TF模型tensorrt C++ API搭建部署
TF模型tensorrt C++ API搭建部署
PS
该文章主要参考了基于TensorRT C++ API 加速 TF 模型以及tensorrtx,记录face_landmark tf模型的tensorrt部署,具体代码参考https://github.com/ycdhqzhiai/face_landmarks_tensorrtx(仓库已经添加了pytorch实现)
1.ckpt转pb模型
git clone https://github.com/610265158/face_landmark
git checkout tf1
- 根据仓库里面转tflite的代码,简单修改下,可以直接生成pb模型
#-*-coding:utf-8-*-
import sys
sys.path.append('.')
import tensorflow as tf
import tensorflow.contrib.slim as slim
import math
from train_config import config as cfg
from lib.core.model.Mobilenet import mobilenet
from lib.helper import logger
###also u can change it to a specific model
free_graphmodel_folder = './model'
checkpoint = tf.train.get_checkpoint_state(model_folder).model_checkpoint_path
pretrained_model=checkpoint
saved_name ='./model/landmark_deploy.ckpt'
class trainner():
def __init__(self):
self.inputs=[]
self.outputs=[]
self.ite_num=1
def _wing_loss(self,landmarks, labels, w=10.0, epsilon=2.0):
"""
Arguments:
landmarks, labels: float tensors with shape [batch_size, landmarks]. landmarks means x1,x2,x3,x4...y1,y2,y3,y4 1-D
w, epsilon: a float numbers.
Returns:
a float tensor with shape [].
"""
with tf.name_scope('wing_loss'):
x = landmarks - labels
c = w * (1.0 - math.log(1.0 + w / epsilon))
absolute_x = tf.abs(x)
losses = tf.where(
tf.greater(w, absolute_x),
w * tf.log(1.0 + absolute_x / epsilon),
absolute_x - c
)
if cfg.TRAIN.ohem:
return losses
else:
loss = tf.reduce_mean(tf.reduce_mean(losses, axis=[1]), axis=0)
return loss
def tower_loss(self,scope, images, labels, L2_reg):
"""Calculate the total loss on a single tower running the model.
Args:
scope: unique prefix string identifying the CIFAR tower, e.g. 'tower_0'
images: Images. 4D tensor of shape [batch_size, height, width, 3].
labels: Labels. 1D tensor of shape [batch_size].
Returns:
Tensor of shape [] containing the total loss for a batch of data
"""
# Build the portion of the Graph calculating the losses. Note that we will
# assemble the total_loss using a custom function below.
#net_out = shufflenet_v2(images, L2_reg, False)
#net_out = resnet(images, L2_reg, False)
net_out = mobilenet(images, L2_reg, False)
loss, leye_loss, reye_loss, mouth_loss, leye_cla_accuracy,\
reye_cla_accuracy, mouth_cla_accuracy, l2_loss=calculate_loss(net_out,labels,scope)
return loss,leye_loss,reye_loss,mouth_loss,leye_cla_accuracy,reye_cla_accuracy,mouth_cla_accuracy, l2_loss
def build(self):
"""Train faces data for a number of epoch."""
with tf.Graph().as_default(), tf.device('/cpu:0'):
# Create a variable to count the number of train() calls. This equals the
# number of batches processed * FLAGS.num_gpus.
global_step = tf.get_variable(
'global_step', [],
initializer=tf.constant_initializer(0), dtype=tf.int32, trainable=False)
# Decay the learning rate
lr = tf.train.piecewise_constant(global_step,
cfg.TRAIN.lr_decay_every_step,
cfg.TRAIN.lr_value_every_step
)
keep_prob = tf.placeholder(tf.float32, name="keep_prob")
L2_reg = tf.placeholder(tf.float32, name="L2_reg")
images_place_holder_list = []
labels_place_holder_list = []
# Create an optimizer that performs gradient descent.
#opt = tf.train.AdamOptimizer(lr)
opt = tf.train.MomentumOptimizer(lr,momentum=0.9,use_nesterov=False)
# Get images and labels
weights_initializer = slim.xavier_initializer()
biases_initializer = tf.constant_initializer(0.)
biases_regularizer = tf.no_regularizer
weights_regularizer = tf.contrib.layers.l2_regularizer(L2_reg)
# Calculate the gradients for each model tower.
tower_grads = []
with tf.variable_scope(tf.get_variable_scope()):
for i in range(1):
with tf.device('/gpu:%d' % i):
with tf.name_scope('tower_%d' % (i)) as scope:
with slim.arg_scope([slim.model_variable, slim.variable], device='/cpu:0'):
images_ = tf.placeholder(tf.float32, [None, cfg.MODEL.hin, cfg.MODEL.win, 3], name="images")
labels_ = tf.placeholder(tf.float32, [None, cfg.MODEL.out_channel],name="labels")
images_place_holder_list.append(images_)
labels_place_holder_list.append(labels_)
with slim.arg_scope([slim.conv2d, slim.conv2d_in_plane, \
slim.conv2d_transpose, slim.separable_conv2d,
slim.fully_connected],
weights_regularizer=weights_regularizer,
biases_regularizer=biases_regularizer,
weights_initializer=weights_initializer,
biases_initializer=biases_initializer):
loss, leye_loss, reye_loss, mouth_loss,leye_cla_accuracy,reye_cla_accuracy,mouth_cla_accuracy, l2_loss = self.tower_loss(
scope, images_, labels_, L2_reg)
##use muti gpu ,large batch
if i == cfg.TRAIN.num_gpu - 1:
total_loss = tf.add_n([loss, leye_loss, reye_loss, mouth_loss, l2_loss])
else:
total_loss = tf.add_n([loss, leye_loss, reye_loss, mouth_loss])
# Reuse variables for the next tower.
tf.get_variable_scope().reuse_variables()
##when use batchnorm, updates operations only from the
## final tower. Ideally, we should grab the updates from all towers
# but these stats accumulate extremely fast so we can ignore the
# other stats from the other towers without significant detriment.
bn_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS, scope=scope)
# Retain the summaries from the final tower.
#summaries = tf.get_collection(tf.GraphKeys.SUMMARIES, scope)
free_graph summaries = tf.get_collection('%smutiloss'%scope, scope)
# Calculate the gradients for the batch of data on this CIFAR tower.
grads = opt.compute_gradients(total_loss)
# Keep track of the gradients across all towers.
tower_grads.append(grads)
# We must calculate the mean of each gradient. Note that this is the
# synchronization point across all towers.
self.saver = tf.train.Saver(tf.global_variables(), max_to_keep=10)
# Build the summary operation from the last tower summaries.
# Build an initialization operation to run below.
init = tf.global_variables_initializer()
# Start running operations on the Graph. allow_soft_placement must be set to
# True to build towers on GPU, as some of the ops do not have GPU
# implementations.
tf_config = tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=False)
tf_config.gpu_options.allow_growth = True
self.sess = tf.Session(config=tf_config)
self.sess.run(init)
#########################restore the params
variables_restore = tf.get_collection(tf.GraphKeys.MODEL_VARIABLES)#,scope=cfg.MODEL.net_structure)
saver2 = tf.train.Saver(variables_restore)
saver2.restore(self.sess, pretrained_model)
logger.info('landmark_deploy saved')
self.saver.save(self.sess, save_path=saved_name)
self.sess.close()
train=trainner()
train.build()
将train_flage置为False,运行脚本重新生成ckpt模型
python net_work_for_tf_lite.py
- 去除auto_freeze脚本里面training参数直接转换
import sys
sys.path.append('.')
import os
import tensorflow as tf
from train_config import config as cfg
model_folder = cfg.MODEL.model_path
checkpoint = tf.train.get_checkpoint_state(model_folder)
##input_checkpoint
input_checkpoint = checkpoint.model_checkpoint_path
##input_graph
input_meta_graph = input_checkpoint + '.meta'
##output_node_names
output_node_names='tower_0/images,tower_0/prediction'
#output_graph
output_graph='./model/keypoints.pb'
print('excuted')
command="python tools/freeze.py --input_checkpoint %s --input_meta_graph %s --output_node_names %s --output_graph %s"\
%(input_checkpoint,input_meta_graph,output_node_names,output_graph)
os.system(command)
生成最终pb模型
python auto_freeze.py
2.将pb模型转换为wts文件
- 基于tf1
上面第一部分都是基于tf1将ckpt转换为pb模型,下面脚本是将pb转换为wts文件,参考了基于TensorRT C++ API 加速 TF 模型这篇文章,具体注意事项可以查看原文
import tensorflow as tf
from tensorflow.python.platform import gfile
import struct
import torch
from tensorflow.python.framework import tensor_util
# path to your .pb file
GRAPH_PB_PATH = './model/keypoints.pb'
GRAPH_WTS_PATH = './model/keypoints.wts'
with tf.Session() as sess:
print("load graph")
with gfile.FastGFile(GRAPH_PB_PATH, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
sess.graph.as_default()
tf.import_graph_def(graph_def, name='')
graph_nodes = [n for n in graph_def.node]
wts = [n for n in graph_nodes if n.op == 'Const']
dict = {}
for n in wts:
v = n.attr['value']
print(n.name)
ar = tensor_util.MakeNdarray(v.tensor)
dict[n.name] = torch.Tensor(ar)
f = open(GRAPH_WTS_PATH, 'w')
f.write("{}\n".format(len(dict.keys())))
for k, v in dict.items():
print('key: ', k)
print('value: ', v.shape)
if v.ndim == 4: # tf:NHWC trt:NCHW
v = v.transpose(3, 0).transpose(2, 1).transpose(3, 2)
vr = v.reshape(-1).cpu().numpy()
else:
vr = v.reshape(-1).cpu().numpy()
f.write("{} {}".format(k, len(vr)))
for vv in vr:
f.write(" ")
f.write(struct.pack(">f", float(vv)).hex())
f.write("\n")
- 基于tf2
源训练仓库tf2模型主要使用了tf.saved_model.save/tf.saved_model.load这2个api,用来保存和加载save_mode.pb模型,由于不是蛮会tf,查阅相关API,写了以下脚本转换wts文件
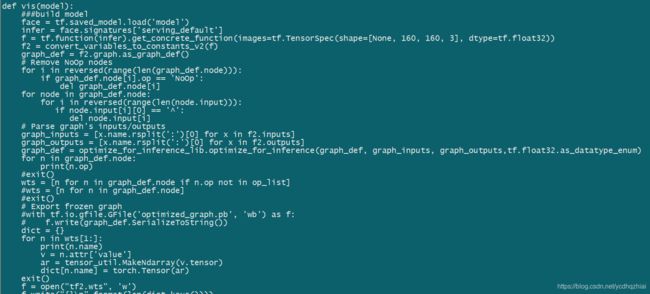
该脚本转换出来的wts文件,模型权重与netron对比是一致的,但是模型节点名称却很奇怪。没有接下来验证,感兴趣的可以验证下
3.根据wts 使用tensorRT API搭建网络
基于TensorRT C++ API 加速 TF 模型这篇文章中详细提到了各个层的使用到的API,我这里参考这篇文章,根据训练源码中shufflenetv2,重写了一遍,具体可以参考
https://github.com/ycdhqzhiai/face_landmarks_tensorrtx