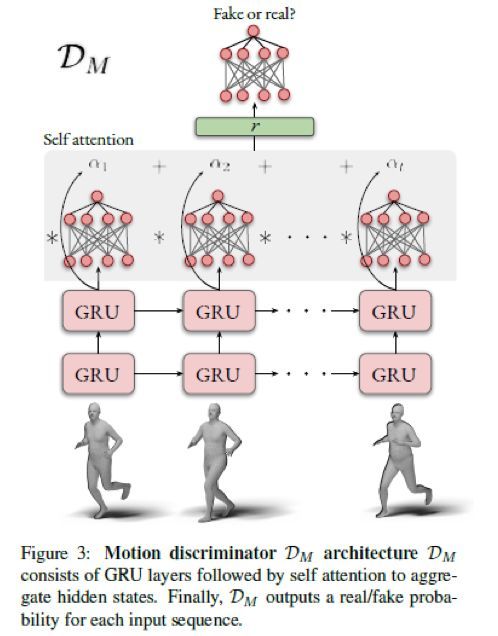
动作判别器(Motion Discriminator)
作者使用动作判别器来判断生成的姿态序列是否对应于真实的序列。如下图所示:
判别器的损失项计算方式如下:
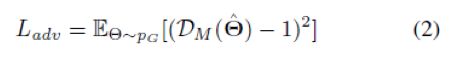
而动作判别器的目标函数如下:
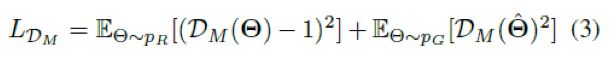

实验
作者首先介绍了训练和测试用的数据集,接下来,将本文方法的结果与之前的基于帧和基于视频的最新方法(SOTA)进行比较,如表格1所示。此外还做了消融实验,展示本文的贡献。最后,图4展示了可视化的结果。
本文方法与SOTA方法对比
作者证明了使用3DPW训练集,是有助于改善模型对in-the-wild数据的处理能力。由于本文方法保持了时序姿态和动作的一致性,因此MPJPE和PVE指标得到了显著的提升。

消融实验(关于动作判别器)
可以观察到,一旦添加了生成器G,由于缺少足够的视频训练数据,与基于帧的模型相比,本文获得的效果会稍差一些,但视觉效果会更平滑。在Temporal-HMR方法中也观察到了这种效果。另外,使用动作判别器可以有助于改善G的性能,同时仍会产生更加平滑的预测结果。

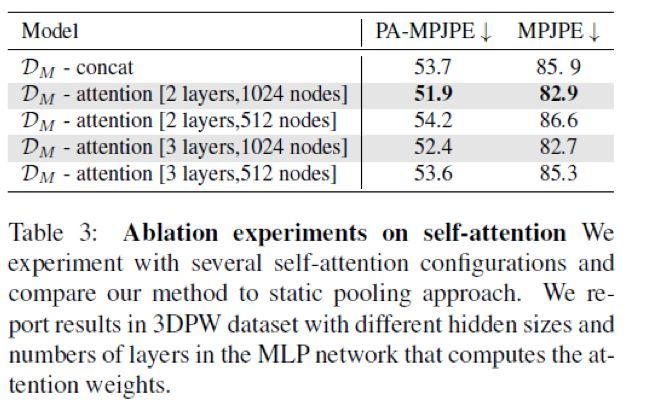
消融实验(关于自注意力机制)
如表3所示,与静态池化相比,动作判别器中的动态特征聚合可显著的改善最终结果。使用自注意力机制,可以加强动作判别器在时间上的相关性。在大多数情况下,使用自注意力机制会产生更好的结果。
下面图4和图5是本文方法的可视化结果,可以发现它能够正确复原全局旋转,这个是之前的方法都难以解决的一个问题。


总结
尽管当前的3D人体姿态方法效果很好,但是其中大多数都是未经过训练去估计视频中的人体运动。这种运动对于理解人体行为至关重要。
在这里,本文探索了几种将静态方法扩展到可以处理视频的方法:(1)介绍了一种随时间传播信息的循环体系结构;(2)介绍了使用AMASS数据集引入运动序列的判别训练;(3)本文在判别器中引入了自注意力机制,使它学会了关注人体运动的时间结构;(4)本文还从AMASS学习了一种新的人体先验序列信息(MPoser),并表明它也有助于训练结果,虽然能力不如判别器。未来的工作,作者会探索使用视频来监督单帧的方法,比如看看光流信息是否可以帮助提升结果。
原文链接:
https://arxiv.org/abs/1912.05656
姿态估计交流群
关注最新、最前沿的人体姿态估计、手势识别技术,扫码添加CV君拉你入群,如已为CV君其他账号好友请直接私信,
(请务必注明:姿态):

喜欢在QQ交流的童鞋可以加52CV官方QQ群:805388940。
(不会时时在线,如果没能及时通过还请见谅)

长按关注我爱计算机视觉